Universal Dependencies Parsing for Colloquial Singaporean English
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-
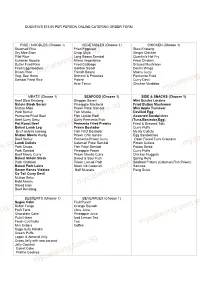
Menu Order Form
QUENTIN'S $15.00 PER PERSON ONLINE CATERING ORDER FORM RICE / NOODLES (Choose 1) VEGETABLES (Choose 1) CHICKEN (Choose 1) Steamed Rice Fried Eggplant Stew Kristang Dry Mee Siam Chap Chye Ginger Chicken Pilaf Rice Long Beans Sambal Quentin's Hot Fry Eurasian Noodle Mixed Vegetables Fried Chicken Butter Fried Rice Fried Cabbage Braised Mushroom Fried Egg Noodles Garden Salad Devil's Wings Bryani Rice French Beans Moeru Curry Veg. Bee Hoon Broccoli & Potatoes Permenta Fried Sambal Fried Rice Patchri Curry Devil Acar Timun Chicken Vindaloo MEATS (Choose 1) SEAFOOD (Choose 1) SIDE & SNACKS (Choose 1) Beef Stew Kristang Singgan Serani Mini Quiche Loraine Sirloin Steak Serani Pineapple Mackeral Fried Button Mushroom Mutton Miso Prawn Petai Sambal Mini Apple Turnover mycatering.com.sg Pork Semur mycatering.com.sg Fish Moolie Devilled Egg Permenta Fried Beef Fish Lemak Padi Assorted Sandwiches Beef Curry Seku Curry Permenta Fish (Tuna,Bostador,Egg) Pot Roast Beef Permenta Fried Prawns Fried & Dressed Tofu Baked Lamb Leg Prawn Bostador Curry Puffs Beef ambilla kacang Fish Fillet Bostador Meaty Cutlets Mutton Moeru Curry Prawn Chili Garam Egg Sandwiches Beef Semur Permenta Prawn Curry Open Faced Tuna Croutons Lamb Cutlets Calamari Petai Sambal Potato Cutlets Pork Chops Fish Petai Sambal Potato Salad Pork Sambal Pineapple Prawn Curry Puffs Beef Moeru Curry Prawn Moolie Curry Chicken Nuggets Baked Sirloin Steak Sweet & Sour Fish Spring Rolls Pork Vindaloo Prawn Lemak Padi Seafood Fritters (Calamari,Fish,Prawn) mycatering.com.sg Baked Pork Loins mycatering.com.sg -

Food Menu Dapur 2019.09
BREAKFAST MENU ALL DAY MENU ALL DAY MENU Served until 11am Main Course Dishes Comfort on a plate Continental Breakfast £7.50 Beef rendang £12.50 Soto Ayam Tanjung Puteri £10.50 A selection of bread, pastries and viennoiserie with a selection of jam and Slow cooked beef in a myriad of spices, infused with aromatics, Nasi Impit (compressed rice cubes) OR Bihun (rice vermicelli) in hearty, spiced spread. Unlimited amount of orange juice, tea & coffee enriched with creamy coconut milk and kerisik chicken broth served with shredded chicken, begedil, beansprouts, spring onion and fried shallots. Accompanied by fiery sambal kicap (soy sauce with chilli) on the side) Full Halal English Breakfast £10.90 Ayam Goreng Bawang Putih £9.00 Perfectly British, and HALAL. 2 rashers of turkey bacon, 2 sausages, a fried Chicken marinade in garlic and deep fried egg, 2 hash browns, beans, tomatoes and toasts. Bihun Sup Brisket £9.50 Bihun (rice vermicelli) soaked in beef broth laden with tender brisket slices, Seabass Tanjung Tualang £13.50 home made beef balls, garnished with choi sum, tofu pieces, fried shallot and Fried seabass doused in our homemade special sauce home made chilli oil. Sambal udang petai £11.50 Kari Laksa Majidee £10.50 Prawn sambal with stinky beans Mee/Bihun in our kari laksa broth served with puffed tofu, fishballs, chicken, ALL DAY MENU green beans, stuffed chilli and our home made chili sambal Broccoli Berlada [v] £6.50 Broccoli stir fried with garlic and chilli. Nasi Lemak Dapur £12.50 Starters Fluffy and creamy coconut rice infused with fragrant pandan leaves served with ayam goreng, beef rendang, sambal, boiled egg, cucumber slices, Beans and Taugeh goreng kicap [v] £6.50 fried peanuts and anchovies. -

Entrees Soups Hawker Style Noodles Malaysian
Entrees 32. Kari Ikan (Fish) ...................................................$16.90 Sliced fish fillet cooked with vegetables, coconut milk and selected spices Prawns and Sea Food Dishes 1. Satay Chicken or Beef (3 Sticks)..........................$8.50 33. Rendang Daging (Beef)......................................$16.90 55. King Prawns with Almonds or Cashews .............$18.90 2. Spring Rolls (6).....................................................$8.00 Selected diced meat cooked until tender with a fresh blend of spices 56. King Prawns with Chilli Sauce ............................$18.90 3. Homemade Dim Sim (Steamed or Fried) (6)........$8.90 and coconut milk 57. King Prawns with Black Bean Sauce .................$18.90 4. Prawn Dorsees (4) ...............................................$6.50 34. Sambal Udang (Prawns) ....................................$18.90 58. King Prawns with Satay Sauce ..........................$18.90 King Prawns cooked with a thick coconut creamy flavour 5. Curry Dorsees (6) .................................................$6.00 50. Curry King Prawns .............................................$18.90 35. Sambal Ikan (Fish) .............................................$16.90 6. Malaysian Curry Puff (3) .......................................$7.50 60. Honey King Prawns ............................................$18.90 7. Roti Canai (2) .....................................................$10.50 Sliced fish fillet cooked in Chef’s special spicy shirmp paste sauce 61. Sweet and Sour King Prawns.............................$18.90 -

Entree Beverages
Beverages Entree HOT/ COLD MOCKTAIL • Sambal Ikan Bilis Kacang $ 6 Spicy anchovies with peanuts $ 4.5 • Longing for Longan $ 7 • Teh Tarik longan, lychee jelly and lemon zest $ 4.5 • Kopi Tarik $ 7 • Spring Rolls $ 6.5 • Milo $ 4.5 • Rambutan Rocks rambutan, coconut jelly and rose syrup Vegetables wrapped in popia skin. (4 pieces) • Teh O $ 3.5 • Mango Madness $ 7 • Kopi O $ 3.5 mango, green apple and coconut jelly $ 6.5 • Tropical Crush $ 7 • Samosa pineapple, orange and lime zest Curry potato wrapped in popia skin. (5 pieces) COLD • Coconut Craze $ 7 coconut juice and pulp, with milk and vanilla ice cream • Satay $ 10 • 3 Layered Tea $ 6 black tea layered with palm sugar and Chicken or Beef skewers served with nasi impit (compressed rice), cucumber, evaporated milk onions and homemade peanut sauce. (4 sticks) • Root Beer Float $ 6 FRESH JUICE sarsaparilla with ice cream $ 10 $ 6 • Tauhu Sumbat • Soya Bean Cincau $5.5 • Apple Juice A popular street snack. Fresh crispy vegetables stuff in golden deep fried tofu. soya bean milk served with grass jelly • Orange Juice $ 6 • Teh O Ais Limau $ 5 • Carrot Juice $ 6 ice lemon tea $ 6 • Watermelon Juice $ 12 $ 5 • Kerabu Apple • freshAir Kelapa coconut juice Muda with pulp Crisp green apple salad tossed in mild sweet and sour dressing served with deep $ 5 fried chicken. • Sirap Bandung Muar rose syrup with milk and cream soda COFFEE $ 5 • Dinosaur Milo $ 12 malaysian favourite choco-malt drink • Beef Noodle Salad $ 4.5 Noodle salad tossed in mild sweet and sour dressing served with marinated beef. -
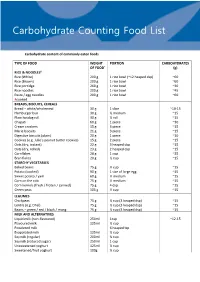
Carbohydrate Counting List
Tr45 Carbohydrate Counting Food List Carbohydrate content of commonly eaten foods TYPE OF FOOD WEIGHT PORTION CARBOHYDRATES OF FOOD* (g) RICE & NOODLES# Rice (White) 200 g 1 rice bowl (~12 heaped dsp) ~60 Rice (Brown) 200 g 1 rice bowl ~60 Rice porridge 260 g 1 rice bowl ~30 Rice noodles 200 g 1 rice bowl ~45 Pasta / egg noodles 200 g 1 rice bowl ~60 #cooked BREADS, BISCUITS, CEREALS Bread – white/wholemeal 30 g 1 slice ~10-15 Hamburger bun 30 g ½ medium ~15 Plain hotdog roll 30 g ½ roll ~15 Chapati 60 g 1 piece ~30 Cream crackers 15 g 3 piece ~15 Marie biscuits 21 g 3 piece ~15 Digestive biscuits (plain) 20 g 1 piece ~10 Cookies (e.g. Julie’s peanut butter cookies) 15 g 2 piece ~15 Oats (dry, instant) 22 g 3 heaped dsp ~15 Oats (dry, rolled) 23 g 2 heaped dsp ~15 Cornflakes 28 g 1 cup ~25 Bran flakes 20 g ½ cup ~15 STARCHY VEGETABLES Baked beans 75 g ⅓ cup ~15 Potato (cooked) 90 g 1 size of large egg ~15 Sweet potato / yam 60 g ½ medium ~15 Corn on the cob 75 g ½ medium ~15 Corn kernels (fresh / frozen / canned) 75 g 4 dsp ~15 Green peas 105 g ½ cup ~15 LEGUMES Chickpeas 75 g ½ cup (3 heaped dsp) ~15 Lentils (e.g. Dhal) 75 g ½ cup (3 heaped dsp) ~15 Beans – green / red / black / mung 75 g ½ cup (3 heaped dsp) ~15 MILK AND ALTERNATIVES Liquid milk (non-flavoured) 250ml 1cup ~12-15 Flavoured milk 125ml ½ cup Powdered milk 6 heaped tsp Evaporated milk 125ml ½ cup Soymilk (regular) 200ml ¾ cup Soymilk (reduced sugar) 250ml 1 cup Unsweetened yoghurt 125ml ½ cup Sweetened/fruit yoghurt 100g ⅓ cup TYPE OF FOOD WEIGHT PORTION CARBOHYDRATES OF -

Starters Sharing Plates Mains Noodle Bowls Rice Sides Vegetables
starters mains noodle bowls SOM TUM THAI 700 TOFU POCKETS WITH MANGO 1250 CHAR KWAY TEOW 1650 Young papaya salad with chilli, dried shrimp and a fresh lime dressing ‘Tauhu Bakar’ I grilled tofu with mango salad and spicy sauce Homemade flat rice noodles stir fried with prawns, pork, squid, light & dark soya sauce, chilli and bean sprouts VIETNAMESE DUCK & LYCHEE SALAD 1150 GOLDEN FRAGRANT PRAWNS 1650 Pan fried duck breast with raw onion, zucchini, cherry tomato ‘Kam Heong’ I a signature Malaysian stir-fry renowned for its fragrance PHAD THAI 1600 and lychee tossed with hoisin BBQ sauce Stir-fried flat rice noodles with prawns, tofu, egg, peanut, chilli and bean sprouts BAKED ASIAN SEA BASS 1450 GADO GADO BALI 700 ‘Ikan Bakar Pedas’ I Malay baked Asian sea bass with spicy chilli sauce BAMI GORENG 1400 Indonesian style fried egg noodles with chicken and vegetables Indonesian salad with cucumber, bean sprouts, potatoes, THAI BARRAMUNDI 1450 tofu and rice crackers with peanut sauce ‘Pla Nueng Ma Nao’ I steamed barramundi with lime, garlic, CHICKEN & SEAFOOD LAKSA 1650 TUNA CEVICHE 850 coriander, chilli and pineapple ‘Nyonya Melaka Laksa’ I spicy coconut soup with egg noodles, chicken, prawns, egg, fish cake, tofu and bean sprouts ‘Gohu Ikan Maluku’ I marinated Ternate style tuna with THAI GREEN CURRY virgin coconut oil, lime, pomelo and toasted cashew nuts Chicken 1450 Prawn 1550 Vegetable 1300 SINGAPORE SIAMESE NOODLES 1500 CRISPY CHILLI BEEF 1050 Authentic Thai style curry cooked in freshly blended spices, ‘Mee Siam’ I a spicy fried rice vermicelli -
Beef Haw Fun 11 Chicken Lo Mein 9 Yaki Udon 10 Pad Thai
CHARLOTTE, NC Rip.Rip. Dip.Dip. Repeat.Repeat. TwoTwo MalaysianMalaysian flatbreads,flatbreads, servedserved withwith aa sideside ofof ourour signaturesignature currycurry sauce.sauce. 55 Korean Twice Fried Wings 8.5 Sauced in garlic gochujang and topped with peanuts, sesame and cilantro. Hawkers Wings 7.5 BATTERED or NAKED Choice of sauce: sweet thai chili, hainanese , honey sriracha , spring onion ginger or rub: five-spice, chuan jerk Sichuan Wontons 8 Yi-Yi’s Chicken Dumplings 7 Our Auntie’s classic recipe hand-rolled daily, wok-seared or steamed, served with a sweet soy dipping sauce. Golden Wontons 7.5 Hand-made daily filled with chicken, shrimp and mushrooms, fried to a crisp and served with a sweet chili dipping sauce. Char Siu 8 Pork shoulder, sweet soy, spring onions Crispy Tofu Bites 6 Edamame 4 add chili and garlic 1 Hawker’s Delight 7 Saucy blend of wok-seared tofu, broccoli, carrots, napa (pro tip: the cabbage, not the city), bell peppers, shiitake and straw mushrooms Five-Spice Green Beans 6 Lightly battered, fried to a crisp, tossed in our signature five-spice seasoning Chow Faan 9 Classic fried rice packed with chicken, shrimp, char siu, eggs, onions and soy sauce. Basil Fried Rice 7 An herbal take on a classic fave. Eggs, onions, fresh basil and soy sauce. Po Po Lo’s Curry 10 Our hearty family recipe that has been shared for generations with veggies, rice and your choice of: CHICKEN / BEEF / TOFU Jasmine Rice 2 Beef Haw Fun 11 Hey, wok hei! Savory wide rice noodles, sliced steak, green onions, bean sprouts, onions and soy sauce Hokkien Mee 11 Egg noodles mixed with shrimp, sliced chicken and char siu, wok-seared with veggies in a dark soy sauce. -

Bank Kalori.Pdf
i) BUKAN VEGETARIAN NASI, MI, BIHUN,KUETIAU DAN LAIN- LAIN Makanan Hidangan Berat (g) Kalori (kcal) Rujukan Bihun bandung 1 mangkuk 450 490 NC Bihun goreng 2 senduk 150 260 NC Bihun goreng ala Cina 2 senduk 150 240 NP Bihun goreng putih 2 senduk 120 200 NP Bihun hailam + sayur + ayam 1 mangkuk 250 350 NP Bihun kantonis + sayur + ayam 1 pinggan 280 430 NP Bihun kari + sayur + ayam 1 mangkuk 250 330 NP Bihun latna + sayur + ayam 1 mangkuk 250 380 NP Bihun rebus + sayur + ½ biji telur rebus 1 mangkuk 250 310 NP Bihun Soto 1 mangkuk cina 130 50 NP NC Bihun sup + sayur + hirisan ayam 1 mangkuk 250 150 (perkadar an) Bihun tom yam + sayur + ayam 1 mangkuk 250 230 NP braised egg noodles Szechuan style 1 senduk 50 90 Bubur ayam Atlas + (2 sudu makan ayam + 2 sudu makan lobak 1 mangkuk 250 150 NC merah) Bubur daging Atlas + (2 sudu makan daging + 2 sudu makan lobak 1 mangkuk 250 150 NC merah) Bubur ikan Atlas + (1 sudu makan ikan merah + 2 sudu makan 1 mangkuk 250 110 NC lobak merah) Bubur nasi (kosong) 1 cawan 170 70 Atlas Chap chye 1 senduk 60 50 NP Char kuetiau 2 senduk 120 230 NP Fried cintan noodle 1 senduk 60 100 Ketupat nasi 5 potong 200 215 NP Kuetiau bandung 1 mangkuk 320 380 NC Kuetiau goreng 2 senduk 150 280 NC Kuetiau hailam + sayur + ayam 1 mangkuk 250 380 NP Kuetiau kantonis + sayur + ayam 1 pinggan 280 410 NP Kuetiau kari + sayur + ayam 1 mangkuk 250 320 NP Kuetiau latna + sayur + ayam 1 mangkuk 250 320 NP NC Kuetiau sup 1 mangkuk 320 180 (perkadar an) Kuetiau tom yam + sayur + ayam 1 mangkuk 250 210 NP Laksa + sayur + ½ biji telur -

Appetizers & Vegetables
APPETIZERS & VEGETABLES APPETIZERS & VEGETABLES Roti Prata with Curry Sauce Indian. Vegetarian. Grilled Indian style multi-layered bread. Served with vegetarian curry … $8.50 5-Spice Roll Chinese. Minced pork, prawns, jicama, carrot, eggs, scallion, five-spices, wrapped in bean curd … $16.00 Sayor Lodeh Malay. Vegan. Carrot, jicama, cabbage, string beans, tofu, cooked in a yellow curry broth. $12.00 Lettuce Cup Fresh scallops, celery, carrot, shiitake mushrooms, sweet pepper, pine nuts, fried in orange flavored … $13.00 Shiok! Salad Chinese. Vegan. Carrot, jicama, lettuce, pickled papaya, topped with toasted sesame seed, peanu… $15.00 Veggie Stir-Fry Chinese. Vegan. Bok choy, mushroom, carrot, tofu, stir-fried in vegetarian sauce. $13.00 Sambal String Beans Malay. String beans sauteed with fresh chili spices and dried shrimp. Vegan available. Page 1 APPETIZERS & VEGETABLES $13.00 Assam Aubergine Malay. Vegetarian. Grilled eggplant topped with hot and sour tamarind sauce. $17.00 Tahu Goreng Malay. Vegetarian. Lightly fried tofu topped with cucumber, jicama and bean sprout with a sweet p… $16.00 Crispy Tofu Chinese. Vegan, Crispy tofu topped with fresh shiitake mushrooms, carrots and scallion sauce. $13.00 Sambal Kangkong or Okra Kangkong or okra stir-fried with dried shrimp, chili-garlic sauce. Vegan available. $17.00 SOUP, NOODLES & RICE Shiok! Soup Chinese. Non-vegetarian. Choice of chicken, seafood or vegetable in clear chicken broth. $15.00 Hokkien Mee Chinese. Yellow noodle, vermicelli, prawns, calamari, chive, bean sprouts, eggs, wok-fried in c… $14.00 Hor Fun Page 2 APPETIZERS & VEGETABLES Chinese. Broad rice noodle, vegetable, and choice of seafood, beef or chicken, stir-fried in rich stock… $14.00 Laksa Chinese. -

Have Your Favourite Hawker Foods and Eat It - Guilt-Free
Have Your Favourite Hawker Foods and Eat It - Guilt-Free Saturday, Jul 12, 2014 Men's Health By Justin Harper SINGAPORE - Breakfast is the most important meal of the day for a reason. Get it right and you will jump-start your day with energy. Get it wrong and you will achieve very little, apart from an expanded waistline. "Some of our local dishes are the worst foods you can eat, especially the first thing in the morning," says Jab Wan, nutrition advisor and managing director of Integrated Training Institute. But you don't have to trade your nasi lemak for bland oatmeal. These five choices - one or two may even surprise you - will kick-start your day without leaving your taste buds out in the cold. Mee siam Don't be put off by the amount of calories (694kcal) and carbohydrates (91g) this dish contains. Rice vermicelli (bee hoon) - the noodle used in mee siam - is considered a medium GI food with a glycemic index of 58, meaning it won't drastically spike your blood sugar levels. Another way to make this Malay dish healthier is to leave half the noodles unfinished, and slurp up less of the oily and sodium-laden gravy, which will help bring the calorie count to below 450kcal, advises clinical dietician Jaclyn Reutens. In terms of Malay cuisine, mee siam is also healthier than its more robust sibling, mee rebus. The good news: You don't have to pass up on the hard-boiled egg and tofu. Together, they may provide up to 20g of protein. -

No. Stall Name Food Categories Address
No. Stall Name Food Categories Address Chi Le Ma 505 Beach Road #01-87, 1 吃了吗 Seafood Golden Mile Food Center 307 Changi Road, 2 Katong Laksa Laksa Singapore 419785 Duck / Goose (Stewed) Rice, Porridge & 168 Lor 1 Toa Payoh #01-1040, 3 Benson Salted Duck Rice Noodles Maxim Coffee Shop 4 Kampung Kia Blue Pea Nasi Lemak Nasi Lemak 10 Sengkang Square #01-26 5 Sin Huat Seafood Crab Bee Hoon 659 Lorong 35 Geylang 6 Hoy Yong Seafood Restaurant Cze Cha 352 Clementi Ave 2, #01-153 Haig Road Market and Food Centre, 13, #01-36 7 Chef Chik Cze Cha Haig Road 505 Beach Road #B1-30, 8 Charlie's Peranakan Food Eurasian / Peranakan / Nonya Golden Mile Food Centre Sean Kee Duck Rice or Duck / Goose (Stewed) Rice, Porridge & 9 Sia Kee Duck Rice Noodles 659-661Lor Lor 35 Geylang 665 Buffalo Rd #01-326, 10 545 Whampoa Prawn Noodles Prawn Mee / Noodle Tekka Mkt & Food Ctr 466 Crawford Lane #01-12, 11 Hill Street Tai Hwa Pork Noodle Bak Chor Mee Tai Hwa Eating House High Street Tai Wah Pork Noodle 531A Upper Cross St #02-16, Hong Lim Market & 12 大崋肉脞麵 Bak Chor Mee Food Centre 505 Beach Road #B1-49, 13 Kopi More Coffee Golden Mile Food Centre Hainan Fried Hokkien Prawn Mee 505 Beach Road #B1-34, 14 海南福建炒虾麵 Fried Hokkien Mee Golden Mile Food Centre 505 Beach Road #B1-21, 15 Longhouse Lim Kee Beef Noodles Beef Noodle Golden Mile Food Centre 505 Beach Road #01-73, 16 Yew Chuan Claypot Rice Claypot Rice Golden Mile Food Centre Da Po Curry Chicken Noodle 505 Beach Road #B1-53, 17 大坡咖喱鸡面 Curry Mee / Noodles Golden Mile Food Centre Heng Kee Curry Chicken Noodle 531A -

Daftar Produk Halal
Dunia Daging KELOMPOK DAGING DAN PRODUK DAGING OLAHAN Fronte : Vegetable Chicken Sausage, Fronte : 00010013540900 141213 Food Industries, November - Desember 2012 Beef Frankfurter, Fronte : Chicken Frankfurter, PT Nama Produk Sertifikat Exp Produsen Fronte : Blackpepper Beef Sausage Reguler, Fronte : Breakfast Beef Sausage, Fronte : Beef Frankfurter Kibif Rolade Sapi, Kibif Rolade Sapi (wet mar- Bina Mentari Skinless, Fronte : Chicken Frankfruter Skinless, Fronte : Sosis Ayam (Chicken Chipolata), Fronte : Sosis ket), Kibif Beef Salami, Kibif Daging Sapi Lada ‘00010060390212 010214 Tunggal, PT Sapi (Beef Bockwurst), Fronte : Cheesy Beef Sausage, Fronte : Blackpepper Beef Sausage, Fronte : Hitam, Kibif Sosis Sapi, Kibif Sosis Sapi Chicken Luncheon (wet market), Kibif Beef Pepperoni, Kibif Nugget Sapi, Kibif Bakso Sapi WK, Kibif Bakso Sapi WM, Kibif Dunia Daging Meat Ball Super, Kibif Bakso Halus, Kibif Beef Patties, Kibif Burger Patties Black Pepper, Kibif Beef Burger Fronte : Beef Lucheon, Fronte : Galapeno Beef 00010013540900 141213 Food Industries, Bulgogi, Kibif Burger Daging Sapi Sasage, Fronte : Roast Beef, Fronte : Beef PT Kerupuk Ikan Lele, Fish Cookies (Kerupuk 00100062720912 250914 Mina Sejahtera Coctail, Fronte : Sosis sapi Asap, Fronte : Veal Bratwurst, Fronte : Corn Beef sausage, Fronte : Garlic Beef Ikan Lele) Sausage, Fronte : Paprica Beef Sausage, Fronte : Beef Pastrami, Fronte : Beef Pepperoni, Fronte : Beef MARINADE, MRND CHICKEN STEAK , SPICY Frozen Food Salami WING , MRND SIRLOIN STEAK , SPICY WING ‘00010043750307 110414