Natural Language Processing: My ”Grandchild-Bot”
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

The Korean Internet Freak Community and Its Cultural Politics, 2002–2011
The Korean Internet Freak Community and Its Cultural Politics, 2002–2011 by Sunyoung Yang A thesis submitted in conformity with the requirements for the degree of Doctor of Philosophy Graduate Department of Anthropology University of Toronto © Copyright by Sunyoung Yang Year of 2015 The Korean Internet Freak Community and Its Cultural Politics, 2002–2011 Sunyoung Yang Doctor of Philosophy Department of Anthropology University of Toronto 2015 Abstract In this dissertation I will shed light on the interwoven process between Internet development and neoliberalization in South Korea, and I will also examine the formation of new subjectivities of Internet users who are also becoming neoliberal subjects. In particular, I examine the culture of the South Korean Internet freak community of DCinside.com and the phenomenon I have dubbed “loser aesthetics.” Throughout the dissertation, I elaborate on the meaning-making process of self-reflexive mockery including the labels “Internet freak” and “surplus (human)” and gender politics based on sexuality focusing on gender ambiguous characters, called Nunhwa, as a means of collective identity-making, and I explore the exploitation of unpaid immaterial labor through a collective project making a review book of a TV drama Painter of the Wind. The youth of South Korea emerge as the backbone of these creative endeavors as they try to find their place in a precarious labor market that has changed so rapidly since the 1990s that only the very best succeed, leaving a large group of disenfranchised and disillusioned youth. I go on to explore the impact of late industrialization and the Asian financial crisis, and the nationalistic desire not be left behind in the age of informatization, but to be ahead of the curve. -

Publications Contents Digest January/2020
IEEE Communications Society Publications Contents Digest January/2020 Direct links to magazine and journal s and full paper pdfs via IEEE Xplore ComSoc Vice President – Publications – Robert Schober Director – Journals – Michele Zorzi Director – Magazines – Ekram Hossain Magazine Editors EIC, IEEE Communications Magazine – Tarek El-Bawab AEIC, IEEE Communications Magazine – Antonio Sanchez-Esquavillas EIC, IEEE Network Magazine – Mohsen Guizani AEIC, IEEE Network Magazine – David Soldani EIC, IEEE Wireless Communications Magazine – Yi Qian AEIC, IEEE Wireless Communications Magazine – Nirwan Ansari EIC, IEEE Communications Standards Magazine – Glenn Parsons AEIC, IEEE Communications Standards Magazine – Zander Lei EIC, IEEE Internet of Things Magazine — Keith Gremban EIC, China Communications – Zhongcheng Hou Journal Editors EIC, IEEE Transactions on Communications –Tolga M. Duman EIC, IEEE Journal on Selected Areas In Communications (J-SAC) –Raouf Boutaba EIC, IEEE Communications Letters – Marco Di Renzo EIC, IEEE Communications Surveys & Tutorials – Ying-Dar Lin EIC, IEEE Transactions on Network & Service Management (TNSM) – Filip De Turck EIC, IEEE Wireless Communications Letters – Kai Kit Wong EIC, IEEE Transactions on Wireless Communications – Junshan Zhang EIC, IEEE Transactions on Mobile Communications – Marwan Krunz EIC, IEEE/ACM Transactions on Networking – Eytan Modiano EIC, IEEE/OSA Journal of Optical Communications & Networking (JOCN) – Jane M. Simmons EIC, IEEE/OSA Journal of Lightwave Technology – Gabriella Bosco Co-EICs, -

Final Program Pdf Version
2021 JOINT IEEE INTERNATIONAL SYMPOSIUM ON ELECTROMAGNETIC COMPATIBILITY, SIGNAL & POWER INTEGRITY, AND EMC EUROPE ENTER THE VIRTUAL PLATFORM AT: www.engagez.net/emc-sipi2021 CHAIRMAN’S MESSAGE TABLE OF CONTENTS A LETTER FROM 2021 GENERAL CHAIR, Chairman’s Message 2 ALISTAIR DUFFY & BRUCE ARCHAMBEAULT Message from the co-chairs Thank You to Our Sponsors 4 Twelve months ago, I think we all genuinely believed that we would have met up this year in either or Week 1 Schedule At A Glance 6 both of Raleigh and Glasgow. It was virtually inconceivable that we would be in the position of needing to move our two conferences this year to a virtual platform. For those who attended the virtual EMC Clayton R Paul Global University 7 Europe last year, who would have thought that they would not be heading to Glasgow with its rich history and culture? However, as the phrase goes, “we are where we are”. Week 2 Schedule At A Glance: 2-6 Aug 8 A “thank you” is needed to all the authors and presenters because rather than the Joint IEEE Technical Program 12 BRINGING International Symposium on EMC + SIPI and EMC Europe being a “poor relative” of the event that COMPATIBILITY had been planned, people have really risen to the challenge and delivered a program that is a Week 3 Schedule At A Glance: 9-13 Aug 58 TO ENGINEERING virtual landmark! Usually, a Chairman’s message might tell you what is in the program but we will Keynote Speaker Presentation 60 INNOVATIONS just ask you to browse through the flipbook final program and see for yourselves. -

Appropriation of Religion: the Re-Formation of the Korean Notion of Religion in Global Society
Appropriation of Religion: The Re-formation of the Korean Notion of Religion in Global Society Kyuhoon Cho Thesis Submitted to the Faculty of Graduate and Postdoctoral Studies In Partial Fulfillment of the Requirements For the Degree of Doctor of Philosophy In Religious Studies Department of Classics & Religious Studies Faculty of Arts University of Ottawa © Kyuhoon Cho, Ottawa, Canada, 2013 ABSTRACTS Appropriation of Religion: The Re-formation of the Korean Notion of Religion in Global Society By Kyuhoon Cho Doctor of Philosophy in Religious Studies, University of Ottawa, Canada Dr. Peter F. Beyer, Supervisor Dr. Lori G. Beaman, Co-supervisor This dissertation explores the reconfiguration of religion in modern global society with a focus on Koreans’ use of the category of religion. Using textual and structural analysis, this study examines how the notion of religion is structurally and semantically contextualized in the public sphere of modern Korea. I scrutinize the operation of the differentiated communication systems that produces a variety of discourses and imaginaries on religion and religions in modern Korea. Rather than narrowly define religion in terms of the consequence of religious or scientific projects, this dissertation shows the process in which the evolving societal systems such as politics, law, education, and mass media determine and re-determine what counts as religion in the emergence of a globalized Korea. I argue that, ever since the Western notion of religion was introduced to East Asia in the eighteenth and nineteenth centuries, religion was, unlike in China and Japan, constructed as a positive social component in Korea, because it was considered to be instrumental in maintaining Korean identity and modernizing the Korean nation in the new global context. -

Strategic Advisory Group of Experts (SAGE) on Immunization 22-24 March 2021 Virtual Meeting Geneva, Switzerland
Strategic Advisory Group of Experts (SAGE) on Immunization 22-24 March 2021 Virtual meeting Geneva, Switzerland List of Participants SAGE Members Aggarwal, Professor Rakesh Director Jawaharlal Institute of Postgraduate Medical Education and Research (JIPMER) Puducherry India Cravioto, Professor Alejandro Professor Facultad de Medicina, Universidad Nacional Autónoma de México Coyoacan Mexico Jani, Dr Ilesh Director General National Institute of Health, Ministry of Health Maputo Mozambique Jawad, Dr Jaleela Head of immunization group Public Health Directorate, Ministry of Health Manama Bahrain Kochhar, Dr Sonali Clinical Associate Professor, Department of Global Health University of Washington Seattle United States of America MacDonald, Professor Noni Professor of Paediatrics Division of Paediatric Infectious Diseases, Dalhousie University Halifax, Nova Scotia Canada Madhi, Professor Shabir Professor of Vaccinology University of the Witwatersrand Johannesburg South Africa McIntyre, Professor Peter Professor Dept of Women's and Children's Health, Dunedin School of Medicine, University of Otago Dunedin New Zealand Page 1 of 41 Mohsni, Dr Ezzeddine Senior Technical Adviser Global Health Development (GHD), The Eastern Mediterranean Public Health Network (EMPHNET) Amman Jordan Mulholland, Professor Kim Murdoch Children’s Research Institute, University of Melbourne Parkville Australia Neuzil, Professor Kathleen Director Centre for Vaccine Development and Global Health, University of Maryland School of Medicine, Baltimore United States of America -

Transparent Conductors Based on Microscale/Nanoscale Materials for High Performance Devices
TRANSPARENT CONDUCTORS BASED ON MICROSCALE/NANOSCALE MATERIALS FOR HIGH PERFORMANCE DEVICES by Tongchuan Gao B. S., Tsinghua University, China, 2011 Submitted to the Graduate Faculty of the Swanson School of Engineering in partial fulfillment of the requirements for the degree of Doctor of Philosophy University of Pittsburgh 2016 UNIVERSITY OF PITTSBURGH SWANSON SCHOOL OF ENGINEERING This dissertation was presented by Tongchuan Gao It was defended on August 31st, 2016 and approved by Paul W. Leu, Ph.D., Associate Professor, Department of Industrial Engineering Bopaya Bidanda, Ph.D., Ernest E. Roth Professor, Department of Industrial Engineering Jung-kun Lee, Ph.D., Associate Professor, Department of Mechanical Engineering & Materials Science Youngjae Chun, Ph.D., Assistant Professor, Department of Industrial Engineering Dissertation Director: Paul W. Leu, Ph.D., Associate Professor, Department of Industrial Engineering ii Copyright © by Tongchuan Gao 2016 iii TRANSPARENT CONDUCTORS BASED ON MICROSCALE/NANOSCALE MATERIALS FOR HIGH PERFORMANCE DEVICES Tongchuan Gao, PhD University of Pittsburgh, 2016 Transparent conductors are important as the top electrode for a variety of optoelectronic devices, including solar cells, light-emitting diodes (LEDs), flat panel displays, and touch screens. Doped indium tin oxide (ITO) thin films are the predominant transparent conductor material. However, ITO thin films are brittle, making them unsuitable for the emerging flex- ible devices, and suffer from high material and processing cost. In my thesis, we developed a variety of transparent conductors toward a performance comparable with or superior to ITO thin films, with lower cost and potential for scalable manufacturing. Metal nanomesh (NM), hierarchical graphene/metal microgrid (MG), and hierarchical metal NM/MG ma- terials were investigated. -

3.1: a Novel Architecture for Autostereoscopic 2D3D Switchable
51st Annual SID Symposium, Seminar, and Exhibition 2013 (Display Week 2013) SID International Symposium Digest of Technical Papers Volume 44 Vancouver, Canada 19-24 May 2013 Part 1 of 2 ISBN: 978-1-5108-1530-8 Printed from e-media with permission by: Curran Associates, Inc. 57 Morehouse Lane Red Hook, NY 12571 Some format issues inherent in the e-media version may also appear in this print version. Copyright© (2013) by SID-the Society for Information Display All rights reserved. Printed by Curran Associates, Inc. (2015) For permission requests, please contact John Wiley & Sons at the address below. John Wiley & Sons 111 River Street Hoboken, NJ 07030-5774 Phone: (201) 748-6000 Fax: (201) 748-6088 [email protected] Additional copies of this publication are available from: Curran Associates, Inc. 57 Morehouse Lane Red Hook, NY 12571 USA Phone: 845-758-0400 Fax: 845-758-2633 Email: [email protected] Web: www.proceedings.com TABLE OF CONTENTS PART 1 SESSION 3: AUTOSTEREOSCOPIC AND MULTI-VIEW I 3.1: A Novel Architecture for Autostereoscopic 2D/3D Switchable Display Using Dual-Layer OLED Backlight Module .................................................................................................................................................................................................................1 Yi-Jun Wang, Jun Liu, Wei-Chung Chao, Bo-Ru Yang, Jian-Gang Lu, Han-Ping D. Shieh 3.2: The Application of Flexible Liquid-Crystal Display in High Resolution Switchable Autostereoscopic 3D Display .................................................................................................................................................................................................................5 -

Beyond Korean Style: Shaping a New Growth Formula Growth a New Shaping Style: Korean Beyond
McKinsey Global Institute McKinsey Global Institute Beyond Korean style: Shaping a new growth formula April 2013 Beyond Korean style: Shaping a new growth formula The McKinsey Global Institute The McKinsey Global Institute (MGI), the business and economics research arm of McKinsey & Company, was established in 1990 to develop a deeper understanding of the evolving global economy. Our goal is to provide leaders in the commercial, public, and social sectors with the facts and insights on which to base management and policy decisions. MGI research combines the disciplines of economics and management, employing the analytical tools of economics with the insights of business leaders. Our “micro-to-macro” methodology examines microeconomic industry trends to better understand the broad macroeconomic forces affecting business strategy and public policy. MGI’s in-depth reports have covered more than 20 countries and 30 industries. Current research focuses on six themes: productivity and growth, natural resources, labor markets, the evolution of global financial markets, the economic impact of technology and innovation, and urbanization. Recent reports have assessed job creation, resource productivity, cities of the future, the economic impact of the Internet, and the future of manufacturing. MGI is led by McKinsey & Company directors Richard Dobbs and James Manyika. Michael Chui, Susan Lund, and Jaana Remes serve as MGI principals. Project teams are led by the MGI principals and a group of senior fellows and include consultants from McKinsey & Company’s offices around the world. These teams draw on McKinsey & Company’s global network of partners and industry and management experts. In addition, leading economists, including Nobel laureates, act as research advisers. -

Rodney S. Ruoff
Rodney S. Ruoff (512) 471 4691 [email protected] http://bucky-central.me.utexas.edu/publications.html Address Dept of Mechanical Engineering and the Materials Science and Engineering Program Cockrell School of Engineering The University of Texas at Austin 204 E. Dean Keeton Street; Stop C2200 Austin, TX 78712-1591 Education 1988 Ph.D. Chemical Physics, University of Illinois-Urbana Thesis: "Fourier-Transform Microwave Spectroscopy of Hydrogen-bonded Trimers and of Conformer Relaxation in Free Jets" (Prof. H. S. Gutowsky, research advisor). 1981 B.S. Chemistry, University of Texas-Austin, High Honors Professional Experience Cockrell Family Regents Chair Sept ‘07-present University of Texas at Austin John Evans Professor of Nanoengineering 2003 – Aug 2007 Northwestern University Full Professor, Department of Mechanical Engineering 2000 - 2007 Director, NU BIMat Institute (A NASA URETI Institute) Northwestern University, IL Associate Professor, Department of Physics 1997 - 2000 Washington University, MO Research Staff Scientist, Molecular Physics Laboratory 1991 – 1996 SRI International Postdoctoral Fellow 1990 – 1991 IBM-Watson Research Laboratory Fulbright Postdoctoral Fellow Max Planck Institut fuer Stroemungsforschung, Goettingen, Germany 1989 - 1990 Professional Associations and Activities Managing Editor and Editorial Board Member: NANO (http://www.worldscinet.com/nano/nano.shtml) Editorial Advisory Board: Carbon (http://www.elsevier.com/wps/find/journaldescription.cws_home/258/description#description) Editorial Board Member: -
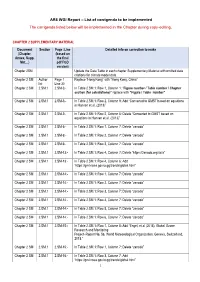
AR6 WGI Report – List of Corrigenda to Be Implemented the Corrigenda Listed Below Will Be Implemented in the Chapter During Copy-Editing
AR6 WGI Report – List of corrigenda to be implemented The corrigenda listed below will be implemented in the Chapter during copy-editing. CHAPTER 2 SUPPLEMENTARY MATERIAL Document Section Page :Line Detailed info on correction to make (Chapter, (based on Annex, Supp. the final Mat…) pdf FGD version) Chapter 2SM Update the Data Table in each chapter Supplementary Material with omitted data citations for climate model data. Chapter 2 SM Author Page 1 Replace “Hong Kong” with “Hong Kong, China” list Line 30 Chapter 2 SM 2.SM.1 2.SM-3:- In Table 2.SM.1: Row 1, Column 1: “Figure number / Table number / Chapter section (for calculations)” replace with “Figure / Table number” Chapter 2 SM 2.SM.1 2.SM-3:- In Table 2.SM.1: Row 2, Column 9: Add “Converted to GMST based on equations in Hansen et al. (2013)” Chapter 2 SM 2.SM.1 2.SM-3:- In Table 2.SM.1: Row 2, Column 6: Delete “Converted to GMST based on equations in Hansen et al. (2013)” Chapter 2 SM 2.SM.1 2.SM-5:- In Table 2.SM.1: Row 7, Column 7: Delete “zenodo” Chapter 2 SM 2.SM.1 2.SM-6:- In Table 2.SM.1: Row 2, Column 7: Delete “zenodo” Chapter 2 SM 2.SM.1 2.SM-6:- In Table 2.SM.1: Row 3, Column 7: Delete “zenodo” Chapter 2 SM 2.SM.1 2.SM-13:- In Table 2.SM.1: Row 4, Column 7: Delete “https://zenodo.org/xxxx” Chapter 2 SM 2.SM.1 2.SM-13:- In Table 2.SM.1: Row 4, Column 6: Add “https://gml.noaa.gov/ccgg/trends/global.html” Chapter 2 SM 2.SM.1 2.SM-14:- In Table 2.SM.1: Row 1, Column 7: Delete “zenodo” Chapter 2 SM 2.SM.1 2.SM-14:- In Table 2.SM.1: Row 2, Column 7: Delete “zenodo” Chapter 2 SM 2.SM.1 2.SM-14:- In Table 2.SM.1: Row 3, Column 7: Delete “zenodo” Chapter 2 SM 2.SM.1 2.SM-14:- In Table 2.SM.1: Row 4, Column 7: Delete “zenodo” Chapter 2 SM 2.SM.1 2.SM-14:- In Table 2.SM.1: Row 5, Column 7: Delete “zenodo” Chapter 2 SM 2.SM.1 2.SM-14:- In Table 2.SM.1: Row 6, Column 7: Delete “zenodo” Chapter 2 SM 2.SM.1 2.SM-15:- In Table 2.SM.1: Row 1, Column 8: Add “Engel, et al (2018), Global Ozone Research and Monitoring Project–Report No. -

Language and Culture Center University of Houston
Summer 2009 Language and Culture Center University of Houston Inside this Issue: Director’s Message 2 Scholarship Recipients 3 Life Lessons 4 – 5 Glimpses into My Culture 6 – 13 A Key Person 14 – 15 LCC Culture Festival 16 – 21 My Home 22 – 26 Art Appreciation 27 – 29 Blogging 30 – 32 Culture Shock 33 Dave’s Page 34 Director’s Message by Joy Tesh We teach English here at the Language and Culture Center, but we know that a lot more is going on than the writing of essays and the practice of the past perfect tense. For one thing, we know that English is not the only language you learn here. I am certain of that when a student from Saudi Arabia enters our office in the afternoon and says in Spanish, “Hola, ¿qué pasa?" Later, someone from Venezuela will greet me in Chinese. LCC students are enjoying the company of friends from all over the world. Each of you has a very particular story. We watch you as you enter this very new culture in the United States (in some cases, we meet you at the airport), and we are prepared to help you through the inevitable experience of culture shock. The Language and Culture Center is a bridge for you -- a bridge between the language and customs and traditions of your country and the language and customs and traditions of the United States. Our job is not only to teach you English, but also to help you understand and prepare for the "newness" and "strangeness" of this country, its educational system, and its people. -

온라인 춘계학술발표회 온라인 KNS 2020 Spring 온라인 춘계학술발표회
www.kns.org KNS 2020 Spring 온라인 춘계학술발표회 KNS 2020 Spring 온라인 춘계학술발표회 KOREAN NUCLEAR SOCIETY KOREAN NUCLEAR 2020. 7. 8.(수) ~ 10.(금) Virtual Spring Meeting SOCIETY (http://2020springmeeting.kns.org) www.kns.org KNS 2020 Spring 온라인 춘계학술발표회 2020. 7. 8.(수) ~ 10.(금) Virtual Spring Meeting (http://2020springmeeting.kns.org) CONTENTS 03 학회장 인사말 04 종합일정 안내 05 축사 08 참가요령(논문발표자, 일반참가자) 10 한국원자력학회 제32대 임원진 11 한국원자력학회 원자력이슈 및 소통위원회 위원 12 한국원자력학회 편집위원회 위원 13 한국원자력학회 연구부회장/차기연구부회장·지부장 14 한국원자력학회 포상 및 장학위원회 위원/사무국 15 특별강연 17 2020 춘계학술발표회 수상자 명단 19 Workshop 20 Thorium Energy and Accelerator Driven System 21 4 시대 전 22 전 23 분과별 논제 및 발표자 24 1 로시 Reactor System Technology 29 2 로 Reactor Physics and Computational Science 33 3 시 성 Nuclear Facility Decommissioning and Radioactive Waste Management 38 4 Nuclear Fuel and Materials 45 5 Nuclear Thermal Hydraulics 54 6 전 Nuclear Safety 62 7 Radiation Protection 64 8 Radiation Utilization and Instrumentation 69 9 Quantum Engineering and Nuclear Fusion 71 10 전 Nuclear Power Plant construction and Operation Technology 74 11 Nuclear Policy Human Resources and Cooperation 77 12 동 Nuclear IC Human Factors and Automatic Remote Systems [ 한국원자력학회 특별회원 광고 ] 2 2020 7 8 10 학회장 인사말 ? 32대 장 . 로19 전로 . 시 . 로19 대(Untact) 로 , 50 역 로 2020 장 아 대 로 . 5 로 민병주 장 구 성 . 6 로19 전 아 로 . 시 성 유 로 . 로19 로 피 시 로 대 성로 . 장 로 동 시 . 로 시 로 로 시 , .