A Simplified Database Pattern for the Microservice Architecture
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Software Architecture: Past, Present, Future
Software Architecture: Past, Present, Future Wilhelm Hasselbring 1 Introduction For large, complex software systems, the design of the overall system structure (the software architecture) is an essential challenge. The architecture of a software system defines that system in terms of components and connections among those components [55, 58]. It is not the design of that system which is more detailed. The architecture shows the correspondence between the requirements and the constructed system, thereby providing some rationale for the design decisions. This level of design has been addressed in a number of ways including informal diagrams and descriptive terms, module interconnection languages, and frameworks for systems that serve the needs of specific application domains. An architecture embodies decisions about quality properties. It represents the earliest opportunity for evaluating those decisions. Furthermore, reusability of components and services depends on how strongly coupled they are with other components in the system architecture. Performance, for instance, depends largely upon the complexity of the required coordination, in particular when the components are distributed via some network. The architecture is usually the first artifact to be examined when a programmer (particularly a maintenance programmer) unfamiliar with the system begins to work on it. Software architecture is often the first design artifact that represents decisions on how requirements of all types are to be achieved. As the manifestation of early design decisions, it represents design decisions that are hardest to change and hence most deserving of careful consideration. W. Hasselbring () Kiel University, Kiel, Germany e-mail: [email protected] © The Author(s) 2018 169 V. -

An Experimental Study on Microservices Based Edge Computing Platforms Qian Qu, Ronghua Xu, Seyed Yahya Nikouei, Yu Chen Dept
1 An Experimental Study on Microservices based Edge Computing Platforms Qian Qu, Ronghua Xu, Seyed Yahya Nikouei, Yu Chen Dept. of Electrical & Computer Engineering, Binghamton University, SUNY, Binghamton, NY 13902, USA fqqu2, rxu22, snikoue1, [email protected] Abstract—The rapid technological advances in the Internet of development and easy deployment among multiple service Things (IoT) allows the blueprint of Smart Cities to become providers. feasible by integrating heterogeneous cloud/fog/edge computing Because of many attractive features, such as good scalabil- paradigms to collaboratively provide variant smart services in our cities and communities. Thanks to attractive features like fine ity, fine granularity, loose coupling, continuous development, granularity and loose coupling, the microservices architecture and low maintenance cost, the microservices architecture has has been proposed to provide scalable and extensible services in emerged and gained a lot of interests both in industry and large scale distributed IoT systems. Recent studies have evaluated academic community [17], [21]. Compared to traditional SOAs and analyzed the performance interference between microser- in which the system is a monolithic unit, the microservices vices based on scenarios on the cloud computing environment. However, they are not holistic for IoT applications given the architecture divides an monolithic application into multiple restriction of the edge device like computation consumption and atomic microservices that run independently on distributed network capacity. This paper investigates multiple microservice computing platforms. Each microservice performs one specific deployment policies on edge computing platform. The microser- sub-task or service, which requires less computation resource vices are developed as docker containers, and comprehensive ex- and reduces the communication overhead. -

Preview Orientdb Tutorial
OrientDB OrientDB About the Tutorial OrientDB is an Open Source NoSQL Database Management System, which contains the features of traditional DBMS along with the new features of both Document and Graph DBMS. It is written in Java and is amazingly fast. It can store 220,000 records per second on commodity hardware. In the following chapters of this tutorial, we will look closely at OrientDB, one of the best open-source, multi-model, next generation NoSQL product. Audience This tutorial is designed for software professionals who are willing to learn NoSQL Database in simple and easy steps. This tutorial will give a great understanding on OrientDB concepts. Prerequisites OrientDB is NoSQL Database technologies which deals with the Documents, Graphs and traditional database components, like Schema and relation. Thus it is better to have knowledge of SQL. Familiarity with NoSQL is an added advantage. Disclaimer & Copyright Copyright 2018 by Tutorials Point (I) Pvt. Ltd. All the content and graphics published in this e-book are the property of Tutorials Point (I) Pvt. Ltd. The user of this e-book is prohibited to reuse, retain, copy, distribute or republish any contents or a part of contents of this e-book in any manner without written consent of the publisher. We strive to update the contents of our website and tutorials as timely and as precisely as possible, however, the contents may contain inaccuracies or errors. Tutorials Point (I) Pvt. Ltd. provides no guarantee regarding the accuracy, timeliness or completeness of our website or its contents including this tutorial. If you discover any errors on our website or in this tutorial, please notify us at [email protected]. -

Comparing Service- Based Architectures
Comparing Service- based Architectures @neal4d nealford.com 1 agenda Micro Service-oriented Service-based 2 Service-oriented Architecture 3 origins: hubs System B System A System C 4 origins: hubs System B System A System C System D (ftp only) 5 origins: hubs System E (http only) System B System A System C System D (ftp only) 6 origins: hubs System E (http only) System B System A System C System D (ftp only) 7 origins: hubs System E (http only) System B Integration System A Hub System C System D (ftp only) 8 origins: hubs System E (http only) System B Integration System A Hub System C System D (ftp only) 9 origins: hubs System E (http only) System B Integration System A Hub System C System D (ftp only) 10 origins: hubs looks great, but what about single point of failure and performance bottleneck considerations? 11 orchestration hub intelligent hub service oriented architecture / enterprise service bus pattern 12 service-oriented architecture abstraction service taxonomy shared resources middleware interoperability 13 service-oriented architecture business services BS BS BS BS BS BS message bus process choreographer service orchestrator enterprise services ES ES ES ES ES ES application services AS infrastructure services IS 14 service-oriented architecture business services BS BS BS BS BS BS messageabstract bus enterprise-level coarse-grained process choreographer owned and defined by business users data represented as WSDL, BPEL, XML, etc. service orchestrator no implementation - only name, input, and output enterpriseAre we services -

Case Study on Building Data- Centric Microservices
Case Study on Building Data- Centric Microservices Part I - Getting Started May 26, 2020 | Version 1.0 Copyright © 2020, Oracle and/or its affiliates Public DISCLAIMER This document in any form, software or printed matter, contains proprietary information that is the exclusive property of Oracle. Your access to and use of this confidential material is subject to the terms and conditions of your Oracle software license and service agreement, which has been executed and with which you agree to comply. This document and information contained herein may not be disclosed, copied, reproduced or distributed to anyone outside Oracle without prior written consent of Oracle. This document is not part of your license agreement nor can it be incorporated into any contractual agreement with Oracle or its subsidiaries or affiliates. This document is for informational purposes only and is intended solely to assist you in planning for the implementation and upgrade of the product features described. It is not a commitment to deliver any material, code, or functionality, and should not be relied upon in making purchasing decisions. The development, release, and timing of any features or functionality described in this document remains at the sole discretion of Oracle. Due to the nature of the product architecture, it may not be possible to safely include all features described in this document without risking significant destabilization of the code. TABLE OF CONTENTS DISCLAIMER INTRODUCTION ARCHITECTURE OVERVIEW Before You Begin Our Canonical Application -

The Java API Quick Reference You Can Create Both Local (That Is, Without Using a Remote Server) and Remote Database with the Java API
The Java API quick reference You can create both local (that is, without using a remote server) and remote database with the Java API. Each kind of database has a specific related class, but they expose the same interface: • To create a local document database, use the ODatabaseDocumentTx class: ODatabaseDocumentTx db = new ODatabaseDocumentTx ("local:<path>/<db-name>").create(); • To create a local graph database, use the OGraphDatabase class: OGraphDatabase db = new GraphDatabase("local:<path>/<db-name>"). create(); • To create a local object database, use the OObjectDatabaseTx class: OGraphDatabase db = new GraphDatabase("local:<path>/<db-name>"). create(); • To create a remote database: new OServerAdmin("remote:<db-host>").connect(<root- username>,<root-password>).createDatabase(<db-name>,<db- type>,<storage-type>).close(); • To drop a remote database: new OServerAdmin("remote:<db-host>/<db-name>").connect(<root- username>,<root-password>).dropDatabase(); Where: • path: This specifies the path where you wish to create the new database. • db-host: This is the remote host. It could be an IP address or the name of the host. • root-user: This is the root username as defined in the server config file. • root-password: This is the root password as defined in the server config file. • db-name: This is the name of the database. • db-type: This specifies the type of database. It can be "document" or "graph". • storage-type: This specifies the storage type. It can be local or memory. local means that the database will be persistent, while memory means that the database will be volatile. Appendix Open and close connections To open a connection, the open API is available: <database>(<db>).open(<username>,<password>); Where: • database: This is a database class. -

Evaluating Service-Oriented and Microservice Architecture Patterns to Deploy Ehealth Applications in Cloud Computing Environment
applied sciences Article Evaluating Service-Oriented and Microservice Architecture Patterns to Deploy eHealth Applications in Cloud Computing Environment Huriviades Calderón-Gómez 1,2 , Luis Mendoza-Pittí 1,2 , Miguel Vargas-Lombardo 2,* , José Manuel Gómez-Pulido 1,3 , Diego Rodríguez-Puyol 3,4,5, Gloria Sención 6 and María-Luz Polo-Luque 3,7 1 Department of Computer Science, University of Alcalá, 28805 Alcalá de Henares, Spain; [email protected] (H.C.-G.); [email protected] (L.M.-P.); [email protected] (J.M.G.-P.) 2 e-Health and Supercomputing Research Group (GISES), Technological University of Panama, 0819-07289 Panama City, Panama 3 Department of Medicine and Medical Specialties, Ramón y Cajal Institute for Health Research (IRYCIS), 28034 Madrid, Spain; [email protected] (D.R.-P.); [email protected] (M.-L.P.-L.) 4 Foundation for Biomedical Research, Hospital Universitario Príncipe de Asturias, 28805 Alcalá de Henares, Spain 5 Department of Medicine and Medical Specialties, University of Alcalá, 28805 Alcalá de Henares, Spain 6 School of Medicine Autonomous, University of Santo Domingo, Santo Domingo 10105, Dominican Republic; [email protected] 7 Department of Nursing and Physiotherapy, University of Alcalá, 28801 Alcalá de Henares, Spain * Correspondence: [email protected] Citation: Calderón-Gómez, H.; Mendoza-Pittí, L.; Vargas-Lombardo, Abstract: This article proposes a new framework for a Cloud-based eHealth platform concept focused M.; Gómez-Pulido, J.M.; on Cloud computing environments, since current and emerging approaches using digital clinical Rodríguez-Puyol, D.; Sención, G.; history increasingly demonstrate their potential in maintaining the quality of the benefits in medical Polo-Luque, M.-L. -

From Component-Based Architectures to Microservices: a 25-Years-Long Journey in Designing and Realizing Service-Based Systems
From Component-based Architectures to Microservices: A 25-years-long Journey in Designing and Realizing Service-based Systems Giuseppe De Giacomo[0000−0001−9680−7658], Maurizio Lenzerini[0000−0003−2875−6187], Francesco Leotta[0000−0001−9216−8502], and Massimo Mecella[0000−0002−9730−8882] Sapienza Universit`adi Roma Dipartimento di Ingegneria Informatica Automatica e Gestionale fdegiacomo,lenzerini,leotta,[email protected] Abstract. Distributed information systems and applications are gen- erally described in terms of components and interfaces among them. How these component-based architectures have been designed and im- plemented evolved over the years, giving rise to the so-called paradigm of Service-Oriented Computing (SOC). In this chapter, we will follow a 25-years-long journey on how design methodologies and supporting technologies influenced one each other, and we discuss how already back in the late 90s the ancestors of the SOC paradigm were there, already paving the way for the technological evolution recently leading to mi- croservice architectures and serverless computing. Keywords: components · SOC · middleware technologies · microser- vices · design methodologies 1 Introduction Divide et impera1 describes an approach, relevant to many fields, where, to solve a problem, it is required or advantageous to break or divide what opposes the solution. As an example, in computer science and engineering, it is applied at the level of standalone programs, by organizing codes in functions, classes and libraries, but it is also at the basis of how complex business processes, spanning several departments/offices of the same organization and/or different organizations, are implemented by making different parties collaborating on a computer network [1]. -
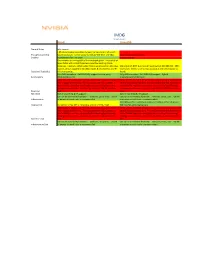
Neo4j Orientdb
IMDG Graph-based Neo4J OrientDB General Notes jdbc support > 85 referenceable customers; largest market share of all graph- Thought Leadership based databases; named accounts include Wal-Mart and EBay. 33 referenceable customers Stability In production for > 10 years Created in 2010. One instance is running 60% of the Facebook graph. Thousands of times faster with 10-100 times less code than existing Oracle instances. Unable to obtain actual figures on production data sizes. Max size is 19.8 EB; max rows in result set is 2,000,000,000. 150K Current version capable of 32 billion nodes & relationships and 64 inserts/sec. Seems to be at least as good as the performance as Capacity / Scalability billion properties. Neo4J. Fully ACID compliant. Full JDBC/SQL support (via 3rd party Fully ACID compliant. Full JDBC/SQL support. Hybrid Functionality jdbc4sparql driver). Graph/Document database. While specific Neo4J is hard to find, senior Java resources should be While specific OrientDB is hard to find, senior Java resources should able to adapt quickly to it. The most expensive skill, however, is be able to adapt quickly to it. The most expensive skill, however, is that of NoSQL expertise, specifically data sharding (partitioning) that of NoSQL expertise, specifically data sharding (partitioning) strategies across nodes. Ability to tune JVM's > 128 GB is hard to strategies across nodes. Ability to tune JVM's > 128 GB is hard to Expertise find. find. Resilience Built in clustering & HA support. Built in clustering & HA support. Can run on commodity hardware -- windows, Linux, Unix. 128 GB Can run on commodity hardware -- windows, Linux, Unix. -

Gremlin: Systematic Resilience Testing of Microservices
Gremlin: Systematic Resilience Testing of Microservices Victor Heorhiadi Shriram Rajagopalan Hani Jamjoom Michael K. Reiter Vyas Sekar UNC Chapel Hill IBM T. J. Watson Research IBM T. J. Watson Research UNC Chapel Hill Carnegie Mellon University [email protected] [email protected] [email protected] [email protected] [email protected] Abstract—Modern Internet applications are being disaggre- Company Downtime Postmortem findings gated into a microservice-based architecture, with services Parse.ly, 13 hours Cascading failure due to message bus being updated and deployed hundreds of times a day. The 2015 [25] overload accelerated software life cycle and heterogeneity of language CircleCI, 17 hours Cascading failure due to database over- runtimes in a single application necessitates a new approach 2015 [19] load BBC, 48 hours Cascading failure due to database over- for testing the resiliency of these applications in production in- 2014 [18] load frastructures. We present Gremlin, a framework for systemat- Spotify, Several Cascading failure due to degradation of a ically testing the failure-handling capabilities of microservices. 2013 [26] hours core internal service Gremlin is based on the observation that microservices are Twilio, 10 hours Database failure caused billing service to loosely coupled and thus rely on standard message-exchange 2013 [28] repeatedly bill customers patterns over the network. Gremlin allows the operator to TABLE 1: A subset of recent outages experienced by popular, easily design tests and executes them by manipulating inter- highly available Internet services. Postmortem reports revealed service messages at the network layer. We show how to use missing or faulty failure-handling logic. -

Testing Microservice Applications
Dmitrii Savchenko TESTING MICROSERVICE APPLICATIONS ACTA UNIVERSITATIS LAPPEENRANTAENSIS 868 Dmitrii Savchenko TESTING MICROSERVICE APPLICATIONS Thesis for the degree of Doctor of Science (Technology) to be presented with due permission for public examination and criticism in the Auditorium of the Student Union House at Lappeenranta-Lahti University of Technology LUT, Lappeenranta, Finland on the 18th of October, 2019, at noon. The thesis was written under a joint doctorate agreement between Lappeenranta-Lahti University of Technology LUT, Finland and South Ural State University, Russia and jointly supervised by supervisors from both universities. Acta Universitatis Lappeenrantaensis 868 Supervisors Adjunct Professor Ossi Taipale LUT School of Engineering Science Lappeenranta-Lahti University of Technology LUT Finland Associate Professor Jussi Kasurinen LUT School of Engineering Science Lappeenranta-Lahti University of Technology LUT Finland Associate Professor Gleb Radchenko School of Electrical Engineering and Computer Science Department of System Programming Federal State Autonomous Educational Institution of High Education South Ural State University (National Research University) Russian Federation Reviewers Professor Timo Mantere Dept. of Electrical Engineering and Automation University of Vaasa Finland Professor Markku Tukiainen School of Computing University of Eastern Finland Joensuu Finland Opponent Professor Ita Richardson Lero - The Irish Software Research Centre University of Limerick Ireland ISBN 978-952-335-414-2 ISBN 978-952-335-415-9 (PDF) ISSN 1456-4491 ISSN-L 1456-4491 Lappeenranta-Lahti University of Technology LUT LUT University Press 2019 Abstract Dmitrii Savchenko Testing microservice applications Lappeenranta, 2019 59 p. Acta Universitatis Lappeenrantaensis 868 Diss. Lappeenranta-Lahti University of Technology LUT ISBN 978-952-335-414-2, ISBN 978-952-335-415-9 (PDF), ISSN-L 1456-4491, ISSN 1456- 4491 Software maintenance costs are growing from year to year because of the growing soft- ware complexity. -

The Database Designed for the Modern World
– 888 953 9572 (US) +44 203 3971 609 (International) [email protected] www.orientdb.com The database designed for the modern world The world runs on big data. Owning that data to build transformative applications is now more critical than ever. That’s why OrientDB developed the world’s first multi-model graph database. Leverage your data to the fullest extent. Performance Security Scalability Process complex transactions Protect your data and ensure your Collect, process, and analyze enormous quickly with a high-performance company remains compliant with a volumes of data in real time with a NoSQL database built for today’s fully encrypted database protected database designed to scale to meet the leading enterprises. by a proprietary algorithm. needs of today’s largest and fastest- moving organizations. Benefits Multi-Model Organize and manage complicated data sets in a single database ■ Speed: Store up to 120,000 records per second and to increase productivity, reduce costs, and eliminate complexity. process transactions 10x Simplify database management and unlock the full potential of faster than competitors. the data your organization collects. Store and analyze structured ■ Ease of use: Get results and unstructured data with a NoSQL database engineered to serve immediately with a plug- as your primary RDBMS. Modernize the way your organization and-play database solution leverages data and move past your competitors that still rely on that runs on any platform traditional master-slave architecture. and uses SQL as its query language. Native Graph Database ■ All-in-one platform: Manage Understand the relationships between disparate sets of data more data without having to hop thoroughly with a database that enables you to store, query, and from platform to platform.