Automatically Identifying Vocal Expressions for Music Transcription
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-
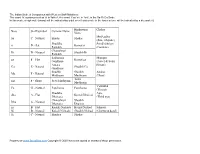
Note Staff Symbol Carnatic Name Hindustani Name Chakra Sa C
The Indian Scale & Comparison with Western Staff Notations: The vowel 'a' is pronounced as 'a' in 'father', the vowel 'i' as 'ee' in 'feet', in the Sa-Ri-Ga Scale In this scale, a high note (swara) will be indicated by a dot over it and a note in the lower octave will be indicated by a dot under it. Hindustani Chakra Note Staff Symbol Carnatic Name Name MulAadhar Sa C - Natural Shadaj Shadaj (Base of spine) Shuddha Swadhishthan ri D - flat Komal ri Rishabh (Genitals) Chatushruti Ri D - Natural Shudhh Ri Rishabh Sadharana Manipur ga E - Flat Komal ga Gandhara (Navel & Solar Antara Plexus) Ga E - Natural Shudhh Ga Gandhara Shudhh Shudhh Anahat Ma F - Natural Madhyam Madhyam (Heart) Tivra ma F - Sharp Prati Madhyam Madhyam Vishudhh Pa G - Natural Panchama Panchama (Throat) Shuddha Ajna dha A - Flat Komal Dhaivat Dhaivata (Third eye) Chatushruti Shudhh Dha A - Natural Dhaivata Dhaivat ni B - Flat Kaisiki Nishada Komal Nishad Sahsaar Ni B - Natural Kakali Nishada Shudhh Nishad (Crown of head) Så C - Natural Shadaja Shadaj Property of www.SarodSitar.com Copyright © 2010 Not to be copied or shared without permission. Short description of Few Popular Raags :: Sanskrut (Sanskrit) pronunciation is Raag and NOT Raga (Alphabetical) Aroha Timing Name of Raag (Karnataki Details Avroha Resemblance) Mood Vadi, Samvadi (Main Swaras) It is a old raag obtained by the combination of two raags, Ahiri Sa ri Ga Ma Pa Ga Ma Dha ni Så Ahir Bhairav Morning & Bhairav. It belongs to the Bhairav Thaat. Its first part (poorvang) has the Bhairav ang and the second part has kafi or Så ni Dha Pa Ma Ga ri Sa (Chakravaka) serious, devotional harpriya ang. -

Reflections on Ragamala Painting Fall 2000 Honors Thesis Susan Fuchser Dianne T a Y L O T ^ N U ^ \,<U^<N Gloria Cox H
Reflections on Ragamala Painting Fall 2000 Honors Thesis Susan Fuchser Dianne TayloT^nu^ \,<u^<n Gloria Cox hjL^Ua^ CJOY- Fuchser 2 Table of Contents Introduction 3 Part I: Religious Context 4 Hinduism 4 Islam 11 Jainism and Buddhism 12 Part II: Historical Context 13 Part II: Ragamala Painting 19 Music: the raga 19 Poetry: the dhyana 24 Painting: the ragamala 25 Part IV: Asavari Ragini 41 Conclusion 45 Works Cited 46 Fuchser 3 Introduction At various times in history, artists have intertwined the art of painting with other forms of art. For example, the Chinese paintings of the Song Dynasty combined painting with the art of poetry, and some Western Baroque paintings worked with the music played in churches to aid in worship (Yee 122; Gardner 651). But the first works of art to ever merge the three art forms of music, poetry, and painting, was the Ragamala paintings of India. Ragamala painting is quite a unique form of art in that it successfully combines these three art forms. This paper will describe many facets of Ragamala painting, and describe a specific example of Ragamala painting, in what one could call an onion of art. This is because, just as an onion has layer upon layer, art too has many different layers. The layers around a work of art include the artwork itself, its uses, any symbolism in the artwork, the role of the artist, and the background or any traditions that the artwork follows. It also includes cultural and religious contexts as well as social, political, economical, and historical contexts. -

Scale Independent Raga Identification Using Chromagram Patterns and Swara Based Features
SCALE INDEPENDENT RAGA IDENTIFICATION USING CHROMAGRAM PATTERNS AND SWARA BASED FEATURES Pranay Dighe, Parul Agrawal, Harish Karnick Siddartha Thota1,Bhiksha Raj2 Department of Computer Science and Engineering 1. NIT Surathkal, India Indian Institute of Technology Kanpur, India 2. Carnegie Mellon University, USA fpranayd,parulag,[email protected] [email protected], [email protected] ABSTRACT 2. RELATED WORK In Indian classical music a raga describes the constituent structure of notes in a musical piece. In this work, we investigate the prob- The importance of Raga identification in Indian music cannot be lem of scale independent automatic raga identification by achiev- overstated – any analysis must begin with identifying the un- ing state-of-the-art results using GMM based Hidden Markov Mod- derlying raga. Consequently, several approaches have been pro- els over a collection of features consisting of chromagram patterns, posed for automatic raga identification. One early work is by mel-cepstrum coefficients and timbre features. We also perform the Sahasrabuddhe[4](1992) who modelled a raga as a finite state au- above task using 1) discrete HMMs and 2) classification trees over tomaton based on the swara patterns followed in it. swara based features created from chromagrams using the concept Pandey et al.(2003) extended this idea of swara sequence in the of vadi of a raga.On a dataset of 4 ragas- darbari, khamaj, malhar “Tansen” raga recognition system [5] where they worked with Hid- and sohini; we have achieved an average accuracy of ∼ 97%. This den Markov Models on swara sequences extracted using a heuristics is a certain improvement over previous works because they use the driven note-segmentation technique. -

Ragang Based Raga Identification System
IOSR Journal Of Humanities And Social Science (IOSR-JHSS) Volume 16, Issue 3 (Sep. - Oct. 2013), PP 83-85 e-ISSN: 2279-0837, p-ISSN: 2279-0845. www.Iosrjournals.Org Ragang based Raga Identification system Awadhesh Pratap Singh Tomer Assistant Professor (Music-vocal), Department of Music Dr. H. S. G. Central University Sagar M.P. Gopal Sangeet Mahavidhyalaya Mahaveer Chowk Bina Distt. Sagar (M.P.) 470113 Abstract: The paper describes the importance of Ragang in the Raga classification system and its utility as being unique musical patterns; in raga identification. The idea behind the paper is to reinvestigate Ragang with a prospective to use it in digital classification and identification system. Previous works in this field are based on Swara sequence and patterns, Pakad and basic structure of Raga individually. To my best knowledge previous works doesn’t deal with the Ragang Patterns for identification and thus the paper approaches Raga identification with a Ragang (musical pattern group) base model. This work also reviews the Thaat-Raagang classification system. This describes scope in application for Automatic digital teaching of classical music by software program to analyze music (Classical vocal and instrumental). The Raag classification should be flawless and logically perfect for best ever results. Key words: Aadhar shadaj, Ati Komal Gandhar , Bahar, Bhairav, Dhanashri, Dhaivat, Gamak, Gandhar, Gitkarri, Graam, Jati Gayan, Kafi, Kanada, Kann, Komal Rishabh , Madhyam, Malhar, Meed, Nishad, Raga, Ragang, Ragini, Rishabh, Saarang, Saptak, Shruti, Shrutiantra, Swaras, Swar Prastar, Thaat, Tivra swar, UpRag, Vikrat Swar A Raga is a tonal frame work for composition and improvisation. It embodies a unique musical idea.(Balle and Joshi 2009, 1) Ragang is included in 10 point Raga classification of Saarang Dev, With Graam Raga, UpRaga and more. -

The Thaat-Ragas of North Indian Classical Music: the Basic Atempt to Perform Dr
The Thaat-Ragas of North Indian Classical Music: The Basic Atempt to Perform Dr. Sujata Roy Manna ABSTRACT Indian classical music is divided into two streams, Hindustani music and Carnatic music. Though the rules and regulations of the Indian Shastras provide both bindings and liberties for the musicians, one can use one’s innovations while performing. As the Indian music requires to be learnt under the guidance of Master or Guru, scriptural guidelines are never sufficient for a learner. Keywords: Raga, Thaat, Music, Performing, Alapa. There are two streams of Classical music of India – the Ragas are to be performed with the basic help the North Indian i.e., Hindustani music and the of their Thaats. Hence, we may compare the Thaats South Indian i.e., Carnatic music. The vast area of with the skeleton of creature, whereas the body Indian Classical music consists upon the foremost can be compared with the Raga. The names of the criterion – the origin of the Ragas, named the 10 (ten) Thaats of North Indian Classical Music Thaats. In the Carnatic system, there are 10 system i.e., Hindustani music are as follows: Thaats. Let us look upon the origin of the 10 Thaats Sl. Thaats Ragas as well as their Thaat-ragas (i.e., the Ragas named 01. Vilabal Vilabal, Alhaiya–Vilaval, Bihag, according to their origin). The Indian Shastras Durga, Deshkar, Shankara etc. 02. Kalyan Yaman, Bhupali, Hameer, Kedar, throw light on the rules and regulations, the nature Kamod etc. of Ragas, process of performing these, and the 03. Khamaj Khamaj, Desh, Tilakkamod, Tilang, liberty and bindings of the Ragas while Jayjayanti / Jayjayvanti etc. -

Emotional Responses to Hindustani Raga Music: the Role of Musical Structure
Emotional responses to Hindustani raga music: the role of musical structure Article Published Version Creative Commons: Attribution 3.0 (CC-BY) Open Access Mathur, A., Vijayakumar, S. H., Chakrabarti, B. and Singh, N. C. (2015) Emotional responses to Hindustani raga music: the role of musical structure. Frontiers in Psychology, 6. ISSN 1664-1078 doi: https://doi.org/10.3389/fpsyg.2015.00513 Available at http://centaur.reading.ac.uk/40148/ It is advisable to refer to the publisher’s version if you intend to cite from the work. See Guidance on citing . Published version at: http://dx.doi.org/10.3389/fpsyg.2015.00513 To link to this article DOI: http://dx.doi.org/10.3389/fpsyg.2015.00513 Publisher: Frontiers Media All outputs in CentAUR are protected by Intellectual Property Rights law, including copyright law. Copyright and IPR is retained by the creators or other copyright holders. Terms and conditions for use of this material are defined in the End User Agreement . www.reading.ac.uk/centaur CentAUR Central Archive at the University of Reading Reading’s research outputs online ORIGINAL RESEARCH published: 30 April 2015 doi: 10.3389/fpsyg.2015.00513 Emotional responses to Hindustani raga music: the role of musical structure Avantika Mathur1, Suhas H. Vijayakumar1, Bhismadev Chakrabarti2 and Nandini C. Singh1* 1 Speech and Language Laboratory, Cognitive Neuroscience, National Brain Research Centre, Manesar, India, 2 Centre for Integrative Neuroscience and Neurodynamics, School of Psychology and Clinical Language Sciences, University of Reading, Reading, UK In Indian classical music, ragas constitute specific combinations of tonic intervals potentially capable of evoking distinct emotions. -

(Vocal & Instrumental) Faculty of Performing Arts the M. S
Implementation of Choice Based Credit System Department of Music (Vocal & Instrumental) Faculty of Performing Arts The M. S. University of Baroda (Appendix – A) A general framework for Master’s Program shall as follows. Level Semester – Wise credits Total Credits 1 2 3 4 Master’s program 24 24 24 24 96 The credit framework for the Core course shall be as follows. HOURS Course Credit % Marks Lecture + Practical Core Compulsory TheoryIPrinciples of Music I 03 03 + 00 30%+70% Core Compulsory Theory II Study of Ragas I 03 03 + 00 30%+70% Core Compulsory IIIHistory of Music I 03 03 + 00 30%+70% Core compulsory IV Dissertation I from Core Theory 02 02 + 00 30%+70% Prescribed Syllabus Core Compulsory Practical IIntensive Practical study of 05 02 + 05 30%+70% Ragas I Core Compulsory Practical IIPractical Tradition and 05 02 + 05 30%+70% composition of Ragas I Core Compulsory Practical III Stage Performance I 03 01 + 03 30%+70% Core Subject Total Credits 24 16 + 13 30%+70% 1 Department of Music (Vocal & Instrumental) Academic Faculty of Performing Arts Year 2018-19 The Maharaja Sayajirao University of Baroda Master of Performing Arts : Music (Vocal / Sitar / Violin) Post – Graduate Program Year 1 Core Compulsory-1 : Theory I Principle of Music I Credit 3 Semester 1 Section I Aesthetics of Music Hours 45 Section II Acoustics of Music Vocal / Sitar / Violin (Practical- 0 credit & Theory-3 credit= 3 credit) To introduce Concept of Shruti and its interpretations in ancient period OBJECTIVES To improve knowledge of student in Principles of Music To introduce of Indian & Western Music scales & Notation systems Unit-1 Section I Aesthetics of Music 12 hours The Ras – Sutra of Acharya Bharat Muni. -

Indian Classical Music Is One of the Oldest Forms of Music in the World
AN INTRODUCTION TO THE CLASSICAL MUSIC OF INDIA Rangaraj M. Rangayyan Department of Electrical and Computer Engineering University of Calgary Calgary, Canada T2N 1N4. Phone: +1 (403) 220-6745 Fax: +1 (403) 282-6855 e-mail: [email protected] Web: http://www.enel.ucalgary.ca/People/Ranga 48 Scandia Hill N.W. Calgary, Alberta, CANADA T3L 1T8 Phone/fax: +1 (403) 239-7380 I. INTRODUCTION Indian classical music is one of the oldest forms of music in the world. It has its roots in diverse areas such as the ancient religious vedic hymns, tribal chants, devotional temple music, and folk music[2]. Indian music is melodic in nature, as opposed to Western music which is harmonic. The most important point to note is that movements in Indian classical music are on a one-note-at-a-time basis. This progression of sound patterns along time is the most significant contributor to the tune and rhythm of the presentation, and hence to the melody[2]. Although Indian music is now divided into the two major classes of Hindusthani (Northern Indian) and Karnatak or Carnatic (Southern Indian), the origins and fundamental concepts of both these types of music are the same. The form of presentation may however vary between the two systems, as well as from one gharana (family) to another in the former system. The fundamental concepts that have to be understood at the outset are those of swara (musical note), raga (a melodic concept, or scale of notes) and tala (beats of timing or rhythm). This paper begins with an introduction to these concepts. -

2 M Music Hcm.Pdf
Visva-Bharati, Sangit-Bhavana DEPARTMENT OF HINDUSTHANI CLASSICAL MUSIC CURRICULUM FOR POSTGRADUATE COURSE M.MUS IN HINDUSTHANI CLASSICAL MUSIC Sl.No Course Semester Credit Marks Full . Marks 1. 16 Courses I-IV 16X4=64 16X50 800 10 Courses Practical 06 Courses Theoretical Total Courses 16 Semester IV Credits 64 Marks 800 M.MUS IN HINDUSTHANI CLASSICAL MUSIC OUTLINE OF THE COURSE STRUCTURE 1st Semester 200 Marks Course Marks Credits Course-I (Practical) 40+10=50 4 Course-II (Practical) 40+10=50 4 Course-III (Practical) 40+10=50 4 Course-IV (Theoretical) 40+10=50 4 2nd Semester 200 Marks Course Marks Credits Course-V (Practical) 40+10=50 4 Course-VI (Practical) 40+10=50 4 Course-VII (Theoretical) 40+10=50 4 Course-VIII (Theoretical) 40+10=50 4 3rd Semester 200 Marks Course Marks Credits Course-IX (Practical) 40+10=50 4 Course-X (Practical) 40+10=50 4 Course-XI (Practical) 40+10=50 4 Course-XII (Theoretical) 40+10=50 4 4th Semester 200 Marks Course Marks Credits Course-XIII (Practical) 40+10=50 4 Course-XIV (Practical) 40+10=50 4 Course-XV (Theoretical) 40+10=50 4 Course-XVI (Theoretical) 40+10=50 4 1 Sangit-Bhavana, Visva Bharati Department of Hindusthani Classical Music CURRICULUM FOR POST GRADUATE COURSE M.MUS IN HINDUSTHANI CLASSICAL MUSIC TABLE OF CONTENTS HINDUSTHANI CLASSICAL MUSIC (VOCAL)………………………………………………3 HINDUSTHANI CLASSICAL MUSIC INSTRUMENTAL (SITAR)…………………………14 HINDUSTHANI CLASSICAL MUSIC INSTRUMENTAL (ESRAJ)…………………………23 HINDUSTHANI CLASSICAL MUSIC INSTRUMENTAL (TABLA)………………………..32 HINDUSTHANI CLASSICAL MUSIC INSTRUMENTAL (PAKHAWAJ)………………….42 2 CURRICULUM FOR POSTGRADUATE COURSE DEPARTMENT OF HINDUSTHANI CLASSICAL MUSIC SUBJECT- HINDUSTHANI CLASSICAL MUSIC (VOCAL) Course Objectives: This is a Master’s degree course in Hindustani Classical vocal music with emphasis on teaching a nuanced interpretation of different ragas. -

Hindustani Music (Vocal/ Instrumental) Submitted to University Grants Commission New Delhi Under Choice Based Credit System
Appendix-XXXIII E.C. dated 03.07.2017/14-15.07.2017 (Page No. 353-393) Syllabus of B.A. (Prog.) Hindustani Music (Vocal/ Instrumental) Submitted to University Grants Commission New Delhi Under Choice Based Credit System CHOICE BASED CREDIT SYSTEM 2015 DEPARTMENT OF MUSIC FACULTY OF MUSIC & FINE ARTS UNIVERSITY OF DELHI DELHI-110007 1 353 Appendix-XXXIII CHOICE BASED CREDIT SYSTEM INE.C. B.A. dated PROGRAMME 03.07.2017/14-15.07.2017 HINDUSTANI MUSIC (VOCAL/INSTRUMENTAL)(Page No. 353-393) CORE COURSE Ability Skill Elective: Elective: Semester Enhancement Enhancement Discipline Generic (GE) Compulsory Course Course (SEC) Specific DSE (AECC) 1 English/MIL-1 (English/MIL Communication)/ Environmental DSC-1A Theory of Indian Science Music: Unit-1 Practical: Unit-2 II Theory of Indian Music General Environmental & Biographies Unit-I Science/(English/MI L Communication) Practical : Unit-II III Theory: Unit-1 Ancient SEC-1 Granthas & Contribution of musicologists Value based & Practical Practical : Unit-2 Oriented course for Hindustani Music (Vocal/Instrum ental) Credits-4 IV Theory : Unit-1 SEC-2 Medieval Granthas & Contribution of Musicians Value based & Practical Practical : Unit-2 Oriented course for Hindustani Music (Vocal/Instrum ental) Credits-4 V SEC-3 DSE-1A Theory: Generic Elective Value based & Vocal / -1 (Vocal/ Practical Instrumental Instrumental Oriented (Hindustani Music) course for Music) Credit-2 Credit-6 Hindustani Music DSE-2A (Vocal/Instrum Practical: ental) Vocal / Credits-4 Instrumental (Hindustani Music) Credit-4 VI SEC-4 DSE-1B Generic Elective Value based & Theory: -2 (Vocal/ Practical Vocal / Instrumental Oriented Instrumental Music) course for (Hindustani Credit-6 Hindustani Music) Credit-2 Music (Vocal/Instrum DSE-2B ental) Practical: Credits-4 Vocal / Instrumental (Hindustani Music) Credit-4 2 354 Appendix-XXXIII E.C. -

Discovering Structural Similarities Among Rāgas in Indian Art Music
Sådhanå (2019) 44:120 Ó Indian Academy of Sciences https://doi.org/10.1007/s12046-019-1112-2Sadhana(0123456789().,-volV)FT3](0123456789().,-volV) Discovering structural similarities among ra¯gas in Indian Art Music: a computational approach H G RANJANI1,* , DEEPAK PARAMASHIVAN2 and THIPPUR V SREENIVAS1 1 Department of Electrical Communication Engineering, Indian Institute of Science, Bangalore, India 2 Department of Music, University of Alberta, Edmonton, Canada e-mail: [email protected]; [email protected]; [email protected] MS received 16 August 2018; revised 4 February 2019; accepted 19 February 2019; published online 20 April 2019 Abstract. Indian Art Music has a huge variety of ra¯gas. The similarity across ra¯gas has traditionally been approached from various musicological viewpoints. This work aims at discovering structural similarities among renditions of ra¯gas using a data-driven approach. Starting from melodic contours, we obtain the descriptive note-level transcription of each rendition. Repetitive note patterns of variable and fixed lengths are derived using stochastic models. We propose a latent variable approach for raga distinction based on statistics of these patterns. The posterior probability of the latent variable is shown to capture similarities across raga renditions. We show that it is possible to visualize the similarities in a low-dimensional embedded space. Experiments show that it is possible to compare and contrast relations and distances between ragas in the embedded space with the musicological knowledge of the same for both Hindustani and Carnatic music forms. The proposed approach also shows robustness to duration of rendition. Keywords. Indian Art Music; similar ra¯gas; ra¯ga identification; repetitive note patterns. -

FIRST YEAR ARTS MUSIC VOCAL THEORY PAPER-1 HINDUSTANI MUSIC 1 PAPER CODE – MUSV101 Time: 3 Hrs M.M
FIRST YEAR ARTS MUSIC VOCAL THEORY PAPER-1 HINDUSTANI MUSIC 1 PAPER CODE – MUSV101 Time: 3 hrs M.M. 30 Unit-1 1. Full study of following Ragas prescribed in the course. i. Kafi ii. Yaman iii. Des iv. Bhairav v. Aasawari 2. Fully Description of the following ; Talas with Dungun. i. Trital ii. Ektal iii. Jhaptal iv. Kaherva Unit-2 3. Writing of chota khayal with notation in following Ragas. Yaman-Bhairav-Kafi-Aasawari 4. Writing of Ten Alankar in Ten That’s. Unit-3 5. Complete knowledge about the following terms i. Aroh ii. Pakad iii. Samvadi iv. Vivadi v. Avroh vi. Vadi vii. Anuvadi viii. Saptak 6. Complete knowledge about sangeet and alankar. Unit-4 7. Brief study of the following terms: i. Alap ii. Tan iii. Alankar iv. Meed v. Gamak vi. Khayal 8. Study of 10 That’s and difference between That’s and Rag. Unit-5 9. Description and utility of following Instruments: i. Tanpura ii. Tabla iii. Sitar 10. Life sketches of: i. Jaidev ii. Gopal Nayak iii. Swami hari das iv. Ameer Khusro v. Tansen FIRST YEAR ARTS MUSIC VOCAL THEORY PAPER-II HINDUSTANI MUSIC II PAPER CODE – MUSV102 Time: 3 hrs M.M. 30 Unit- 1 1. Complete knowledge of Aadhunik Alap Gayan. 2. Detailed study of following terms : i. Raag Alap ii. Rupak Alap iii. Swasthan Niyam iv. Nad v. Alpatva vi. Laya Unit-2 3. Importance and basic rules regarding Hindustani Music. 4. Detail study of Rag Jati. Unit-3 5. History of Indian Music with reference to ancient period.