UC Berkeley Proposals from the Script Encoding Initiative
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

The Origin and Spread of the Jawi Script
Sub-regional Symposium on the Incorporation of the Languages of Asian Muslim Peoples into the Standardized Quranic Script 2008 ﻧﺪﻭﺓ November 7-5 ﺷﺒﻪ ,Kuala Lumpur ﺇﻗﻠﻴﻤﻴﺔ ,(SQSP) ﺣﻮﻝ:Project ﺇﺩﺭﺍﺝ ﻟﻐﺎﺕ ﺍﻟﺸﻌﻮﺏ ﺍﻹﺳﻼﻣﻴﺔ ﰲ ﺁﺳﻴﺎ ﰲ ﻣﺸﺮﻭﻉ ﺍﳊﺮﻑ ﺍﻟﻘﺮﺁﱐ 7_9 ﺫﻭ ﺍﻟﻘﻌﺪﺓ 1429 ﻫـ ﺍﳌﻮﺍﻓﻖ 5-7 ﻧﻮﻓﻤﱪ 2008 ﻡ ﻗﺎﻋﺔ ﳎﻠﺲ ﺍﻷﺳﺎﺗﺬﺓ : ﺍﳉﺎﻣﻌﺔ ﺍﻹﺳﻼﻣﻴﺔ ﺍﻟﻌﺎﳌﻴﺔ ﲟﺎﻟﻴﺰﻳﺎ THE ORIGIN AND SPREAD OF THE JAWI SCRIPT Amat Juhari Ph.D Bangi, Malaysia Sub-regional Symposium on the Incorporation of the Languages of Asian Muslim Peoples into the Standardized Quranic Script Project (SQSP), Kuala Lumpur, 5-7 November 2008 THE ORIGIN AND THE SPREAD OF THE JAWI SCRIPT SYNOPSIS This paper discusses the origin and the spread of the Jawi Script. Jawi Script is derived from the Arabic Script, but it later changed its name to Jawi because in Jawi Script there are six more new letters being added to it to represent the six Malay phonemes which are not found in the Arabic Language. The oldest known Jawi writing is the Terengganu Inscriptions dated 24 th February 1303 or 702 Hijrah. Later on Jawi Script was used extensively in the Sultanate of Malacca, the Sultanate of Old Johor, the Sultanate of Aceh, the Sultanate of Johor-Riau and other sultanates and kingdoms of South East Asia. Jawi Script had spread from Aceh in North Sumatra in the west to Ternate and Tidore in the Moluccas Islands in the eastern part of Indonesia, and then from Cambodia in the north to Banten in the south. Nowadays, about 16,000 Malay Jawi manuscripts are being preserved and kept in many libraries and archives around the world. -

75 Characters Maximum
Kannada Script LGR Proposal Introduction, Current Analysis and Next Steps Dr. U.B. Pavanaja NBGP F2F Meeting, Colombo 14 December 2017 | 1 Agenda 1 2 3 Introduction to Repertoire Analysis Within Script Kannada Script Variants 4 5 6 Cross-Script WLE Rules Current Status and Variants Next Steps for Completion | 2 Introduction to Kannada Script Population – there are about 60 million speakers of Kannada language which uses Kannada script. Geographical area - Kannada is spoken predominantly by the people of Karnataka State of India. It is also spoken by significant linguistic minorities in the states of Andhra Pradesh, Telangana, Tamil Nadu, Maharashtra, Kerala, Goa and abroad Languages written in Kannada script – Kannada, Tulu, Kodava (Coorgi), Konkani, Havyaka, Sanketi, Beary (byaari), Arebaase, Koraga | 3 Classification of Characters Swaras (vowels) Letter ಅ ಆ ಇ ಈ ಉ ಊ ಋ ಎ ಏ ಐ ಒ ಓ ಔ Vowel sign/ N/Aಾ ಾ ಾ ಾ ಾ ಾ ಾ ಾ ಾ ಾ ಾ ಾ matra Yogavahas In Kannada, all consonants Anusvara ಅಂ (vyanjanas) when written as ಕ (ka), ಖ (kha), ಗ (ga), etc. actually have a built-in vowel sign (matra) Visarga ಅಃ of vowel ಅ (a) in them. | 4 Classification of Characters Vargeeya vyanjana (structured consonants) voiceless voiceless aspirate voiced voiced aspirate nasal Velars ಕ ಖ ಗ ಘ ಙ Palatals ಚ ಛ ಜ ಝ ಞ Retroflex ಟ ಠ ಡ ಢ ಣ Dentals ತ ಥ ದ ಧ ನ Labials ಪ ಫ ಬ ಭ ಮ Avargeeya vyanjana (unstructured consonants) ಯ ರ ಱ (obsolete) ಲ ವ ಶ ಷ ಸ ಹ ಳ ೞ (obsolete) | 5 Repertoire Included-1 Sr. Unicode Glyph Character Name Unicode Indic Ref Widespread No. Code General Syllabic use ? Point Category Category [Yes/No] 1 0C82 ಂ KANNADA SIGN ANUSVARA Mc Anusvara Yes 2 0C83 ಂ KANNADA SIGN VISARGA Mc Visarga Yes 3 0C85 ಅ KANNADA LETTER A Lo Vowel Yes 4 0C86 ಆ KANNADA LETTER AA Lo Vowel Yes 5 0C87 ಇ KANNADA LETTER I Lo Vowel Yes 6 0C88 ಈ KANNADA LETTER II Lo Vowel Yes 7 0C89 ಉ KANNADA LETTER U Lo Vowel Yes 8 0C8A ಊ KANNADA LETTER UU Lo Vowel Yes KANNADA LETTER VOCALIC 9 0C8B ಋ R Lo Vowel Yes 10 0C8E ಎ KANNADA LETTER E Lo Vowel Yes | 6 Repertoire Included-2 Sr. -

UNICODE for Kannada General Information & Description
UNICODE for Kannada (U+0C80 to U+0CFF) General Information & Description Written by: C V Srinatha Sastry Issued by: Director Directorate of Information Technology Government of Karnataka Multi Storied Buildings, Vidhana Veedhi BANGALORE 560 001 INDIA PDF created with FinePrint pdfFactory Pro trial version http://www.pdffactory.com UNICODE for Kannada Introduction The Kannada script is a South Indian script. It is used to write Kannada language of Karnataka State in India. This is also used in many parts of Tamil Nadu, Kerala, Andhra Pradesh and Maharashtra States of India. In addition, the Kannada script is also used to write Tulu, Konkani and Kodava languages. Kannada along with other Indian language scripts shares a large number of structural features. The Kannada block of Unicode Standard (0C80 to 0CFF) is based on ISCII-1988 (Indian Standard Code for Information Interchange). The Unicode Standard (version 3) encodes Kannada characters in the same relative positions as those coded in the ISCII-1988 standard. The Writing system that employs Kannada script constitutes a cross between syllabic writing systems and phonemic writing systems (alphabets). The effective unit of writing Kannada is the orthographic syllable consisting of a consonant (Vyanjana) and vowel (Vowel) (CV) core and optionally, one or more preceding consonants, with a canonical structure of ((C)C)CV. The orthographic syllable need not correspond exactly with a phonological syllable, especially when a consonant cluster is involved, but the writing system is built on phonological principles and tends to correspond quite closely to pronunciation. The orthographic syllable is built up of alphabetic pieces, the actual letters of Kannada script. -

Technical Reference Manual for the Standardization of Geographical Names United Nations Group of Experts on Geographical Names
ST/ESA/STAT/SER.M/87 Department of Economic and Social Affairs Statistics Division Technical reference manual for the standardization of geographical names United Nations Group of Experts on Geographical Names United Nations New York, 2007 The Department of Economic and Social Affairs of the United Nations Secretariat is a vital interface between global policies in the economic, social and environmental spheres and national action. The Department works in three main interlinked areas: (i) it compiles, generates and analyses a wide range of economic, social and environmental data and information on which Member States of the United Nations draw to review common problems and to take stock of policy options; (ii) it facilitates the negotiations of Member States in many intergovernmental bodies on joint courses of action to address ongoing or emerging global challenges; and (iii) it advises interested Governments on the ways and means of translating policy frameworks developed in United Nations conferences and summits into programmes at the country level and, through technical assistance, helps build national capacities. NOTE The designations employed and the presentation of material in the present publication do not imply the expression of any opinion whatsoever on the part of the Secretariat of the United Nations concerning the legal status of any country, territory, city or area or of its authorities, or concerning the delimitation of its frontiers or boundaries. The term “country” as used in the text of this publication also refers, as appropriate, to territories or areas. Symbols of United Nations documents are composed of capital letters combined with figures. ST/ESA/STAT/SER.M/87 UNITED NATIONS PUBLICATION Sales No. -

Assessment of Options for Handling Full Unicode Character Encodings in MARC21 a Study for the Library of Congress
1 Assessment of Options for Handling Full Unicode Character Encodings in MARC21 A Study for the Library of Congress Part 1: New Scripts Jack Cain Senior Consultant Trylus Computing, Toronto 1 Purpose This assessment intends to study the issues and make recommendations on the possible expansion of the character set repertoire for bibliographic records in MARC21 format. 1.1 “Encoding Scheme” vs. “Repertoire” An encoding scheme contains codes by which characters are represented in computer memory. These codes are organized according to a certain methodology called an encoding scheme. The list of all characters so encoded is referred to as the “repertoire” of characters in the given encoding schemes. For example, ASCII is one encoding scheme, perhaps the one best known to the average non-technical person in North America. “A”, “B”, & “C” are three characters in the repertoire of this encoding scheme. These three characters are assigned encodings 41, 42 & 43 in ASCII (expressed here in hexadecimal). 1.2 MARC8 "MARC8" is the term commonly used to refer both to the encoding scheme and its repertoire as used in MARC records up to 1998. The ‘8’ refers to the fact that, unlike Unicode which is a multi-byte per character code set, the MARC8 encoding scheme is principally made up of multiple one byte tables in which each character is encoded using a single 8 bit byte. (It also includes the EACC set which actually uses fixed length 3 bytes per character.) (For details on MARC8 and its specifications see: http://www.loc.gov/marc/.) MARC8 was introduced around 1968 and was initially limited to essentially Latin script only. -

Constitution of the Federation of Bosnia and Herzegovina
Emerika Bluma 1, 71000 Sarajevo Tel. 28 35 00 Fax. 28 35 01 Department for Legal Affairs CONSTITUTION OF THE FEDERATION OF BOSNIA AND HERZEGOVINA “Official Gazette of the Federation of Bosnia and Herzegovina”, 1/94, 13/97 CONSTITUTION OF THE FEDERATION OF BOSNIA AND HERZEGOVINA - consolidated translation, with amendments indicated - • The Constitution of the Federation of Bosnia and Herzegovina was adopted by the Constitutional Assembly of the Federation of BiH, at the session held on June 24, 1994. It was published in Slu`bene Novine Federacije Bosne i Hercegovine n. 1, 1994. • Amendment I to the Constitution of the Federation of Bosnia and Herzegovina was passed by the Constitutional Assembly of the Federation of BiH, at the session held on June 24th,1994. It was also published in Slu`bene Novine Federacije Bosne i Hercegovine n. 1, 1994. • Amendments II to XXIV to the Constitution of the Federation of Bosnia and Herzegovina were passed by the Constitutional Assembly of the Federation of BiH, at its 14th session held on June 5th,1996. They were published in Slu`bene Novine Federacije Bosne i Hercegovine n. 13, 1997. • Amendments XXV and XXVI to the Constitution of the Federation of Bosnia and Herzegovina were passed according to the procedure in Chapter VIII, finalized on May 8th, 1997. They were also published in Slu`bene Novine Federacije Bosne i Hercegovine n. 13, 1997. PREAMBLE I. ESTABLISHMENT OF THE FEDERATION Arts. 1-6 II. HUMAN RIGHTS A. General Arts. 1-7 B. Initial Appointment and Functions of the Ombudsmen Arts. 1-9 III. DIVISION OF RESPONSIBILITIES BETWEEN THE FEDERATION GOVERNMENT AND THE CANTONS Arts. -

5892 Cisco Category: Standards Track August 2010 ISSN: 2070-1721
Internet Engineering Task Force (IETF) P. Faltstrom, Ed. Request for Comments: 5892 Cisco Category: Standards Track August 2010 ISSN: 2070-1721 The Unicode Code Points and Internationalized Domain Names for Applications (IDNA) Abstract This document specifies rules for deciding whether a code point, considered in isolation or in context, is a candidate for inclusion in an Internationalized Domain Name (IDN). It is part of the specification of Internationalizing Domain Names in Applications 2008 (IDNA2008). Status of This Memo This is an Internet Standards Track document. This document is a product of the Internet Engineering Task Force (IETF). It represents the consensus of the IETF community. It has received public review and has been approved for publication by the Internet Engineering Steering Group (IESG). Further information on Internet Standards is available in Section 2 of RFC 5741. Information about the current status of this document, any errata, and how to provide feedback on it may be obtained at http://www.rfc-editor.org/info/rfc5892. Copyright Notice Copyright (c) 2010 IETF Trust and the persons identified as the document authors. All rights reserved. This document is subject to BCP 78 and the IETF Trust's Legal Provisions Relating to IETF Documents (http://trustee.ietf.org/license-info) in effect on the date of publication of this document. Please review these documents carefully, as they describe your rights and restrictions with respect to this document. Code Components extracted from this document must include Simplified BSD License text as described in Section 4.e of the Trust Legal Provisions and are provided without warranty as described in the Simplified BSD License. -

The Chinese Script T � * 'L
Norman, Jerry, Chinese, Cambridge: Cambridge University Press, 1988. 1 3.1 Th e beginnings of Chinese writing 59 3 FISH HORSE ELEPHANT cow (yu) (m ii) (xiimg) (niu) " The Chinese script t � * 'l Figure 3.1. Pictographs in early Chinese writing 3.1 The beginnings of Chinese writing1 The Chinese script appears as a fully developed writing system in the late Shang .dynasty (fourteenth to eleventh centuries BC). From this period we have copious examples of the script inscribed or written on bones and tortoise shells, for the most part in the form of short divinatory texts. From the same period there also Figure 3.2. The graph fo r quiin'dog' exist a number of inscriptions on bronze vessels of various sorts. The former type of graphic record is referred to as the oracle bone script while the latter is com of this sort of graph are shown in Figure 3.1. The more truly representational a monly known· as the bronze script. The script of this period is already a fully graph is, the more difficult and time-consuming it is to depict. There is a natural developed writing system, capable of recording the contemporary Chinese lan tendency for such graphs to become progressively simplified and stylized as a guage in a complete and unambiguous manner. The maturity of this early script writing system matures and becomes more widely used. As a result, pictographs has suggested to many scholars that it must have passed through a fairly long gradually tend to lose their obvious pictorial quality. The graph for qui'in 'dog' period of development before reaching this stage, but the few examples of writing shown in Figure 3.2 can serve as a good illustration of this sort of development. -

Proposal for a Kannada Script Root Zone Label Generation Ruleset (LGR)
Proposal for a Kannada Script Root Zone Label Generation Ruleset (LGR) Proposal for a Kannada Script Root Zone Label Generation Ruleset (LGR) LGR Version: 3.0 Date: 2019-03-06 Document version: 2.6 Authors: Neo-Brahmi Generation Panel [NBGP] 1. General Information/ Overview/ Abstract The purpose of this document is to give an overview of the proposed Kannada LGR in the XML format and the rationale behind the design decisions taken. It includes a discussion of relevant features of the script, the communities or languages using it, the process and methodology used and information on the contributors. The formal specification of the LGR can be found in the accompanying XML document: proposal-kannada-lgr-06mar19-en.xml Labels for testing can be found in the accompanying text document: kannada-test-labels-06mar19-en.txt 2. Script for which the LGR is Proposed ISO 15924 Code: Knda ISO 15924 N°: 345 ISO 15924 English Name: Kannada Latin transliteration of the native script name: Native name of the script: ಕನ#ಡ Maximal Starting Repertoire (MSR) version: MSR-4 Some languages using the script and their ISO 639-3 codes: Kannada (kan), Tulu (tcy), Beary, Konkani (kok), Havyaka, Kodava (kfa) 1 Proposal for a Kannada Script Root Zone Label Generation Ruleset (LGR) 3. Background on Script and Principal Languages Using It 3.1 Kannada language Kannada is one of the scheduled languages of India. It is spoken predominantly by the people of Karnataka State of India. It is one of the major languages among the Dravidian languages. Kannada is also spoken by significant linguistic minorities in the states of Andhra Pradesh, Telangana, Tamil Nadu, Maharashtra, Kerala, Goa and abroad. -

A Script Independent Approach for Handwritten Bilingual Kannada and Telugu Digits Recognition
IJMI International Journal of Machine Intelligence ISSN: 0975–2927 & E-ISSN: 0975–9166, Volume 3, Issue 3, 2011, pp-155-159 Available online at http://www.bioinfo.in/contents.php?id=31 A SCRIPT INDEPENDENT APPROACH FOR HANDWRITTEN BILINGUAL KANNADA AND TELUGU DIGITS RECOGNITION DHANDRA B.V.1, GURURAJ MUKARAMBI1, MALLIKARJUN HANGARGE2 1Department of P.G. Studies and Research in Computer Science Gulbarga University, Gulbarga, Karnataka. 2Department of Computer Science, Karnatak Arts, Science and Commerce College Bidar, Karnataka. *Corresponding author. E-mail: [email protected],[email protected],[email protected] Received: September 29, 2011; Accepted: November 03, 2011 Abstract- In this paper, handwritten Kannada and Telugu digits recognition system is proposed based on zone features. The digit image is divided into 64 zones. For each zone, pixel density is computed. The KNN and SVM classifiers are employed to classify the Kannada and Telugu handwritten digits independently and achieved average recognition accuracy of 95.50%, 96.22% and 99.83%, 99.80% respectively. For bilingual digit recognition the KNN and SVM classifiers are used and achieved average recognition accuracy of 96.18%, 97.81% respectively. Keywords- OCR, Zone Features, KNN, SVM 1. Introduction recognition of isolated handwritten Kannada numerals Recent advances in Computer technology, made every and have reported the recognition accuracy of 90.50%. organization to implement the automatic processing Drawback of this procedure is that, it is not free from systems for its activities. For example, automatic thinning. U. Pal et al. [11] have proposed zoning and recognition of vehicle numbers, postal zip codes for directional chain code features and considered a feature sorting the mails, ID numbers, processing of bank vector of length 100 for handwritten Kannada numeral cheques etc. -
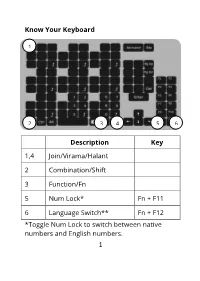
Know Your Keyboard Description Key 1,4 Join/Virama/Halant 2
Know Your Keyboard 1 2 3 4 5 6 Description Key 1,4 Join/Virama/Halant 2 Combination/Shift 3 Function/Fn 5 Num Lock* Fn + F11 6 Language Switch** Fn + F12 *Toggle Num Lock to switch between native numbers and English numbers. 1 ** Language Switch works on Windows, Linux and Android. For macOS, a configuration in settings is required. Note: If numbers are appearing in English, turn off Num Lock. Connecting Your Keyboard To Computer – Plug-in the cable to USB port on your computer. To Android Phone/Tablet 3 2 1 Use USB-to-OTG connector to plug-in keyboard. 2 Language and Layout You can use one keyboard to type multiple languages. You need to install at least one language to type. Language Layout Bengali Ka-Naada Bengali Keyboard Assamese Devanagari Sanskrit Hindi Ka-Naada Hindi Keyboard Marathi Neapli English Ka-Naada English Keyboard Guajarati Ka-Naada Guajarati Keyboard Kannada Ka-Naada Kannada Keyboard Malayalam Ka-Naada Malayalam Keyboard Tulu Odiya Ka-Naada Odiya Keyboard Panjabi Ka-Naada Gurmukhi Keyboard Telugu Ka-Naada Telugu Keyboard 3 Note: You need to switch to Ka-Naada input language before typing. Note: To switch between the languages you’re using, repeatedly press Language Switch key to cycle through all your installed languages. Language Pack Installation Go to https://ka-naada.com/downloads/ and click on the “Download” button in front of your operating system. Installation – Windows 1. Open your “Downloads” folder and locate “kanaada_keyboards.zip”. 2. Right click on zip file and choose “Extract Here” from the option menu. 3. -

Analysis of Comments for Telugu Script LGR Proposal for the Root Zone Revision: June 30, 2019
Neo-Brahmi Generation Panel: Analysis of comments for Telugu script LGR Proposal for the Root Zone Revision: June 30, 2019 Neo-Brahmi Generation Panel (NBGP) published the Telugu script LGR Propsoal for the Root Zone for public comment on 8 August 2018. This document is an additional document of the public comment report, collecting NBGP analyses as well as the concluded responses. There is 1 (one) comment submission. The analysis is as follow: No. 1 From Liang Hai Subject A Quick review of the Telugu proposal Comment 2, “telɯgɯ”: This is probably a phonetic transcription, not an accurate transliteration that should be used in this document. NBGP The NBGP acknowledges the comment. Analysis NBGP Updated the proposal in section 2 to use ‘Telugu’ Response Comment 3.5, “… and 16 dependent signs”: 15. NBGP There are 16 Matras: 14 Matras are in the repertoire, 2 Matras are Analysis excluded from the repertoire. NBGP No action required. Response Comment 3.5.1: Vocalic l should be categorized with vocalic rr and vocalic ll. Transliteration of vocalic ll is wrong. NBGP Agree. Analysis NBGP Update as suggested. Response 1 Comment 3.5.1, R1, “ca= a consonant with an inherent ‘a’”: When discussing text encoding, Indic consonants naturally are with an inherent vowel. Try to distinguish phonetic seQuence and written forms and encoded character sequence. The 3 lines under R1 are not helpful. NBGP The comment does not affect the normative part of the LGR. Analysis NBGP No action required. Response Comment 3.5.3: The introduction of arasunna usage is unclear. Is it commonly used today or not? NBGP The arsunna is not used frequently and it is not in the MSR.