Consistency Models of Nosql Databases
Total Page:16
File Type:pdf, Size:1020Kb

Load more
Recommended publications
-

Memory Consistency
Lecture 9: Memory Consistency Parallel Computing Stanford CS149, Winter 2019 Midterm ▪ Feb 12 ▪ Open notes ▪ Practice midterm Stanford CS149, Winter 2019 Shared Memory Behavior ▪ Intuition says loads should return latest value written - What is latest? - Coherence: only one memory location - Consistency: apparent ordering for all locations - Order in which memory operations performed by one thread become visible to other threads ▪ Affects - Programmability: how programmers reason about program behavior - Allowed behavior of multithreaded programs executing with shared memory - Performance: limits HW/SW optimizations that can be used - Reordering memory operations to hide latency Stanford CS149, Winter 2019 Today: what you should know ▪ Understand the motivation for relaxed consistency models ▪ Understand the implications of relaxing W→R ordering Stanford CS149, Winter 2019 Today: who should care ▪ Anyone who: - Wants to implement a synchronization library - Will ever work a job in kernel (or driver) development - Seeks to implement lock-free data structures * - Does any of the above on ARM processors ** * Topic of a later lecture ** For reasons to be described later Stanford CS149, Winter 2019 Memory coherence vs. memory consistency ▪ Memory coherence defines requirements for the observed Observed chronology of operations on address X behavior of reads and writes to the same memory location - All processors must agree on the order of reads/writes to X P0 write: 5 - In other words: it is possible to put all operations involving X on a timeline such P1 read (5) that the observations of all processors are consistent with that timeline P2 write: 10 ▪ Memory consistency defines the behavior of reads and writes to different locations (as observed by other processors) P2 write: 11 - Coherence only guarantees that writes to address X will eventually propagate to other processors P1 read (11) - Consistency deals with when writes to X propagate to other processors, relative to reads and writes to other addresses Stanford CS149, Winter 2019 Coherence vs. -

Memory Consistency: in a Distributed Outline for Lecture 20 Memory System, References to Memory in Remote Processors Do Not Take Place I
Memory consistency: In a distributed Outline for Lecture 20 memory system, references to memory in remote processors do not take place I. Memory consistency immediately. II. Consistency models not requiring synch. This raises a potential problem. Suppose operations that— Strict consistency Sequential consistency • The value of a particular memory PRAM & processor consist. word in processor 2’s local memory III. Consistency models is 0. not requiring synch. operations. • Then processor 1 writes the value 1 to that word of memory. Note that Weak consistency this is a remote write. Release consistency • Processor 2 then reads the word. But, being local, the read occurs quickly, and the value 0 is returned. What’s wrong with this? This situation can be diagrammed like this (the horizontal axis represents time): P1: W (x )1 P2: R (x )0 Depending upon how the program is written, it may or may not be able to tolerate a situation like this. But, in any case, the programmer must understand what can happen when memory is accessed in a DSM system. Consistency models: A consistency model is essentially a contract between the software and the memory. It says that iff they software agrees to obey certain rules, the memory promises to store and retrieve the expected values. © 1997 Edward F. Gehringer CSC/ECE 501 Lecture Notes Page 220 Strict consistency: The most obvious consistency model is strict consistency. Strict consistency: Any read to a memory location x returns the value stored by the most recent write operation to x. This definition implicitly assumes the existence of a global clock, so that the determination of “most recent” is unambiguous. -

Smart Methods for Retrieving Physiological Data in Physiqual
University of Groningen Bachelor thesis Smart methods for retrieving physiological data in Physiqual Marc Babtist & Sebastian Wehkamp Supervisors: Frank Blaauw & Marco Aiello July, 2016 Contents 1 Introduction 4 1.1 Physiqual . 4 1.2 Problem description . 4 1.3 Research questions . 5 1.4 Document structure . 5 2 Related work 5 2.1 IJkdijk project . 5 2.2 MUMPS . 6 3 Background 7 3.1 Scalability . 7 3.2 CAP theorem . 7 3.3 Reliability models . 7 4 Requirements 8 4.1 Scalability . 8 4.2 Reliability . 9 4.3 Performance . 9 4.4 Open source . 9 5 General database options 9 5.1 Relational or Non-relational . 9 5.2 NoSQL categories . 10 5.2.1 Key-value Stores . 10 5.2.2 Document Stores . 11 5.2.3 Column Family Stores . 11 5.2.4 Graph Stores . 12 5.3 When to use which category . 12 5.4 Conclusion . 12 5.4.1 Key-Value . 13 5.4.2 Document stores . 13 5.4.3 Column family stores . 13 5.4.4 Graph Stores . 13 6 Specific database options 13 6.1 Key-value stores: Riak . 14 6.2 Document stores: MongoDB . 14 6.3 Column Family stores: Cassandra . 14 6.4 Performance comparison . 15 6.4.1 Sensor Data Storage Performance . 16 6.4.2 Conclusion . 16 7 Data model 17 7.1 Modeling rules . 17 7.2 Data model Design . 18 2 7.3 Summary . 18 8 Architecture 20 8.1 Basic layout . 20 8.2 Sidekiq . 21 9 Design decisions 21 9.1 Keyspaces . 21 9.2 Gap determination . -

(DDL) Reference Manual
Data Definition Language (DDL) Reference Manual Abstract This publication describes the DDL language syntax and the DDL dictionary database. The audience includes application programmers and database administrators. Product Version DDL D40 DDL H01 Supported Release Version Updates (RVUs) This publication supports J06.03 and all subsequent J-series RVUs, H06.03 and all subsequent H-series RVUs, and G06.26 and all subsequent G-series RVUs, until otherwise indicated by its replacement publications. Part Number Published 529431-003 May 2010 Document History Part Number Product Version Published 529431-002 DDL D40, DDL H01 July 2005 529431-003 DDL D40, DDL H01 May 2010 Legal Notices Copyright 2010 Hewlett-Packard Development Company L.P. Confidential computer software. Valid license from HP required for possession, use or copying. Consistent with FAR 12.211 and 12.212, Commercial Computer Software, Computer Software Documentation, and Technical Data for Commercial Items are licensed to the U.S. Government under vendor's standard commercial license. The information contained herein is subject to change without notice. The only warranties for HP products and services are set forth in the express warranty statements accompanying such products and services. Nothing herein should be construed as constituting an additional warranty. HP shall not be liable for technical or editorial errors or omissions contained herein. Export of the information contained in this publication may require authorization from the U.S. Department of Commerce. Microsoft, Windows, and Windows NT are U.S. registered trademarks of Microsoft Corporation. Intel, Itanium, Pentium, and Celeron are trademarks or registered trademarks of Intel Corporation or its subsidiaries in the United States and other countries. -

Failures in DBMS
Chapter 11 Database Recovery 1 Failures in DBMS Two common kinds of failures StSystem filfailure (t)(e.g. power outage) ‒ affects all transactions currently in progress but does not physically damage the data (soft crash) Media failures (e.g. Head crash on the disk) ‒ damagg()e to the database (hard crash) ‒ need backup data Recoveryyp scheme responsible for handling failures and restoring database to consistent state 2 Recovery Recovering the database itself Recovery algorithm has two parts ‒ Actions taken during normal operation to ensure system can recover from failure (e.g., backup, log file) ‒ Actions taken after a failure to restore database to consistent state We will discuss (briefly) ‒ Transactions/Transaction recovery ‒ System Recovery 3 Transactions A database is updated by processing transactions that result in changes to one or more records. A user’s program may carry out many operations on the data retrieved from the database, but the DBMS is only concerned with data read/written from/to the database. The DBMS’s abstract view of a user program is a sequence of transactions (reads and writes). To understand database recovery, we must first understand the concept of transaction integrity. 4 Transactions A transaction is considered a logical unit of work ‒ START Statement: BEGIN TRANSACTION ‒ END Statement: COMMIT ‒ Execution errors: ROLLBACK Assume we want to transfer $100 from one bank (A) account to another (B): UPDATE Account_A SET Balance= Balance -100; UPDATE Account_B SET Balance= Balance +100; We want these two operations to appear as a single atomic action 5 Transactions We want these two operations to appear as a single atomic action ‒ To avoid inconsistent states of the database in-between the two updates ‒ And obviously we cannot allow the first UPDATE to be executed and the second not or vice versa. -
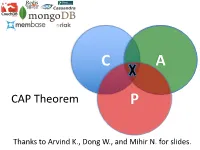
CAP Theorem P
C A CAP Theorem P Thanks to Arvind K., Dong W., and Mihir N. for slides. CAP Theorem • “It is impossible for a web service to provide these three guarantees at the same time (pick 2 of 3): • (Sequential) Consistency • Availability • Partition-tolerance” • Conjectured by Eric Brewer in ’00 • Proved by Gilbert and Lynch in ’02 • But with definitions that do not match what you’d assume (or Brewer meant) • Influenced the NoSQL mania • Highly controversial: “the CAP theorem encourages engineers to make awful decisions.” – Stonebraker • Many misinterpretations 2 CAP Theorem • Consistency: – Sequential consistency (a data item behaves as if there is one copy) • Availability: – Node failures do not prevent survivors from continuing to operate • Partition-tolerance: – The system continues to operate despite network partitions • CAP says that “A distributed system can satisfy any two of these guarantees at the same time but not all three” 3 C in CAP != C in ACID • They are different! • CAP’s C(onsistency) = sequential consistency – Similar to ACID’s A(tomicity) = Visibility to all future operations • ACID’s C(onsistency) = Does the data satisfy schema constraints 4 Sequential consistency • Makes it appear as if there is one copy of the object • Strict ordering on ops from same client • A single linear ordering across client ops – If client a executes operations {a1, a2, a3, ...}, client b executes operations {b1, b2, b3, ...} – Then, globally, clients observe some serialized version of the sequence • e.g., {a1, b1, b2, a2, ...} (or whatever) Notice -

Towards Shared Memory Consistency Models for Gpus
TOWARDS SHARED MEMORY CONSISTENCY MODELS FOR GPUS by Tyler Sorensen A thesis submitted to the faculty of The University of Utah in partial fulfillment of the requirements for the degree of Bachelor of Science School of Computing The University of Utah March 2013 FINAL READING APPROVAL I have read the thesis of Tyler Sorensen in its final form and have found that (1) its format, citations, and bibliographic style are consistent and acceptable; (2) its illustrative materials including figures, tables, and charts are in place. Date Ganesh Gopalakrishnan ABSTRACT With the widespread use of GPUs, it is important to ensure that programmers have a clear understanding of their shared memory consistency model i.e. what values can be read when issued concurrently with writes. While memory consistency has been studied for CPUs, GPUs present very different memory and concurrency systems and have not been well studied. We propose a collection of litmus tests that shed light on interesting visibility and ordering properties. These include classical shared memory consistency model properties, such as coherence and write atomicity, as well as GPU specific properties e.g. memory visibility differences between intra and inter block threads. The results of the litmus tests are determined by feedback from industry experts, the limited documentation available and properties common to all modern multi-core systems. Some of the behaviors remain unresolved. Using the results of the litmus tests, we establish a formal state transition model using intuitive data structures and operations. We implement our model in the Murphi modeling language and verify the initial litmus tests. -

Nosql Databases: Yearning for Disambiguation
NOSQL DATABASES: YEARNING FOR DISAMBIGUATION Chaimae Asaad Alqualsadi, Rabat IT Center, ENSIAS, University Mohammed V in Rabat and TicLab, International University of Rabat, Morocco [email protected] Karim Baïna Alqualsadi, Rabat IT Center, ENSIAS, University Mohammed V in Rabat, Morocco [email protected] Mounir Ghogho TicLab, International University of Rabat Morocco [email protected] March 17, 2020 ABSTRACT The demanding requirements of the new Big Data intensive era raised the need for flexible storage systems capable of handling huge volumes of unstructured data and of tackling the challenges that arXiv:2003.04074v2 [cs.DB] 16 Mar 2020 traditional databases were facing. NoSQL Databases, in their heterogeneity, are a powerful and diverse set of databases tailored to specific industrial and business needs. However, the lack of the- oretical background creates a lack of consensus even among experts about many NoSQL concepts, leading to ambiguity and confusion. In this paper, we present a survey of NoSQL databases and their classification by data model type. We also conduct a benchmark in order to compare different NoSQL databases and distinguish their characteristics. Additionally, we present the major areas of ambiguity and confusion around NoSQL databases and their related concepts, and attempt to disambiguate them. Keywords NoSQL Databases · NoSQL data models · NoSQL characteristics · NoSQL Classification A PREPRINT -MARCH 17, 2020 1 Introduction The proliferation of data sources ranging from social media and Internet of Things (IoT) to industrially generated data (e.g. transactions) has led to a growing demand for data intensive cloud based applications and has created new challenges for big-data-era databases. -

IBM Cloudant: Database As a Service Fundamentals
Front cover IBM Cloudant: Database as a Service Fundamentals Understand the basics of NoSQL document data stores Access and work with the Cloudant API Work programmatically with Cloudant data Christopher Bienko Marina Greenstein Stephen E Holt Richard T Phillips ibm.com/redbooks Redpaper Contents Notices . 5 Trademarks . 6 Preface . 7 Authors. 7 Now you can become a published author, too! . 8 Comments welcome. 8 Stay connected to IBM Redbooks . 9 Chapter 1. Survey of the database landscape . 1 1.1 The fundamentals and evolution of relational databases . 2 1.1.1 The relational model . 2 1.1.2 The CAP Theorem . 4 1.2 The NoSQL paradigm . 5 1.2.1 ACID versus BASE systems . 7 1.2.2 What is NoSQL? . 8 1.2.3 NoSQL database landscape . 9 1.2.4 JSON and schema-less model . 11 Chapter 2. Build more, grow more, and sleep more with IBM Cloudant . 13 2.1 Business value . 15 2.2 Solution overview . 16 2.3 Solution architecture . 18 2.4 Usage scenarios . 20 2.5 Intuitively interact with data using Cloudant Dashboard . 21 2.5.1 Editing JSON documents using Cloudant Dashboard . 22 2.5.2 Configuring access permissions and replication jobs within Cloudant Dashboard. 24 2.6 A continuum of services working together on cloud . 25 2.6.1 Provisioning an analytics warehouse with IBM dashDB . 26 2.6.2 Data refinement services on-premises. 30 2.6.3 Data refinement services on the cloud. 30 2.6.4 Hybrid clouds: Data refinement across on/off–premises. 31 Chapter 3. -

Preview Orientdb Tutorial
OrientDB OrientDB About the Tutorial OrientDB is an Open Source NoSQL Database Management System, which contains the features of traditional DBMS along with the new features of both Document and Graph DBMS. It is written in Java and is amazingly fast. It can store 220,000 records per second on commodity hardware. In the following chapters of this tutorial, we will look closely at OrientDB, one of the best open-source, multi-model, next generation NoSQL product. Audience This tutorial is designed for software professionals who are willing to learn NoSQL Database in simple and easy steps. This tutorial will give a great understanding on OrientDB concepts. Prerequisites OrientDB is NoSQL Database technologies which deals with the Documents, Graphs and traditional database components, like Schema and relation. Thus it is better to have knowledge of SQL. Familiarity with NoSQL is an added advantage. Disclaimer & Copyright Copyright 2018 by Tutorials Point (I) Pvt. Ltd. All the content and graphics published in this e-book are the property of Tutorials Point (I) Pvt. Ltd. The user of this e-book is prohibited to reuse, retain, copy, distribute or republish any contents or a part of contents of this e-book in any manner without written consent of the publisher. We strive to update the contents of our website and tutorials as timely and as precisely as possible, however, the contents may contain inaccuracies or errors. Tutorials Point (I) Pvt. Ltd. provides no guarantee regarding the accuracy, timeliness or completeness of our website or its contents including this tutorial. If you discover any errors on our website or in this tutorial, please notify us at [email protected]. -

On the Coexistence of Shared-Memory and Message-Passing in The
On the Co existence of SharedMemory and MessagePassing in the Programming of Parallel Applications 1 2 J Cordsen and W SchroderPreikschat GMD FIRST Rudower Chaussee D Berlin Germany University of Potsdam Am Neuen Palais D Potsdam Germany Abstract Interop erability in nonsequential applications requires com munication to exchange information using either the sharedmemory or messagepassing paradigm In the past the communication paradigm in use was determined through the architecture of the underlying comput ing platform Sharedmemory computing systems were programmed to use sharedmemory communication whereas distributedmemory archi tectures were running applications communicating via messagepassing Current trends in the architecture of parallel machines are based on sharedmemory and distributedmemory For scalable parallel applica tions in order to maintain transparency and eciency b oth communi cation paradigms have to co exist Users should not b e obliged to know when to use which of the two paradigms On the other hand the user should b e able to exploit either of the paradigms directly in order to achieve the b est p ossible solution The pap er presents the VOTE communication supp ort system VOTE provides co existent implementations of sharedmemory and message passing communication Applications can change the communication paradigm dynamically at runtime thus are able to employ the under lying computing system in the most convenient and applicationoriented way The presented case study and detailed p erformance analysis un derpins the -

Exploring the Visualization of Schemas for Aggregate-Oriented Nosql Databases?
Exploring the Visualization of Schemas for Aggregate-Oriented NoSQL Databases? Alberto Hernández Chillón, Severino Feliciano Morales, Diego Sevilla Ruiz, and Jesús García Molina Faculty of Computer Science, University of Murcia Campus Espinardo, Murcia, Spain {alberto.hernandez1,severino.feliciano,dsevilla,jmolina}@um.es Abstract. The lack of an explicit data schema (schemaless) is one of the most attractive NoSQL database features for developers. Being schema- less, these databases provide a greater flexibility, as data with different structure can be stored for the same entity type, which in turn eases data evolution. This flexibility, however, should not be obtained at the expense of losing the benefits provided by having schemas: When writ- ing code that deals with NoSQL databases, developers need to keep in mind at any moment some kind of schema. Also, database tools usu- ally require the knowledge of a schema to implement their functionality. Several approaches to infer an implicit schema from NoSQL data have been proposed recently, and some utilities that take advantage of inferred schemas are emerging. In this article we focus on the requisites for the vi- sualization of schemas for aggregate-oriented NoSQL Databases. Schema diagrams have proven useful in designing and understanding databases. Plenty of tools are available to visualize relational schemas, but the vi- sualization of NoSQL schemas (and the variation that they allow) is still in an immature state, and a great R&D effort is required to achieve tools with the desired capabilities. Here, we study the main challenges to be addressed, and propose some visual representations. Moreover, we outline the desired features to be supported by visualization tools.