Efficient Execution of the MD5 Algorithm in Password Recovery
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Intro to Cryptography 1 Introduction 2 Secure Password Manager
Programming Assignment 1 Winter 2021 CS 255: Intro to Cryptography Prof. Dan Boneh Due Monday, Feb. 8, 11:59pm 1 Introduction In many software systems today, the primary weakness often lies in the user’s password. This is especially apparent in light of recent security breaches that have highlighted some of the weak passwords people commonly use (e.g., 123456 or password). It is very important, then, that users choose strong passwords (or “passphrases”) to secure their accounts, but strong passwords can be long and unwieldy. Even more problematic, the user generally has many different services that use password authentication, and as a result, the user has to recall many different passwords. One way for users to address this problem is to use a password manager, such as LastPass and KeePass. Password managers make it very convenient for users to use a unique, strong password for each service that requires password authentication. However, given the sensitivity of the data contained in the password manager, it takes considerable care to store the information securely. In this assignment, you will be writing a secure and efficient password manager. In your implemen- tation, you will make use of various cryptographic primitives we have discussed in class—notably, authenticated encryption and collision-resistant hash functions. Because it is ill-advised to imple- ment your own primitives in cryptography, you should use an established library: in this case, the Stanford Javascript Crypto Library (SJCL). We will provide starter code that contains a basic tem- plate, which you will be able to fill in to satisfy the functionality and security properties described below. -

User Authentication and Cryptographic Primitives
User Authentication and Cryptographic Primitives Brad Karp UCL Computer Science CS GZ03 / M030 16th November 2016 Outline • Authenticating users – Local users: hashed passwords – Remote users: s/key – Unexpected covert channel: the Tenex password- guessing attack • Symmetric-key-cryptography • Public-key cryptography usage model • RSA algorithm for public-key cryptography – Number theory background – Algorithm definition 2 Dictionary Attack on Hashed Password Databases • Suppose hacker obtains copy of password file (until recently, world-readable on UNIX) • Compute H(x) for 50K common words • String compare resulting hashed words against passwords in file • Learn all users’ passwords that are common English words after only 50K computations of H(x)! • Same hashed dictionary works on all password files in world! 3 Salted Password Hashes • Generate a random string of bytes, r • For user password x, store [H(r,x), r] in password file • Result: same password produces different result on every machine – So must see password file before can hash dictionary – …and single hashed dictionary won’t work for multiple hosts • Modern UNIX: password hashes salted; hashed password database readable only by root 4 Salted Password Hashes • Generate a random string of bytes, r Dictionary• For user password attack still x, store possible [H(r,x after), r] in attacker seespassword password file file! Users• Result: should same pick password passwords produces that different aren’t result close to ondictionary every machine words. – So must see password file -

To Change Your Ud Password(S)
TO CHANGE YOUR UD PASSWORD(S) The MyCampus portal allows the user a single-signon for campus applications. IMPORTANT NOTICE AT BOTTOM OF THESE INSTRUCTIONS !! INITIAL PROCEDURE TO ALLOW YOU TO CHANGE YOUR PASSWORD ON THE UD NETWORK : 1. In your web browser, enter http://mycampus.dbq.edu . If you are logging in for the first time, you will be directed to answer (3) security questions. Also, be sure to answer one of the recovery methods. 2. Once the questions are answered, you will click on SUBMIT and then CONTINUE and then YES. 3. In one location, you will now find MyUD, Campus Portal, Email and UDOnline (Moodle). 4. You can now click on any of these apps and you will be logged in already. The email link will prompt you for the password a second time until we get all accounts set up properly. YOU MUST BE SURE TO LOGOUT OF EACH APPLICATION AFTER YOU’RE DONE USING IT !! TO CHANGE YOUR PASSWORD: 1. After you have logged into the MyCampus.dbq.edu website, you will see your username in the upper- right corner of the screen. 2. Click on your name and then go into My Account. 3. At the bottom, you will click on Change Password and then proceed as directed. 4. You can now logout. You will need to use your new password on your next login. Password must be a minimum of 6 characters and contain 3 of the following 4 categories: - Uppercase character - Lowercase character - Number - Special character You cannot use the previous password You’ll be required to change your password every 180 days. -
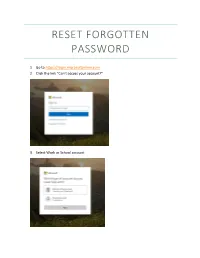
Reset Forgotten Password with Office365
RESET FORGOTTEN PASSWORD 1. Go to https://login.microsoftonline.com 2. Click the link “Can’t access your account?” 3. Select Work or School account 4. Enter in your User ID with the @uamont.edu at the end and then enter the characters as seen in the picture. You can click the refresh button for a different set of letters. 5. You will have 3 options to verify your account and reset your password. This information was set up when you registered with self-service password reset. If you have not registered, please go to https://aka.ms/ssprsetup and enter in your information. A step by step guide on how to do this can be found here. a. Text your mobile phone b. Call your mobile phone c. Answer Security Questions 6. Choose one option and enter the information requested 7. Click Text for text my mobile phone, Call for call my mobile phone, or click Next when you’ve answered all security questions. a. If you have selected Text my mobile phone you will be required to enter in a verification code and click Next b. If you have select Call my mobile phone you will receive a call and will need to enter # to verify. 8. Enter in your new password and click Finish a. Note: If you receive the message, “Unfortunately, your password contains a word, phrase, or pattern that makes it easily guessable. Please try again with a different password.” Please try to create a password that does not use any dictionary words. b. Passwords must meet 3 of the 4 following requirements i. -

Optimizing a Password Hashing Function with Hardware-Accelerated Symmetric Encryption
S S symmetry Article Optimizing a Password Hashing Function with Hardware-Accelerated Symmetric Encryption Rafael Álvarez 1,* , Alicia Andrade 2 and Antonio Zamora 3 1 Departamento de Ciencia de la Computación e Inteligencia Artificial (DCCIA), Universidad de Alicante, 03690 Alicante, Spain 2 Fac. Ingeniería, Ciencias Físicas y Matemática, Universidad Central, Quito 170129, Ecuador; [email protected] 3 Departamento de Ciencia de la Computación e Inteligencia Artificial (DCCIA), Universidad de Alicante, 03690 Alicante, Spain; [email protected] * Correspondence: [email protected] Received: 2 November 2018; Accepted: 22 November 2018; Published: 3 December 2018 Abstract: Password-based key derivation functions (PBKDFs) are commonly used to transform user passwords into keys for symmetric encryption, as well as for user authentication, password hashing, and preventing attacks based on custom hardware. We propose two optimized alternatives that enhance the performance of a previously published PBKDF. This design is based on (1) employing a symmetric cipher, the Advanced Encryption Standard (AES), as a pseudo-random generator and (2) taking advantage of the support for the hardware acceleration for AES that is available on many common platforms in order to mitigate common attacks to password-based user authentication systems. We also analyze their security characteristics, establishing that they are equivalent to the security of the core primitive (AES), and we compare their performance with well-known PBKDF algorithms, such as Scrypt and Argon2, with favorable results. Keywords: symmetric; encryption; password; hash; cryptography; PBKDF 1. Introduction Key derivation functions are employed to obtain one or more keys from a master secret. This is especially useful in the case of user passwords, which can be of arbitrary length and are unsuitable to be used directly as fixed-size cipher keys, so, there must be a process for converting passwords into secret keys. -

Strong Password-Based Authentication in TLS Using the Three-Party Group Diffie–Hellman Protocol
284 Int. J. Security and Networks, Vol. 2, Nos. 3/4, 2007 Strong password-based authentication in TLS using the three-party group Diffie–Hellman protocol Michel Abdalla* École normale supérieure – CNRS, LIENS, Paris, France E-mail: [email protected] *Corresponding author Emmanuel Bresson Department of Cryptology, CELAR Technology Center, Bruz, France E-mail: [email protected] Olivier Chevassut Lawrence Berkeley National Laboratory, Berkeley, CA, USA E-mail: [email protected] Bodo Möller Horst Görtz Institute for IT Security, Ruhr-Universität Bochum, Bochum, Germany E-mail: [email protected] David Pointcheval École normale supérieure – CNRS, LIENS, Paris, France E-mail: [email protected] Abstract: The internet has evolved into a very hostile ecosystem where ‘phishing’ attacks are common practice. This paper shows that the three-party group Diffie-Hellman key exchange can help protect against these attacks. We have developed password-based ciphersuites for the Transport Layer Security (TLS) protocol that are not only provably secure but also believed to be free from patent and licensing restrictions based on an analysis of relevant patents in the area. Keywords: password authentication; group Diffie–Hellman key exchange; transport layer security; TLS. Reference to this paper should be made as follows: Abdalla, M., Bresson, E., Chevassut, O., Möller, B. and Pointcheval, D. (2007) ‘Strong password-based authentication in TLS using the three-party group Diffie-Hellman protocol’, Int. J. Security and Networks, Vol. 2, Nos. 3/4, pp.284–296. Biographical notes: Michel Abdalla is currently a Researcher with the Centre National de la Recherche Scientifique (CNRS), France and a Member of the Cryptography Team at the Ecole Normale Supérieure (ENS), France. -

Password Cracking
Password Cracking Sam Martin and Mark Tokutomi 1 Introduction Passwords are a system designed to provide authentication. There are many different ways to authenticate users of a system: a user can present a physical object like a key card, prove identity using a personal characteristic like a fingerprint, or use something that only the user knows. In contrast to the other approaches listed, a primary benefit of using authentication through a pass- word is that in the event that your password becomes compromised it can be easily changed. This paper will discuss what password cracking is, techniques for password cracking when an attacker has the ability to attempt to log in to the system using a user name and password pair, techniques for when an attacker has access to however passwords are stored on the system, attacks involve observing password entry in some way and finally how graphical passwords and graphical password cracks work. Figure 1: The flow of password attacking possibilities. Figure 1 shows some scenarios attempts at password cracking can occur. The attacker can gain access to a machine through physical or remote access. The user could attempt to try each possible password or likely password (a form of dictionary attack). If the attack can gain access to hashes of the passwords it is possible to use software like OphCrack which utilizes Rainbow Tables to crack passwords[1]. A spammer may use dictionary attacks to gain access to bank accounts or other 1 web services as well. Wireless protocols are vulnerable to some password cracking techniques when packet sniffers are able to gain initialization packets. -

Modified SHA1: a Hashing Solution to Secure Web Applications Through Login Authentication
36 International Journal of Communication Networks and Information Security (IJCNIS) Vol. 11, No. 1, April 2019 Modified SHA1: A Hashing Solution to Secure Web Applications through Login Authentication Esmael V. Maliberan Graduate Studies, Surigao del Sur State University, Philippines Abstract: The modified SHA1 algorithm has been developed by attack against the SHA-1 hash function, generating two expanding its hash value up to 1280 bits from the original size of different PDF files. The research study conducted by [9] 160 bit. This was done by allocating 32 buffer registers for presented a specific freestart identical pair for SHA-1, i.e. a variables A, B, C and D at 5 bytes each. The expansion was done by collision within its compression function. This was the first generating 4 buffer registers in every round inside the compression appropriate break of the SHA-1, extending all 80 out of 80 function for 8 times. Findings revealed that the hash value of the steps. This attack was performed for only 10 days of modified algorithm was not cracked or hacked during the experiment and testing using powerful online cracking tool, brute computation on a 64-GPU. Thus, SHA1 algorithm is not force and rainbow table such as Cracking Station and Rainbow anymore safe in login authentication and data transfer. For Crack and bruteforcer which are available online thus improved its this reason, there were enhancements and modifications security level compared to the original SHA1. being developed in the algorithm in order to solve these issues [10, 11]. [12] proposed a new approach to enhance Keywords: SHA1, hashing, client-server communication, MD5 algorithm combined with SHA compression function modified SHA1, hacking, brute force, rainbow table that produced a 256-bit hash code. -

Rootkits for Javascript Environments
Rootkits for JavaScript Environments Ben Adida Adam Barth Collin Jackson Harvard University UC Berkeley Stanford University ben [email protected] [email protected] [email protected] Abstract Web Site Bookmarklet Web Site Bookmarklet A number of commercial cloud-based password managers use bookmarklets to automatically populate and submit login forms. Unfortunately, an attacker web Native JavaScript environment site can maliciously alter the JavaScript environment and, when the login bookmarklet is invoked, steal the Figure 1. Developers assume the bookmarklet in- user’s passwords. We describe general attack tech- teracts with the native JavaScript environment directly niques for altering a bookmarklet’s JavaScript envi- (left). In fact, the bookmarklet’s environment can be ronment and apply them to extracting passwords from manipulated by the current web page (right). six commercial password managers. Our proposed solution has been adopted by several of the commercial vendors. If the user clicks a bookmarklet while visiting an untrusted web page, the bookmarklet’s JavaScript is run in the context of the malicious page, potentially 1. Introduction letting an attacker manipulate its execution by care- fully crafting its JavaScript environment, essentially One promising direction for building engaging web installing a “rootkit” in its own JavaScript environment experiences is to combine content and functionality (See Figure 1). Instead of interacting with the native from multiple sources, often called a “mashup.” In JavaScript objects, the bookmarklet interacts with the a traditional mashup, an integrator combines gadgets attacker’s objects. This attack vector is not much of (such as advertisements [1], maps [2], or contact a concern for Delicious’ social bookmarking service, lists [3]), but an increasingly popular mashup design because the site’s own interests are served by advertis- involves the user adding a bookmarklet [4] (also known ing its true location and title. -

A Survey of Password Attacks and Safe Hashing Algorithms
International Research Journal of Engineering and Technology (IRJET) e-ISSN: 2395-0056 Volume: 04 Issue: 12 | Dec-2017 www.irjet.net p-ISSN: 2395-0072 A Survey of Password Attacks and Safe Hashing Algorithms Tejaswini Bhorkar Student, Dept. of Computer Science and Engineering, RGCER, Nagpur, Maharashtra, India ---------------------------------------------------------------------***--------------------------------------------------------------------- Abstract - To authenticate users, most web services use pair of message that would generate the same hash as that of the username and password. When a user wish to login to a web first message. Thus, the hash function should be resistant to application of the service, he/she sends their user name and second-pre-image. password to the web server, which checks if the given username already exist in the database and that the password is identical to 1.2 Hashing Algorithms the password set by that user. This last step of verifying the password of the user can be performed in different ways. The user Different hash algorithms are used in order to generate hash password may be directly stored in the database or the hash value values. Some commonly used hash functions include the of the password may be stored. This survey will include the study following: of password hashing. It will also include the need of password hashing, algorithms used for password hashing along with the attacks possible on the same. • MD5 • SHA-1 Key Words: Password, Hashing, Algorithms, bcrypt, scrypt, • SHA-2 attacks, SHA-1 • SHA-3 1.INTRODUCTION MD5: Web servers store the username and password of its users to authenticate its users. If the web servers store the passwords of This algorithm takes data of arbitrary length and produces its users directly in the database, then in such case, password message digest of 128 bits (i.e. -

Transport Layer Security Protocol for Spwfxxx Module
AN4683 Application note Transport layer security protocol for SPWFxxx module Introduction The purpose of this document is to present a demonstration package for creating a secure connection over TCP/IP between the Wi-Fi module SPWF01Sxxx (see [1] in References )and a remote server exposing secured service. Security is provided by the secure sockets layer (SSL) and transport layer security (TLS) protocols. The SSL/TLS protocols provide security for communication over networks, such as the Internet, and allow client and server applications to communicate in a way that is confidential and secure. The document includes a brief introduction to SSL/TLS principles, a description of the demonstration package organization and a tutorial with client-server connection examples. May 2015 DocID027745 Rev 1 1/31 www.st.com 31 Contents AN4683 Contents 1 SSL/TLS protocol overview . 4 1.1 SSL/TLS sub-protocols . 5 1.1.1 Handshake protocol . 5 1.1.2 Change cipher spec protocol . 7 1.1.3 Alert protocol . 7 1.1.4 Record protocol . 7 1.2 Authentication and certificates . 7 2 SPWF01Sxxx use modes . 11 2.1 TLS protocol . .11 2.2 Supported ciphers list . .11 2.3 Domain name check for server certificate . 12 2.4 Authentication . 12 2.4.1 Anonymous negotiation . 12 2.4.2 One-way authentication . 13 2.4.3 Mutual authentication . 14 2.5 Protocol version downgrade . 16 2.6 Pseudo random number generator . 16 3 Demonstration package . 17 3.1 Package directories . 17 3.2 Wi-Fi module setup . 18 3.3 Example 1: TLS Client with mutual authentication . -

Just in Time Hashing
Just in Time Hashing Benjamin Harsha Jeremiah Blocki Purdue University Purdue University West Lafayette, Indiana West Lafayette, Indiana Email: [email protected] Email: [email protected] Abstract—In the past few years billions of user passwords prove and as many users continue to select low-entropy have been exposed to the threat of offline cracking attempts. passwords, finding it too difficult to memorize multiple Such brute-force cracking attempts are increasingly dangerous strong passwords for each of their accounts. Key stretching as password cracking hardware continues to improve and as serves as a last line of defense for users after a password users continue to select low entropy passwords. Key-stretching breach. The basic idea is to increase guessing costs for the techniques such as hash iteration and memory hard functions attacker by performing hash iteration (e.g., BCRYPT[75] can help to mitigate the risk, but increased key-stretching effort or PBKDF2 [59]) or by intentionally using a password necessarily increases authentication delay so this defense is hash function that is memory hard (e.g., SCRYPT [74, 74], fundamentally constrained by usability concerns. We intro- Argon2 [12]). duce Just in Time Hashing (JIT), a client side key-stretching Unfortunately, there is an inherent security/usability algorithm to protect user passwords against offline brute-force trade-off when adopting traditional key-stretching algo- cracking attempts without increasing delay for the user. The rithms such as PBKDF2, SCRYPT or Argon2. If the key- basic idea is to exploit idle time while the user is typing in stretching algorithm cannot be computed quickly then we their password to perform extra key-stretching.