A Good Graph Database Benchmark - an Industry Experience
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Arangodb Is Hailed As a Native Multi-Model Database by Its Developers
ArangoDB i ArangoDB About the Tutorial Apparently, the world is becoming more and more connected. And at some point in the very near future, your kitchen bar may well be able to recommend your favorite brands of whiskey! This recommended information may come from retailers, or equally likely it can be suggested from friends on Social Networks; whatever it is, you will be able to see the benefits of using graph databases, if you like the recommendations. This tutorial explains the various aspects of ArangoDB which is a major contender in the landscape of graph databases. Starting with the basics of ArangoDB which focuses on the installation and basic concepts of ArangoDB, it gradually moves on to advanced topics such as CRUD operations and AQL. The last few chapters in this tutorial will help you understand how to deploy ArangoDB as a single instance and/or using Docker. Audience This tutorial is meant for those who are interested in learning ArangoDB as a Multimodel Database. Graph databases are spreading like wildfire across the industry and are making an impact on the development of new generation applications. So anyone who is interested in learning different aspects of ArangoDB, should go through this tutorial. Prerequisites Before proceeding with this tutorial, you should have the basic knowledge of Database, SQL, Graph Theory, and JavaScript. Copyright & Disclaimer Copyright 2018 by Tutorials Point (I) Pvt. Ltd. All the content and graphics published in this e-book are the property of Tutorials Point (I) Pvt. Ltd. The user of this e-book is prohibited to reuse, retain, copy, distribute or republish any contents or a part of contents of this e-book in any manner without written consent of the publisher. -

Preview Orientdb Tutorial
OrientDB OrientDB About the Tutorial OrientDB is an Open Source NoSQL Database Management System, which contains the features of traditional DBMS along with the new features of both Document and Graph DBMS. It is written in Java and is amazingly fast. It can store 220,000 records per second on commodity hardware. In the following chapters of this tutorial, we will look closely at OrientDB, one of the best open-source, multi-model, next generation NoSQL product. Audience This tutorial is designed for software professionals who are willing to learn NoSQL Database in simple and easy steps. This tutorial will give a great understanding on OrientDB concepts. Prerequisites OrientDB is NoSQL Database technologies which deals with the Documents, Graphs and traditional database components, like Schema and relation. Thus it is better to have knowledge of SQL. Familiarity with NoSQL is an added advantage. Disclaimer & Copyright Copyright 2018 by Tutorials Point (I) Pvt. Ltd. All the content and graphics published in this e-book are the property of Tutorials Point (I) Pvt. Ltd. The user of this e-book is prohibited to reuse, retain, copy, distribute or republish any contents or a part of contents of this e-book in any manner without written consent of the publisher. We strive to update the contents of our website and tutorials as timely and as precisely as possible, however, the contents may contain inaccuracies or errors. Tutorials Point (I) Pvt. Ltd. provides no guarantee regarding the accuracy, timeliness or completeness of our website or its contents including this tutorial. If you discover any errors on our website or in this tutorial, please notify us at [email protected]. -

The Java API Quick Reference You Can Create Both Local (That Is, Without Using a Remote Server) and Remote Database with the Java API
The Java API quick reference You can create both local (that is, without using a remote server) and remote database with the Java API. Each kind of database has a specific related class, but they expose the same interface: • To create a local document database, use the ODatabaseDocumentTx class: ODatabaseDocumentTx db = new ODatabaseDocumentTx ("local:<path>/<db-name>").create(); • To create a local graph database, use the OGraphDatabase class: OGraphDatabase db = new GraphDatabase("local:<path>/<db-name>"). create(); • To create a local object database, use the OObjectDatabaseTx class: OGraphDatabase db = new GraphDatabase("local:<path>/<db-name>"). create(); • To create a remote database: new OServerAdmin("remote:<db-host>").connect(<root- username>,<root-password>).createDatabase(<db-name>,<db- type>,<storage-type>).close(); • To drop a remote database: new OServerAdmin("remote:<db-host>/<db-name>").connect(<root- username>,<root-password>).dropDatabase(); Where: • path: This specifies the path where you wish to create the new database. • db-host: This is the remote host. It could be an IP address or the name of the host. • root-user: This is the root username as defined in the server config file. • root-password: This is the root password as defined in the server config file. • db-name: This is the name of the database. • db-type: This specifies the type of database. It can be "document" or "graph". • storage-type: This specifies the storage type. It can be local or memory. local means that the database will be persistent, while memory means that the database will be volatile. Appendix Open and close connections To open a connection, the open API is available: <database>(<db>).open(<username>,<password>); Where: • database: This is a database class. -

Storing Metagraph Model in Relational, Document- Oriented, and Graph Databases
Storing Metagraph Model in Relational, Document- Oriented, and Graph Databases © Valeriy M. Chernenkiy © Yuriy E. Gapanyuk © Yuriy T. Kaganov © Ivan V. Dunin © Maxim A. Lyaskovsky © Vadim S. Larionov Bauman Moscow State Technical University, Moscow, Russia [email protected], [email protected], [email protected], [email protected], [email protected], [email protected] Abstract. This paper proposes an approach for metagraph model storage in databases with different data models. The formal definition of the metagraph data model is given. The approaches for mapping the metagraph model to the flat graph, document-oriented, and relational data models are proposed. The limitations of the RDF model in comparison with the metagraph model are considered. It is shown that the metagraph model addresses RDF limitations in a natural way without emergence loss. The experiments result for storing the metagraph model in different databases are given. Keywords: metagraph, metavertex, flat graph, graph database, document-oriented database, relational database. adapted for information systems description by the 1 Introduction present authors [2]. According to [2]: = , , , At present, on the one hand, the domains are becoming where – metagraph; – set of metagraph more and more complex. Therefore, models based on vertices; – set of〈 metagraph metavertices; 〉 – complex graphs are increasingly used in various fields of set of metagraph edges. science from mathematics and computer science to A metagraph vertex is described by the set of biology and sociology. attributes: = { }, , where – metagraph On the other hand, there are currently only graph vertex; – attribute. databases based on flat graph or hypergraph models that A metagraph edge is described∈ by the set of attributes, are not capable enough of being suitable repositories for the source and destination vertices and edge direction complex relations in the domains. -
Arangodb Cookbook
Table of Contents Introduction 1.1 Modelling Document Inheritance 1.2 Accessing Shapes Data 1.3 AQL 1.4 Using Joins in AQL 1.4.1 Using Dynamic Attribute Names 1.4.2 Creating Test-data using AQL 1.4.3 Diffing Documents 1.4.4 Avoiding Parameter Injection 1.4.5 Multiline Query Strings 1.4.6 Migrating named graph functions to 3.0 1.4.7 Migrating anonymous graph functions to 3.0 1.4.8 Migrating graph measurements to 3.0 1.4.9 Graph 1.5 Fulldepth Graph-Traversal 1.5.1 Using a custom Visitor 1.5.2 Example AQL Queries for Graphs 1.5.3 Use Cases / Examples 1.6 Crawling Github with Promises 1.6.1 Using ArangoDB with Sails.js 1.6.2 Populating a Textbox 1.6.3 Exporting Data 1.6.4 Accessing base documents with Java 1.6.5 Add XML data to ArangoDB with Java 1.6.6 Administration 1.7 Using Authentication 1.7.1 Importing Data 1.7.2 Replicating Data 1.7.3 XCopy Install Windows 1.7.4 Silent NSIS on Windows 1.7.5 Migrating 2.8 to 3.0 1.7.6 Show grants function 1.7.7 Compiling / Build 1.8 Compile on Debian 1.8.1 Compile on Windows 1.8.2 OpenSSL 1.8.3 Running Custom Build 1.8.4 Recompiling jemalloc 1.8.4.1 Cloud, DCOS and Docker 1.9 Running on AWS 1.9.1 Update on AWS 1.9.2 1 Running on Azure 1.9.3 Docker ArangoDB 1.9.4 Docker with NodeJS App 1.9.5 In the GiantSwarm 1.9.6 ArangoDB in Mesos 1.9.7 DC/OS: Full example 1.9.8 Monitoring 1.10 Collectd - Replication Slaves 1.10.1 Collectd - Network usage 1.10.2 Collectd - more Metrics 1.10.3 Collectd - Monitoring Foxx 1.10.4 2 Introduction Cookbook This cookbook is filled with recipes to help you understand the multi-model database ArangoDB better and to help you with specific problems. -

Multi-Model Databases: a New Journey to Handle the Variety of Data
0 Multi-model Databases: A New Journey to Handle the Variety of Data JIAHENG LU, Department of Computer Science, University of Helsinki IRENA HOLUBOVA´ , Department of Software Engineering, Charles University, Prague The variety of data is one of the most challenging issues for the research and practice in data management systems. The data are naturally organized in different formats and models, including structured data, semi- structured data and unstructured data. In this survey, we introduce the area of multi-model DBMSs which build a single database platform to manage multi-model data. Even though multi-model databases are a newly emerging area, in recent years we have witnessed many database systems to embrace this category. We provide a general classification and multi-dimensional comparisons for the most popular multi-model databases. This comprehensive introduction on existing approaches and open problems, from the technique and application perspective, make this survey useful for motivating new multi-model database approaches, as well as serving as a technical reference for developing multi-model database applications. CCS Concepts: Information systems ! Database design and models; Data model extensions; Semi- structured data;r Database query processing; Query languages for non-relational engines; Extraction, trans- formation and loading; Object-relational mapping facilities; Additional Key Words and Phrases: Big Data management, multi-model databases, NoSQL database man- agement systems. ACM Reference Format: Jiaheng Lu and Irena Holubova,´ 2019. Multi-model Databases: A New Journey to Handle the Variety of Data. ACM CSUR 0, 0, Article 0 ( 2019), 38 pages. DOI: http://dx.doi.org/10.1145/0000000.0000000 1. -
Neo4j Orientdb
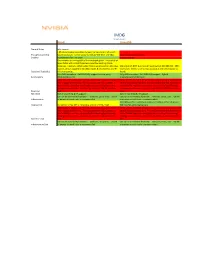
IMDG Graph-based Neo4J OrientDB General Notes jdbc support > 85 referenceable customers; largest market share of all graph- Thought Leadership based databases; named accounts include Wal-Mart and EBay. 33 referenceable customers Stability In production for > 10 years Created in 2010. One instance is running 60% of the Facebook graph. Thousands of times faster with 10-100 times less code than existing Oracle instances. Unable to obtain actual figures on production data sizes. Max size is 19.8 EB; max rows in result set is 2,000,000,000. 150K Current version capable of 32 billion nodes & relationships and 64 inserts/sec. Seems to be at least as good as the performance as Capacity / Scalability billion properties. Neo4J. Fully ACID compliant. Full JDBC/SQL support (via 3rd party Fully ACID compliant. Full JDBC/SQL support. Hybrid Functionality jdbc4sparql driver). Graph/Document database. While specific Neo4J is hard to find, senior Java resources should be While specific OrientDB is hard to find, senior Java resources should able to adapt quickly to it. The most expensive skill, however, is be able to adapt quickly to it. The most expensive skill, however, is that of NoSQL expertise, specifically data sharding (partitioning) that of NoSQL expertise, specifically data sharding (partitioning) strategies across nodes. Ability to tune JVM's > 128 GB is hard to strategies across nodes. Ability to tune JVM's > 128 GB is hard to Expertise find. find. Resilience Built in clustering & HA support. Built in clustering & HA support. Can run on commodity hardware -- windows, Linux, Unix. 128 GB Can run on commodity hardware -- windows, Linux, Unix. -

Accommodating Data Variety by a Multimodel Star Schema Sandro Bimonte, Yassine Hifdi, Mohammed Maliari, Patrick Marcel, Stefano Rizzi
To Each His Own: Accommodating Data Variety by a Multimodel Star Schema Sandro Bimonte, Yassine Hifdi, Mohammed Maliari, Patrick Marcel, Stefano Rizzi To cite this version: Sandro Bimonte, Yassine Hifdi, Mohammed Maliari, Patrick Marcel, Stefano Rizzi. To Each His Own: Accommodating Data Variety by a Multimodel Star Schema. Proceedings of the 22nd International Workshop on Design, Optimization, Languages and Analytical Processing of Big Data co-located with EDBT/ICDT 2020 Joint Conference (EDBT/ICDT 2020), Mar 2020, Copenhagen, Denmark. hal-03009808 HAL Id: hal-03009808 https://hal.archives-ouvertes.fr/hal-03009808 Submitted on 17 Nov 2020 HAL is a multi-disciplinary open access L’archive ouverte pluridisciplinaire HAL, est archive for the deposit and dissemination of sci- destinée au dépôt et à la diffusion de documents entific research documents, whether they are pub- scientifiques de niveau recherche, publiés ou non, lished or not. The documents may come from émanant des établissements d’enseignement et de teaching and research institutions in France or recherche français ou étrangers, des laboratoires abroad, or from public or private research centers. publics ou privés. To Each His Own: Accommodating Data Variety by a Multimodel Star Schema Sandro Bimonte Yassine Hifdi Mohammed Maliari University Clermont, TSCF, INRAE LIFAT Laboratory, University Tours ENSA Aubiere, France Blois, France Tangier, Maroc [email protected] [email protected] [email protected] Patrick Marcel Stefano Rizzi LIFAT Laboratory, University Tours DISI, University of Bologna Blois, France Bologna, Italy [email protected] [email protected] ABSTRACT for the right data type is essential to grant good storage and anal- Recent approaches adopt multimodel databases (MMDBs) to ysis performance. -

The Database Designed for the Modern World
– 888 953 9572 (US) +44 203 3971 609 (International) [email protected] www.orientdb.com The database designed for the modern world The world runs on big data. Owning that data to build transformative applications is now more critical than ever. That’s why OrientDB developed the world’s first multi-model graph database. Leverage your data to the fullest extent. Performance Security Scalability Process complex transactions Protect your data and ensure your Collect, process, and analyze enormous quickly with a high-performance company remains compliant with a volumes of data in real time with a NoSQL database built for today’s fully encrypted database protected database designed to scale to meet the leading enterprises. by a proprietary algorithm. needs of today’s largest and fastest- moving organizations. Benefits Multi-Model Organize and manage complicated data sets in a single database ■ Speed: Store up to 120,000 records per second and to increase productivity, reduce costs, and eliminate complexity. process transactions 10x Simplify database management and unlock the full potential of faster than competitors. the data your organization collects. Store and analyze structured ■ Ease of use: Get results and unstructured data with a NoSQL database engineered to serve immediately with a plug- as your primary RDBMS. Modernize the way your organization and-play database solution leverages data and move past your competitors that still rely on that runs on any platform traditional master-slave architecture. and uses SQL as its query language. Native Graph Database ■ All-in-one platform: Manage Understand the relationships between disparate sets of data more data without having to hop thoroughly with a database that enables you to store, query, and from platform to platform. -

Arangodb Python Driver Documentation Release 0.1A
ArangoDB Python Driver Documentation Release 0.1a Max Klymyshyn Sep 27, 2017 Contents 1 Features support 1 2 Getting started 3 2.1 Installation................................................3 2.2 Usage example..............................................3 3 Contents 5 3.1 Collections................................................5 3.2 Documents................................................8 3.3 AQL Queries............................................... 11 3.4 Indexes.................................................. 14 3.5 Edges................................................... 15 3.6 Database................................................. 17 3.7 Exceptions................................................ 18 3.8 Glossary................................................. 18 3.9 Guidelines................................................ 19 4 Arango versions, Platforms and Python versions 21 5 Indices and tables 23 Python Module Index 25 i ii CHAPTER 1 Features support Driver for Python is not entirely completed. It supports Connections to ArangoDB with custom options, Collections, Documents, Indexes Cursors and partially Edges. Presentation about Graph Databases and Python with real-world examples how to work with arango-python. ArangoDB is an open-source database with a flexible data model for documents, graphs, and key-values. Build high performance applications using a convenient sql-like query language or JavaScript/Ruby ex- tensions. More details about ArangoDB on official website. Some blog posts about this driver. 1 ArangoDB Python -

Cloud Storage
Cloud Storage Big Data and Cloud Computing (CC4053) Eduardo R. B. Marques, DCC/FCUP 1 / 40 Cloud storage We provide an overview of the main storage models used with cloud computing, and example cloud service offerings including: File systems Object stores (buckets) Databases: relational (SQL-based) and other kinds (“NoSQL”) Data warehousing Reference → most of the topics in these slides are also covered in chapters 2 and 3 of Cloud Computing for Science and Engineering. 2 / 40 Local file systems Characteristics: hierarchical organisation of files within directories uses an entire disk or a disk partition with fixed capacity data is read/written by a single host programmatic access by standard APIs (e.g., the POSIX interface) Advantage → most programs are designed to work with files, and use the file system hierarchy (directories) as a natural means to organize information - files/directories have no associated “data schema” though. Disavantadges → Shared access by multiple hosts is not possible, and the volume of data is bound by the file system capacity. Distributed file systems, discussed next, can handle shared access and mitigate volume restrictions. 3 / 40 Local file systems (cont.) Example: configuration of a VM book disk in Compute Engine 4 / 40 Network attached storage Characteristics: Files are physically stored in a server host. The file system can be attached over the network by other hosts, and accessed transparently (i.e. the same way as local file systems). Data consistency is managed by a network protocol such as NFS (Networked File System) and SMB (Server Message Block). Advantages → data sharing by multiple hosts, and typically higher storage capacity (installed at server hosts) Example cloud services → NFS: Amazon EFS, Google File Store, Azure Files (Azure Files also supports SMB). -

Advanced Databases. Project. by Aleksei Karetnikov
A report on INFO-H-415: Advanced Databases. Project. By Aleksei Karetnikov (000455065) Content INTRODUCTION ...................................................................................................................... 3 GRAPH DATABASE .................................................................................................................. 4 What is it? .................................................................................................................................................. 4 Differences between other technologies ................................................................................................... 4 Query languages ......................................................................................................................................... 5 ARANGODB ............................................................................................................................. 7 Features .................................................................................................................................................. 7 Benefits with same DB ............................................................................................................................... 9 DB architecture .......................................................................................................................................... 9 Storage engines .......................................................................................................................................