PDF Output of CLIC (Clustering by Inferred Co-Expression)
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

CENPT (NM 025082) Human 3' UTR Clone – SC200995 | Origene
OriGene Technologies, Inc. 9620 Medical Center Drive, Ste 200 Rockville, MD 20850, US Phone: +1-888-267-4436 [email protected] EU: [email protected] CN: [email protected] Product datasheet for SC200995 CENPT (NM_025082) Human 3' UTR Clone Product data: Product Type: 3' UTR Clones Product Name: CENPT (NM_025082) Human 3' UTR Clone Vector: pMirTarget (PS100062) Symbol: CENPT Synonyms: C16orf56; CENP-T; SSMGA ACCN: NM_025082 Insert Size: 140 bp Insert Sequence: >SC200995 3’UTR clone of NM_025082 The sequence shown below is from the reference sequence of NM_025082. The complete sequence of this clone may contain minor differences, such as SNPs. Blue=Stop Codon Red=Cloning site GGCAAGTTGGACGCCCGCAAGATCCGCGAGATTCTCATTAAGGCCAAGAAGGGCGGAAAGATCGCCGTG TAACAATTGGCAGAGCTCAGAATTCAAGCGATCGCC AGTGGCAACTCTGTCTTCCCTGCCCAGTAGTGGCCAGGCTTCAACACTTTCCCTGTCCCCACCTGGGGA CTCTTGCCCCCACATATTTCTCCAGGTCTCCTCCCCACCCCCCCAGCATCAATAAAGTGTCATAAACAG AA ACGCGTAAGCGGCCGCGGCATCTAGATTCGAAGAAAATGACCGACCAAGCGACGCCCAACCTGCCATCA CGAGATTTCGATTCCACCGCCGCCTTCTATGAAAGG Restriction Sites: SgfI-MluI OTI Disclaimer: Our molecular clone sequence data has been matched to the sequence identifier above as a point of reference. Note that the complete sequence of this clone is largely the same as the reference sequence but may contain minor differences , e.g., single nucleotide polymorphisms (SNPs). RefSeq: NM_025082.4 Summary: The centromere is a specialized chromatin domain, present throughout the cell cycle, that acts as a platform on which the transient assembly of the kinetochore occurs during mitosis. All active centromeres are characterized by the presence of long arrays of nucleosomes in which CENPA (MIM 117139) replaces histone H3 (see MIM 601128). CENPT is an additional factor required for centromere assembly (Foltz et al., 2006 [PubMed 16622419]).[supplied by OMIM, Mar 2008] Locus ID: 80152 This product is to be used for laboratory only. Not for diagnostic or therapeutic use. -

Gene Knockdown of CENPA Reduces Sphere Forming Ability and Stemness of Glioblastoma Initiating Cells
Neuroepigenetics 7 (2016) 6–18 Contents lists available at ScienceDirect Neuroepigenetics journal homepage: www.elsevier.com/locate/nepig Gene knockdown of CENPA reduces sphere forming ability and stemness of glioblastoma initiating cells Jinan Behnan a,1, Zanina Grieg b,c,1, Mrinal Joel b,c, Ingunn Ramsness c, Biljana Stangeland a,b,⁎ a Department of Molecular Medicine, Institute of Basic Medical Sciences, The Medical Faculty, University of Oslo, Oslo, Norway b Norwegian Center for Stem Cell Research, Department of Immunology and Transfusion Medicine, Oslo University Hospital, Oslo, Norway c Vilhelm Magnus Laboratory for Neurosurgical Research, Institute for Surgical Research and Department of Neurosurgery, Oslo University Hospital, Oslo, Norway article info abstract Article history: CENPA is a centromere-associated variant of histone H3 implicated in numerous malignancies. However, the Received 20 May 2016 role of this protein in glioblastoma (GBM) has not been demonstrated. GBM is one of the most aggressive Received in revised form 23 July 2016 human cancers. GBM initiating cells (GICs), contained within these tumors are deemed to convey Accepted 2 August 2016 characteristics such as invasiveness and resistance to therapy. Therefore, there is a strong rationale for targeting these cells. We investigated the expression of CENPA and other centromeric proteins (CENPs) in Keywords: fi CENPA GICs, GBM and variety of other cell types and tissues. Bioinformatics analysis identi ed the gene signature: fi Centromeric proteins high_CENP(AEFNM)/low_CENP(BCTQ) whose expression correlated with signi cantly worse GBM patient Glioblastoma survival. GBM Knockdown of CENPA reduced sphere forming ability, proliferation and cell viability of GICs. We also Brain tumor detected significant reduction in the expression of stemness marker SOX2 and the proliferation marker Glioblastoma initiating cells and therapeutic Ki67. -

Centromere RNA Is a Key Component for the Assembly of Nucleoproteins at the Nucleolus and Centromere
Downloaded from genome.cshlp.org on September 23, 2021 - Published by Cold Spring Harbor Laboratory Press Letter Centromere RNA is a key component for the assembly of nucleoproteins at the nucleolus and centromere Lee H. Wong,1,3 Kate H. Brettingham-Moore,1 Lyn Chan,1 Julie M. Quach,1 Melisssa A. Anderson,1 Emma L. Northrop,1 Ross Hannan,2 Richard Saffery,1 Margaret L. Shaw,1 Evan Williams,1 and K.H. Andy Choo1 1Chromosome and Chromatin Research Laboratory, Murdoch Childrens Research Institute & Department of Paediatrics, University of Melbourne, Royal Children’s Hospital, Parkville 3052, Victoria, Australia; 2Peter MacCallum Research Institute, St. Andrew’s Place, East Melbourne, Victoria 3002, Australia The centromere is a complex structure, the components and assembly pathway of which remain inadequately defined. Here, we demonstrate that centromeric ␣-satellite RNA and proteins CENPC1 and INCENP accumulate in the human interphase nucleolus in an RNA polymerase I–dependent manner. The nucleolar targeting of CENPC1 and INCENP requires ␣-satellite RNA, as evident from the delocalization of both proteins from the nucleolus in RNase-treated cells, and the nucleolar relocalization of these proteins following ␣-satellite RNA replenishment in these cells. Using protein truncation and in vitro mutagenesis, we have identified the nucleolar localization sequences on CENPC1 and INCENP. We present evidence that CENPC1 is an RNA-associating protein that binds ␣-satellite RNA by an in vitro binding assay. Using chromatin immunoprecipitation, RNase treatment, and “RNA replenishment” experiments, we show that ␣-satellite RNA is a key component in the assembly of CENPC1, INCENP, and survivin (an INCENP-interacting protein) at the metaphase centromere. -

PDF Output of CLIC (Clustering by Inferred Co-Expression)
PDF Output of CLIC (clustering by inferred co-expression) Dataset: Num of genes in input gene set: 13 Total number of genes: 16493 CLIC PDF output has three sections: 1) Overview of Co-Expression Modules (CEMs) Heatmap shows pairwise correlations between all genes in the input query gene set. Red lines shows the partition of input genes into CEMs, ordered by CEM strength. Each row shows one gene, and the brightness of squares indicates its correlations with other genes. Gene symbols are shown at left side and on the top of the heatmap. 2) Details of each CEM and its expansion CEM+ Top panel shows the posterior selection probability (dataset weights) for top GEO series datasets. Bottom panel shows the CEM genes (blue rows) as well as expanded CEM+ genes (green rows). Each column is one GEO series dataset, sorted by their posterior probability of being selected. The brightness of squares indicates the gene's correlations with CEM genes in the corresponding dataset. CEM+ includes genes that co-express with CEM genes in high-weight datasets, measured by LLR score. 3) Details of each GEO series dataset and its expression profile: Top panel shows the detailed information (e.g. title, summary) for the GEO series dataset. Bottom panel shows the background distribution and the expression profile for CEM genes in this dataset. Overview of Co-Expression Modules (CEMs) with Dataset Weighting Scale of average Pearson correlations Num of Genes in Query Geneset: 13. Num of CEMs: 1. 0.0 0.2 0.4 0.6 0.8 1.0 Cenpk Cenph Cenpp Cenpu Cenpn Cenpq Cenpl Apitd1 -

Identification of Conserved Genes Triggering Puberty in European Sea
Blázquez et al. BMC Genomics (2017) 18:441 DOI 10.1186/s12864-017-3823-2 RESEARCHARTICLE Open Access Identification of conserved genes triggering puberty in European sea bass males (Dicentrarchus labrax) by microarray expression profiling Mercedes Blázquez1,2* , Paula Medina1,2,3, Berta Crespo1,4, Ana Gómez1 and Silvia Zanuy1* Abstract Background: Spermatogenesisisacomplexprocesscharacterized by the activation and/or repression of a number of genes in a spatio-temporal manner. Pubertal development in males starts with the onset of the first spermatogenesis and implies the division of primary spermatogonia and their subsequent entry into meiosis. This study is aimed at the characterization of genes involved in the onset of puberty in European sea bass, and constitutes the first transcriptomic approach focused on meiosis in this species. Results: European sea bass testes collected at the onset of puberty (first successful reproduction) were grouped in stage I (resting stage), and stage II (proliferative stage). Transition from stage I to stage II was marked by an increase of 11ketotestosterone (11KT), the main fish androgen, whereas the transcriptomic study resulted in 315 genes differentially expressed between the two stages. The onset of puberty induced 1) an up-regulation of genes involved in cell proliferation, cell cycle and meiosis progression, 2) changes in genes related with reproduction and growth, and 3) a down-regulation of genes included in the retinoic acid (RA) signalling pathway. The analysis of GO-terms and biological pathways showed that cell cycle, cell division, cellular metabolic processes, and reproduction were affected, consistent with the early events that occur during the onset of puberty. -

IL21R Expressing CD14+CD16+ Monocytes Expand in Multiple
Plasma Cell Disorders SUPPLEMENTARY APPENDIX IL21R expressing CD14 +CD16 + monocytes expand in multiple myeloma patients leading to increased osteoclasts Marina Bolzoni, 1 Domenica Ronchetti, 2,3 Paola Storti, 1,4 Gaetano Donofrio, 5 Valentina Marchica, 1,4 Federica Costa, 1 Luca Agnelli, 2,3 Denise Toscani, 1 Rosanna Vescovini, 1 Katia Todoerti, 6 Sabrina Bonomini, 7 Gabriella Sammarelli, 1,7 Andrea Vecchi, 8 Daniela Guasco, 1 Fabrizio Accardi, 1,7 Benedetta Dalla Palma, 1,7 Barbara Gamberi, 9 Carlo Ferrari, 8 Antonino Neri, 2,3 Franco Aversa 1,4,7 and Nicola Giuliani 1,4,7 1Myeloma Unit, Dept. of Medicine and Surgery, University of Parma; 2Dept. of Oncology and Hemato-Oncology, University of Milan; 3Hematology Unit, “Fondazione IRCCS Ca’ Granda”, Ospedale Maggiore Policlinico, Milan; 4CoreLab, University Hospital of Parma; 5Dept. of Medical-Veterinary Science, University of Parma; 6Laboratory of Pre-clinical and Translational Research, IRCCS-CROB, Referral Cancer Center of Basilicata, Rionero in Vulture; 7Hematology and BMT Center, University Hospital of Parma; 8Infectious Disease Unit, University Hospital of Parma and 9“Dip. Oncologico e Tecnologie Avanzate”, IRCCS Arcispedale Santa Maria Nuova, Reggio Emilia, Italy ©2017 Ferrata Storti Foundation. This is an open-access paper. doi:10.3324/haematol. 2016.153841 Received: August 5, 2016. Accepted: December 23, 2016. Pre-published: January 5, 2017. Correspondence: [email protected] SUPPLEMENTAL METHODS Immunophenotype of BM CD14+ in patients with monoclonal gammopathies. Briefly, 100 μl of total BM aspirate was incubated in the dark with anti-human HLA-DR-PE (clone L243; BD), anti-human CD14-PerCP-Cy 5.5, anti-human CD16-PE-Cy7 (clone B73.1; BD) and anti-human CD45-APC-H 7 (clone 2D1; BD) for 20 min. -
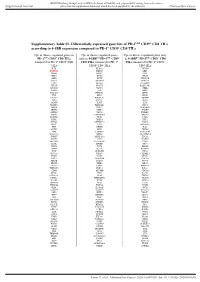
Supplementary Table S5. Differentially Expressed Gene Lists of PD-1High CD39+ CD8 Tils According to 4-1BB Expression Compared to PD-1+ CD39- CD8 Tils
BMJ Publishing Group Limited (BMJ) disclaims all liability and responsibility arising from any reliance Supplemental material placed on this supplemental material which has been supplied by the author(s) J Immunother Cancer Supplementary Table S5. Differentially expressed gene lists of PD-1high CD39+ CD8 TILs according to 4-1BB expression compared to PD-1+ CD39- CD8 TILs Up- or down- regulated genes in Up- or down- regulated genes Up- or down- regulated genes only PD-1high CD39+ CD8 TILs only in 4-1BBneg PD-1high CD39+ in 4-1BBpos PD-1high CD39+ CD8 compared to PD-1+ CD39- CD8 CD8 TILs compared to PD-1+ TILs compared to PD-1+ CD39- TILs CD39- CD8 TILs CD8 TILs IL7R KLRG1 TNFSF4 ENTPD1 DHRS3 LEF1 ITGA5 MKI67 PZP KLF3 RYR2 SIK1B ANK3 LYST PPP1R3B ETV1 ADAM28 H2AC13 CCR7 GFOD1 RASGRP2 ITGAX MAST4 RAD51AP1 MYO1E CLCF1 NEBL S1PR5 VCL MPP7 MS4A6A PHLDB1 GFPT2 TNF RPL3 SPRY4 VCAM1 B4GALT5 TIPARP TNS3 PDCD1 POLQ AKAP5 IL6ST LY9 PLXND1 PLEKHA1 NEU1 DGKH SPRY2 PLEKHG3 IKZF4 MTX3 PARK7 ATP8B4 SYT11 PTGER4 SORL1 RAB11FIP5 BRCA1 MAP4K3 NCR1 CCR4 S1PR1 PDE8A IFIT2 EPHA4 ARHGEF12 PAICS PELI2 LAT2 GPRASP1 TTN RPLP0 IL4I1 AUTS2 RPS3 CDCA3 NHS LONRF2 CDC42EP3 SLCO3A1 RRM2 ADAMTSL4 INPP5F ARHGAP31 ESCO2 ADRB2 CSF1 WDHD1 GOLIM4 CDK5RAP1 CD69 GLUL HJURP SHC4 GNLY TTC9 HELLS DPP4 IL23A PITPNC1 TOX ARHGEF9 EXO1 SLC4A4 CKAP4 CARMIL3 NHSL2 DZIP3 GINS1 FUT8 UBASH3B CDCA5 PDE7B SOGA1 CDC45 NR3C2 TRIB1 KIF14 TRAF5 LIMS1 PPP1R2C TNFRSF9 KLRC2 POLA1 CD80 ATP10D CDCA8 SETD7 IER2 PATL2 CCDC141 CD84 HSPA6 CYB561 MPHOSPH9 CLSPN KLRC1 PTMS SCML4 ZBTB10 CCL3 CA5B PIP5K1B WNT9A CCNH GEM IL18RAP GGH SARDH B3GNT7 C13orf46 SBF2 IKZF3 ZMAT1 TCF7 NECTIN1 H3C7 FOS PAG1 HECA SLC4A10 SLC35G2 PER1 P2RY1 NFKBIA WDR76 PLAUR KDM1A H1-5 TSHZ2 FAM102B HMMR GPR132 CCRL2 PARP8 A2M ST8SIA1 NUF2 IL5RA RBPMS UBE2T USP53 EEF1A1 PLAC8 LGR6 TMEM123 NEK2 SNAP47 PTGIS SH2B3 P2RY8 S100PBP PLEKHA7 CLNK CRIM1 MGAT5 YBX3 TP53INP1 DTL CFH FEZ1 MYB FRMD4B TSPAN5 STIL ITGA2 GOLGA6L10 MYBL2 AHI1 CAND2 GZMB RBPJ PELI1 HSPA1B KCNK5 GOLGA6L9 TICRR TPRG1 UBE2C AURKA Leem G, et al. -

Supplementary Table S1. Correlation Between the Mutant P53-Interacting Partners and PTTG3P, PTTG1 and PTTG2, Based on Data from Starbase V3.0 Database
Supplementary Table S1. Correlation between the mutant p53-interacting partners and PTTG3P, PTTG1 and PTTG2, based on data from StarBase v3.0 database. PTTG3P PTTG1 PTTG2 Gene ID Coefficient-R p-value Coefficient-R p-value Coefficient-R p-value NF-YA ENSG00000001167 −0.077 8.59e-2 −0.210 2.09e-6 −0.122 6.23e-3 NF-YB ENSG00000120837 0.176 7.12e-5 0.227 2.82e-7 0.094 3.59e-2 NF-YC ENSG00000066136 0.124 5.45e-3 0.124 5.40e-3 0.051 2.51e-1 Sp1 ENSG00000185591 −0.014 7.50e-1 −0.201 5.82e-6 −0.072 1.07e-1 Ets-1 ENSG00000134954 −0.096 3.14e-2 −0.257 4.83e-9 0.034 4.46e-1 VDR ENSG00000111424 −0.091 4.10e-2 −0.216 1.03e-6 0.014 7.48e-1 SREBP-2 ENSG00000198911 −0.064 1.53e-1 −0.147 9.27e-4 −0.073 1.01e-1 TopBP1 ENSG00000163781 0.067 1.36e-1 0.051 2.57e-1 −0.020 6.57e-1 Pin1 ENSG00000127445 0.250 1.40e-8 0.571 9.56e-45 0.187 2.52e-5 MRE11 ENSG00000020922 0.063 1.56e-1 −0.007 8.81e-1 −0.024 5.93e-1 PML ENSG00000140464 0.072 1.05e-1 0.217 9.36e-7 0.166 1.85e-4 p63 ENSG00000073282 −0.120 7.04e-3 −0.283 1.08e-10 −0.198 7.71e-6 p73 ENSG00000078900 0.104 2.03e-2 0.258 4.67e-9 0.097 3.02e-2 Supplementary Table S2. -

Greg's Awesome Thesis
Analysis of alignment error and sitewise constraint in mammalian comparative genomics Gregory Jordan European Bioinformatics Institute University of Cambridge A dissertation submitted for the degree of Doctor of Philosophy November 30, 2011 To my parents, who kept us thinking and playing This dissertation is the result of my own work and includes nothing which is the out- come of work done in collaboration except where specifically indicated in the text and acknowledgements. This dissertation is not substantially the same as any I have submitted for a degree, diploma or other qualification at any other university, and no part has already been, or is currently being submitted for any degree, diploma or other qualification. This dissertation does not exceed the specified length limit of 60,000 words as defined by the Biology Degree Committee. November 30, 2011 Gregory Jordan ii Analysis of alignment error and sitewise constraint in mammalian comparative genomics Summary Gregory Jordan November 30, 2011 Darwin College Insight into the evolution of protein-coding genes can be gained from the use of phylogenetic codon models. Recently sequenced mammalian genomes and powerful analysis methods developed over the past decade provide the potential to globally measure the impact of natural selection on pro- tein sequences at a fine scale. The detection of positive selection in particular is of great interest, with relevance to the study of host-parasite conflicts, immune system evolution and adaptive dif- ferences between species. This thesis examines the performance of methods for detecting positive selection first with a series of simulation experiments, and then with two empirical studies in mammals and primates. -

Loss of Inner Kinetochore Genes Is Associated with the Transition to an Unconventional Point Centromere in Budding Yeast
Loss of inner kinetochore genes is associated with the transition to an unconventional point centromere in budding yeast Nagarjun Vijay Computational Evolutionary Genomics Lab, Department of Biological Sciences, Indian Institute of Science Education and Research, Bhopal, Madhya Pradesh, India ABSTRACT Background: The genomic sequences of centromeres, as well as the set of proteins that recognize and interact with centromeres, are known to quickly diverge between lineages potentially contributing to post-zygotic reproductive isolation. However, the actual sequence of events and processes involved in the divergence of the kinetochore machinery is not known. The patterns of gene loss that occur during evolution concomitant with phenotypic changes have been used to understand the timing and order of molecular changes. Methods: I screened the high-quality genomes of twenty budding yeast species for the presence of well-studied kinetochore genes. Based on the conserved gene order and complete genome assemblies, I identified gene loss events. Subsequently, I searched the intergenic regions to identify any un-annotated genes or gene remnants to obtain additional evidence of gene loss. Results: My analysis identified the loss of four genes (NKP1, NKP2, CENPL/IML3 and CENPN/CHL4) of the inner kinetochore constitutive centromere-associated network (CCAN/also known as CTF19 complex in yeast) in both the Naumovozyma species for which genome assemblies are available. Surprisingly, this collective loss of four genes of the CCAN/CTF19 complex coincides with the emergence of Submitted 18 June 2020 unconventional centromeres in N. castellii and N. dairenensis. My study suggests a 11 September 2020 Accepted tentative link between the emergence of unconventional point centromeres and the Published 29 September 2020 turnover of kinetochore genes in budding yeast. -

Investigation of Differentially Expressed Genes in Nasopharyngeal Carcinoma by Integrated Bioinformatics Analysis
916 ONCOLOGY LETTERS 18: 916-926, 2019 Investigation of differentially expressed genes in nasopharyngeal carcinoma by integrated bioinformatics analysis ZhENNING ZOU1*, SIYUAN GAN1*, ShUGUANG LIU2, RUjIA LI1 and jIAN hUANG1 1Department of Pathology, Guangdong Medical University, Zhanjiang, Guangdong 524023; 2Department of Pathology, The Eighth Affiliated hospital of Sun Yat‑sen University, Shenzhen, Guangdong 518033, P.R. China Received October 9, 2018; Accepted April 10, 2019 DOI: 10.3892/ol.2019.10382 Abstract. Nasopharyngeal carcinoma (NPC) is a common topoisomerase 2α and TPX2 microtubule nucleation factor), malignancy of the head and neck. The aim of the present study 8 modules, and 14 TFs were identified. Modules analysis was to conduct an integrated bioinformatics analysis of differ- revealed that cyclin-dependent kinase 1 and exportin 1 were entially expressed genes (DEGs) and to explore the molecular involved in the pathway of Epstein‑Barr virus infection. In mechanisms of NPC. Two profiling datasets, GSE12452 and summary, the hub genes, key modules and TFs identified in GSE34573, were downloaded from the Gene Expression this study may promote our understanding of the pathogenesis Omnibus database and included 44 NPC specimens and of NPC and require further in-depth investigation. 13 normal nasopharyngeal tissues. R software was used to identify the DEGs between NPC and normal nasopharyngeal Introduction tissues. Distributions of DEGs in chromosomes were explored based on the annotation file and the CYTOBAND database Nasopharyngeal carcinoma (NPC) is a common malignancy of DAVID. Gene ontology (GO) and Kyoto Encyclopedia of occurring in the head and neck. It is prevalent in the eastern Genes and Genomes (KEGG) pathway enrichment analysis and southeastern parts of Asia, especially in southern China, were applied. -

Centromere Protein N May Be a Novel Malignant Prognostic Biomarker for Hepatocellular Carcinoma
Centromere protein N may be a novel malignant prognostic biomarker for hepatocellular carcinoma Qingqing Wang, Xiaoyan Yu, Zhewen Zheng, Fengxia Chen, Ningning Yang and Yunfeng Zhou Hubei Cancer Clinical Study Center, Hubei Key Laboratory of Tumor Biological Behaviors, Zhongnan Hospital, Wuhan University, Wuhan, China Department of Radiation Oncology and Medical Oncology, Zhongnan Hospital, Wuhan University, Wuhan, China ABSTRACT Background. Hepatocellular carcinoma (HCC) is one of the deadliest tumors. The majority of HCC is detected in the late stage, and the clinical results for HCC patients are poor. There is an urgent need to discover early diagnostic biomarkers and potential therapeutic targets for HCC. Methods. The GSE87630 and GSE112790 datasets from the Gene Expression Omnibus (GEO) database were downloaded to analyze the differentially expressed genes (DEGs) between HCC and normal tissues. R packages were used for Kyoto Encyclopedia of Genes and Genomes (KEGG) and Gene Ontology (GO) enrichment analyses of the DEGs. A Search Tool for Retrieval of Interacting Genes (STRING) database was used to develop a protein-protein interaction (PPI) network, and also cytoHubba, Molecular Complex Detection (MCODE), EMBL-EBI, CCLE, Gene Expression Profiling Interac- tive Analysis (GEPIA), and Oncomine analyses were performed to identify hub genes. Gene expression was verified with a third GEO dataset, GSE25097. The Cancer Genome Atlas (TCGA) database was used to explore the correlations between the hub genes and clinical indexes of HCC patients. The functions of the hub genes were enriched by gene set enrichment analysis (GSEA), and the biological significance of the hub genes was explored by real-time polymerase chain reaction (qRT-PCR), western blot, Submitted 4 January 2021 immunofluorescence, CCK-8, colony formation, Transwell and flow cytometry assays Accepted 3 April 2021 with loss-of-function experiments in vitro.