CMP Architecture - I
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Design and Implementation of Pentium-M Based Floswitch for Intracluster Communication Veerappa Chikkagoudar, Dr
Design and Implementation of Pentium-M Based Floswitch for Intracluster Communication Veerappa chikkagoudar, Dr. U. N. Sinha, Prof. B. L. Desai. [email protected], [email protected], [email protected] Department of Electronics and Communication B. V. Bhoomaraddi college of Engg. And Tech. Hubli-580031 Abstract: aero dynamical problems, [1].Since 1986, six Flosolver MK6 is a Parallel processing system, generations of Flosolver machine have evolved based on distributed memory concept and built namely Flosolver MK-1, MK-2, MK-3, MK-4, MK-5 around Pentium-III processors, which acts as and MK-6. processing elements (PEs). Communication Flosolver MK-6 is the latest of the parallel between processing elements is very important, computer based on 128 Pentium III processors which is done through hardware switch called (which act as processing elements, PEs) in 64 dual Floswitch. Floswitch supports both message processor boards each with 1GB RAM and 80 GB passing as well as message processing. Message HDD. It is essentially a distributed memory system. processing is a unique feature of Floswitch. A group of four Dual processor boards with a Floswitch and an optical module is a natural cluster. In existing MK-6 system, communication 16 such clusters form the system. Processing between PEs is done through the Intel 486-based elements (PEs) communicate through Floswitch (a Floswitch, which operates at 32MHz and has 32- communication switch) using PCI-DPM interface bit wide data path. The data transfer rate and card. Clusters communicate through Optical module. floating point computation of existing switch need to be increased. -

Inside Intel® Core™ Microarchitecture Setting New Standards for Energy-Efficient Performance
White Paper Inside Intel® Core™ Microarchitecture Setting New Standards for Energy-Efficient Performance Ofri Wechsler Intel Fellow, Mobility Group Director, Mobility Microprocessor Architecture Intel Corporation White Paper Inside Intel®Core™ Microarchitecture Introduction Introduction 2 The Intel® Core™ microarchitecture is a new foundation for Intel®Core™ Microarchitecture Design Goals 3 Intel® architecture-based desktop, mobile, and mainstream server multi-core processors. This state-of-the-art multi-core optimized Delivering Energy-Efficient Performance 4 and power-efficient microarchitecture is designed to deliver Intel®Core™ Microarchitecture Innovations 5 increased performance and performance-per-watt—thus increasing Intel® Wide Dynamic Execution 6 overall energy efficiency. This new microarchitecture extends the energy efficient philosophy first delivered in Intel's mobile Intel® Intelligent Power Capability 8 microarchitecture found in the Intel® Pentium® M processor, and Intel® Advanced Smart Cache 8 greatly enhances it with many new and leading edge microar- Intel® Smart Memory Access 9 chitectural innovations as well as existing Intel NetBurst® microarchitecture features. What’s more, it incorporates many Intel® Advanced Digital Media Boost 10 new and significant innovations designed to optimize the Intel®Core™ Microarchitecture and Software 11 power, performance, and scalability of multi-core processors. Summary 12 The Intel Core microarchitecture shows Intel’s continued Learn More 12 innovation by delivering both greater energy efficiency Author Biographies 12 and compute capability required for the new workloads and usage models now making their way across computing. With its higher performance and low power, the new Intel Core microarchitecture will be the basis for many new solutions and form factors. In the home, these include higher performing, ultra-quiet, sleek and low-power computer designs, and new advances in more sophisticated, user-friendly entertainment systems. -

Pentium II Processor Performance Brief
PentiumÒ II Processor Performance Brief January 1998 Order Number: 243336-004 Information in this document is provided in connection with Intel products. No license, express or implied, by estoppel or otherwise, to any intellectual property rights is granted by this document. Except as provided in Intel’s Terms and Conditions of Sale for such products, Intel assumes no liability whatsoever, and Intel disclaims any express or implied warranty, relating to sale and/or use of Intel products including liability or warranties relating to fitness for a particular purpose, merchantability, or infringement of any patent, copyright or other intellectual property right. Intel products are not intended for use in medical, life saving, or life sustaining applications. Intel may make changes to specifications and product descriptions at any time, without notice. Designers must not rely on the absence or characteristics of any features or instructions marked "reserved" or "undefined." Intel reserves these for future definition and shall have no responsibility whatsoever for conflicts or incompatibilities arising from future changes to them. The Pentium® II processor may contain design defects or errors known as errata. Current characterized errata are available on request. MPEG is an international standard for video compression/decompression promoted by ISO. Implementations of MPEG CODECs, or MPEG enabled platforms may require licenses from various entities, including Intel Corporation. Contact your local Intel sales office or your distributor to obtain the latest specifications and before placing your product order. Copies of documents which have an ordering number and are referenced in this document, or other Intel literature, may be obtained from by calling 1-800-548-4725 or by visiting Intel’s website at http://www.intel.com. -

Fujitsu Siemens Computers
SPEC CINT2006 Result spec Copyright 2006-2014 Standard Performance Evaluation Corporation Fujitsu Siemens Computers SPECint_rate2006 = 21.4 PRIMERGY TX150 S5, Intel Pentium D processor 945, 3.40 GHz SPECint_rate_base2006 = 20.5 CPU2006 license: 22 Test date: May-2007 Test sponsor: Fujitsu Siemens Computers Hardware Availability: Sep-2006 Tested by: Fujitsu Siemens Computers Software Availability: Mar-2007 Copies 0 2.00 4.00 6.00 8.00 10.0 12.0 14.0 16.0 18.0 20.0 22.0 24.0 26.0 28.0 30.0 32.0 34.0 36.0 38.0 40.0 25.5 400.perlbench 2 2 24.1 17.8 401.bzip2 2 2 16.7 22.4 403.gcc 2 22.5 429.mcf 2 2 23.2 19.8 445.gobmk 2 2 18.7 19.5 456.hmmer 2 2 17.1 18.5 458.sjeng 2 2 17.4 19.4 462.libquantum 2 2 18.8 39.9 464.h264ref 2 2 38.3 16.7 471.omnetpp 2 2 15.7 15.5 473.astar 2 2 14.9 28.2 483.xalancbmk 2 SPECint_rate_base2006 = 20.5 SPECint_rate2006 = 21.4 Hardware Software CPU Name: Intel Pentium D 945 Operating System: 64-Bit SUSE LINUX Enterprise Server 10, Kernel CPU Characteristics: 800 MHz system bus 2.6.16.21-0.8-smp on an x86_64 CPU MHz: 3400 Compiler: Intel C++ Compiler for IA32/EM64T application, Version 9.1 - Build 20070215, Package-ID: FPU: Integrated l_cc_p_9.1.047 CPU(s) enabled: 2 cores, 1 chip, 2 cores/chip Auto Parallel: No CPU(s) orderable: 1 chip File System: ReiserFS Primary Cache: 12 K micro-ops I + 16 KB D on chip per core System State: Multiuser, Runlevel 3 Secondary Cache: 2 MB I+D on chip per core Base Pointers: 32-bit L3 Cache: None Peak Pointers: 32/64-bit Other Cache: None Other Software: Smart Heap Library, Version -

Microcode Revision Guidance August 31, 2019 MCU Recommendations
microcode revision guidance August 31, 2019 MCU Recommendations Section 1 – Planned microcode updates • Provides details on Intel microcode updates currently planned or available and corresponding to Intel-SA-00233 published June 18, 2019. • Changes from prior revision(s) will be highlighted in yellow. Section 2 – No planned microcode updates • Products for which Intel does not plan to release microcode updates. This includes products previously identified as such. LEGEND: Production Status: • Planned – Intel is planning on releasing a MCU at a future date. • Beta – Intel has released this production signed MCU under NDA for all customers to validate. • Production – Intel has completed all validation and is authorizing customers to use this MCU in a production environment. -

Intel Architecture Optimization Manual
Intel Architecture Optimization Manual Order Number 242816-003 1997 5/5/97 11:38 AM FRONT.DOC Information in this document is provided in connection with Intel products. No license, express or implied, by estoppel or otherwise, to any intellectual property rights is granted by this document. Except as provided in Intel's Terms and Conditions of Sale for such products, Intel assumes no liability whatsoever, and Intel disclaims any express or implied warranty, relating to sale and/or use of Intel products including liability or warranties relating to fitness for a particular purpose, merchantability, or infringement of any patent, copyright or other intellectual property right. Intel products are not intended for use in medical, life saving, or life sustaining applications. Intel may make changes to specifications and product descriptions at any time, without notice. Designers must not rely on the absence or characteristics of any features or instructions marked "reserved" or "undefined." Intel reserves these for future definition and shall have no responsibility whatsoever for conflicts or incompatibilities arising from future changes to them. The Pentium®, Pentium Pro and Pentium II processors may contain design defects or errors known as errata which may cause the product to deviate from published specifications. Such errata are not covered by Intel’s warranty. Current characterized errata are available on request. Contact your local Intel sales office or your distributor to obtain the latest specifications before placing your product order. Copies of documents which have an ordering number and are referenced in this document, or other Intel literature, may be obtained from: Intel Corporation P.O. -

SIMD Extensions
SIMD Extensions PDF generated using the open source mwlib toolkit. See http://code.pediapress.com/ for more information. PDF generated at: Sat, 12 May 2012 17:14:46 UTC Contents Articles SIMD 1 MMX (instruction set) 6 3DNow! 8 Streaming SIMD Extensions 12 SSE2 16 SSE3 18 SSSE3 20 SSE4 22 SSE5 26 Advanced Vector Extensions 28 CVT16 instruction set 31 XOP instruction set 31 References Article Sources and Contributors 33 Image Sources, Licenses and Contributors 34 Article Licenses License 35 SIMD 1 SIMD Single instruction Multiple instruction Single data SISD MISD Multiple data SIMD MIMD Single instruction, multiple data (SIMD), is a class of parallel computers in Flynn's taxonomy. It describes computers with multiple processing elements that perform the same operation on multiple data simultaneously. Thus, such machines exploit data level parallelism. History The first use of SIMD instructions was in vector supercomputers of the early 1970s such as the CDC Star-100 and the Texas Instruments ASC, which could operate on a vector of data with a single instruction. Vector processing was especially popularized by Cray in the 1970s and 1980s. Vector-processing architectures are now considered separate from SIMD machines, based on the fact that vector machines processed the vectors one word at a time through pipelined processors (though still based on a single instruction), whereas modern SIMD machines process all elements of the vector simultaneously.[1] The first era of modern SIMD machines was characterized by massively parallel processing-style supercomputers such as the Thinking Machines CM-1 and CM-2. These machines had many limited-functionality processors that would work in parallel. -

Class-Action Lawsuit
Case 3:20-cv-00863-SI Document 1 Filed 05/29/20 Page 1 of 279 Steve D. Larson, OSB No. 863540 Email: [email protected] Jennifer S. Wagner, OSB No. 024470 Email: [email protected] STOLL STOLL BERNE LOKTING & SHLACHTER P.C. 209 SW Oak Street, Suite 500 Portland, Oregon 97204 Telephone: (503) 227-1600 Attorneys for Plaintiffs [Additional Counsel Listed on Signature Page.] UNITED STATES DISTRICT COURT DISTRICT OF OREGON PORTLAND DIVISION BLUE PEAK HOSTING, LLC, PAMELA Case No. GREEN, TITI RICAFORT, MARGARITE SIMPSON, and MICHAEL NELSON, on behalf of CLASS ACTION ALLEGATION themselves and all others similarly situated, COMPLAINT Plaintiffs, DEMAND FOR JURY TRIAL v. INTEL CORPORATION, a Delaware corporation, Defendant. CLASS ACTION ALLEGATION COMPLAINT Case 3:20-cv-00863-SI Document 1 Filed 05/29/20 Page 2 of 279 Plaintiffs Blue Peak Hosting, LLC, Pamela Green, Titi Ricafort, Margarite Sampson, and Michael Nelson, individually and on behalf of the members of the Class defined below, allege the following against Defendant Intel Corporation (“Intel” or “the Company”), based upon personal knowledge with respect to themselves and on information and belief derived from, among other things, the investigation of counsel and review of public documents as to all other matters. INTRODUCTION 1. Despite Intel’s intentional concealment of specific design choices that it long knew rendered its central processing units (“CPUs” or “processors”) unsecure, it was only in January 2018 that it was first revealed to the public that Intel’s CPUs have significant security vulnerabilities that gave unauthorized program instructions access to protected data. 2. A CPU is the “brain” in every computer and mobile device and processes all of the essential applications, including the handling of confidential information such as passwords and encryption keys. -
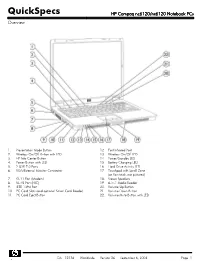
HP Compaq Nc6120/Nx6120 Notebook Pcs Overview
QuickSpecs HP Compaq nc6120/nx6120 Notebook PCs Overview 1. Presentation Mode Button 12. Fast Infrared Port 2. Wireless On/Off Button with LED 13. Wireless On/Off LED 3. HP Info Center Button 14. Power/Standby LED 4. Power Button with LED 15. Battery Charging LED 5. 2 USB 2.0 Ports 16 Hard Drive Activity LED 6. VGA/External Monitor Connector 17. Touchpad with Scroll Zone (or Pointstick, not pictured) 7. RJ-11 Port (Modem) 18. Stereo Speakers 8. RJ-45 Port (NIC) 19. 6-in-1 Media Reader 9. IEEE 1394 Port 20. Volume Up Button 10. PC Card Slots (and optional Smart Card Reader) 21. Volume Down Button 11. PC Card Eject Button 22. Volume Mute Button with LED DA - 12136 Worldwide — Version 26 — September 6, 2006 Page 1 QuickSpecs HP Compaq nc6120/nx6120 Notebook PCs Overview 1. Headphone Jack 6. Serial Port 2. Microphone Jack 7. Kensington Lock Slot 3. 2 USB 2.0 Ports 8. DC Power Connector 4. Optical Drive 9. Parallel Port 5. Optical Drive Button 10. S-Video TV Out At A Glance Genuine Windows XP Professional, Genuine Windows XP Home Edition (select countries), or FreeDOS Certified for Novell Linux Desktop 9 Intel® Pentium® M processors 730 to 770* or Intel Celeron® M processors 350J to 380* Sleek industrial design starting at 5.82 lb/2.64 kg and 1.2-inch/30.3 mm thin at front Mobile Intel 915GM Express Chipset 256-MB DDR SDRAM, upgradeable to 2048-MB maximum Up to 100-GB 5400 rpm hard drive Intel Graphics Media Accelerator 900 Optional Integrated 802.11a/b/g or 802.11b/g wireless LAN module Support for optional Intel Centrino™ mobile technology Optional integrated Bluetooth® 6-in-1 Media Reader NetXtreme Gigabit Ethernet Controller Choice of Touchpad with scroll zone or Pointstick Protected by one-year or three-year (depending on country and/or model) standard parts and labor warranty - certain restrictions and exclusions apply *Intel's numbering system is not a measurement of performance. -

Generic Pipelined Processor Modeling and High Performance
Generic Pipelined Processor Modeling and High Performance Cycle-Accurate Simulator Generation Mehrdad Reshadi, Nikil Dutt Center for Embedded Computer Systems (CECS), Donald Bren School of Information and Computer Science, University of California Irvine, CA 92697, USA. {reshadi, dutt}@cecs.uci.edu simulators were more limited or slower than their manually generated Abstract counterparts. Detailed modeling of processors and high performance cycle- Colored Petri Net (CPN) [1] is a very powerful and flexible accurate simulators are essential for today’s hardware and software modeling technique and has been successfully used for describing design. These problems are challenging enough by themselves and parallelism, resource sharing and synchronization. It can naturally have seen many previous research efforts. Addressing both capture most of the behavioral elements of instruction flow in a simultaneously is even more challenging, with many existing processor. However, CPN models of realistic processors are very approaches focusing on one over another. In this paper, we propose complex mostly due to incompatibility of a token-based mechanism for the Reduced Colored Petri Net (RCPN) model that has two capturing data hazards. Such complexity reduces the productivity and advantages: first, it offers a very simple and intuitive way of modeling results in very slow simulators. In this paper, we present Reduced pipelined processors; second, it can generate high performance cycle- Colored Petri Net (RCPN), a generic modeling approach for accurate simulators. RCPN benefits from all the useful features of generating fast cycle-accurate simulators for pipelined processors. Colored Petri Nets without suffering from their exponential growth in RCPN is based on CPN and reduces the modeling complexity by complexity. -

Professor Won Woo Ro, School of Electrical and Electronic Engineering Yonsei University the Intel® 4004 Microprocessor, Introdu
Professor Won Woo Ro, School of Electrical and Electronic Engineering Yonsei University The 1st Microprocessor The Intel® 4004 microprocessor, introduced in November 1971 An electronics revolution that changed our world. There were no customer‐ programmable microprocessors on the market before the 4004. It propelled software into the limelight as a key player in the world of digital electronics design. 4004 Microprocessor Display at New Intel Museum A Japanese calculator maker (Busicom) asked to design: A set of 12 custom logic chips for a line of programmable calculators. Marcian E. "Ted" Hoff Recognized the integrated circuit technology (of the day) had advanced enough to build a single chip, general purpose computer. Federico Faggin to turn Hoff's vision into a silicon reality. (In less than one year, Faggin and his team delivered the 4004, which was introduced in November, 1971.) The world's first microprocessor application was this Busicom calculator. (sold about 100,000 calculators.) Measuring 1/8 inch wide by 1/6 inch long, consisting of 2,300 transistors, Intel’s 4004 microprocessor had as much computing power as the first electronic computer, ENIAC. 2 inch 4004 and 12 inch Core™2 Duo wafer ENIAC, built in 1946, filled 3000‐cubic‐ feet of space and contained 18,000 vacuum tubes. The 4004 microprocessor could execute 60,000 operations per second Running frequency: 108 KHz Founders wanted to name their new company Moore Noyce. However the name sounds very much similar to “more noise”. "Only the paranoid survive". Moore received a B.S. degree in Chemistry from the University of California, Berkeley in 1950 and a Ph.D. -

Multiprocessing Contents
Multiprocessing Contents 1 Multiprocessing 1 1.1 Pre-history .............................................. 1 1.2 Key topics ............................................... 1 1.2.1 Processor symmetry ...................................... 1 1.2.2 Instruction and data streams ................................. 1 1.2.3 Processor coupling ...................................... 2 1.2.4 Multiprocessor Communication Architecture ......................... 2 1.3 Flynn’s taxonomy ........................................... 2 1.3.1 SISD multiprocessing ..................................... 2 1.3.2 SIMD multiprocessing .................................... 2 1.3.3 MISD multiprocessing .................................... 3 1.3.4 MIMD multiprocessing .................................... 3 1.4 See also ................................................ 3 1.5 References ............................................... 3 2 Computer multitasking 5 2.1 Multiprogramming .......................................... 5 2.2 Cooperative multitasking ....................................... 6 2.3 Preemptive multitasking ....................................... 6 2.4 Real time ............................................... 7 2.5 Multithreading ............................................ 7 2.6 Memory protection .......................................... 7 2.7 Memory swapping .......................................... 7 2.8 Programming ............................................. 7 2.9 See also ................................................ 8 2.10 References .............................................