ZFS 2018 and Onward
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

ストレージの管理: Geom, Ufs, Zfs
FreeBSD 勉強会 ストレージの管理: GEOM, UFS, ZFS 佐藤 広生 <[email protected]> 東京工業大学/ FreeBSD Project 2012/7/20 2012/7/20 (c) Hiroki Sato 1 / 94 FreeBSD 勉強会 前編 ストレージの管理: GEOM, UFS, ZFS 佐藤 広生 <[email protected]> 東京工業大学/ FreeBSD Project 2012/7/20 2012/7/20 (c) Hiroki Sato 1 / 94 講師紹介 佐藤 広生 <[email protected]> ▶ *BSD関連のプロジェクトで10年くらい色々やってます ▶ カーネル開発・ユーザランド開発・文書翻訳・サーバ提供 などなど ▶ FreeBSD コアチームメンバ(2006 年から 4期目)、 リリースエンジニア (commit 比率は src/ports/doc で 1:1:1くらい) ▶ AsiaBSDCon 主宰 ▶ 技術的なご相談や講演・執筆依頼は [email protected] まで 2012/7/20 (c) Hiroki Sato 2 / 94 お話すること ▶ ストレージ管理 ▶ まずは基礎知識 ▶ GEOMフレームワーク ▶ 構造とコンセプト ▶ 使い方 ▶ ファイルシステム ▶ 原理と技術的詳細を知ろう ▶ UFS の構造 ▶ ZFS の構造(次回) ▶ GEOM, UFS, ZFSの実際の運用と具体例(次回) 2012/7/20 (c) Hiroki Sato 3 / 94 復習:UNIX系OSの記憶装置 記憶装置 ハードウェア カーネル ソフトウェア ユーザランド ユーザランド ユーザランド プロセス プロセス プロセス 2012/7/20 (c) Hiroki Sato 4 / 94 復習:UNIX系OSの記憶装置 HDD カーネル デバイスドライバ GEOMサブシステム /dev/foo (devfs) バッファキャッシュ VMサブシステム physio() ファイルシステム ユーザランドアプリケーション 2012/7/20 (c) Hiroki Sato 5 / 94 復習:UNIX系OSの記憶装置 ▶ 記憶装置はどう見える? ▶ UNIX系OSでは、資源は基本的に「ファイル」 ▶ /dev/ada0 (SATA, SAS HDD) ▶ /dev/da0 (SCSI HDD, USB mass storage class device) ▶ 特殊ファイル(デバイスノード) # ls -al /dev/ada* crw-r----- 1 root operator 0, 75 Jul 19 23:46 /dev/ada0 crw-r----- 1 root operator 0, 77 Jul 19 23:46 /dev/ada1 crw-r----- 1 root operator 0, 79 Jul 19 23:46 /dev/ada1s1 crw-r----- 1 root operator 0, 81 Jul 19 23:46 /dev/ada1s1a crw-r----- 1 root operator 0, 83 Jul 19 23:46 /dev/ada1s1b crw-r----- 1 root operator 0, 85 Jul 19 23:46 /dev/ada1s1d crw-r----- 1 root operator 0, 87 Jul 19 23:46 /dev/ada1s1e crw-r----- 1 root operator 0, 89 -

Portace Na Jin´E Os
VYSOKEU´ CENˇ ´I TECHNICKE´ V BRNEˇ BRNO UNIVERSITY OF TECHNOLOGY FAKULTA INFORMACNˇ ´ICH TECHNOLOGI´I USTAV´ INFORMACNˇ ´ICH SYSTEM´ U˚ FACULTY OF INFORMATION TECHNOLOGY DEPARTMENT OF INFORMATION SYSTEMS REDIRFS - PORTACE NA JINE´ OS PORTING OF REDIRFS ON OTHER OS DIPLOMOVA´ PRACE´ MASTER’S THESIS AUTOR PRACE´ Bc. LUKA´ Sˇ CZERNER AUTHOR VEDOUC´I PRACE´ Ing. TOMA´ Sˇ KASPˇ AREK´ SUPERVISOR BRNO 2010 Abstrakt Tato pr´acepopisuje jak pˇr´ıpravu na portaci, tak samotnou portaci Linuxov´ehomodulu RedirFS na operaˇcn´ısyst´emFreeBSD. Jsou zde pops´any z´akladn´ırozd´ılypˇr´ıstupuk Lin- uxov´emu a FreeBSD j´adru,d´alerozd´ılyv implementaci, pro RedirFS z´asadn´ı,ˇc´astij´adra a sice VFS vrstvy. D´alezkoum´amoˇznostia r˚uzn´epˇr´ıstupy k implementaci funkcionality linuxov´ehoRedirFS na operaˇcn´ımsyst´emu FreeBSD. N´aslednˇejsou zhodnoceny moˇznostia navrˇzenide´aln´ıpostup portace. N´asleduj´ıc´ıkapitoly pak popisuj´ıpoˇzadovanou funkcional- itu spolu s navrhovanou architekturou nov´ehomodulu. D´aleje detailnˇepops´ann´avrha implementace nov´ehomodulu tak, aby mˇelˇcten´aˇrjasnou pˇredstavu jak´ymzp˚usobem modul implementuje poˇzadovanou funkcionalitu. Abstract This thesis describes preparation for porting as well aw porting itself of RedirFS Linux kernel module to FreeBSD. Basic differences between Linux and FreeBSD kernels are de- scribed as well as differences in implementation of the Virtual Filesystem, crucial part for RedirFS. Further there are described possibilities and different approaches to implemen- tation RedirFS functionality to FreeBSD. Then, the possibilities are evaluated and ideal approach is proposed. Next chapters introduces erquired functionality of the new module as well as its solutions. Then the implementation details are describet so the reader can very well understand how the new module works and how the required functionality is implemented into the module. -

Best Practices for Openzfs L2ARC in the Era of Nvme
Best Practices for OpenZFS L2ARC in the Era of NVMe Ryan McKenzie iXsystems 2019 Storage Developer Conference. © Insert Your Company Name. All Rights Reserved. 1 Agenda ❏ Brief Overview of OpenZFS ARC / L2ARC ❏ Key Performance Factors ❏ Existing “Best Practices” for L2ARC ❏ Rules of Thumb, Tribal Knowledge, etc. ❏ NVMe as L2ARC ❏ Testing and Results ❏ Revised “Best Practices” 2019 Storage Developer Conference. © iXsystems. All Rights Reserved. 2 ARC Overview ● Adaptive Replacement Cache ● Resides in system memory NIC/HBA ● Shared by all pools ● Used to store/cache: ARC OpenZFS ○ All incoming data ○ “Hottest” data and Metadata (a tunable ratio) SLOG vdevs ● Balances between ○ Most Frequently Used (MFU) Data vdevs L2ARC vdevs ○ Most Recently zpool Used (MRU) FreeBSD + OpenZFS Server 2019 Storage Developer Conference. © iXsystems. All Rights Reserved. 3 L2ARC Overview ● Level 2 Adaptive Replacement Cache ● Resides on one or more storage devices NIC/HBA ○ Usually Flash ● Device(s) added to pool ARC OpenZFS ○ Only services data held by that pool ● Used to store/cache: ○ “Warm” data and SLOG vdevs metadata ( about to be evicted from ARC) Data vdevs L2ARC vdevs ○ Indexes to L2ARC zpool blocks stored in ARC headers FreeBSD + OpenZFS Server 2019 Storage Developer Conference. © iXsystems. All Rights Reserved. 4 ZFS Writes ● All writes go through ARC, written blocks are “dirty” until on stable storage ACK NIC/HBA ○ async write ACKs immediately ARC OpenZFS ○ sync write copied to ZIL/SLOG then ACKs ○ copied to data SLOG vdevs vdev in TXG ● When no longer dirty, written blocks stay in Data vdevs L2ARC vdevs ARC and move through zpool MRU/MFU lists normally FreeBSD + OpenZFS Server 2019 Storage Developer Conference. -

GELI (8) Freebsd System Manager's Manual GELI (8) NAME Geli
GELI (8) FreeBSD System Manager’s Manual GELI (8) NAME geli — control utility for cryptographic GEOM class SYNOPSIS To compile GEOM ELI into your kernel, place the following lines in your kernel configuration file: device crypto options GEOM_ELI Alternately, to load the GEOM ELI module at boot time, place the following line in your loader.conf(5): geom_eli_load="YES" Usage of the geli(8) utility: geli init [ -bPv][ -a algo ][ -i iterations ][ -K newkeyfile][ -l keylen ][ -s sectorsize ] prov geli label - an alias for init geli attach [ -dpv ][ -k keyfile ] prov geli detach [ -fl] prov . geli stop - an alias for detach geli onetime [ -d][ -a algo][ -l keylen][ -s sectorsize ] prov . geli setkey [ -pPv ][ -i iterations ][ -k keyfile][ -K newkeyfile][ -n keyno] prov geli delkey [ -afv ][ -n keyno] prov geli kill [ -av][ prov . ] geli backup [ -v] prov file geli restore [ -v] file prov geli clear [ -v] prov . geli dump [ -v] prov . geli list geli status geli load geli unload DESCRIPTION The geli utility is used to configure encryption on GEOM providers. The following is a list of the most important features: • Utilizes the crypto(9) framework, so when there is crypto hardware available, geli will make use of it automatically. • Supports many cryptographic algorithms (currently AES, Blowfish and 3DES). • Can create a key from a couple of components (user entered passphrase, random bits from a file, etc.). • Allows to encrypt the root partition - the user will be asked for the passphrase before the root file system is mounted. • The passphrase of the user is strengthened with: B. Kaliski, PKCS #5: Password-Based Cryptography Specification, Version 2.0. -

Referência Debian I
Referência Debian i Referência Debian Osamu Aoki Referência Debian ii Copyright © 2013-2021 Osamu Aoki Esta Referência Debian (versão 2.85) (2021-09-17 09:11:56 UTC) pretende fornecer uma visão geral do sistema Debian como um guia do utilizador pós-instalação. Cobre muitos aspetos da administração do sistema através de exemplos shell-command para não programadores. Referência Debian iii COLLABORATORS TITLE : Referência Debian ACTION NAME DATE SIGNATURE WRITTEN BY Osamu Aoki 17 de setembro de 2021 REVISION HISTORY NUMBER DATE DESCRIPTION NAME Referência Debian iv Conteúdo 1 Manuais de GNU/Linux 1 1.1 Básico da consola ................................................... 1 1.1.1 A linha de comandos da shell ........................................ 1 1.1.2 The shell prompt under GUI ......................................... 2 1.1.3 A conta root .................................................. 2 1.1.4 A linha de comandos shell do root ...................................... 3 1.1.5 GUI de ferramentas de administração do sistema .............................. 3 1.1.6 Consolas virtuais ............................................... 3 1.1.7 Como abandonar a linha de comandos .................................... 3 1.1.8 Como desligar o sistema ........................................... 4 1.1.9 Recuperar uma consola sã .......................................... 4 1.1.10 Sugestões de pacotes adicionais para o novato ................................ 4 1.1.11 Uma conta de utilizador extra ........................................ 5 1.1.12 Configuração -

Openzfs on Linux Hepix 2014 October 16, 2014 Brian Behlendorf [email protected]
OpenZFS on Linux HEPiX 2014 October 16, 2014 Brian Behlendorf [email protected] LLNL-PRES-XXXXXX This work was performed under the auspices of the U.S. Department of Energy by Lawrence Livermore National Laboratory under Contract DE-AC52-07NA27344. Lawrence Livermore National Security, LLC 1 Lawrence Livermore National Laboratory LLNL-PRES-xxxxxx High Performance Computing Advanced Simulation Massive Scale Data Intensive Top 500 (June 2014) #3 Sequoia 20.1 Peak PFLOP/s 1,572,864 cores 55 PB of storage at 850 GB/s #9 Vulcan 5.0 Peak PFLOPS/s 393,216 cores 6.7 PB of storage at 106 GB/s World class computing resources 2 Lawrence Livermore National Laboratory LLNL-PRES-xxxxxx Linux Clusters 2001 – First Linux cluster Today – ~10 large Linux clusters (100– 3,000 nodes) and 10-20 smaller ones Near-commodity hardware Open source software stack (TOSS) Tri-Labratory Operating System Stack Modified RHEL targeted for HPC RHEL kernel optimized for clusters Moab and SLURM for scheduling Lustre parallel filesystem Additional packages for monitoring, power/console, compilers, etc LLNL Loves Linux 3 Lawrence Livermore National Laboratory LLNL-PRES-xxxxxx Lustre Lustre is our parallel filesystem of choice Livermore Computing Filesystems: Open – 20PB in 5 filesystems Secure – 22PB in 3 filesystems Plus the 55PB Sequoia filesystem 1000+ storage servers Billions of files Users want: Access to their data from every cluster Good performance High availability How do we design a system to handle this? Lustre is used extensively -

967-Malone.Pdf
IN THIS ARTICLE I’M GOING TO LOOK at some less well known security features DAVID MALONE of FreeBSD. Some of these features are com- mon to all the BSDs. Others are FreeBSD- specific or have been extended in some way in FreeBSD. The features that I will be security through discussing are available in FreeBSD 5.4. obscurity First, I’ll mention some features that I don’t plan to cover. FreeBSD jails are like a more powerful version of chroot. Like chroot they are restricted to a subtree A REVIEW OF A FEW OF of the file system, but users (including root) in a jail are also restricted in terms of networking and system FREEBSD’S LESSER-KNOWN calls. It should be safe to give root access to a jail to an untrusted user, making a jail like virtual system, SECURITY CAPABILITIES not unlike some applications of UML [1] or Xen [2] David is a system administrator at Trinity College, but without running separate kernels for each system. Dublin, a researcher in NUI Maynooth, and a com- A lot has already been written about jails [3], so I mitter on the FreeBSD project. He likes to express won’t dwell on them further here. himself on technical matters, and so has a Ph.D. in mathematics and is the co-author of IPv6 Network Another feature that I don’t plan to spend much time Administration (O’Reilly, 2005). on is ACLs. ACLs are an extension of the traditional [email protected] UNIX permissions system to allow you to specify per- missions for users and groups other than the file’s owner and group. -

ZFS Basics Various ZFS RAID Lebels = & . = a Little About Zetabyte File System ( ZFS / Openzfs)
= BDNOG11 | Cox's Bazar | Day # 3 | ZFS Basics & Various ZFS RAID Lebels. = = ZFS Basics & Various ZFS RAID Lebels . = A Little About Zetabyte File System ( ZFS / OpenZFS) =1= = BDNOG11 | Cox's Bazar | Day # 3 | ZFS Basics & Various ZFS RAID Lebels. = Disclaimer: The scope of this topic here is not to discuss in detail about the architecture of the ZFS (OpenZFS) rather Features, Use Cases and Operational Method. =2= = BDNOG11 | Cox's Bazar | Day # 3 | ZFS Basics & Various ZFS RAID Lebels. = What is ZFS? =0= ZFS is a combined file system and logical volume manager designed by Sun Microsystems and now owned by Oracle Corporation. It was designed and implemented by a team at Sun Microsystems led by Jeff Bonwick and Matthew Ahrens. Matt is the founding member of OpenZFS. =0= Its development started in 2001 and it was officially announced in 2004. In 2005 it was integrated into the main trunk of Solaris and released as part of OpenSolaris. =0= It was described by one analyst as "the only proven Open Source data-validating enterprise file system". This file =3= = BDNOG11 | Cox's Bazar | Day # 3 | ZFS Basics & Various ZFS RAID Lebels. = system also termed as the “world’s safest file system” by some analyst. =0= ZFS is scalable, and includes extensive protection against data corruption, support for high storage capacities, efficient data compression and deduplication. =0= ZFS is available for Solaris (and its variants), BSD (and its variants) & Linux (Canonical’s Ubuntu Integrated as native kernel module from version 16.04x) =0= OpenZFS was announced in September 2013 as the truly open source successor to the ZFS project. -

Matt Ahrens [email protected] Brian Behlendorf Behlendorf1@Llnl
LinuxCon 2013 September 17, 2013 Brian Behlendorf, Open ZFS on Linux LLNL-PRES-643675 This work was performed under the auspices of the U.S. Department of Energy by Lawrence Livermore National Laboratory under Contract DE-AC52-07NA27344. Lawrence Livermore National Security, LLC High Performance Computing ● Advanced Simulation – Massive Scale – Data Intensive ● Top 500 – #3 Sequoia ● 20.1 Peak PFLOP/s ● 1,572,864 cores ● 55 PB of storage at 850 GB/s – #8 Vulcan ● 5.0 Peak PFLOPS/s ● 393,216 cores ● 6.7 PB of storage at 106 GB/s ● ● World class computing resources 2 Lawrence Livermore National Laboratory LLNL-PRES-xxxxxx Linux Clusters ● First Linux cluster deployed in 2001 ● Near-commodity hardware ● Open Source ● Clustered HiGh Availability OperatinG System (CHAOS) – Modified RHEL Kernel – New packaGes – monitorinG, power/console, compilers, etc – Lustre Parallel Filesystem – ZFS Filesystem LLNL Loves Linux 3 Lawrence Livermore National Laboratory LLNL-PRES-643675 Lustre Filesystem ● Massively parallel distributed filesystem ● Lustre servers use a modified ext4 – Stable and fast, but... – No sCalability – No data integrity – No online manageability ● Something better was needed – Use XFS, BTRFS, etC? – Write a filesystem from sCratCh? – Port ZFS to Linux? Existing Linux filesystems do not meet our requirements 4 Lawrence Livermore National Laboratory LLNL-PRES-643675 ZFS on Linux History ● 2008 – Prototype to determine viability ● 2009 – Initial ZVOL and Lustre support ● 2010 – Development moved to Github ● 2011 – POSIX layer -

Freebsd VS. Linux: ZFS by ALLAN JUDE
SEE TEXT ONLY FreeBSD VS. Linux: ZFS BY ALLAN JUDE Why Use ZFS? It is not that other filesystems are bad; they just make the mistake of trusting your storage hardware to return your data when you ask for it. As it turns out, hard drives are pretty good at that, but pretty good is often not good enough. ZFS is the only open-source, OpenZFS is available on many plat- production-quality filesystem that can not only forms, including FreeBSD and Solaris detect but correct the errors when a disk derivatives like IllumOS, as well as Mac returns incorrect data. By combining the roles of filesystem and volume manager, ZFS is also OS X and Linux. However, not all of the able to ensure your data is safe, even in the functionality is available on the latter absence of one or more disks, depending on platforms. The FreeBSD Project has fully your configuration. ZFS doesn’t trust your adopted ZFS, putting significant effort hardware; it verifies that the correct data was into integrating it with the system and returned from each read from the disk. The primary design consideration for ZFS is management tools to make ZFS a seam- the safety of the data. Every block that is writ- less part of the OS, rather than a bolt- ten to the filesystem is accompanied by a ed-on extra. OpenZFS is better inte- checksum of the data, stored with the other grated, instrumented, and documented metadata. That metadata block also has a on FreeBSD than on any of the various checksum, as does its parent, all the way up to the top-level block, called the uber block. -

Freebsd Enterprise Storage Polish BSD User Group Welcome 2020/02/11 Freebsd Enterprise Storage
FreeBSD Enterprise Storage Polish BSD User Group Welcome 2020/02/11 FreeBSD Enterprise Storage Sławomir Wojciech Wojtczak [email protected] vermaden.wordpress.com twitter.com/vermaden bsd.network/@vermaden https://is.gd/bsdstg FreeBSD Enterprise Storage Polish BSD User Group What is !nterprise" 2020/02/11 What is Enterprise Storage? The wikipedia.org/wiki/enterprise_storage page tells nothing about enterprise. Actually just redirects to wikipedia.org/wiki/data_storage page. The other wikipedia.org/wiki/computer_data_storage page also does the same. The wikipedia.org/wiki/enterprise is just meta page with lin s. FreeBSD Enterprise Storage Polish BSD User Group What is !nterprise" 2020/02/11 Common Charasteristics o Enterprise Storage ● Category that includes ser$ices/products designed &or !arge organizations. ● Can handle !arge "o!umes o data and !arge num%ers o sim#!tano#s users. ● 'n$olves centra!ized storage repositories such as SA( or NAS de$ices. ● )equires more time and experience%expertise to set up and operate. ● Generally costs more than consumer or small business storage de$ices. ● Generally o&&ers higher re!ia%i!it'%a"aila%i!it'%sca!a%i!it'. FreeBSD Enterprise Storage Polish BSD User Group What is !nterprise" 2020/02/11 EnterpriCe or EnterpriSe? DuckDuckGo does not pro$ide search results count +, Goog!e search &or enterprice word gi$es ~ 1 )00 000 results. Goog!e search &or enterprise word gi$es ~ 1 000 000 000 results ,1000 times more). ● /ost dictionaries &or enterprice word sends you to enterprise term. ● Given the *+,CE o& many enterprise solutions it could be enterPRICE 0 ● 0 or enterpri$e as well +. -
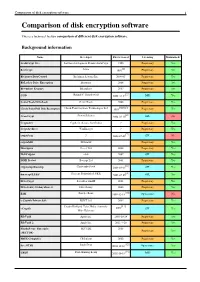
Comparison of Disk Encryption Software 1 Comparison of Disk Encryption Software
Comparison of disk encryption software 1 Comparison of disk encryption software This is a technical feature comparison of different disk encryption software. Background information Name Developer First released Licensing Maintained? ArchiCrypt Live Softwaredevelopment Remus ArchiCrypt 1998 Proprietary Yes [1] BestCrypt Jetico 1993 Proprietary Yes BitArmor DataControl BitArmor Systems Inc. 2008-05 Proprietary Yes BitLocker Drive Encryption Microsoft 2006 Proprietary Yes Bloombase Keyparc Bloombase 2007 Proprietary Yes [2] CGD Roland C. Dowdeswell 2002-10-04 BSD Yes CenterTools DriveLock CenterTools 2008 Proprietary Yes [3][4][5] Check Point Full Disk Encryption Check Point Software Technologies Ltd 1999 Proprietary Yes [6] CrossCrypt Steven Scherrer 2004-02-10 GPL No Cryptainer Cypherix (Secure-Soft India) ? Proprietary Yes CryptArchiver WinEncrypt ? Proprietary Yes [7] cryptoloop ? 2003-07-02 GPL No cryptoMill SEAhawk Proprietary Yes Discryptor Cosect Ltd. 2008 Proprietary Yes DiskCryptor ntldr 2007 GPL Yes DISK Protect Becrypt Ltd 2001 Proprietary Yes [8] cryptsetup/dmsetup Christophe Saout 2004-03-11 GPL Yes [9] dm-crypt/LUKS Clemens Fruhwirth (LUKS) 2005-02-05 GPL Yes DriveCrypt SecurStar GmbH 2001 Proprietary Yes DriveSentry GoAnywhere 2 DriveSentry 2008 Proprietary Yes [10] E4M Paul Le Roux 1998-12-18 Open source No e-Capsule Private Safe EISST Ltd. 2005 Proprietary Yes Dustin Kirkland, Tyler Hicks, (formerly [11] eCryptfs 2005 GPL Yes Mike Halcrow) FileVault Apple Inc. 2003-10-24 Proprietary Yes FileVault 2 Apple Inc. 2011-7-20 Proprietary