Proposal for a Gurmukhi Script Root Zone Label Generation Ruleset (LGR)
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Grammatica Et Verba Glamor and Verve
“GippertOVprint” — 2014/4/24 — 22:14 — page 81 —#1 Grammatica et verba Glamor and verve Studies in South Asian, historical, and Indo-European linguistics in honor of Hans Henrich Hock on the occasion of his seventy-fifth birthday edited by Shu-Fen Chen and Benjamin Slade Beech Stave Press Ann Arbor New York • “GippertOVprint” — 2014/4/24 — 22:14 — page 82 —#2 © Beech Stave Press, Inc. All rights reserved. No part of this publication may be reproduced, translated, stored in a retrieval system, or transmitted in any form or by any means, electronic, mechanical, photocopying, recording or otherwise, without prior written permission from the publisher. Typeset with LATEX using the Galliard typeface designed by Matthew Carter and Greek Old Face by Ralph Hancock. The typeface on the cover is Post Hock by Steve Peter. Library of Congress Cataloging-in-Publication Data Grammatica et verba : glamor and verve : studies in South Asian, historical, and Indo- European linguistics in honor of Hans Henrich Hock on the occasion of his seventy- fifth birthday / edited by Shu-Fen Chen and Benjamin Slade. pages cm Includes bibliographical references. ISBN ---- (alk. paper) . Indo-European languages. Lexicography. Historical linguistics. I. Hock, Hans Henrich, - honoree. II. Chen, Shu-Fen, editor of compilation. III. Slade, Ben- jamin, editor of compilation. –dc Printed in the United States of America “GippertOVprint” — 2014/4/24 — 22:14 — page 83 —#3 TableHHHHHH ofHHHHHHHHHHHHHHH ContentsHHHHHHHHHHHH Preface . vii Bibliography of Hans Henrich Hock . ix List of Contributors . xxi , Traces of Archaic Human Language Structure Anvita Abbi in the Great Andamanese Language. , A Study of Punctuation Errors in the Chinese Diamond Sutra Shu-Fen Chen Based on Sanskrit Texts . -

Schwa Deletion: Investigating Improved Approach for Text-To-IPA System for Shiri Guru Granth Sahib
ISSN (Online) 2278-1021 ISSN (Print) 2319-5940 International Journal of Advanced Research in Computer and Communication Engineering Vol. 4, Issue 4, April 2015 Schwa Deletion: Investigating Improved Approach for Text-to-IPA System for Shiri Guru Granth Sahib Sandeep Kaur1, Dr. Amitoj Singh2 Pursuing M.E, CSE, Chitkara University, India 1 Associate Director, CSE, Chitkara University , India 2 Abstract: Punjabi (Omniglot) is an interesting language for more than one reasons. This is the only living Indo- Europen language which is a fully tonal language. Punjabi language is an abugida writing system, with each consonant having an inherent vowel, SCHWA sound. This sound is modifiable using vowel symbols attached to consonant bearing the vowel. Shri Guru Granth Sahib is a voluminous text of 1430 pages with 511,874 words, 1,720,345 characters, and 28,534 lines and contains hymns of 36 composers written in twenty-two languages in Gurmukhi script (Lal). In addition to text being in form of hymns and coming from so many composers belonging to different languages, what makes the language of Shri Guru Granth Sahib even more different from contemporary Punjabi. The task of developing an accurate Letter-to-Sound system is made difficult due to two further reasons: 1. Punjabi being the only tonal language 2. Historical and Cultural circumstance/period of writings in terms of historical and religious nature of text and use of words from multiple languages and non-native phonemes. The handling of schwa deletion is of great concern for development of accurate/ near perfect system, the presented work intend to report the state-of-the-art in terms of schwa deletion for Indian languages, in general and for Gurmukhi Punjabi, in particular. -

Assessment of Options for Handling Full Unicode Character Encodings in MARC21 a Study for the Library of Congress
1 Assessment of Options for Handling Full Unicode Character Encodings in MARC21 A Study for the Library of Congress Part 1: New Scripts Jack Cain Senior Consultant Trylus Computing, Toronto 1 Purpose This assessment intends to study the issues and make recommendations on the possible expansion of the character set repertoire for bibliographic records in MARC21 format. 1.1 “Encoding Scheme” vs. “Repertoire” An encoding scheme contains codes by which characters are represented in computer memory. These codes are organized according to a certain methodology called an encoding scheme. The list of all characters so encoded is referred to as the “repertoire” of characters in the given encoding schemes. For example, ASCII is one encoding scheme, perhaps the one best known to the average non-technical person in North America. “A”, “B”, & “C” are three characters in the repertoire of this encoding scheme. These three characters are assigned encodings 41, 42 & 43 in ASCII (expressed here in hexadecimal). 1.2 MARC8 "MARC8" is the term commonly used to refer both to the encoding scheme and its repertoire as used in MARC records up to 1998. The ‘8’ refers to the fact that, unlike Unicode which is a multi-byte per character code set, the MARC8 encoding scheme is principally made up of multiple one byte tables in which each character is encoded using a single 8 bit byte. (It also includes the EACC set which actually uses fixed length 3 bytes per character.) (For details on MARC8 and its specifications see: http://www.loc.gov/marc/.) MARC8 was introduced around 1968 and was initially limited to essentially Latin script only. -

Shahmukhi to Gurmukhi Transliteration System: a Corpus Based Approach
Shahmukhi to Gurmukhi Transliteration System: A Corpus based Approach Tejinder Singh Saini1 and Gurpreet Singh Lehal2 1 Advanced Centre for Technical Development of Punjabi Language, Literature & Culture, Punjabi University, Patiala 147 002, Punjab, India [email protected] http://www.advancedcentrepunjabi.org 2 Department of Computer Science, Punjabi University, Patiala 147 002, Punjab, India [email protected] Abstract. This research paper describes a corpus based transliteration system for Punjabi language. The existence of two scripts for Punjabi language has created a script barrier between the Punjabi literature written in India and in Pakistan. This research project has developed a new system for the first time of its kind for Shahmukhi script of Punjabi language. The proposed system for Shahmukhi to Gurmukhi transliteration has been implemented with various research techniques based on language corpus. The corpus analysis program has been run on both Shahmukhi and Gurmukhi corpora for generating statistical data for different types like character, word and n-gram frequencies. This statistical analysis is used in different phases of transliteration. Potentially, all members of the substantial Punjabi community will benefit vastly from this transliteration system. 1 Introduction One of the great challenges before Information Technology is to overcome language barriers dividing the mankind so that everyone can communicate with everyone else on the planet in real time. South Asia is one of those unique parts of the world where a single language is written in different scripts. This is the case, for example, with Punjabi language spoken by tens of millions of people but written in Indian East Punjab (20 million) in Gurmukhi script (a left to right script based on Devanagari) and in Pakistani West Punjab (80 million), written in Shahmukhi script (a right to left script based on Arabic), and by a growing number of Punjabis (2 million) in the EU and the US in the Roman script. -

South Asian Art a Resource for Classroom Teachers
South Asian Art A Resource for Classroom Teachers South Asian Art A Resource for Classroom Teachers Contents 2 Introduction 3 Acknowledgments 4 Map of South Asia 6 Religions of South Asia 8 Connections to Educational Standards Works of Art Hinduism 10 The Sun God (Surya, Sun God) 12 Dancing Ganesha 14 The Gods Sing and Dance for Shiva and Parvati 16 The Monkeys and Bears Build a Bridge to Lanka 18 Krishna Lifts Mount Govardhana Jainism 20 Harinegameshin Transfers Mahavira’s Embryo 22 Jina (Jain Savior-Saint) Seated in Meditation Islam 24 Qasam al-Abbas Arrives from Mecca and Crushes Tahmasp with a Mace 26 Prince Manohar Receives a Magic Ring from a Hermit Buddhism 28 Avalokiteshvara, Bodhisattva of Compassion 30 Vajradhara (the source of all teachings on how to achieve enlightenment) CONTENTS Introduction The Philadelphia Museum of Art is home to one of the most important collections of South Asian and Himalayan art in the Western Hemisphere. The collection includes sculptures, paintings, textiles, architecture, and decorative arts. It spans over two thousand years and encompasses an area of the world that today includes multiple nations and nearly a third of the planet’s population. This vast region has produced thousands of civilizations, birthed major religious traditions, and provided fundamental innovations in the arts and sciences. This teaching resource highlights eleven works of art that reflect the diverse cultures and religions of South Asia and the extraordinary beauty and variety of artworks produced in the region over the centuries. We hope that you enjoy exploring these works of art with your students, looking closely together, and talking about responses to what you see. -

Jtc1/Sc2/Wg2 N3427 L2/08-132
JTC1/SC2/WG2 N3427 L2/08-132 2008-04-08 Universal Multiple-Octet Coded Character Set International Organization for Standardization Organisation Internationale de Normalisation Международная организация по стандартизации Doc Type: Working Group Document Title: Proposal to encode 39 Unified Canadian Aboriginal Syllabics in the UCS Source: Michael Everson and Chris Harvey Status: Individual Contribution Action: For consideration by JTC1/SC2/WG2 and UTC Date: 2008-04-08 1. Summary. This document requests 39 additional characters to be added to the UCS and contains the proposal summary form. 1. Syllabics hyphen (U+1400). Many Aboriginal Canadian languages use the character U+1428 CANADIAN SYLLABICS FINAL SHORT HORIZONTAL STROKE, which looks like the Latin script hyphen. Algonquian languages like western dialects of Cree, Oji-Cree, western and northern dialects of Ojibway employ this character to represent /tʃ/, /c/, or /j/, as in Plains Cree ᐊᓄᐦᐨ /anohc/ ‘today’. In Athabaskan languages, like Chipewyan, the sound is /d/ or an alveolar onset, as in Sayisi Dene ᐨᕦᐣᐨᕤ /t’ąt’ú/ ‘how’. To avoid ambiguity between this character and a line-breaking hyphen, a SYLLABICS HYPHEN was developed which resembles an equals sign. Depending on the typeface, the width of the syllabics hyphen can range from a short ᐀ to a much longer ᐀. This hyphen is line-breaking punctuation, and should not be confused with the Blackfoot syllable internal-w final proposed for U+167F. See Figures 1 and 2. 2. DHW- additions for Woods Cree (U+1677..U+167D). ᙷᙸᙹᙺᙻᙼᙽ/ðwē/ /ðwi/ /ðwī/ /ðwo/ /ðwō/ /ðwa/ /ðwā/. The basic syllable structure in Cree is (C)(w)V(C)(C). -

Typotheque North American Syllabics Proposed Revisions to The
Typotheque Prepared by Kevin King Typotheque [email protected] www.typotheque.com 04/06/21 North American Syllabics Proposed revisions to the representative characters of the Unified Canadian Aboriginal Syllabics code charts Typotheque Proposed representative character revisions of the Unified Canadian Aboriginal Syllabics 2 CONTENTS 1 Summary of proposed character revisions 3 2 Revisions for Carrier 9 3 Revisions for Sayisi 36 4 Revisions for Ojibway 46 Bibliography 52 Acknowledgements 54 Typotheque Proposed representative character revisions of the Unified Canadian Aboriginal Syllabics 3 1 Summary of proposed character revisions The following proposal requests 120 revisions to the representative char- acters in the official code charts of Unified Canadian Aboriginal Syllabics main and extended blocks. The proposed characters for revision have been summarized below with representative glyphs and corresponding character names with annotations where applicable. Additionally, revised code charts for UCAS main and extended has been provided in the following section with the proposed revised representative characters marked in pink, imple- mented into their corresponding code point locations. The author has prepared a style-matched font for the purpose of imple- menting into the code chart: 144B ᑋ CANADIAN SYLLABICS carrier H 160D ᘍ CANADIAN SYLLABICS carrier ma 14D1 ᓑ CANADIAN SYLLABICS carrier NG 160E ᘎ CANADIAN SYLLABICS carrier yu 1506 ᔆ CANADIAN SYLLABICS athapascan s 160F ᘏ CANADIAN SYLLABICS carrier yO 15C0 ᗀ CANADIAN SYLLABICS Sayisi -

Proposal for a Gujarati Script Root Zone Label Generation Ruleset (LGR)
Proposal for a Gujarati Root Zone LGR Neo-Brahmi Generation Panel Proposal for a Gujarati Script Root Zone Label Generation Ruleset (LGR) LGR Version: 3.0 Date: 2019-03-06 Document version: 3.6 Authors: Neo-Brahmi Generation Panel [NBGP] 1 General Information/ Overview/ Abstract The purpose of this document is to give an overview of the proposed Gujarati LGR in the XML format and the rationale behind the design decisions taken. It includes a discussion of relevant features of the script, the communities or languages using it, the process and methodology used and information on the contributors. The formal specification of the LGR can be found in the accompanying XML document: proposal-gujarati-lgr-06mar19-en.xml Labels for testing can be found in the accompanying text document: gujarati-test-labels-06mar19-en.txt 2 Script for which the LGR is proposed ISO 15924 Code: Gujr ISO 15924 Key N°: 320 ISO 15924 English Name: Gujarati Latin transliteration of native script name: gujarâtî Native name of the script: ગજુ રાતી Maximal Starting Repertoire (MSR) version: MSR-4 1 Proposal for a Gujarati Root Zone LGR Neo-Brahmi Generation Panel 3 Background on the Script and the Principal Languages Using it1 Gujarati (ગજુ રાતી) [also sometimes written as Gujerati, Gujarathi, Guzratee, Guujaratee, Gujrathi, and Gujerathi2] is an Indo-Aryan language native to the Indian state of Gujarat. It is part of the greater Indo-European language family. It is so named because Gujarati is the language of the Gujjars. Gujarati's origins can be traced back to Old Gujarati (circa 1100– 1500 AD). -

Contribution to the UN Secretary-General's 2018 Report
COMMISSION ON SCIENCE AND TECHNOLOGY FOR DEVELOPMENT (CSTD) Twenty-second session Geneva, 13 to 17 May 2019 Submissions from entities in the United Nations system and elsewhere on their efforts in 2018 to implement the outcome of the WSIS Submission by Internet Corporation for Assigned Names and Numbers This submission was prepared as an input to the report of the UN Secretary-General on "Progress made in the implementation of and follow-up to the outcomes of the World Summit on the Information Society at the regional and international levels" (to the 22nd session of the CSTD), in response to the request by the Economic and Social Council, in its resolution 2006/46, to the UN Secretary-General to inform the Commission on Science and Technology for Development on the implementation of the outcomes of the WSIS as part of his annual reporting to the Commission. DISCLAIMER: The views presented here are the contributors' and do not necessarily reflect the views and position of the United Nations or the United Nations Conference on Trade and Development. 2018 ANNUAL REPORT TO UNCTAD: ICANN CONTRIBUTION Progress made in the implementation of and follow-up to the outcomes of the World Summit on the Information Society at the regional and international levels Executive Summary ICANN is pleased and honoured be invited to contribute to this annual UNCTAD Report. We value our involvement with, and contribution to, the overall WSIS process and to our relationship with the UN Commission on Science and Technology for Development (CSTD). 2018 has been a busy and important year for ICANN and for the Internet Governance Ecosystem in general; with the ITU Plenipotentiary taking place in Dubai and the IGF in Paris. -
Census of India Website at Censusinfo.Html
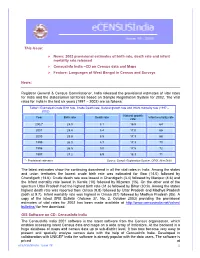
This Issue: News: 2002 provisional estimates of birth rate, death rate and infant mortality rate released CensusInfo India –CD on Census data and Maps Feature: Languages of West Bengal in Census and Surveys News: Registrar General & Census Commissioner, India released the provisional estimates of vital rates for India and the states/union territories based on Sample Registration System for 2002. The vital rates for India in the last six years (1997 – 2002) are as follows: Table1: Estimated Crude Birth rate, Crude Death rate, Natural growth rate and Infant mortality rate (1997 – 2002) Natural growth Year Birth rate Death rate Infant mortality rate rate 2002* 25.0 8.1 16.9 64 2001 25.4 8.4 17.0 66 2000 25.8 8.5 17.3 68 1999 26.0 8.7 17.3 70 1998 26.5 9.0 17.5 72 1997 27.2 8.9 18.3 71 * - Provisional estimates Source: Sample Registration System, ORGI, New Delhi The latest estimates show the continuing downtrend in all the vital rates in India. Among the states and union territories the lowest crude birth rate was estimated for Goa (14.0) followed by Chandigarh (14.6). Crude death rate was lowest in Chandigarh (3.4) followed by Manipur (4.6) and the Infant mortality rate lowest in Kerala (10) followed by Mizoram (15). On the other end of the spectrum Uttar Pradesh had the highest birth rate (31.6) followed by Bihar (30.9). Among the states highest death rate was reported from Orissa (9.8) followed by Uttar Pradesh and Madhya Pradesh (both at 9.7). -

Finite-State Script Normalization and Processing Utilities: the Nisaba Brahmic Library
Finite-state script normalization and processing utilities: The Nisaba Brahmic library Cibu Johny† Lawrence Wolf-Sonkin‡ Alexander Gutkin† Brian Roark‡ Google Research †United Kingdom and ‡United States {cibu,wolfsonkin,agutkin,roark}@google.com Abstract In addition to such normalization issues, some scripts also have well-formedness constraints, i.e., This paper presents an open-source library for efficient low-level processing of ten ma- not all strings of Unicode characters from a single jor South Asian Brahmic scripts. The library script correspond to a valid (i.e., legible) grapheme provides a flexible and extensible framework sequence in the script. Such constraints do not ap- for supporting crucial operations on Brahmic ply in the basic Latin alphabet, where any permuta- scripts, such as NFC, visual normalization, tion of letters can be rendered as a valid string (e.g., reversible transliteration, and validity checks, for use as an acronym). The Brahmic family of implemented in Python within a finite-state scripts, however, including the Devanagari script transducer formalism. We survey some com- mon Brahmic script issues that may adversely used to write Hindi, Marathi and many other South affect the performance of downstream NLP Asian languages, do have such constraints. These tasks, and provide the rationale for finite-state scripts are alphasyllabaries, meaning that they are design and system implementation details. structured around orthographic syllables (aksara)̣ as the basic unit.1 One or more Unicode characters 1 Introduction combine when rendering one of thousands of leg- The Unicode Standard separates the representation ible aksara,̣ but many combinations do not corre- of text from its specific graphical rendering: text spond to any aksara.̣ Given a token in these scripts, is encoded as a sequence of characters, which, at one may want to (a) normalize it to a canonical presentation time are then collectively rendered form; and (b) check whether it is a well-formed into the appropriate sequence of glyphs for display. -

16-Sanskrit-In-JAPAN.Pdf
A rich literary treasure of Sanskrit literature consisting of dharanis, tantras, sutras and other texts has been kept in Japan for nearly 1400 years. Entry of Sanskrit Buddhist scriptures into Japan was their identification with the central axis of human advance. Buddhism opened up unfathomed spheres of thought as soon as it reached Japan officially in AD 552. Prince Shotoku Taishi himself wrote commentaries and lectured on Saddharmapundarika-sutra, Srimala- devi-simhanada-sutra and Vimala-kirt-nirdesa-sutra. They can be heard in the daily recitation of the Japanese up to the day. Palmleaf manuscripts kept at different temples since olden times comprise of texts which carry immeasurable importance from the viewpoint of Sanskrit philology although some of them are incomplete Sanskrit manuscripts crossed the boundaries of India along with the expansion of Buddhist philosophy, art and thought and reached Japan via Central Asia and China. Thousands of Sanskrit texts were translated into Khotanese, Tokharian, Uigur and Sogdian in Central Asia, on their way to China. With destruction of monastic libraries, most of the Sanskrit literature perished leaving behind a large number of fragments which are discovered by the great explorers who went from Germany, Russia, British India, Sweden and Japan. These excavations have uncovered vast quantities of manuscripts in Sanskrit. Only those manuscripts and texts have survived which were taken to Nepal and Tibet or other parts of Asia. Their translations into Tibetan, Chinese and Mongolian fill the gap, but partly. A number of ancient Sanskrit manuscripts are strewn in the monasteries nestling among high mountains and waterless deserts.