Portace Na Jin´E Os
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

ストレージの管理: Geom, Ufs, Zfs
FreeBSD 勉強会 ストレージの管理: GEOM, UFS, ZFS 佐藤 広生 <[email protected]> 東京工業大学/ FreeBSD Project 2012/7/20 2012/7/20 (c) Hiroki Sato 1 / 94 FreeBSD 勉強会 前編 ストレージの管理: GEOM, UFS, ZFS 佐藤 広生 <[email protected]> 東京工業大学/ FreeBSD Project 2012/7/20 2012/7/20 (c) Hiroki Sato 1 / 94 講師紹介 佐藤 広生 <[email protected]> ▶ *BSD関連のプロジェクトで10年くらい色々やってます ▶ カーネル開発・ユーザランド開発・文書翻訳・サーバ提供 などなど ▶ FreeBSD コアチームメンバ(2006 年から 4期目)、 リリースエンジニア (commit 比率は src/ports/doc で 1:1:1くらい) ▶ AsiaBSDCon 主宰 ▶ 技術的なご相談や講演・執筆依頼は [email protected] まで 2012/7/20 (c) Hiroki Sato 2 / 94 お話すること ▶ ストレージ管理 ▶ まずは基礎知識 ▶ GEOMフレームワーク ▶ 構造とコンセプト ▶ 使い方 ▶ ファイルシステム ▶ 原理と技術的詳細を知ろう ▶ UFS の構造 ▶ ZFS の構造(次回) ▶ GEOM, UFS, ZFSの実際の運用と具体例(次回) 2012/7/20 (c) Hiroki Sato 3 / 94 復習:UNIX系OSの記憶装置 記憶装置 ハードウェア カーネル ソフトウェア ユーザランド ユーザランド ユーザランド プロセス プロセス プロセス 2012/7/20 (c) Hiroki Sato 4 / 94 復習:UNIX系OSの記憶装置 HDD カーネル デバイスドライバ GEOMサブシステム /dev/foo (devfs) バッファキャッシュ VMサブシステム physio() ファイルシステム ユーザランドアプリケーション 2012/7/20 (c) Hiroki Sato 5 / 94 復習:UNIX系OSの記憶装置 ▶ 記憶装置はどう見える? ▶ UNIX系OSでは、資源は基本的に「ファイル」 ▶ /dev/ada0 (SATA, SAS HDD) ▶ /dev/da0 (SCSI HDD, USB mass storage class device) ▶ 特殊ファイル(デバイスノード) # ls -al /dev/ada* crw-r----- 1 root operator 0, 75 Jul 19 23:46 /dev/ada0 crw-r----- 1 root operator 0, 77 Jul 19 23:46 /dev/ada1 crw-r----- 1 root operator 0, 79 Jul 19 23:46 /dev/ada1s1 crw-r----- 1 root operator 0, 81 Jul 19 23:46 /dev/ada1s1a crw-r----- 1 root operator 0, 83 Jul 19 23:46 /dev/ada1s1b crw-r----- 1 root operator 0, 85 Jul 19 23:46 /dev/ada1s1d crw-r----- 1 root operator 0, 87 Jul 19 23:46 /dev/ada1s1e crw-r----- 1 root operator 0, 89 -

Introduzione Al Mondo Freebsd
Introduzione al mondo FreeBSD Corso avanzato Netstudent Netstudent http://netstudent.polito.it E.Richiardone [email protected] maggio 2009 CC-by http://creativecommons.org/licenses/by/2.5/it/ The FreeBSD project - 1 ·EÁ un progetto software open in parte finanziato ·Lo scopo eÁ mantenere e sviluppare il sistema operativo FreeBSD ·Nasce su CDROM come FreeBSD 1.0 nel 1993 ·Deriva da un patchkit per 386BSD, eredita codice da UNIX versione Berkeley 1977 ·Per problemi legali subisce un rallentamento, release 2.0 nel 1995 con codice royalty-free ·Dalla release 5.0 (2003) assume la struttura che ha oggi ·Disponibile per x86 32 e 64bit, ia64, MIPS, ppc, sparc... ·La mascotte (Beastie) nasce nel 1984 The FreeBSD project - 2 ·Erede di 4.4BSD (eÁ la stessa gente...) ·Sistema stabile; sviluppo uniforme; codice molto chiaro, ordinato e ben commentato ·Documentazione ufficiale ben curata ·Licenza molto permissiva, spesso attrae aziende per progetti commerciali: ·saltuariamente esterni collaborano con implementazioni ex-novo (i.e. Intel, GEOM, atheros, NDISwrapper, ZFS) ·a volte no (i.e. Windows NT) ·Semplificazione di molte caratteristiche tradizionali UNIX Di cosa si tratta Il progetto FreeBSD include: ·Un sistema base ·Bootloader, kernel, moduli, librerie di base, comandi e utility di base, servizi tradizionali ·Sorgenti completi in /usr/src (~500MB) ·EÁ giaÁ abbastanza completo (i.e. ipfw, ppp, bind, ...) ·Un sistema di gestione per software aggiuntivo ·Ports e packages ·Documentazione, canali di assistenza, strumenti di sviluppo ·i.e. Handbook, -

BSD UNIX Toolbox 1000+ Commands for Freebsd, Openbsd
76034ffirs.qxd:Toolbox 4/2/08 12:50 PM Page iii BSD UNIX® TOOLBOX 1000+ Commands for FreeBSD®, OpenBSD, and NetBSD®Power Users Christopher Negus François Caen 76034ffirs.qxd:Toolbox 4/2/08 12:50 PM Page ii 76034ffirs.qxd:Toolbox 4/2/08 12:50 PM Page i BSD UNIX® TOOLBOX 76034ffirs.qxd:Toolbox 4/2/08 12:50 PM Page ii 76034ffirs.qxd:Toolbox 4/2/08 12:50 PM Page iii BSD UNIX® TOOLBOX 1000+ Commands for FreeBSD®, OpenBSD, and NetBSD®Power Users Christopher Negus François Caen 76034ffirs.qxd:Toolbox 4/2/08 12:50 PM Page iv BSD UNIX® Toolbox: 1000+ Commands for FreeBSD®, OpenBSD, and NetBSD® Power Users Published by Wiley Publishing, Inc. 10475 Crosspoint Boulevard Indianapolis, IN 46256 www.wiley.com Copyright © 2008 by Wiley Publishing, Inc., Indianapolis, Indiana Published simultaneously in Canada ISBN: 978-0-470-37603-4 Manufactured in the United States of America 10 9 8 7 6 5 4 3 2 1 Library of Congress Cataloging-in-Publication Data is available from the publisher. No part of this publication may be reproduced, stored in a retrieval system or transmitted in any form or by any means, electronic, mechanical, photocopying, recording, scanning or otherwise, except as permitted under Sections 107 or 108 of the 1976 United States Copyright Act, without either the prior written permission of the Publisher, or authorization through payment of the appropriate per-copy fee to the Copyright Clearance Center, 222 Rosewood Drive, Danvers, MA 01923, (978) 750-8400, fax (978) 646-8600. Requests to the Publisher for permis- sion should be addressed to the Legal Department, Wiley Publishing, Inc., 10475 Crosspoint Blvd., Indianapolis, IN 46256, (317) 572-3447, fax (317) 572-4355, or online at http://www.wiley.com/go/permissions. -

ZFS 2018 and Onward
SEE TEXT ONLY 2018 and Onward BY ALLAN JUDE 2018 is going to be a big year for ZFS RAID-Z Expansion not only FreeBSD, but for OpenZFS • 2018Q4 as well. OpenZFS is the collaboration of developers from IllumOS, FreeBSD, The ability to add an additional disk to an existing RAID-Z VDEV to grow its size with- Linux, Mac OS X, many industry ven- out changing its redundancy level. For dors, and a number of other projects example, a RAID-Z2 consisting of 6 disks to maintain and advance the open- could be expanded to contain 7 disks, source version of Sun’s ZFS filesystem. increasing the available space. This is accomplished by reflowing the data across Improved Pool Import the disks, so as to not change an individual • 2018Q1 block’s offset from the start of the VDEV. The new disk will appear as a new column on the A new patch set changes the way pools are right, and the data will be relocated to main- imported, such that they depend less on con- tain the offset within the VDEV. Similar to figuration data from the system. Instead, the reflowing a paragraph by making it wider, possibly outdated configuration from the sys- without changing the order of the words. In tem is used to find the pool, and partially open the end this means all of the new space shows it read-only. Then the correct on-disk configura- up at the end of the disk, without any frag- tion is loaded. This reduces the number of mentation. -

GELI (8) Freebsd System Manager's Manual GELI (8) NAME Geli
GELI (8) FreeBSD System Manager’s Manual GELI (8) NAME geli — control utility for cryptographic GEOM class SYNOPSIS To compile GEOM ELI into your kernel, place the following lines in your kernel configuration file: device crypto options GEOM_ELI Alternately, to load the GEOM ELI module at boot time, place the following line in your loader.conf(5): geom_eli_load="YES" Usage of the geli(8) utility: geli init [ -bPv][ -a algo ][ -i iterations ][ -K newkeyfile][ -l keylen ][ -s sectorsize ] prov geli label - an alias for init geli attach [ -dpv ][ -k keyfile ] prov geli detach [ -fl] prov . geli stop - an alias for detach geli onetime [ -d][ -a algo][ -l keylen][ -s sectorsize ] prov . geli setkey [ -pPv ][ -i iterations ][ -k keyfile][ -K newkeyfile][ -n keyno] prov geli delkey [ -afv ][ -n keyno] prov geli kill [ -av][ prov . ] geli backup [ -v] prov file geli restore [ -v] file prov geli clear [ -v] prov . geli dump [ -v] prov . geli list geli status geli load geli unload DESCRIPTION The geli utility is used to configure encryption on GEOM providers. The following is a list of the most important features: • Utilizes the crypto(9) framework, so when there is crypto hardware available, geli will make use of it automatically. • Supports many cryptographic algorithms (currently AES, Blowfish and 3DES). • Can create a key from a couple of components (user entered passphrase, random bits from a file, etc.). • Allows to encrypt the root partition - the user will be asked for the passphrase before the root file system is mounted. • The passphrase of the user is strengthened with: B. Kaliski, PKCS #5: Password-Based Cryptography Specification, Version 2.0. -

Freesbie - Français
FreeBSD FreeSBIE - Français Surfer anonymement sur la toile avec Tor et Liste de choses à faire (TODO list) pour la Privoxy prochaine édition de FreeSBIE La vie privée n'est pas seulement importante, c'est une né- Les point suivants sont ceux qui n'ont pas été réalisés FreeBSD cessité. Vous ne voulez pas que d'autres personnes ap- dans la présente version. Si une version possédait toutes prennent les adresses des sites que vous allez visiter, d'où les caractéristiques nécessaires aux utilisateurs et celles FreeSBIE LiveCD vous venez, et ainsi de suite. Les mêmes principes s'appli- souhaitées par les programmeurs alors il n'y aurait plus de quent pour les autres services internet : SSH, IRC, etc. nouvelle version. FreeSBIE fournit deux puissants outils pour rendre la 1. Relecture du code - Bien que la boîte à outils de FreeS- Qu'est ce que FreeSBIE ? navigation anonyme et plus sûre: Tor et Privoxy. Vous BIE ait été complètement réécrite au cours de l'été 2004, FreeSBIE est un système d'exploitation complet utilisable pouvez rediriger vos connexions à travers différents il subsiste bon nombre de parties modifiées qui requièrent à partir d'un CD ou d'un DVD. Il est capable de détecter routeurs et obtenir un anonymat presque parfait. Parce un examen minutieux. automatiquement les composants de votre ordinateur et il qu'une telle configuration est loin d'être simple, FreeSBIE 2. Réécriture de BSDinstaller. Cette tâche progresse rap- reconnaît quantité de cartes graphiques, de périphériques vous assiste avec un script : /usr/local/bin/freesbie_tor. En idement. USB et autres matériels. -

List of BSD Operating Systems
FreeBSD-based SNo Name Description A lightweight operating system that aims to bring the flexibility and philosophy of Arch 1 ArchBSD Linux to BSD-based operating systems. 2 AskoziaPBX Discontinued 3 BSDBox 4 BSDeviant 5 BSDLive 6 Bzerk CD 7 DragonFly BSD Originally forked from FreeBSD 4.8, now developed in a different direction 8 ClosedBSD DesktopBSD is a discontinued desktop-oriented FreeBSD variant using K Desktop 9 DesktopBSD Environment 3.5. 10 EclipseBSD Formerly DamnSmallBSD; a small live FreeBSD environment geared toward developers and 11 Evoke system administrators. 12 FenestrOS BSD 13 FreeBSDLive FreeBSD 14 LiveCD 15 FreeNAS 16 FreeSBIE A "portable system administrator toolkit". It generally contains software for hardware tests, 17 Frenzy Live CD file system check, security check and network setup and analysis. Debian 18 GNU/kFreeBSD 19 Ging Gentoo/*BSD subproject to port Gentoo features such as Portage to the FreeBSD operating 20 Gentoo/FreeBSD system GhostBSD is a Unix-derivative, desktop-oriented operating system based on FreeBSD. It aims to be easy to install, ready-to-use and easy to use. Its goal is to combine the stability 21 GhostBSD and security of FreeBSD with pre-installed Gnome, Mate, Xfce, LXDE or Openbox graphical user interface. 22 GuLIC-BSD 23 HamFreeSBIE 24 HeX IronPort 25 security appliances AsyncOS 26 JunOS For Juniper routers A LiveCD or USB stick-based modular toolkit, including an anonymous surfing capability using Tor. The author also made NetBSD LiveUSB - MaheshaNetBSD, and DragonFlyBSD 27 MaheshaBSD LiveUSB - MaheshaDragonFlyBSD. A LiveCD can be made from all these USB distributions by running the /makeiso script in the root directory. -

967-Malone.Pdf
IN THIS ARTICLE I’M GOING TO LOOK at some less well known security features DAVID MALONE of FreeBSD. Some of these features are com- mon to all the BSDs. Others are FreeBSD- specific or have been extended in some way in FreeBSD. The features that I will be security through discussing are available in FreeBSD 5.4. obscurity First, I’ll mention some features that I don’t plan to cover. FreeBSD jails are like a more powerful version of chroot. Like chroot they are restricted to a subtree A REVIEW OF A FEW OF of the file system, but users (including root) in a jail are also restricted in terms of networking and system FREEBSD’S LESSER-KNOWN calls. It should be safe to give root access to a jail to an untrusted user, making a jail like virtual system, SECURITY CAPABILITIES not unlike some applications of UML [1] or Xen [2] David is a system administrator at Trinity College, but without running separate kernels for each system. Dublin, a researcher in NUI Maynooth, and a com- A lot has already been written about jails [3], so I mitter on the FreeBSD project. He likes to express won’t dwell on them further here. himself on technical matters, and so has a Ph.D. in mathematics and is the co-author of IPv6 Network Another feature that I don’t plan to spend much time Administration (O’Reilly, 2005). on is ACLs. ACLs are an extension of the traditional [email protected] UNIX permissions system to allow you to specify per- missions for users and groups other than the file’s owner and group. -

Introduzione Al Mondo Freebsd Corso Avanzato
Introduzione al mondo FreeBSD corso Avanzato •Struttura •Installazione •Configurazione •I ports •Gestione •Netstudent http://netstudent.polito.it •E.Richiardone [email protected] •Novembre 2012 •CC-by http://creativecommons.org/licenses/by/3.0/it/ The FreeBSD project - 1 • E` un progetto software open • Lo scopo e` mantenere e sviluppare il sistema operativo FreeBSD • Nasce su CDROM come FreeBSD 1.0 nel 1993 • Deriva da un patchkit per 386BSD, eredita codice da UNIX versione Berkeley 1977 • Per problemi legali subisce un rallentamento, release 2.0 nel 1995 con codice royalty-free • Dalla release 4.0 (2000) assume la struttura che ha oggi • Disponibile per x86 32 e 64bit, ia64, MIPS, ppc, sparc... • La mascotte (Beastie) nasce nel 1984 The FreeBSD project - 2 • Erede di 4.4BSD (e` la stessa gente...) • Sistema stabile; sviluppo uniforme; codice molto chiaro, ordinato e ben commentato • Documentazione ufficiale ben curata • Licenza molto permissiva, spesso attrae aziende per progetti commerciali: • saltuariamente progetti collaborano con implementazioni ex-novo (i.e. Intel, GEOM, NDISwrapper, ZFS, GNU/Linux emulation) • Semplificazione di molte caratteristiche tradizionali UNIX Di cosa si tratta Il progetto FreeBSD include: • Un sistema base • Bootloader, kernel, moduli, librerie di base, comandi e utility di base, servizi tradizionali • Sorgenti completi in /usr/src (~500MB) • E` gia` completo (i.e. ipfw, ppp, bind, ...) • Un sistema di gestione per software aggiuntivo • Ports e packages • Documentazione, canali di assistenza, strumenti -

Freebsd Enterprise Storage Polish BSD User Group Welcome 2020/02/11 Freebsd Enterprise Storage
FreeBSD Enterprise Storage Polish BSD User Group Welcome 2020/02/11 FreeBSD Enterprise Storage Sławomir Wojciech Wojtczak [email protected] vermaden.wordpress.com twitter.com/vermaden bsd.network/@vermaden https://is.gd/bsdstg FreeBSD Enterprise Storage Polish BSD User Group What is !nterprise" 2020/02/11 What is Enterprise Storage? The wikipedia.org/wiki/enterprise_storage page tells nothing about enterprise. Actually just redirects to wikipedia.org/wiki/data_storage page. The other wikipedia.org/wiki/computer_data_storage page also does the same. The wikipedia.org/wiki/enterprise is just meta page with lin s. FreeBSD Enterprise Storage Polish BSD User Group What is !nterprise" 2020/02/11 Common Charasteristics o Enterprise Storage ● Category that includes ser$ices/products designed &or !arge organizations. ● Can handle !arge "o!umes o data and !arge num%ers o sim#!tano#s users. ● 'n$olves centra!ized storage repositories such as SA( or NAS de$ices. ● )equires more time and experience%expertise to set up and operate. ● Generally costs more than consumer or small business storage de$ices. ● Generally o&&ers higher re!ia%i!it'%a"aila%i!it'%sca!a%i!it'. FreeBSD Enterprise Storage Polish BSD User Group What is !nterprise" 2020/02/11 EnterpriCe or EnterpriSe? DuckDuckGo does not pro$ide search results count +, Goog!e search &or enterprice word gi$es ~ 1 )00 000 results. Goog!e search &or enterprise word gi$es ~ 1 000 000 000 results ,1000 times more). ● /ost dictionaries &or enterprice word sends you to enterprise term. ● Given the *+,CE o& many enterprise solutions it could be enterPRICE 0 ● 0 or enterpri$e as well +. -
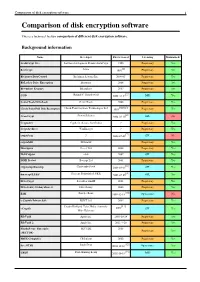
Comparison of Disk Encryption Software 1 Comparison of Disk Encryption Software
Comparison of disk encryption software 1 Comparison of disk encryption software This is a technical feature comparison of different disk encryption software. Background information Name Developer First released Licensing Maintained? ArchiCrypt Live Softwaredevelopment Remus ArchiCrypt 1998 Proprietary Yes [1] BestCrypt Jetico 1993 Proprietary Yes BitArmor DataControl BitArmor Systems Inc. 2008-05 Proprietary Yes BitLocker Drive Encryption Microsoft 2006 Proprietary Yes Bloombase Keyparc Bloombase 2007 Proprietary Yes [2] CGD Roland C. Dowdeswell 2002-10-04 BSD Yes CenterTools DriveLock CenterTools 2008 Proprietary Yes [3][4][5] Check Point Full Disk Encryption Check Point Software Technologies Ltd 1999 Proprietary Yes [6] CrossCrypt Steven Scherrer 2004-02-10 GPL No Cryptainer Cypherix (Secure-Soft India) ? Proprietary Yes CryptArchiver WinEncrypt ? Proprietary Yes [7] cryptoloop ? 2003-07-02 GPL No cryptoMill SEAhawk Proprietary Yes Discryptor Cosect Ltd. 2008 Proprietary Yes DiskCryptor ntldr 2007 GPL Yes DISK Protect Becrypt Ltd 2001 Proprietary Yes [8] cryptsetup/dmsetup Christophe Saout 2004-03-11 GPL Yes [9] dm-crypt/LUKS Clemens Fruhwirth (LUKS) 2005-02-05 GPL Yes DriveCrypt SecurStar GmbH 2001 Proprietary Yes DriveSentry GoAnywhere 2 DriveSentry 2008 Proprietary Yes [10] E4M Paul Le Roux 1998-12-18 Open source No e-Capsule Private Safe EISST Ltd. 2005 Proprietary Yes Dustin Kirkland, Tyler Hicks, (formerly [11] eCryptfs 2005 GPL Yes Mike Halcrow) FileVault Apple Inc. 2003-10-24 Proprietary Yes FileVault 2 Apple Inc. 2011-7-20 Proprietary -

Freebsd-Based Live Disks (Deel 2)
SoftwareBus 2008 6 ----------- FreeBSD-based live disks (deel 2) ------------ Jan Stedehouder In dit tweede deel staan wel stil bij drie GIMP, Inkscape en GQView vullen de live cd’s die op FreeBSD zijn gebaseerd. grafische afdeling in e n Beep Media In het eerste deel bekeken we l i v e cd’s Player, BMPx en MPlayer zorgen v o o r het voor O p e n B S D , NetBSD en Dragonfly. multimediale gebeuren. Dewerkblad- Mooie projecten, maar we misten bij de achtergrond verandert bij iedere vol- meeste de mogelijkheid om de cd op gende start. een harde schijf te installeren. Zullen de drie kandidaten voor dit deel het be- Deze live cd heeft geen mogelijkheid tot ter doen? We bekijken FreeSBIE, Desk- installatie op de harde schijf. In e e n in- topBSD and RoFreeSBIE Zoals we zullen terview met Distrowatch Weekly (num- zien, kan RoFreeSBIE beschouwd worden mer 186, 22 januari 2007) verklaarde als een samensmelting van de andere ontwikkelaar Matteo R o n d a t o dat dit ook twee cd’s. geen hoge prioriteit had. Hij geeft er de voorkeur aan dat gebruikers in dat geval FreeSBIE direct FreeBSD gebruiken. FreeSBIE kan worden gezien als een voort- zetting van het FreeBSD live-project en werd voor het eerst vrijgegeven in 2003. De meest recente vrij- gave (2.0.1) is al weer anderhalf jaar oud en was gebaseerd op FreeBSD 6.2. FreeSBIE presenteert een grafi- sche desktop, geba- seerd op Xfce (met Fluxbox als alternatie- ve mogelijkheid). Het aantal program- Fig. 6:FreeSBIE maakt gebruik van de Xfce gr a fi - ma ’ s is beperkt, maar voor eindgebrui- sche omgeving kers in eerste instantie afdoende.