Introduction to Intel Core Duo Processor Architecture
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Design and Implementation of Pentium-M Based Floswitch for Intracluster Communication Veerappa Chikkagoudar, Dr
Design and Implementation of Pentium-M Based Floswitch for Intracluster Communication Veerappa chikkagoudar, Dr. U. N. Sinha, Prof. B. L. Desai. [email protected], [email protected], [email protected] Department of Electronics and Communication B. V. Bhoomaraddi college of Engg. And Tech. Hubli-580031 Abstract: aero dynamical problems, [1].Since 1986, six Flosolver MK6 is a Parallel processing system, generations of Flosolver machine have evolved based on distributed memory concept and built namely Flosolver MK-1, MK-2, MK-3, MK-4, MK-5 around Pentium-III processors, which acts as and MK-6. processing elements (PEs). Communication Flosolver MK-6 is the latest of the parallel between processing elements is very important, computer based on 128 Pentium III processors which is done through hardware switch called (which act as processing elements, PEs) in 64 dual Floswitch. Floswitch supports both message processor boards each with 1GB RAM and 80 GB passing as well as message processing. Message HDD. It is essentially a distributed memory system. processing is a unique feature of Floswitch. A group of four Dual processor boards with a Floswitch and an optical module is a natural cluster. In existing MK-6 system, communication 16 such clusters form the system. Processing between PEs is done through the Intel 486-based elements (PEs) communicate through Floswitch (a Floswitch, which operates at 32MHz and has 32- communication switch) using PCI-DPM interface bit wide data path. The data transfer rate and card. Clusters communicate through Optical module. floating point computation of existing switch need to be increased. -

Inside Intel® Core™ Microarchitecture Setting New Standards for Energy-Efficient Performance
White Paper Inside Intel® Core™ Microarchitecture Setting New Standards for Energy-Efficient Performance Ofri Wechsler Intel Fellow, Mobility Group Director, Mobility Microprocessor Architecture Intel Corporation White Paper Inside Intel®Core™ Microarchitecture Introduction Introduction 2 The Intel® Core™ microarchitecture is a new foundation for Intel®Core™ Microarchitecture Design Goals 3 Intel® architecture-based desktop, mobile, and mainstream server multi-core processors. This state-of-the-art multi-core optimized Delivering Energy-Efficient Performance 4 and power-efficient microarchitecture is designed to deliver Intel®Core™ Microarchitecture Innovations 5 increased performance and performance-per-watt—thus increasing Intel® Wide Dynamic Execution 6 overall energy efficiency. This new microarchitecture extends the energy efficient philosophy first delivered in Intel's mobile Intel® Intelligent Power Capability 8 microarchitecture found in the Intel® Pentium® M processor, and Intel® Advanced Smart Cache 8 greatly enhances it with many new and leading edge microar- Intel® Smart Memory Access 9 chitectural innovations as well as existing Intel NetBurst® microarchitecture features. What’s more, it incorporates many Intel® Advanced Digital Media Boost 10 new and significant innovations designed to optimize the Intel®Core™ Microarchitecture and Software 11 power, performance, and scalability of multi-core processors. Summary 12 The Intel Core microarchitecture shows Intel’s continued Learn More 12 innovation by delivering both greater energy efficiency Author Biographies 12 and compute capability required for the new workloads and usage models now making their way across computing. With its higher performance and low power, the new Intel Core microarchitecture will be the basis for many new solutions and form factors. In the home, these include higher performing, ultra-quiet, sleek and low-power computer designs, and new advances in more sophisticated, user-friendly entertainment systems. -
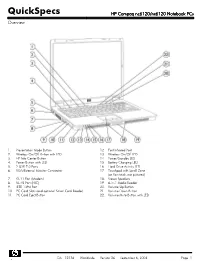
HP Compaq Nc6120/Nx6120 Notebook Pcs Overview
QuickSpecs HP Compaq nc6120/nx6120 Notebook PCs Overview 1. Presentation Mode Button 12. Fast Infrared Port 2. Wireless On/Off Button with LED 13. Wireless On/Off LED 3. HP Info Center Button 14. Power/Standby LED 4. Power Button with LED 15. Battery Charging LED 5. 2 USB 2.0 Ports 16 Hard Drive Activity LED 6. VGA/External Monitor Connector 17. Touchpad with Scroll Zone (or Pointstick, not pictured) 7. RJ-11 Port (Modem) 18. Stereo Speakers 8. RJ-45 Port (NIC) 19. 6-in-1 Media Reader 9. IEEE 1394 Port 20. Volume Up Button 10. PC Card Slots (and optional Smart Card Reader) 21. Volume Down Button 11. PC Card Eject Button 22. Volume Mute Button with LED DA - 12136 Worldwide — Version 26 — September 6, 2006 Page 1 QuickSpecs HP Compaq nc6120/nx6120 Notebook PCs Overview 1. Headphone Jack 6. Serial Port 2. Microphone Jack 7. Kensington Lock Slot 3. 2 USB 2.0 Ports 8. DC Power Connector 4. Optical Drive 9. Parallel Port 5. Optical Drive Button 10. S-Video TV Out At A Glance Genuine Windows XP Professional, Genuine Windows XP Home Edition (select countries), or FreeDOS Certified for Novell Linux Desktop 9 Intel® Pentium® M processors 730 to 770* or Intel Celeron® M processors 350J to 380* Sleek industrial design starting at 5.82 lb/2.64 kg and 1.2-inch/30.3 mm thin at front Mobile Intel 915GM Express Chipset 256-MB DDR SDRAM, upgradeable to 2048-MB maximum Up to 100-GB 5400 rpm hard drive Intel Graphics Media Accelerator 900 Optional Integrated 802.11a/b/g or 802.11b/g wireless LAN module Support for optional Intel Centrino™ mobile technology Optional integrated Bluetooth® 6-in-1 Media Reader NetXtreme Gigabit Ethernet Controller Choice of Touchpad with scroll zone or Pointstick Protected by one-year or three-year (depending on country and/or model) standard parts and labor warranty - certain restrictions and exclusions apply *Intel's numbering system is not a measurement of performance. -

Multiprocessing Contents
Multiprocessing Contents 1 Multiprocessing 1 1.1 Pre-history .............................................. 1 1.2 Key topics ............................................... 1 1.2.1 Processor symmetry ...................................... 1 1.2.2 Instruction and data streams ................................. 1 1.2.3 Processor coupling ...................................... 2 1.2.4 Multiprocessor Communication Architecture ......................... 2 1.3 Flynn’s taxonomy ........................................... 2 1.3.1 SISD multiprocessing ..................................... 2 1.3.2 SIMD multiprocessing .................................... 2 1.3.3 MISD multiprocessing .................................... 3 1.3.4 MIMD multiprocessing .................................... 3 1.4 See also ................................................ 3 1.5 References ............................................... 3 2 Computer multitasking 5 2.1 Multiprogramming .......................................... 5 2.2 Cooperative multitasking ....................................... 6 2.3 Preemptive multitasking ....................................... 6 2.4 Real time ............................................... 7 2.5 Multithreading ............................................ 7 2.6 Memory protection .......................................... 7 2.7 Memory swapping .......................................... 7 2.8 Programming ............................................. 7 2.9 See also ................................................ 8 2.10 References ............................................. -

The Secret Processor Will Go to the Ball Benchmark Insider-Proof Encrypted Computing
The Secret Processor Will Go to the Ball Benchmark Insider-Proof Encrypted Computing Peter T. Breuer Jonathan P. Bowen Esther Palomar Zhiming Liu Hecusys LLC London South Bank University Birmingham City University South West University Atlanta, GA London, UK Birmingham, UK Chongqing, China Abstract—Appropriately modifying the arithmetic in a pro- processor designs that depend on a modified arithmetic and cessor causes data to remain in encrypted form throughout encrypted working, where before they were only intuitively processing. That principle is the basis for the design re- safer. It was always probable from an engineering point of ported here, extending our initial reports in 2016. The design view, however, that such a processor would run fast or could aims to prevent insider attacks by the operator against the be made to with current technology. That is because, in user. Progress and practical experience with the prototype principle, only one piece of stateless logic, the arithmetic superscalar pipelined RISC processor and supporting software logic unit (ALU), needs to be changed from a conventional 1 infrastructure is reported. The privileged, operator mode of design – the rest remains the same. This paper provides the processor runs on unencrypted data and has full access to experimental data from our prototype to support that view. all registers and memory in the conventional way, facilitating If the reader is to take away one thing from this paper, 2 operating system and infrastructure development. The user it should be the understanding that in supervisor mode mode has restricted access rights, as is conventional, but the this processor runs unencrypted, while in user mode it runs security barrier that protects it is not based on access but on encrypted. -

The Intel X86 Microarchitectures Map Version 2.0
The Intel x86 Microarchitectures Map Version 2.0 P6 (1995, 0.50 to 0.35 μm) 8086 (1978, 3 µm) 80386 (1985, 1.5 to 1 µm) P5 (1993, 0.80 to 0.35 μm) NetBurst (2000 , 180 to 130 nm) Skylake (2015, 14 nm) Alternative Names: i686 Series: Alternative Names: iAPX 386, 386, i386 Alternative Names: Pentium, 80586, 586, i586 Alternative Names: Pentium 4, Pentium IV, P4 Alternative Names: SKL (Desktop and Mobile), SKX (Server) Series: Pentium Pro (used in desktops and servers) • 16-bit data bus: 8086 (iAPX Series: Series: Series: Series: • Variant: Klamath (1997, 0.35 μm) 86) • Desktop/Server: i386DX Desktop/Server: P5, P54C • Desktop: Willamette (180 nm) • Desktop: Desktop 6th Generation Core i5 (Skylake-S and Skylake-H) • Alternative Names: Pentium II, PII • 8-bit data bus: 8088 (iAPX • Desktop lower-performance: i386SX Desktop/Server higher-performance: P54CQS, P54CS • Desktop higher-performance: Northwood Pentium 4 (130 nm), Northwood B Pentium 4 HT (130 nm), • Desktop higher-performance: Desktop 6th Generation Core i7 (Skylake-S and Skylake-H), Desktop 7th Generation Core i7 X (Skylake-X), • Series: Klamath (used in desktops) 88) • Mobile: i386SL, 80376, i386EX, Mobile: P54C, P54LM Northwood C Pentium 4 HT (130 nm), Gallatin (Pentium 4 Extreme Edition 130 nm) Desktop 7th Generation Core i9 X (Skylake-X), Desktop 9th Generation Core i7 X (Skylake-X), Desktop 9th Generation Core i9 X (Skylake-X) • Variant: Deschutes (1998, 0.25 to 0.18 μm) i386CXSA, i386SXSA, i386CXSB Compatibility: Pentium OverDrive • Desktop lower-performance: Willamette-128 -

Enhanced Intel Speedstep Technology for the Intel Pentium M Processor
Enhanced Intel® SpeedStep® Technology for the Intel® Pentium® M Processor White Paper March 2004 Order Number: 301170-001 ® ® ® ® Enhanced Intel SpeedStep Technology for the Intel Pentium M Processor INFORMATION IN THIS DOCUMENT IS PROVIDED IN CONNECTION WITH INTEL® PRODUCTS. NO LICENSE, EXPRESS OR IMPLIED, BY ESTOPPEL OR OTHERWISE, TO ANY INTELLECTUAL PROPERTY RIGHTS IS GRANTED BY THIS DOCUMENT. EXCEPT AS PROVIDED IN INTEL'S TERMS AND CONDITIONS OF SALE FOR SUCH PRODUCTS, INTEL ASSUMES NO LIABILITY WHATSOEVER, AND INTEL DISCLAIMS ANY EXPRESS OR IMPLIED WARRANTY, RELATING TO SALE AND/OR USE OF INTEL PRODUCTS INCLUDING LIABILITY OR WARRANTIES RELATING TO FITNESS FOR A PARTICULAR PURPOSE, MERCHANTABILITY, OR INFRINGEMENT OF ANY PATENT, COPYRIGHT OR OTHER INTELLECTUAL PROPERTY RIGHT. Intel products are not intended for use in medical, life saving, life sustaining applications. Intel may make changes to specifications and product descriptions at any time, without notice. Designers must not rely on the absence or characteristics of any features or instructions marked “reserved” or “undefined.” Intel reserves these for future definition and shall have no responsibility whatsoever for conflicts or incompatibilities arising from future changes to them. This document as well as the software described in it is furnished under license and may only be used or copied in accordance with the terms of the license. The information in this manual is furnished for informational use only, is subject to change without notice, and should not be construed as a commitment by Intel Corporation. Intel Corporation assumes no responsibility or liability for any errors or inaccuracies that may appear in this document or any software that may be provided in association with this document. -

Energy Per Instruction Trends in Intel® Microprocessors
Energy per Instruction Trends in Intel® Microprocessors Ed Grochowski, Murali Annavaram Microarchitecture Research Lab, Intel Corporation 2200 Mission College Blvd, Santa Clara, CA 95054 [email protected], [email protected] Abstract where throughput performance is the primary objective. In order to deliver high throughput performance within a Energy per Instruction (EPI) is a measure of the amount fixed power budget, a microprocessor must achieve low of energy expended by a microprocessor for each EPI. instruction that the microprocessor executes. In this It is important to note that MIPS/watt and EPI do not paper, we present an overview of EPI, explain the consider the amount of time (latency) needed to process factors that affect a microprocessor’s EPI, and derive a an instruction from start to finish. Other metrics such as MIPS 2/watt (related to energy•delay) and MIPS 3/watt historical comparison of the trends in EPI over multiple 2 generations of Intel microprocessors. We show that the (related to energy•delay ) assign increasing importance recent Intel® Pentium® M and Intel® Core™ Duo to the time required to process instructions, and are thus microprocessors achieve significantly lower EPI than used in environments in which latency performance is what would be expected from a continuation of historical the primary objective. trends. 2. What Determines EPI? 1. Introduction Consider a capacitor that is charged and discharged With the power consumption of recent desktop by a CMOS inverter as shown in Figure 1. microprocessors having reached 130 watts, power has emerged at the forefront of challenges facing the V microprocessor designer [1, 2]. -

Intel® Itanium® Architecture Assembly Language Reference Guide
Intel® Itanium® Architecture Assembly Language Reference Guide Copyright © 2000 - 2003 Intel Corporation. All rights reserved. Order Number: 248801-004 World Wide Web: http://developer.intel.com Intel(R) Itanium(R) Architecture Assembly Lanuage Reference Guide Page 2 Disclaimer and Legal Information Information in this document is provided in connection with Intel products. No license, express or implied, by estoppel or otherwise, to any intellectual property rights is granted by this document. EXCEPT AS PROVIDED IN INTEL'S TERMS AND CONDITIONS OF SALE FOR SUCH PRODUCTS, INTEL ASSUMES NO LIABILITY WHATSOEVER, AND INTEL DISCLAIMS ANY EXPRESS OR IMPLIED WARRANTY, RELATING TO SALE AND/OR USE OF INTEL PRODUCTS INCLUDING LIABILITY OR WARRANTIES RELATING TO FITNESS FOR A PARTICULAR PURPOSE, MERCHANTABILITY, OR INFRINGEMENT OF ANY PATENT, COPYRIGHT OR OTHER INTELLECTUAL PROPERTY RIGHT. Intel products are not intended for use in medical, life saving, or life sustaining applications. This Intel® Itanium® Architecture Assembly Language Reference Guide as well as the software described in it is furnished under license and may only be used or copied in accordance with the terms of the license. The information in this manual is furnished for informational use only, is subject to change without notice, and should not be construed as a commitment by Intel Corporation. Intel Corporation assumes no responsibility or liability for any errors or inaccuracies that may appear in this document or any software that may be provided in association with this document. Designers must not rely on the absence or characteristics of any features or instructions marked "reserved" or "undefined." Intel reserves these for future definition and shall have no responsibility whatsoever for conflicts or incompatibilities arising from future changes to them. -

The Intel X86 Microarchitectures Map Version 2.2
The Intel x86 Microarchitectures Map Version 2.2 P6 (1995, 0.50 to 0.35 μm) 8086 (1978, 3 µm) 80386 (1985, 1.5 to 1 µm) P5 (1993, 0.80 to 0.35 μm) NetBurst (2000 , 180 to 130 nm) Skylake (2015, 14 nm) Alternative Names: i686 Series: Alternative Names: iAPX 386, 386, i386 Alternative Names: Pentium, 80586, 586, i586 Alternative Names: Pentium 4, Pentium IV, P4 Alternative Names: SKL (Desktop and Mobile), SKX (Server) Series: Pentium Pro (used in desktops and servers) • 16-bit data bus: 8086 (iAPX Series: Series: Series: Series: • Variant: Klamath (1997, 0.35 μm) 86) • Desktop/Server: i386DX Desktop/Server: P5, P54C • Desktop: Willamette (180 nm) • Desktop: Desktop 6th Generation Core i5 (Skylake-S and Skylake-H) • Alternative Names: Pentium II, PII • 8-bit data bus: 8088 (iAPX • Desktop lower-performance: i386SX Desktop/Server higher-performance: P54CQS, P54CS • Desktop higher-performance: Northwood Pentium 4 (130 nm), Northwood B Pentium 4 HT (130 nm), • Desktop higher-performance: Desktop 6th Generation Core i7 (Skylake-S and Skylake-H), Desktop 7th Generation Core i7 X (Skylake-X), • Series: Klamath (used in desktops) 88) • Mobile: i386SL, 80376, i386EX, Mobile: P54C, P54LM Northwood C Pentium 4 HT (130 nm), Gallatin (Pentium 4 Extreme Edition 130 nm) Desktop 7th Generation Core i9 X (Skylake-X), Desktop 9th Generation Core i7 X (Skylake-X), Desktop 9th Generation Core i9 X (Skylake-X) • New instructions: Deschutes (1998, 0.25 to 0.18 μm) i386CXSA, i386SXSA, i386CXSB Compatibility: Pentium OverDrive • Desktop lower-performance: Willamette-128 -

Pentium M Processor Micro-Architecture Yy Thethe Performanceperformance
TheThe IntelIntel®® PentiumPentium®® MM processorprocessor PowerPower--AwarenessAwareness StoryStory FromFrom TheoryTheory toto PracticePractice Ronny Ronen Senior Principal Engineer Director of Architecture Research Intel Labs - Haifa Intel Corporation Technion EE, Haifa, June 2, 2003 BasedBased on…on… TheThe IntelIntel® PentiumPentium® MM Processor:Processor: MicroarchitectureMicroarchitecture andand PerformancePerformance By Simcha Gochman, Ronny Ronen, Ittai Anati, Ariel Berkovits, Tsvika Kurts, Alon Naveh, Ali Saeed, Zeev Sperber, Robert C. Valentine Intel Technology Journal Q2/2003 http://developer.intel.com/technology/itj/ Page 2 All dates, plans, and features are preliminary and subject to change without notice IDCIDC –– IsraelIsrael DevelopmentDevelopment CenterCenter Located on Israel's Mediterranean coast, Haifa is the home of Intel's Israel Development Center (IDC). IDC was established in 1974, and is Intel's first development center outside the US. The center is a multi- disciplinary team, with more than 1000 employees. Many of Intel's leading products were developed and originated at IDC. IDC's employees are currently working on Intel's future The Baha`i Shrine microprocessors, CAD tools, Haifa most known attraction advanced networking components and software technologies. Page 3 All dates, plans, and features are preliminary and subject to change without notice TheThe IntelIntel® CentrinoCentrinoTM MobileMobile technologytechnology Announcing Intel® Centrino™ mobile technology. Intel has expanded its history of innovation -
Intel Mobile CPU Roadmap
Intel Mobile CPU Roadmap 2004 2005 2006 2008 2009 2010 System Price 2007 TDP System CPU Q4 Q1 Q2 Q3 Q4 Q1 Q2 Q3 Q4 Q1 Q2 Q3 Q4 Q1 Q2 Q3 Q4 Q1 Q2 Q3 Q4 Q1 Q2 Q3 2H Q4 Price Core2 Extreme Nehalem/Core 2 Clarksfield QX Quad-Core Quad core Boundary 2.xxGHz/ Calpella Extreme 4 cores/2 cores Penryn QC 8MB/PCIe 45W Extreme Boundary QX9300 (2.53GHz/ Montevina 4cores/PCIe x16 (55W) QC XE 12MB/FSB1066) $1000 Penryn 6M Merom 4M Core2 Extreme Core2 Quad Santa Rosa X9000(2.8GHz/ Penryn 6M Penryn QC Clarksfield 6MB/FSB800) 2.xxGHz/ X/Q Quad-Core Dual core 8MB/PCIe -45W Performance2 Extreme Yonah/Core 2 X7800 (2.6GHz/ X7900 (2.8GHz/ Q9100 (2.26GHz/ Calpella 2 cores/1 core Boundary 4MB/FSB800) 4MB/FSB800) X9100(3.06GHz/ 12MB/FSB1066) (55W) QC P2 Boundary Merom 4M Santa Rosa 6MB/FSB1066) Refresh $750 Montevina Napa Napa Refresh Merom 4M 2.xxGHz/ Clarksfield Quad-Core Dothan 533 Santa Rosa ?MB/PCIe 2.13GHz(770) 2.33GHz(T7600) Q9000 (2GHz/ Calpella Performance1 Yonah Dual-Core2M Core2 Duo 6MB/FSB1066) QC P1 T9500 (2.6GHz/ $34x Performance 2.16GHz(T2600) 2.33GHz(T2700) 6MB/FSB800) Penryn 6M Montevina 2.1GHz(765) T7700 (2.4GHz/ T7800 (2.6GHz/ T9600 (2.8GHz/ T9800 (2.93GHz/ T9900 (3.06GHz/ T Dual-Core 2.26GHz(780) 4MB/FSB800) 4MB/FSB800) 6MB/FSB1066) 6MB/FSB1066) 6MB/FSB1066) 35W Performance2 Core2 Duo (45W) DC P2 Core2 Duo $500 2GHz(760) 2GHz(T2500) Penryn 6M 35W Dual-Core Dothan 2.16GHz(T7400) 2GHz(755) Core Duo T9400 (2.53GHz/ T9550 (2.66GHz/ T9600 (2.8GHz/ Performance1 6MB/FSB1066) 6MB/FSB1066) 6MB/FSB1066) DC P1 2.13GHz(770) 2.16GHz(T2600) T9300 (2.5GHz/