VISUALIZING CLASS DIAGRAM USING Orientdb DATA-STORE
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Preview Orientdb Tutorial
OrientDB OrientDB About the Tutorial OrientDB is an Open Source NoSQL Database Management System, which contains the features of traditional DBMS along with the new features of both Document and Graph DBMS. It is written in Java and is amazingly fast. It can store 220,000 records per second on commodity hardware. In the following chapters of this tutorial, we will look closely at OrientDB, one of the best open-source, multi-model, next generation NoSQL product. Audience This tutorial is designed for software professionals who are willing to learn NoSQL Database in simple and easy steps. This tutorial will give a great understanding on OrientDB concepts. Prerequisites OrientDB is NoSQL Database technologies which deals with the Documents, Graphs and traditional database components, like Schema and relation. Thus it is better to have knowledge of SQL. Familiarity with NoSQL is an added advantage. Disclaimer & Copyright Copyright 2018 by Tutorials Point (I) Pvt. Ltd. All the content and graphics published in this e-book are the property of Tutorials Point (I) Pvt. Ltd. The user of this e-book is prohibited to reuse, retain, copy, distribute or republish any contents or a part of contents of this e-book in any manner without written consent of the publisher. We strive to update the contents of our website and tutorials as timely and as precisely as possible, however, the contents may contain inaccuracies or errors. Tutorials Point (I) Pvt. Ltd. provides no guarantee regarding the accuracy, timeliness or completeness of our website or its contents including this tutorial. If you discover any errors on our website or in this tutorial, please notify us at [email protected]. -

The Java API Quick Reference You Can Create Both Local (That Is, Without Using a Remote Server) and Remote Database with the Java API
The Java API quick reference You can create both local (that is, without using a remote server) and remote database with the Java API. Each kind of database has a specific related class, but they expose the same interface: • To create a local document database, use the ODatabaseDocumentTx class: ODatabaseDocumentTx db = new ODatabaseDocumentTx ("local:<path>/<db-name>").create(); • To create a local graph database, use the OGraphDatabase class: OGraphDatabase db = new GraphDatabase("local:<path>/<db-name>"). create(); • To create a local object database, use the OObjectDatabaseTx class: OGraphDatabase db = new GraphDatabase("local:<path>/<db-name>"). create(); • To create a remote database: new OServerAdmin("remote:<db-host>").connect(<root- username>,<root-password>).createDatabase(<db-name>,<db- type>,<storage-type>).close(); • To drop a remote database: new OServerAdmin("remote:<db-host>/<db-name>").connect(<root- username>,<root-password>).dropDatabase(); Where: • path: This specifies the path where you wish to create the new database. • db-host: This is the remote host. It could be an IP address or the name of the host. • root-user: This is the root username as defined in the server config file. • root-password: This is the root password as defined in the server config file. • db-name: This is the name of the database. • db-type: This specifies the type of database. It can be "document" or "graph". • storage-type: This specifies the storage type. It can be local or memory. local means that the database will be persistent, while memory means that the database will be volatile. Appendix Open and close connections To open a connection, the open API is available: <database>(<db>).open(<username>,<password>); Where: • database: This is a database class. -
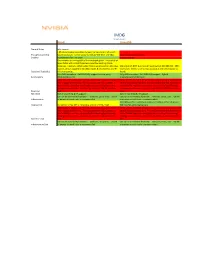
Neo4j Orientdb
IMDG Graph-based Neo4J OrientDB General Notes jdbc support > 85 referenceable customers; largest market share of all graph- Thought Leadership based databases; named accounts include Wal-Mart and EBay. 33 referenceable customers Stability In production for > 10 years Created in 2010. One instance is running 60% of the Facebook graph. Thousands of times faster with 10-100 times less code than existing Oracle instances. Unable to obtain actual figures on production data sizes. Max size is 19.8 EB; max rows in result set is 2,000,000,000. 150K Current version capable of 32 billion nodes & relationships and 64 inserts/sec. Seems to be at least as good as the performance as Capacity / Scalability billion properties. Neo4J. Fully ACID compliant. Full JDBC/SQL support (via 3rd party Fully ACID compliant. Full JDBC/SQL support. Hybrid Functionality jdbc4sparql driver). Graph/Document database. While specific Neo4J is hard to find, senior Java resources should be While specific OrientDB is hard to find, senior Java resources should able to adapt quickly to it. The most expensive skill, however, is be able to adapt quickly to it. The most expensive skill, however, is that of NoSQL expertise, specifically data sharding (partitioning) that of NoSQL expertise, specifically data sharding (partitioning) strategies across nodes. Ability to tune JVM's > 128 GB is hard to strategies across nodes. Ability to tune JVM's > 128 GB is hard to Expertise find. find. Resilience Built in clustering & HA support. Built in clustering & HA support. Can run on commodity hardware -- windows, Linux, Unix. 128 GB Can run on commodity hardware -- windows, Linux, Unix. -

The Database Designed for the Modern World
– 888 953 9572 (US) +44 203 3971 609 (International) [email protected] www.orientdb.com The database designed for the modern world The world runs on big data. Owning that data to build transformative applications is now more critical than ever. That’s why OrientDB developed the world’s first multi-model graph database. Leverage your data to the fullest extent. Performance Security Scalability Process complex transactions Protect your data and ensure your Collect, process, and analyze enormous quickly with a high-performance company remains compliant with a volumes of data in real time with a NoSQL database built for today’s fully encrypted database protected database designed to scale to meet the leading enterprises. by a proprietary algorithm. needs of today’s largest and fastest- moving organizations. Benefits Multi-Model Organize and manage complicated data sets in a single database ■ Speed: Store up to 120,000 records per second and to increase productivity, reduce costs, and eliminate complexity. process transactions 10x Simplify database management and unlock the full potential of faster than competitors. the data your organization collects. Store and analyze structured ■ Ease of use: Get results and unstructured data with a NoSQL database engineered to serve immediately with a plug- as your primary RDBMS. Modernize the way your organization and-play database solution leverages data and move past your competitors that still rely on that runs on any platform traditional master-slave architecture. and uses SQL as its query language. Native Graph Database ■ All-in-one platform: Manage Understand the relationships between disparate sets of data more data without having to hop thoroughly with a database that enables you to store, query, and from platform to platform. -

A Simplified Database Pattern for the Microservice Architecture
DBKDA 2016 : The Eighth International Conference on Advances in Databases, Knowledge, and Data Applications A Simplified Database Pattern for the Microservice Architecture Antonio Messina, Riccardo Rizzo, Pietro Storniolo, Alfonso Urso ICAR - CNR Palermo, Italy Email: fmessina, ricrizzo, storniolo, [email protected] Abstract—Microservice architectures are used as alternative to The microservices pattern implies several important auxili- monolithic applications because they are simpler to scale and ary patterns, such as, for example, those which concern how more flexible. Microservices require a careful design because each clients access the services in a microservices architecture, how service component should be simple and easy to develop. In this clients requests are routed to an available service instance, or paper, a new microservice pattern is proposed: a database that how each service use a database. can be considered a microservice by itself. We named this new pattern as The Database is the Service. The proposed simplified In the new microservice pattern proposed in this paper, database pattern has been tested by adding ebXML registry a database, under certain circumstances and thanks to the capabilities to a noSQL database. integration of some business logic, can be considered a mi- Keywords–microservices, scalable applications, continuous de- croservice by itself. It will be labeled as The database is the livery, microservices patterns, noSQL, database service pattern. The remainder of the paper is organized as follows: Section 2 presents a brief overview about the old monolithic style and I. INTRODUCTION its drawbacks. The microservices architectures and the related The microservice architectural style [1] is a recent approach pattern are described in Section 3. -

Visualizing Class Diagram Using Orientdb Nosql Data-Store
Visualizing Class Diagram Using OrientDB NoSQL Data-Store Thesis submitted in partial fulfilment of the requirements for the award of degree of Master of Engineering in Software Engineering Submitted By Sawinder Kaur (Roll No. 801431025) Under the supervision of: Dr. Karamjit Kaur Assistant Professor COMPUTER SCIENCE AND ENGINEERING DEPARTMENT THAPAR UNIVERSITY PATIALA – 147004 June 2016 3 ACKNOWLEDGEMENTS I am highly grateful for the assistance of all the individuals who spread their valuable time to help me complete my thesis work in time. Foremost I would like to thank my supervisor Ms. Karamjit Kaur for her constant guidance, in-depth knowledge, immense patience, invaluable time, encouraging words and worthy suggestions that helped me in completing my work. Under her guidance, I explored new areas of research. Her practical work approach helped me expand my horizon of research perspective. She has always been a moral support and true guide throughout my research period. I am also thankful to Dr. Maninder Singh, Head of CSED, and the learned faculty of my department Computer Science and Engineering for their support. The intermediate deadlines set by them helped me work more efficiently. I am indebted to my prestigious institute Thapar University, for providing me a learning and progressive environment. My special thanks to all my friends for their endless support, appreciation and moral boost at times of need. I owe a lot to my family for their emotional support and faith in me, for providing me with an opportunity to be a part of this research programme. Last but not the least I thank Almighty for providing me enough inner strength to pursue my goals and accomplish my work. -

How to Install Orientdb Onto Linux
Introducing OrientDB December 2016 -- email any questions to [email protected] OrientDB and Java OrientDB offers many advantages to Java software developers including the ability to run their applications inside the same Java Virtual Machine (JVM) as OrientDB. As no ORM (object-relational mapping) layer exists between your POJO classes and OrientDB’s object schema, there is no impedance mismatch to drag down productivity. In brief we will install OrientDB and then get familiar with its object.load(), object.save(), and object.update() features of its object database through its Java Object API. Running OrientDB in a production environment however requires more knowledge. The A to Z of OrientDB These are the key knowledge buckets that lead to an expert grasp of OrientDB from both a Java Developer and System Administrator’s point of view is to 1. Install OrientDB onto a local or cloud Linux server 2. Configure OrientDB to run as a service (startup after reboot) 3. Learn to talk to OrientDB through its command console 4. Learn to talk to OrientDB through its web interface 5. Learn to connect to OrientDB via its Java Object API 6. Learn to copy, backup, replicate and recover OrientDB 7. Run OrientDB behind an Apache web server proxy There is more to OrientDB than initially meets the eye. It has an “in memory” feature so that your unit tests can work with OrientDB using memory based instead of disk based storage. You can also talk to its RESTful Web Services interface to simply create, read, update and delete both documents and objects with simple HTTP GET, PUT and POST commands. -

Demystifying Graph Databases: Analysis and Taxonomy of Data Organization, System Designs, and Graph Queries
1 Demystifying Graph Databases: Analysis and Taxonomy of Data Organization, System Designs, and Graph Queries MACIEJ BESTA, Department of Computer Science, ETH Zurich ROBERT GERSTENBERGER, Department of Computer Science, ETH Zurich EMANUEL PETER, Department of Computer Science, ETH Zurich MARC FISCHER, PRODYNA (Schweiz) AG MICHAŁ PODSTAWSKI, Future Processing CLAUDE BARTHELS, Department of Computer Science, ETH Zurich GUSTAVO ALONSO, Department of Computer Science, ETH Zurich TORSTEN HOEFLER, Department of Computer Science, ETH Zurich Graph processing has become an important part of multiple areas of computer science, such as machine learning, computational sciences, medical applications, social network analysis, and many others. Numerous graphs such as web or social networks may contain up to trillions of edges. Often, these graphs are also dynamic (their structure changes over time) and have domain-specific rich data associated with vertices and edges. Graph database systems such as Neo4j enable storing, processing, and analyzing such large, evolving, and rich datasets. Due to the sheer size of such datasets, combined with the irregular nature of graph processing, these systems face unique design challenges. To facilitate the understanding of this emerging domain, we present the first survey and taxonomy of graph database systems. We focus on identifying and analyzing fundamental categories of these systems (e.g., triple stores, tuple stores, native graph database systems, or object-oriented systems), the associated graph models (e.g., RDF or Labeled Property Graph), data organization techniques (e.g., storing graph data in indexing structures or dividing data into records), and different aspects of data distribution and query execution (e.g., support for sharding and ACID). -

Graph Databases Comparison: Allegrograph, Arangodb, Infinitegraph, Neo4j, and Orientdb
Graph Databases Comparison: AllegroGraph, ArangoDB, InfiniteGraph, Neo4J, and OrientDB Diogo Fernandes1 and Jorge Bernardino1,2 1Polytechnic of Coimbra - ISEC, Rua Pedro Nunes, Coimbra, Portugal 2CISUC – Centre for Informatics and Systems of the University of Coimbra, Portugal Keywords: Graph databases, NoSQL databases, AllegroGraph, ArangoDB, InfiniteGraph, Neo4J, OrientDB. Abstract: Graph databases are a very powerful solution for storing and searching for data designed for data rich in relationships, such as Facebook and Twitter. With data multiplication and data type diversity there has been a need to create new storage and analysis platforms that structure irregular data with a flexible schema, maintaining a high level of performance and ensuring data scalability effectively, which is a problem that relational databases cannot handle. In this paper, we analyse the most popular graph databases: AllegroGraph, ArangoDB, InfiniteGraph, Neo4J and OrientDB. We study the most important features for a complete and effective application, such as flexible schema, query language, sharding and scalability. 1 INTRODUCTION model relationships between objects. In this context, a graph is basically a structure, which is represented Nowadays, data volume is growing exponentially in by nodes, or also called vertices (the entities), by social networks, such as Facebook and Twitter, edges (the relations) that are the lines that connect which store and process massive amounts of data the various nodes and by properties (attributes). daily, where this data reaches petabytes of storage. Therefore, the graph databases can simply be Current relational databases are predominant in the described as a way of representing and storing data, market, but their adaptability is poor in processing using their structures: nodes, edges, and properties. -
A Demonstration of Noda: Unified Access to Nosql Stores Nikolaos Koutroumanis Nikolaos Kousathanas Dept
A Demonstration of NoDA: Unified Access to NoSQL Stores Nikolaos Koutroumanis Nikolaos Kousathanas Dept. of Digital Systems Dept. of Digital Systems University of Piraeus University of Piraeus Piraeus, Greece Piraeus, Greece [email protected] [email protected] Christos Doulkeridis Akrivi Vlachou Dept. of Digital Systems Dept.of Inf. & Com.Syst.Engineering University of Piraeus University of Aegean Piraeus, Greece Karlovasi, Greece [email protected] [email protected] ABSTRACT which use a common schema that allows for a clear separation and In this demo paper, we present a system prototype, called NoDA, independence between application and storage. that unifies access to NoSQL stores, by exposing a single interface to Motivated by this limitation, we present the system architecture big data developers. This hides the heterogeneity of NoSQL stores, of NoDA [8], a prototype for unified data access to NoSQL stores. in terms of different query languages, non-standardized access, and NoDA acts as an intermediate abstraction layer between applica- different data models. NoDA comprises a layer positioned on top tion code and the underlying NoSQL store. Thus, NoDA offers a set of NoSQL stores that defines a set of basic data access operators of generic data access operators (e.g., filter, project, sort) using a (filter, project, aggregate, etc.), implemented for different NoSQL familiar vocabulary for developers. These operators are internally engines. The provision of generic data access operators enables a implemented for different stores, thus hiding the heterogeneous declarative interface using SQL as query language. Furthermore, languages from the developer. One advantage of using these op- NoDA is extended to provide more complex operators, such as erators is that the same application code becomes portable across geospatial operators, which are only partially supported by NoSQL NoSQL stores. -
Consistency Models of Nosql Databases
future internet Review Consistency Models of NoSQL Databases Miguel Diogo 1, Bruno Cabral 1,2 and Jorge Bernardino 2,3,* 1 Department of Informatics Engineering, University of Coimbra, Coimbra 3030-290, Portugal; [email protected] (M.D.); [email protected] (B.C.) 2 Centre of Informatics and Systems of University of Coimbra (CISUC), Coimbra 3030-290, Portugal 3 ISEC—Coimbra Institute of Engineering, Polytechnic of Coimbra, Coimbra 3030-199, Portugal * Correspondence: [email protected] Received: 30 December 2018; Accepted: 11 February 2019; Published: 14 February 2019 Abstract: Internet has become so widespread that most popular websites are accessed by hundreds of millions of people on a daily basis. Monolithic architectures, which were frequently used in the past, were mostly composed of traditional relational database management systems, but quickly have become incapable of sustaining high data traffic very common these days. Meanwhile, NoSQL databases have emerged to provide some missing properties in relational databases like the schema-less design, horizontal scaling, and eventual consistency. This paper analyzes and compares the consistency model implementation on five popular NoSQL databases: Redis, Cassandra, MongoDB, Neo4j, and OrientDB. All of which offer at least eventual consistency, and some have the option of supporting strong consistency. However, imposing strong consistency will result in less availability when subject to network partition events. Keywords: consistency models; NoSQL databases; redis; cassandra; MongoDB; Neo4j; OrientDB 1. Introduction Consistency can be simply defined by how the copies from the same data may vary within the same replicated database system [1]. When the readings on a given data object are inconsistent with the last update on this data object, this is a consistency anomaly [2]. -

A Good Graph Database Benchmark - an Industry Experience
GooDBye: a Good Graph Database Benchmark - an Industry Experience Piotr Matyjaszczyk Przemyslaw Rosowski Robert Wrembel Poznan University of Technology Poznan University of Technology Poznan University of Technology Poland Poland Poland [email protected] [email protected]. [email protected] poznan.pl ABSTRACT analyzed there. For this reason, a fundamental issue was to choose This paper reports a use-case developed for an international IT a GDBMS that would be the most suitable for particular ’graph company, whose one of multiple branches is located in Poland. In shapes’ and queries needed by the company. The assessment order to deploy a graph database in their IT architecture, the com- criteria included: (1) performance characteristics w.r.t. variable pany needed an assessment of some of the most popular graph number of nodes in a cluster as well as (2) functionality and user database management systems to select one that fits their needs. experience. Despite the fact that multiple graph database benchmarks have The specific structures of graphs produced by the company been proposed so far, they do not cover all use-cases required and specific queries have not matched what was offered by theex- by industry. This problem was faced by the company. A specific isting GDB benchmarks. These facts motivated the development structure of graphs used by the company and specific queries, of the GoodBye benchmark, presented in this paper. Designing initiated developing a new graph benchmark, tailored to their GooDBye was inspired by [19] and it complements the existing needs. With this respect, the benchmark that we developed com- graph database benchmarks mentioned before.