AXI Reference Guide
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-
Iagrams TH EW)
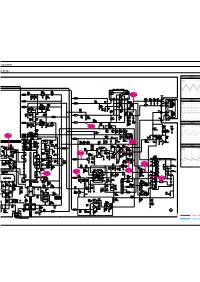
iagrams TH EW) TP07 TP10 TP08 TP09 TP09 TP01 TP06 TP10 TP08 TP05 TP07 TP03 TP02 TP04 : Power Lin : Signal Lin TP12 TP13 TP15 TP11 TP14 TP22 TP23 TP23 TP22 TP24 TP16 TP18 TP17 TP25 TP21 TP19 TP24 TP20 TP25 TP32 TP33 TP35 TP26 TP33 TP34 TP34 TP27 TP32 TP35 TP31 TP28 TP29 TP30 : Power Line : Signal Line -EW) H Alignment and Adjustments 4-4 FOCUS Adjustment 1. Input a black and white signal. 2. Adjust the tuning control for the clearest picture. 3. Adjust the FOCUS control for well defined scanning lines in the center area of the screen. 4-5 SCREEN Adjustment 1. Input Toshiba Pattern 2. Enter “Service Mode”.(Refer to “4-8-1 Service Mode”) 3. Select “G2-Adjust”. 4. Set the values as below. Table 1. Screen Adjustment Table COLR G B No INCH / CRT REGION IBRM WDRV CDL (Smallest Value) 1 14” / SDI 205 35 100 100 Noraml 220 35 180 100 2 15PF / SDI 215 35 100 100 CIS 3 21” 1.7R / SDI 220 35 180 100 4 21” 1.7R / JCT 220 35 200 150 5 21PF / TSB 220 35 180 65 Noraml 6 21PF / LG 230 35 230 65 7 21PF / SDI 220 35 210 65 8 25PF / SDI 210 35 160 120 9 29” 1.3R / SDI 200 35 170 150 5. Turn the SCREEN VR until “MRCR G B” and “MRWDG” are green and those value are about 100. (The incorrect SCREEN Voltage may result that “MRCR G B” and “MRWDG” should be red) 4-2 Samsung Electronics Alignment and Adjustments 4-6 E2PROM (IC902) Replacement 1. -

An Architecture and Compiler for Scalable On-Chip Communication
IEEE TRANSACTIONS ON VERY LARGE SCALE INTEGRATION (VLSI) SYSTEMS, VOL. XX, NO. Y, MONTH 2004 1 An Architecture and Compiler for Scalable On-Chip Communication Jian Liang, Student Member, IEEE, Andrew Laffely, Sriram Srinivasan, and Russell Tessier, Member, IEEE Abstract— tion of communication resources. Significant amounts of arbi- A dramatic increase in single chip capacity has led to a tration across even a small number of components can quickly revolution in on-chip integration. Design reuse and ease-of- form a performance bottleneck, especially for data-intensive, implementation have became important aspects of the design pro- cess. This paper describes a new scalable single-chip communi- stream-based computation. This issue is made more complex cation architecture for heterogeneous resources, adaptive System- by the need to compile high-level representations of applica- On-a-Chip (aSOC), and supporting software for application map- tions to SoC environments. The heterogeneous nature of cores ping. This architecture exhibits hardware simplicity and opti- in terms of clock speed, resources, and processing capability mized support for compile-time scheduled communication. To il- makes cost modeling difficult. Additionally, communication lustrate the benefits of the architecture, four high-bandwidth sig- nal processing applications including an MPEG-2 video encoder modeling for interconnection with long wires and variable arbi- and a Doppler radar processor have been mapped to a prototype tration protocols limits performance predictability required by aSOC device using our design mapping technology. Through ex- computation scheduling. perimentation it is shown that aSOC communication outperforms Our platform for on-chip interconnect, adaptive System-On- a hierarchical bus-based system-on-chip (SoC) approach by up to a-Chip (aSOC), is a modular communications architecture. -

On-Chip Interconnect Schemes for Reconfigurable System-On-Chip
On-chip Interconnect Schemes for Reconfigurable System-on-Chip Andy S. Lee, Neil W. Bergmann. School of ITEE, The University of Queensland, Brisbane Australia {andy, n.bergmann} @itee.uq.edu.au ABSTRACT On-chip communication architectures can have a great influence on the speed and area of System-on-Chip designs, and this influence is expected to be even more pronounced on reconfigurable System-on-Chip (rSoC) designs. To date, little research has been conducted on the performance implications of different on-chip communication architectures for rSoC designs. This paper motivates the need for such research and analyses current and proposed interconnect technologies for rSoC design. The paper also describes work in progress on implementation of a simple serial bus and a packet-switched network, as well as a methodology for quantitatively evaluating the performance of these interconnection structures in comparison to conventional buses. Keywords: FPGAs, Reconfigurable Logic, System-on-Chip 1. INTRODUCTION System-on-chip (SoC) technology has evolved as the predominant circuit design methodology for custom ASICs. SoC technology moves design from the circuit level to the system level, concentrating on the selection of appropriate pre-designed IP Blocks, and their interconnection into a complete system. However, modern ASIC design and fabrication are expensive. Design tools may cost many hundreds of thousands of dollars, while tooling and mask costs for large SoC designs now approach $1million. For low volume applications, and especially for research and development projects in universities, reconfigurable System-on-Chip (rSoC) technology is more cost effective. Like conventional SoC design, rSoC involves the assembly of predefined IP blocks (such as processors and peripherals) and their interconnection. -

Wishbone Bus Architecture – a Survey and Comparison
International Journal of VLSI design & Communication Systems (VLSICS) Vol.3, No.2, April 2012 WISHBONE BUS ARCHITECTURE – A SURVEY AND COMPARISON Mohandeep Sharma 1 and Dilip Kumar 2 1Department of VLSI Design, Center for Development of Advanced Computing, Mohali, India [email protected] 2ACS - Division, Center for Development of Advanced Computing, Mohali, India [email protected] ABSTRACT The performance of an on-chip interconnection architecture used for communication between IP cores depends on the efficiency of its bus architecture. Any bus architecture having advantages of faster bus clock speed, extra data transfer cycle, improved bus width and throughput is highly desirable for a low cost, reduced time-to-market and efficient System-on-Chip (SoC). This paper presents a survey of WISHBONE bus architecture and its comparison with three other on-chip bus architectures viz. Advanced Microcontroller Bus Architecture (AMBA) by ARM, CoreConnect by IBM and Avalon by Altera. The WISHBONE Bus Architecture by Silicore Corporation appears to be gaining an upper edge over the other three bus architecture types because of its special performance parameters like the use of flexible arbitration scheme and additional data transfer cycle (Read-Modify-Write cycle). Moreover, its IP Cores are available free for use requiring neither any registration nor any agreement or license. KEYWORDS SoC buses, WISHBONE Bus, WISHBONE Interface 1. INTRODUCTION The introduction and advancement of multimillion-gate chips technology with new levels of integration in the form of the system-on-chip (SoC) design has brought a revolution in the modern electronics industry. With the evolution of shrinking process technologies and increasing design sizes [1], manufacturers are integrating increasing numbers of components on a chip. -

An Overview of Soc Buses
Vojin Oklobdzija/Digital Systems and Applications 6195_C007 Page Proof page 1 11.7.2007 2:16am Compositor Name: JGanesan 7 An Overview of SoC Buses 7.1 Introduction....................................................................... 7-1 7.2 On-Chip Communication Architectures ........................ 7-2 Background . Topologies . On-Chip Communication Protocols . Other Interconnect Issues . Advantages and M. Mitic´ Disadvantages of On-Chip Buses M. Stojcˇev 7.3 System-On-Chip Buses ..................................................... 7-4 AMBA Bus . Avalon . CoreConnect . STBus . Wishbone . University of Nisˇ CoreFrame . Manchester Asynchronous Bus for Low Energy . Z. Stamenkovic´ PI Bus . Open Core Protocol . Virtual Component Interface . m IHP GmbH—Innovations for High SiliconBackplane Network Performance Microelectronics 7.4 Summary.......................................................................... 7-15 7.1 Introduction The electronics industry has entered the era of multimillion-gate chips, and there is no turning back. This technology promises new levels of integration on a single chip, called the system-on-a-chip (SoC) design, but also presents significant challenges to the chip designers. Processing cores on a single chip may number well into the high tens within the next decade, given the current rate of advancements [1]. Interconnection networks in such an environment are, therefore, becoming more and more important [2]. Currently, on-chip interconnection networks are mostly implemented using buses. For SoC applications, design reuse becomes easier if standard internal connection buses are used for interconnecting components of the design. Design teams developing modules intended for future reuse can design interfaces for the standard bus around their particular modules. This allows future designers to slot the reuse module into their new design simply, which is also based around the same standard bus [3]. -

MC44CM373/4 Audio/Video RF CMOS Fact Sheet
Audio/Video RF CMOS Modulators MC44CM373/4 The MC44CM373/MC44CM374 CMOS family of RF modulators is the latest generation of the legacy MC44BS373/4 family of devices. The MC44CM373/4 RF modulators are designed for use in VCRs, set-top boxes and similar devices. They support multiple standards and can be programmed to support PAL, SECAM or NTSC formats. The devices are programmed by a high-speed I2C bus. The MC44CM373/374 family is backward compatible with the previous I2C control software, providing a smooth transition for system upgrades. A programmable, internal Phase-Lock Loop (PLL), with an on-chip, cost-effective tank covers the full UHF range. The modulators incorporate a programmable, on-chip, sound subcarrier oscillator that covers all broadcast standards. No external tank Orderable Part Numbers circuit components are required, reducing New Part Number Replaces PCB complexity and the need for external MC44BS373CAD adjustments. The PLL obtains its reference MC44CM373CAEF MC44BS373CAEF from a cost-effective 4 MHz crystal oscillator. MC44BS373CAFC The devices are available in a 16-pin SOIC, MC44CM373CASEF (secondary I2C address) MC44BS373CAFC Pb-free package. These parts are functionally MC44BS374CAD MC44CM374CAEF equivalent to the MC44BS373/4 series, but MC44BS374CAEF are not direct drop-in replacements. MC44BS374T1D MC44BS374T1EF All devices now include the aux input found MC44CM374T1AEF MC44BS374T1AD previously only on the 20-pin package MC44BS374T1AEF option. This is a direct input for a modulated subcarrier and is useful in BTSC or NICAM Typical Applications stereo sound or other subcarrier applications. The MC44CM373 and MC44CM374 RF modulators are intended for applications The MC44CM373CASEF has a secondary I2C within IP/DSL, digital terrestrial, satellite address for applications using two modulators or cable set-top boxes, VCRs and DVD on one I2C Bus. -

High Definition Analog Component Measurements
Application Note High Definition Analog Component Measurements Requirements for Measuring Analog Component HD Signals for Video Devices The transition to digital has enabled great strides in the of these devices. When an image is captured by a color processing of video signals, allowing a variety of camera and converted from light to an electrical signal, techniques to be applied to the video image. Despite the signal is comprised of three components - Red, these benefits, the final signal received by the customer Green and Blue (RGB). From the combination of these is still converted to an analog signal for display on a three signals, a representation of the original image can be picture monitor. With the proliferation of a wide variety conveyed to a color display. The various video processing of digital devices - set-top boxes, Digital Versatile Disk systems within the signal paths need to process the (DVD) players and PC cards - comes a wide range of three components identically, in order not to introduce video formats in addition to the standard composite any amplitude or channel timing errors. Each of the three output. It is therefore necessary to understand the components R’G’B’ (the ( ’ ) indicates that the signal requirements for measuring analog component High has been gamma corrected) has identical bandwidth, Definition (HD) signals in order to test the performance which increases complexity within the digital domain. High Definition Analog Component Measurements Application Note Y’, R’-Y’, B’-Y’, Commonly Used for Analog Component Analog Video Format 1125/60/2:1 750/60/1:1 525/59.94/1:1, 625/50/1:1 Y’ 0.2126 R’ + 0.7152 G’ + 0.0722 B’ 0.299 R’ + 0.587 G’ + 0.114 B’ R’-Y’ 0.7874 R’ - 0.7152 G’ - 0.0722 B’ 0.701 R’ - 0.587 G’ - 0.114 B’ B’-Y’ - 0.2126 R’ - 0.7152 G’ + 0.9278 B’ - 0.299 R’ - 0.587 G’ + 0.886 B’ Table 1. -

Understanding HD and 3G-SDI Video Poster
Understanding HD & 3G-SDI Video EYE DIGITAL SIGNAL TIMING EYE DIAGRAM The eye diagram is constructed by overlaying portions of the sampled data stream until enough data amplitude is important because of its relation to noise, and because the Y', R'-Y', B'-Y', COMMONLY USED FOR ANALOG COMPONENT ANALOG VIDEO transitions produce the familiar display. A unit interval (UI) is defined as the time between two adjacent signal receiver estimates the required high-frequency compensation (equalization) based on the Format 1125/60/2:1 750/60/1:1 525/59.94/2:1, 625/50/2:1, 1250/50/2:1 transitions, which is the reciprocal of clock frequency. UI is 3.7 ns for digital component 525 / 625 (SMPTE remaining half-clock-frequency energy as the signal arrives. Incorrect amplitude at the Y’ 0.2126 R' + 0.7152 G' + 0.0722 B' 0.299 R' + 0.587 G' + 0.114 B' 259M), 673.4 ps for digital high-definition (SMPTE 292) and 336.7ps for 3G-SDI serial digital (SMPTE 424M) sending end could result in an incorrect equalization applied at the receiving end, thus causing Digital video synchronization is provided by End of Active Video (EAV) and Start of Active Video (SAV) sequences which start with a R'-Y' 0.7874 R' - 0.7152 G' - 0.0722 B' 0.701 R' - 0.587 G' - 0.114 B' as shown in Table 1. A serial receiver determines if the signal is “high” or “low” in the center of each eye, and signal distortions. Overshoot of the rising and falling edge should not exceed 10% of the waveform HORIZONTAL LINE TIMING unique three word pattern: 3FFh (all bits in the word set to 1), 000h (all 0’s), 000h (all 0’s), followed by a fourth “XYZ” word whose B'-Y' -0.2126 R' - 0.7152 G' + 0.9278 B' -0.299 R' - 0.587 G' + 0.886 B' detects the serial data. -

Vitex-II Pro: the Platfom for Programmable Systems
The Platform for Programmable Systems Developing high-performance systems with embedded pro- cessors and fast I/O is quite a challenge. To be successful, you Industry’s Fastest must solve the difficult technical FPGA Fabric problems of hardware and Up to 4 IBM PowerPC™ Processors immersed in FPGA Fabric software development, I/O Up to 24 Embedded Rocket I/O™ Multi-Gigabit Transceivers interfacing, and third-party IP Up to 12 Digital Clock Managers integration; you must rigorously XCITE Digitally Controlled Impedance Technology simulate, test, and verify your Up to 556 18x18 Multipliers design; and you must meet Over 10 Mb Embedded Block RAM increasingly difficult deadlines with a cost-effective product that can adapt as industry standards Virtex-II Pro Platform FPGA Family quickly evolve. Benefits are Overwhelming The revolutionary Virtex-II Pro™ Because all of the critical system components (such as microprocessors, memory, IP peripherals, programmable logic, and high-performance I/O) are located on one family, based on the highly successful programmable logic device, you gain a significant performance and productivity Virtex-II architecture, provides a advantage. The Virtex-II Pro FPGA family, along with the Wind River Systems embedded tools and Xilinx ISE development environment, is the fastest, easiest, and unique platform for developing most cost effective method for developing your next generation high-performance high-performance microprocessor- programmable systems. and I/O-intensive applications. With Virtex-II Pro FPGAs, you get: Virtex-II Pro FPGAs provide up to • On-Chip IBM PowerPC Processors – You get maximum performance and ease of use because these are hard cores, operating at peak efficiency, tightly coupled with ™ four embedded 32-bit IBM PowerPC all memory and programmable logic resources. -

VPC 3205C, VPC 3215C Video Processor Family
PRELIMINARY DATA SHEET MICRONAS VPC 3205C, VPC 3215C Video Processor Family Edition Oct. 19, 1998 6251-457-2PD MICRONAS VPC 3205C, VPC 3215C PRELIMINARY DATA SHEET Contents Page Section Title 4 1. Introduction 4 1.1. System Architecture 4 1.2. Video Processor Family 5 1.3. VPC Applications 6 2. Functional Description 6 2.1. Analog Front-End 6 2.1.1. Input Selector 6 2.1.2. Clamping 6 2.1.3. Automatic Gain Control 6 2.1.4. Analog-to-Digital Converters 6 2.1.5. Digitally Controlled Clock Oscillator 6 2.1.6. Analog Video Output 7 2.2. Adaptive Comb Filter 7 2.3. Color Decoder 8 2.3.1. IF-Compensation 8 2.3.2. Demodulator 8 2.3.3. Chrominance Filter 9 2.3.4. Frequency Demodulator 9 2.3.5. Burst Detection 9 2.3.6. Color Killer Operation 9 2.3.7. PAL Compensation/1-H Comb Filter 10 2.3.8. Luminance Notch Filter 10 2.3.9. Skew Filtering 11 2.4. Horizontal Scaler 11 2.5. Blackline Detector 11 2.6. Control and Data Output Signals 11 2.6.1. Line-Locked Clock Generation 12 2.6.2. Sync Signals 12 2.6.3. DIGIT3000 Output Format 12 2.6.4. Line-Locked 4:2:2 Output Format 12 2.6.5. Line-Locked 4:1:1 Output Format 12 2.6.6. Output Code Levels 12 2.6.7. Output Signal Levels 12 2.6.8. Test Pattern Generator 13 2.6.9. Priority Bus Codec 13 2.7. -

Computing Platforms Chapter 4
Computing Platforms Chapter 4 COE 306: Introduction to Embedded Systems Dr. Abdulaziz Tabbakh Computer Engineering Department College of Computer Sciences and Engineering King Fahd University of Petroleum and Minerals [Adapted from slides of Dr. A. El-Maleh, COE 306, KFUPM] Next . Basic Computing Platforms The CPU bus Direct Memory Access (DMA) System Bus Configurations ARM Bus: AMBA 2.0 Memory Components Embedded Platforms Platform-Level Performance Computing Platforms COE 306– Introduction to Embedded System– KFUPM slide 2 Embedded Systems Overview Actuator Output Analog/Digital Sensor Input Analog/Digital CPU Memory Embedded Computer Computing Platforms COE 306– Introduction to Embedded System– KFUPM slide 3 Computing Platforms Computing platforms are created using microprocessors, I/O devices, and memory components A CPU bus is required to connect the CPU to other devices Software is required to implement an application Embedded system software is closely tied to the hardware Computing Platform: hardware and software Computing Platforms COE 306– Introduction to Embedded System– KFUPM slide 4 Computing Platform A typical computing platform includes several major hardware components: The CPU provides basic computational facilities. RAM is used for program and data storage. ROM holds the boot program and some permanent data. A DMA controller provides direct memory access capabilities. Timers are used by the operating system A high-speed bus, connected to the CPU bus through a bridge, allows fast devices to communicate efficiently with the rest of the system. A low-speed bus provides an inexpensive way to connect simpler devices and may be necessary for backward compatibility as well. Computing Platforms COE 306– Introduction to Embedded System– KFUPM slide 5 Platform Hardware Components Computer systems may have one or more bus Buses are classified by their overall performance: lows peed, high- speed. -

Xilinx XAPP1000: Reference System : Plbv46 PCI Express in a ML555
Application Note: Embedded Processing Reference System: PLBv46 Endpoint Bridge R for PCI Express in a ML555 PCI/PCI Express Development Platform XAPP1000 (v1.0.1) May 6, 2008 Author: Lester Sanders Abstract This reference system demonstrates the functionality of the PLBv46 Endpoint Bridge for PCI Express® used in the Xilinx ML555 PCI/PCI Express Development Platform. The PLBv46 Endpoint Bridge is used in x1 and x4 PCIe® lane configurations. The PLBv46 Endpoint Bridge uses the Xilinx Endpoint core for PCI Express in the Virtex®-5 XC5VLX50T FPGA. The PLBv46 Bus is an IBM CoreConnect bus used for connecting the IBM PPC405 or PPC440 microprocessors, which are implemented as hard blocks on Xilinx Virtex FPGAs, and the Xilinx Microblaze microprocessor to Xilinx IP. A variety of tests generate and analyze PCIe traffic for hardware validation of the PLBv46 Endpoint Bridge. PCIe transactions are generated and analyzed by Catalyst and LeCroy test equipment. For endpoint to root complex transactions, the pcie_dma software application generates DMA transactions which move data over the PCIe link(s). For root complex to endpoint transactions, Catalyst and LeCroy scripts generate PCIe traffic. A Catalyst script which configures the PLBv46 Endpoint Bridge and performs memory write/read transactions is discussed. The steps to use Catalyst to measure PCIe performance are given, and performance results are provided.The principal intent of the performance testing is to illustrate how performance measurements can be done. Two stand-alone tools, PCItree and Memory Endpoint Test, are used to write and read PLBv46 Endpoint Bridge configuration space and memory in a PC environment.