Design and Analysis of Password-Based Key Derivation Functions
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

GPU-Based Password Cracking on the Security of Password Hashing Schemes Regarding Advances in Graphics Processing Units
Radboud University Nijmegen Faculty of Science Kerckhoffs Institute Master of Science Thesis GPU-based Password Cracking On the Security of Password Hashing Schemes regarding Advances in Graphics Processing Units by Martijn Sprengers [email protected] Supervisors: Dr. L. Batina (Radboud University Nijmegen) Ir. S. Hegt (KPMG IT Advisory) Ir. P. Ceelen (KPMG IT Advisory) Thesis number: 646 Final Version Abstract Since users rely on passwords to authenticate themselves to computer systems, ad- versaries attempt to recover those passwords. To prevent such a recovery, various password hashing schemes can be used to store passwords securely. However, recent advances in the graphics processing unit (GPU) hardware challenge the way we have to look at secure password storage. GPU's have proven to be suitable for crypto- graphic operations and provide a significant speedup in performance compared to traditional central processing units (CPU's). This research focuses on the security requirements and properties of prevalent pass- word hashing schemes. Moreover, we present a proof of concept that launches an exhaustive search attack on the MD5-crypt password hashing scheme using modern GPU's. We show that it is possible to achieve a performance of 880 000 hashes per second, using different optimization techniques. Therefore our implementation, executed on a typical GPU, is more than 30 times faster than equally priced CPU hardware. With this performance increase, `complex' passwords with a length of 8 characters are now becoming feasible to crack. In addition, we show that between 50% and 80% of the passwords in a leaked database could be recovered within 2 months of computation time on one Nvidia GeForce 295 GTX. -

Reconsidering the Security Bound of AES-GCM-SIV
Background on AES-GCM-SIV Fixing the Security Bound Improving Key Derivation Final Remarks Reconsidering the Security Bound of AES-GCM-SIV Tetsu Iwata1 and Yannick Seurin2 1Nagoya University, Japan 2ANSSI, France March 7, 2018 — FSE 2018 T. Iwata and Y. Seurin Reconsidering AES-GCM-SIV’s Security FSE 2018 1 / 26 Background on AES-GCM-SIV Fixing the Security Bound Improving Key Derivation Final Remarks Summary of the contribution • we reconsider the security of the AEAD scheme AES-GCM-SIV designed by Gueron, Langley, and Lindell • we identify flaws in the designers’ security analysis and propose a new security proof • our findings leads to significantly reduced security claims, especially for long messages • we propose a simple modification to the scheme (key derivation function) improving security without efficiency loss T. Iwata and Y. Seurin Reconsidering AES-GCM-SIV’s Security FSE 2018 2 / 26 Background on AES-GCM-SIV Fixing the Security Bound Improving Key Derivation Final Remarks Summary of the contribution • we reconsider the security of the AEAD scheme AES-GCM-SIV designed by Gueron, Langley, and Lindell • we identify flaws in the designers’ security analysis and propose a new security proof • our findings leads to significantly reduced security claims, especially for long messages • we propose a simple modification to the scheme (key derivation function) improving security without efficiency loss T. Iwata and Y. Seurin Reconsidering AES-GCM-SIV’s Security FSE 2018 2 / 26 Background on AES-GCM-SIV Fixing the Security Bound Improving Key Derivation Final Remarks Summary of the contribution • we reconsider the security of the AEAD scheme AES-GCM-SIV designed by Gueron, Langley, and Lindell • we identify flaws in the designers’ security analysis and propose a new security proof • our findings leads to significantly reduced security claims, especially for long messages • we propose a simple modification to the scheme (key derivation function) improving security without efficiency loss T. -

Intro to Cryptography 1 Introduction 2 Secure Password Manager
Programming Assignment 1 Winter 2021 CS 255: Intro to Cryptography Prof. Dan Boneh Due Monday, Feb. 8, 11:59pm 1 Introduction In many software systems today, the primary weakness often lies in the user’s password. This is especially apparent in light of recent security breaches that have highlighted some of the weak passwords people commonly use (e.g., 123456 or password). It is very important, then, that users choose strong passwords (or “passphrases”) to secure their accounts, but strong passwords can be long and unwieldy. Even more problematic, the user generally has many different services that use password authentication, and as a result, the user has to recall many different passwords. One way for users to address this problem is to use a password manager, such as LastPass and KeePass. Password managers make it very convenient for users to use a unique, strong password for each service that requires password authentication. However, given the sensitivity of the data contained in the password manager, it takes considerable care to store the information securely. In this assignment, you will be writing a secure and efficient password manager. In your implemen- tation, you will make use of various cryptographic primitives we have discussed in class—notably, authenticated encryption and collision-resistant hash functions. Because it is ill-advised to imple- ment your own primitives in cryptography, you should use an established library: in this case, the Stanford Javascript Crypto Library (SJCL). We will provide starter code that contains a basic tem- plate, which you will be able to fill in to satisfy the functionality and security properties described below. -

User Authentication and Cryptographic Primitives
User Authentication and Cryptographic Primitives Brad Karp UCL Computer Science CS GZ03 / M030 16th November 2016 Outline • Authenticating users – Local users: hashed passwords – Remote users: s/key – Unexpected covert channel: the Tenex password- guessing attack • Symmetric-key-cryptography • Public-key cryptography usage model • RSA algorithm for public-key cryptography – Number theory background – Algorithm definition 2 Dictionary Attack on Hashed Password Databases • Suppose hacker obtains copy of password file (until recently, world-readable on UNIX) • Compute H(x) for 50K common words • String compare resulting hashed words against passwords in file • Learn all users’ passwords that are common English words after only 50K computations of H(x)! • Same hashed dictionary works on all password files in world! 3 Salted Password Hashes • Generate a random string of bytes, r • For user password x, store [H(r,x), r] in password file • Result: same password produces different result on every machine – So must see password file before can hash dictionary – …and single hashed dictionary won’t work for multiple hosts • Modern UNIX: password hashes salted; hashed password database readable only by root 4 Salted Password Hashes • Generate a random string of bytes, r Dictionary• For user password attack still x, store possible [H(r,x after), r] in attacker seespassword password file file! Users• Result: should same pick password passwords produces that different aren’t result close to ondictionary every machine words. – So must see password file -

Modern Password Security for System Designers What to Consider When Building a Password-Based Authentication System
Modern password security for system designers What to consider when building a password-based authentication system By Ian Maddox and Kyle Moschetto, Google Cloud Solutions Architects This whitepaper describes and models modern password guidance and recommendations for the designers and engineers who create secure online applications. A related whitepaper, Password security for users, offers guidance for end users. This whitepaper covers the wide range of options to consider when building a password-based authentication system. It also establishes a set of user-focused recommendations for password policies and storage, including the balance of password strength and usability. The technology world has been trying to improve on the password since the early days of computing. Shared-knowledge authentication is problematic because information can fall into the wrong hands or be forgotten. The problem is magnified by systems that don't support real-world secure use cases and by the frequent decision of users to take shortcuts. According to a 2019 Yubico/Ponemon study, 69 percent of respondents admit to sharing passwords with their colleagues to access accounts. More than half of respondents (51 percent) reuse an average of five passwords across their business and personal accounts. Furthermore, two-factor authentication is not widely used, even though it adds protection beyond a username and password. Of the respondents, 67 percent don’t use any form of two-factor authentication in their personal life, and 55 percent don’t use it at work. Password systems often allow, or even encourage, users to use insecure passwords. Systems that allow only single-factor credentials and that implement ineffective security policies add to the problem. -

To Change Your Ud Password(S)
TO CHANGE YOUR UD PASSWORD(S) The MyCampus portal allows the user a single-signon for campus applications. IMPORTANT NOTICE AT BOTTOM OF THESE INSTRUCTIONS !! INITIAL PROCEDURE TO ALLOW YOU TO CHANGE YOUR PASSWORD ON THE UD NETWORK : 1. In your web browser, enter http://mycampus.dbq.edu . If you are logging in for the first time, you will be directed to answer (3) security questions. Also, be sure to answer one of the recovery methods. 2. Once the questions are answered, you will click on SUBMIT and then CONTINUE and then YES. 3. In one location, you will now find MyUD, Campus Portal, Email and UDOnline (Moodle). 4. You can now click on any of these apps and you will be logged in already. The email link will prompt you for the password a second time until we get all accounts set up properly. YOU MUST BE SURE TO LOGOUT OF EACH APPLICATION AFTER YOU’RE DONE USING IT !! TO CHANGE YOUR PASSWORD: 1. After you have logged into the MyCampus.dbq.edu website, you will see your username in the upper- right corner of the screen. 2. Click on your name and then go into My Account. 3. At the bottom, you will click on Change Password and then proceed as directed. 4. You can now logout. You will need to use your new password on your next login. Password must be a minimum of 6 characters and contain 3 of the following 4 categories: - Uppercase character - Lowercase character - Number - Special character You cannot use the previous password You’ll be required to change your password every 180 days. -

Security + Encryption Standards
Security + Encryption Standards Author: Joseph Lee Email: joseph@ ripplesoftware.ca Mobile: 778-725-3206 General Concepts Forward secrecy / perfect forward secrecy • Using a key exchange to provide a new key for each session provides improved forward secrecy because if keys are found out by an attacker, past data cannot be compromised with the keys Confusion • Cipher-text is significantly different than the original plaintext data • The property of confusion hides the relationship between the cipher-text and the key Diffusion • Is the principle that small changes in message plaintext results in large changes in the cipher-text • The idea of diffusion is to hide the relationship between the cipher-text and the plaintext Secret-algorithm • A proprietary algorithm that is not publicly disclosed • This is discouraged because it cannot be reviewed Weak / depreciated algorithms • An algorithm that can be easily "cracked" or defeated by an attacker High-resiliency • Refers to the strength of the encryption key if an attacker discovers part of the key Data-in-transit • Data sent over a network Data-at-rest • Data stored on a medium Data-in-use • Data being used by an application / computer system Out-of-band KEX • Using a medium / channel for key-exchange other than the medium the data transfer is taking place (phone, email, snail mail) In-band KEX • Using the same medium / channel for key-exchange that the data transfer is taking place Integrity • Ability to determine the message has not been altered • Hashing algorithms manage Authenticity -
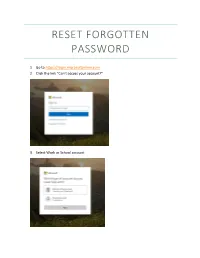
Reset Forgotten Password with Office365
RESET FORGOTTEN PASSWORD 1. Go to https://login.microsoftonline.com 2. Click the link “Can’t access your account?” 3. Select Work or School account 4. Enter in your User ID with the @uamont.edu at the end and then enter the characters as seen in the picture. You can click the refresh button for a different set of letters. 5. You will have 3 options to verify your account and reset your password. This information was set up when you registered with self-service password reset. If you have not registered, please go to https://aka.ms/ssprsetup and enter in your information. A step by step guide on how to do this can be found here. a. Text your mobile phone b. Call your mobile phone c. Answer Security Questions 6. Choose one option and enter the information requested 7. Click Text for text my mobile phone, Call for call my mobile phone, or click Next when you’ve answered all security questions. a. If you have selected Text my mobile phone you will be required to enter in a verification code and click Next b. If you have select Call my mobile phone you will receive a call and will need to enter # to verify. 8. Enter in your new password and click Finish a. Note: If you receive the message, “Unfortunately, your password contains a word, phrase, or pattern that makes it easily guessable. Please try again with a different password.” Please try to create a password that does not use any dictionary words. b. Passwords must meet 3 of the 4 following requirements i. -

A Password-Based Key Derivation Algorithm Using the KBRP Method
American Journal of Applied Sciences 5 (7): 777-782, 2008 ISSN 1546-9239 © 2008 Science Publications A Password-Based Key Derivation Algorithm Using the KBRP Method 1Shakir M. Hussain and 2Hussein Al-Bahadili 1Faculty of CSIT, Applied Science University, P.O. Box 22, Amman 11931, Jordan 2Faculty of Information Systems and Technology, Arab Academy for Banking and Financial Sciences, P.O. Box 13190, Amman 11942, Jordan Abstract: This study presents a new efficient password-based strong key derivation algorithm using the key based random permutation the KBRP method. The algorithm consists of five steps, the first three steps are similar to those formed the KBRP method. The last two steps are added to derive a key and to ensure that the derived key has all the characteristics of a strong key. In order to demonstrate the efficiency of the algorithm, a number of keys are derived using various passwords of different content and length. The features of the derived keys show a good agreement with all characteristics of strong keys. In addition, they are compared with features of keys generated using the WLAN strong key generator v2.2 by Warewolf Labs. Key words: Key derivation, key generation, strong key, random permutation, Key Based Random Permutation (KBRP), key authentication, password authentication, key exchange INTRODUCTION • The key size must be long enough so that it can not Key derivation is the process of generating one or be easily broken more keys for cryptography and authentication, where a • The key should have the highest possible entropy key is a sequence of characters that controls the process (close to unity) [1,2] of a cryptographic or authentication algorithm . -

BLAKE2: Simpler, Smaller, Fast As MD5
BLAKE2: simpler, smaller, fast as MD5 Jean-Philippe Aumasson1, Samuel Neves2, Zooko Wilcox-O'Hearn3, and Christian Winnerlein4 1 Kudelski Security, Switzerland [email protected] 2 University of Coimbra, Portugal [email protected] 3 Least Authority Enterprises, USA [email protected] 4 Ludwig Maximilian University of Munich, Germany [email protected] Abstract. We present the hash function BLAKE2, an improved version of the SHA-3 finalist BLAKE optimized for speed in software. Target applications include cloud storage, intrusion detection, or version control systems. BLAKE2 comes in two main flavors: BLAKE2b is optimized for 64-bit platforms, and BLAKE2s for smaller architectures. On 64- bit platforms, BLAKE2 is often faster than MD5, yet provides security similar to that of SHA-3: up to 256-bit collision resistance, immunity to length extension, indifferentiability from a random oracle, etc. We specify parallel versions BLAKE2bp and BLAKE2sp that are up to 4 and 8 times faster, by taking advantage of SIMD and/or multiple cores. BLAKE2 reduces the RAM requirements of BLAKE down to 168 bytes, making it smaller than any of the five SHA-3 finalists, and 32% smaller than BLAKE. Finally, BLAKE2 provides a comprehensive support for tree-hashing as well as keyed hashing (be it in sequential or tree mode). 1 Introduction The SHA-3 Competition succeeded in selecting a hash function that comple- ments SHA-2 and is much faster than SHA-2 in hardware [1]. There is nev- ertheless a demand for fast software hashing for applications such as integrity checking and deduplication in filesystems and cloud storage, host-based intrusion detection, version control systems, or secure boot schemes. -

Implementation and Performance Analysis of PBKDF2, Bcrypt, Scrypt Algorithms
Implementation and Performance Analysis of PBKDF2, Bcrypt, Scrypt Algorithms Levent Ertaul, Manpreet Kaur, Venkata Arun Kumar R Gudise CSU East Bay, Hayward, CA, USA. [email protected], [email protected], [email protected] Abstract- With the increase in mobile wireless or data lookup. Whereas, Cryptographic hash functions are technologies, security breaches are also increasing. It has used for building blocks for HMACs which provides become critical to safeguard our sensitive information message authentication. They ensure integrity of the data from the wrongdoers. So, having strong password is that is transmitted. Collision free hash function is the one pivotal. As almost every website needs you to login and which can never have same hashes of different output. If a create a password, it’s tempting to use same password and b are inputs such that H (a) =H (b), and a ≠ b. for numerous websites like banks, shopping and social User chosen passwords shall not be used directly as networking websites. This way we are making our cryptographic keys as they have low entropy and information easily accessible to hackers. Hence, we need randomness properties [2].Password is the secret value from a strong application for password security and which the cryptographic key can be generated. Figure 1 management. In this paper, we are going to compare the shows the statics of increasing cybercrime every year. Hence performance of 3 key derivation algorithms, namely, there is a need for strong key generation algorithms which PBKDF2 (Password Based Key Derivation Function), can generate the keys which are nearly impossible for the Bcrypt and Scrypt. -

A New Approach in Expanding the Hash Size of MD5
374 International Journal of Communication Networks and Information Security (IJCNIS) Vol. 10, No. 2, August 2018 A New Approach in Expanding the Hash Size of MD5 Esmael V. Maliberan, Ariel M. Sison, Ruji P. Medina Graduate Programs, Technological Institute of the Philippines, Quezon City, Philippines Abstract: The enhanced MD5 algorithm has been developed by variants and RIPEMD-160. These hash algorithms are used expanding its hash value up to 1280 bits from the original size of widely in cryptographic protocols and internet 128 bit using XOR and AND operators. Findings revealed that the communication in general. Among several hashing hash value of the modified algorithm was not cracked or hacked algorithms mentioned above, MD5 still surpasses the other during the experiment and testing using powerful bruteforce, since it is still widely used in the domain authentication dictionary, cracking tools and rainbow table such as security owing to its feature of irreversible [41]. This only CrackingStation, Hash Cracker, Cain and Abel and Rainbow Crack which are available online thus improved its security level means that the confirmation does not need to demand the compared to the original MD5. Furthermore, the proposed method original data but only need to have an effective digest to could output a hash value with 1280 bits with only 10.9 ms confirm the identity of the client. The MD5 message digest additional execution time from MD5. algorithm was developed by Ronald Rivest sometime in 1991 to change a previous hash function MD4, and it is commonly Keywords: MD5 algorithm, hashing, client-server used in securing data in various applications [27,23,22].