Demystifying Graph Databases: Analysis and Taxonomyof Data Organization, System Designs, and Graph Queries
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

An Evaluation of the Design Space for Scalable Data Loading Into Graph Databases
Otto-von-Guericke-Universit¨at Magdeburg Faculty of Computer Science Databases D B and Software S E Engineering Master's Thesis An Evaluation of the Design Space for Scalable Data Loading into Graph Databases Author: Jingyi Ma February 23, 2018 Advisors: M.Sc. Gabriel Campero Durand Data and Knowledge Engineering Group Prof. Dr. rer. nat. habil. Gunter Saake Data and Knowledge Engineering Group Ma, Jingyi: An Evaluation of the Design Space for Scalable Data Loading into Graph Databases Master's Thesis, Otto-von-Guericke-Universit¨at Magdeburg, 2018. Abstract In recent years, computational network science has become an active area. It offers a wealth of tools to help us gain insight into the interconnected systems around us. Graph databases are non-relational database systems which have been developed to support such network-oriented workloads. Graph databases build a data model based on graph abstractions (i.e. nodes/vertexes and edges) and can use different optimizations to speed up the basic graph processing tasks, such as traversals. In spite of such benefits, some tasks remain challenging in graph databases, such as the task of loading the complete dataset. The loading process has been considered to be a performance bottleneck, specifically a scalability bottleneck, and application developers need to conduct performance tuning to improve it. In this study, we study some optimization alternatives that developers have for load data into a graph databases. With this goal, we propose simple microbenchmarks of application-level load optimizations and evaluate these optimizations experimentally for loading real world graph datasets. We run our tests using JanusGraphLab, a JanusGraph prototype. -

Data-Centric Graphical User Interface of the ATLAS Event Index Service
EPJ Web of Conferences 245, 04036 (2020) https://doi.org/10.1051/epjconf/202024504036 CHEP 2019 Data-centric Graphical User Interface of the ATLAS Event Index Service Julius Hrivnᡠcˇ1,∗, Evgeny Alexandrov2, Igor Alexandrov2, Zbigniew Baranowski3, Dario Barberis4, Gancho Dimitrov3, Alvaro Fernandez Casani5, Elizabeth Gallas6, Carlos Gar- cía Montoro5, Santiago Gonzalez de la Hoz5, Andrei Kazymov2, Mikhail Mineev2, Fedor Prokoshin2, Grigori Rybkin1, Javier Sanchez5, Jose Salt5, Miguel Villaplana Perez7 1Université Paris-Saclay, CNRS/IN2P3, IJCLab, 91405 Orsay, France 2Joint Institute for Nuclear Research, 6 Joliot-Curie St., Dubna, Moscow Region, 141980, Russia 3CERN, 1211 Geneva 23, Switzerland 4Physics Department of the University of Genoa and INFN Sezione di Genova, Via Dodecaneso 33, I-16146 Genova, Italy 5Instituto de Fisica Corpuscular (IFIC), Centro Mixto Universidad de Valencia - CSIC, Valencia, Spain 6Department of Physics, Oxford University, Oxford, United Kingdom 7Department of Physics, University of Alberta, Edmonton AB, Canada Abstract. The Event Index service of the ATLAS experiment at the LHC keeps references to all real and simulated events. Hadoop Map files and HBase tables are used to store the Event Index data, a subset of data is also stored in the Oracle database. Several user interfaces are currently used to access and search the data, from a simple command line interface, through a programmable API, to sophisticated graphical web services. It provides a dynamic graph-like overview of all available data (and data collections). Data are shown together with their relations, like paternity or overlaps. Each data entity then gives users a set of actions available for the referenced data. Some actions are provided directly by the Event Index system, others are just interfaces to different ATLAS services. -

Preview Orientdb Tutorial
OrientDB OrientDB About the Tutorial OrientDB is an Open Source NoSQL Database Management System, which contains the features of traditional DBMS along with the new features of both Document and Graph DBMS. It is written in Java and is amazingly fast. It can store 220,000 records per second on commodity hardware. In the following chapters of this tutorial, we will look closely at OrientDB, one of the best open-source, multi-model, next generation NoSQL product. Audience This tutorial is designed for software professionals who are willing to learn NoSQL Database in simple and easy steps. This tutorial will give a great understanding on OrientDB concepts. Prerequisites OrientDB is NoSQL Database technologies which deals with the Documents, Graphs and traditional database components, like Schema and relation. Thus it is better to have knowledge of SQL. Familiarity with NoSQL is an added advantage. Disclaimer & Copyright Copyright 2018 by Tutorials Point (I) Pvt. Ltd. All the content and graphics published in this e-book are the property of Tutorials Point (I) Pvt. Ltd. The user of this e-book is prohibited to reuse, retain, copy, distribute or republish any contents or a part of contents of this e-book in any manner without written consent of the publisher. We strive to update the contents of our website and tutorials as timely and as precisely as possible, however, the contents may contain inaccuracies or errors. Tutorials Point (I) Pvt. Ltd. provides no guarantee regarding the accuracy, timeliness or completeness of our website or its contents including this tutorial. If you discover any errors on our website or in this tutorial, please notify us at [email protected]. -

Release Notes Date Published: 2021-03-25 Date Modified
Cloudera Runtime 7.2.8 Release Notes Date published: 2021-03-25 Date modified: https://docs.cloudera.com/ Legal Notice © Cloudera Inc. 2021. All rights reserved. The documentation is and contains Cloudera proprietary information protected by copyright and other intellectual property rights. No license under copyright or any other intellectual property right is granted herein. Copyright information for Cloudera software may be found within the documentation accompanying each component in a particular release. Cloudera software includes software from various open source or other third party projects, and may be released under the Apache Software License 2.0 (“ASLv2”), the Affero General Public License version 3 (AGPLv3), or other license terms. Other software included may be released under the terms of alternative open source licenses. Please review the license and notice files accompanying the software for additional licensing information. Please visit the Cloudera software product page for more information on Cloudera software. For more information on Cloudera support services, please visit either the Support or Sales page. Feel free to contact us directly to discuss your specific needs. Cloudera reserves the right to change any products at any time, and without notice. Cloudera assumes no responsibility nor liability arising from the use of products, except as expressly agreed to in writing by Cloudera. Cloudera, Cloudera Altus, HUE, Impala, Cloudera Impala, and other Cloudera marks are registered or unregistered trademarks in the United States and other countries. All other trademarks are the property of their respective owners. Disclaimer: EXCEPT AS EXPRESSLY PROVIDED IN A WRITTEN AGREEMENT WITH CLOUDERA, CLOUDERA DOES NOT MAKE NOR GIVE ANY REPRESENTATION, WARRANTY, NOR COVENANT OF ANY KIND, WHETHER EXPRESS OR IMPLIED, IN CONNECTION WITH CLOUDERA TECHNOLOGY OR RELATED SUPPORT PROVIDED IN CONNECTION THEREWITH. -

The Java API Quick Reference You Can Create Both Local (That Is, Without Using a Remote Server) and Remote Database with the Java API
The Java API quick reference You can create both local (that is, without using a remote server) and remote database with the Java API. Each kind of database has a specific related class, but they expose the same interface: • To create a local document database, use the ODatabaseDocumentTx class: ODatabaseDocumentTx db = new ODatabaseDocumentTx ("local:<path>/<db-name>").create(); • To create a local graph database, use the OGraphDatabase class: OGraphDatabase db = new GraphDatabase("local:<path>/<db-name>"). create(); • To create a local object database, use the OObjectDatabaseTx class: OGraphDatabase db = new GraphDatabase("local:<path>/<db-name>"). create(); • To create a remote database: new OServerAdmin("remote:<db-host>").connect(<root- username>,<root-password>).createDatabase(<db-name>,<db- type>,<storage-type>).close(); • To drop a remote database: new OServerAdmin("remote:<db-host>/<db-name>").connect(<root- username>,<root-password>).dropDatabase(); Where: • path: This specifies the path where you wish to create the new database. • db-host: This is the remote host. It could be an IP address or the name of the host. • root-user: This is the root username as defined in the server config file. • root-password: This is the root password as defined in the server config file. • db-name: This is the name of the database. • db-type: This specifies the type of database. It can be "document" or "graph". • storage-type: This specifies the storage type. It can be local or memory. local means that the database will be persistent, while memory means that the database will be volatile. Appendix Open and close connections To open a connection, the open API is available: <database>(<db>).open(<username>,<password>); Where: • database: This is a database class. -

A Survey of Current Property Graph Query Languages Peter Boncz (CWI)
A Survey Of Current Property Graph Query Languages Peter Boncz (CWI) incorporating slides from: Renzo Angles (Talca University), Oskar van Rest (Oracle), Mingxi Wu (TigerGraph) & Stefan Plantikow (neo4j) 1 History of Graph Query Languages Gremlin DNAQL HPQL BiQL RLV PDQL THQL SoQL GXPath GRE HNQL GUL GraphQL ECRPQ GMQL GSQL SQL/PGQ Graphlog Hyperlog UnQL HQL SPARQL SPARQL 1.1 PGQL GQL G G+ Gram PORL SLQL PRPQ Cypher RQ G-CORE 1987 1989 1995 1997 1999 2009 2013 2015 2017 2019 1990 1992 1994 2000 2002 2006 2008 2012 2016 2018 2021/2022? SPARQL Cypher Gremlin PGQL GSQL G-CORE SQL/PGQ GQL 2 History: the query language G • By Isabel Cruz, Alberto Mendelzon & Peter Wood • Data model: simple graphs • Formal and Graphical forms • Main functionality – Graph pattern queries – Path finding queries I. F. Cruz et al. A graphical query language supporting recursion. SIGMOD 1987. 3 G Example I. F. Cruz et al. A graphical query language supporting recursion. SIGMOD 1987. 4 Systems: Popular Query Language Implementations SQL • MySQL, SQLserver, Oracle, SQLserver, Postgres, Redis, DB2, Amazon Aurora, Amazon Redshift, Snowflake, Spark SQL, etc etc etc (398000k google hits for `sql query’) SPARQL • Amazon Neptune, Ontotext, GraphDB, AllegroGraph, Apache Jena with ARQ, Redland, MarkLogic, Stardog, Virtuoso, Blazegraph, Oracle DB Enterprise Spatial & Graph, Cray Urika-GD, AnzoGraph (1190k google hits for ‘sparql query’) • neo4j, RedisGraph, neo4j CAPS (Cypher on APache Spark), SAP HANA, Agens Graph, AnzoGraph, Cypher Cypher for Gremlin, Memgraph, OrientDB -

The Ubiquity of Large Graphs and Surprising Challenges of Graph Processing: Extended Survey
The VLDB Journal https://doi.org/10.1007/s00778-019-00548-x SPECIAL ISSUE PAPER The ubiquity of large graphs and surprising challenges of graph processing: extended survey Siddhartha Sahu1 · Amine Mhedhbi1 · Semih Salihoglu1 · Jimmy Lin1 · M. Tamer Özsu1 Received: 21 January 2019 / Revised: 9 May 2019 / Accepted: 13 June 2019 © Springer-Verlag GmbH Germany, part of Springer Nature 2019 Abstract Graph processing is becoming increasingly prevalent across many application domains. In spite of this prevalence, there is little research about how graphs are actually used in practice. We performed an extensive study that consisted of an online survey of 89 users, a review of the mailing lists, source repositories, and white papers of a large suite of graph software products, and in-person interviews with 6 users and 2 developers of these products. Our online survey aimed at understanding: (i) the types of graphs users have; (ii) the graph computations users run; (iii) the types of graph software users use; and (iv) the major challenges users face when processing their graphs. We describe the participants’ responses to our questions highlighting common patterns and challenges. Based on our interviews and survey of the rest of our sources, we were able to answer some new questions that were raised by participants’ responses to our online survey and understand the specific applications that use graph data and software. Our study revealed surprising facts about graph processing in practice. In particular, real-world graphs represent a very diverse range of entities and are often very large, scalability and visualization are undeniably the most pressing challenges faced by participants, and data integration, recommendations, and fraud detection are very popular applications supported by existing graph software. -
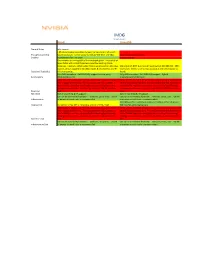
Neo4j Orientdb
IMDG Graph-based Neo4J OrientDB General Notes jdbc support > 85 referenceable customers; largest market share of all graph- Thought Leadership based databases; named accounts include Wal-Mart and EBay. 33 referenceable customers Stability In production for > 10 years Created in 2010. One instance is running 60% of the Facebook graph. Thousands of times faster with 10-100 times less code than existing Oracle instances. Unable to obtain actual figures on production data sizes. Max size is 19.8 EB; max rows in result set is 2,000,000,000. 150K Current version capable of 32 billion nodes & relationships and 64 inserts/sec. Seems to be at least as good as the performance as Capacity / Scalability billion properties. Neo4J. Fully ACID compliant. Full JDBC/SQL support (via 3rd party Fully ACID compliant. Full JDBC/SQL support. Hybrid Functionality jdbc4sparql driver). Graph/Document database. While specific Neo4J is hard to find, senior Java resources should be While specific OrientDB is hard to find, senior Java resources should able to adapt quickly to it. The most expensive skill, however, is be able to adapt quickly to it. The most expensive skill, however, is that of NoSQL expertise, specifically data sharding (partitioning) that of NoSQL expertise, specifically data sharding (partitioning) strategies across nodes. Ability to tune JVM's > 128 GB is hard to strategies across nodes. Ability to tune JVM's > 128 GB is hard to Expertise find. find. Resilience Built in clustering & HA support. Built in clustering & HA support. Can run on commodity hardware -- windows, Linux, Unix. 128 GB Can run on commodity hardware -- windows, Linux, Unix. -

The Database Designed for the Modern World
– 888 953 9572 (US) +44 203 3971 609 (International) [email protected] www.orientdb.com The database designed for the modern world The world runs on big data. Owning that data to build transformative applications is now more critical than ever. That’s why OrientDB developed the world’s first multi-model graph database. Leverage your data to the fullest extent. Performance Security Scalability Process complex transactions Protect your data and ensure your Collect, process, and analyze enormous quickly with a high-performance company remains compliant with a volumes of data in real time with a NoSQL database built for today’s fully encrypted database protected database designed to scale to meet the leading enterprises. by a proprietary algorithm. needs of today’s largest and fastest- moving organizations. Benefits Multi-Model Organize and manage complicated data sets in a single database ■ Speed: Store up to 120,000 records per second and to increase productivity, reduce costs, and eliminate complexity. process transactions 10x Simplify database management and unlock the full potential of faster than competitors. the data your organization collects. Store and analyze structured ■ Ease of use: Get results and unstructured data with a NoSQL database engineered to serve immediately with a plug- as your primary RDBMS. Modernize the way your organization and-play database solution leverages data and move past your competitors that still rely on that runs on any platform traditional master-slave architecture. and uses SQL as its query language. Native Graph Database ■ All-in-one platform: Manage Understand the relationships between disparate sets of data more data without having to hop thoroughly with a database that enables you to store, query, and from platform to platform. -

IDC Techscape IDC Techscape: Internet of Things Analytics and Information Management
IDC TechScape IDC TechScape: Internet of Things Analytics and Information Management Maureen Fleming Stewart Bond Carl W. Olofson David Schubmehl Dan Vesset Chandana Gopal Carrie Solinger IDC TECHSCAPE FIGURE FIGURE 1 IDC TechScape: Internet of Things Analytics and Information Management — Current Adoption Patterns Note: The IDC TechScape represents a snapshot of various technology adoption life cycles, given IDC's current market analysis. Expect, over time, for these technologies to follow the adoption curve on which they are currently mapped. Source: IDC, 2016 December 2016, IDC #US41841116 IN THIS STUDY Implementing the analytics and information management (AIM) tier of an Internet of Things (IoT) initiative is about the delivery and processing of sensor data, the insights that can be derived from that data and, at the moment of insight, initiating actions that should then be taken to respond as rapidly as possible. To achieve value, insight to action must fall within a useful time window. That means the IoT AIM tier needs to be designed for the shortest time window of IoT workloads running through the end- to-end system. It is also critical that the correct type of analytics is used to arrive at the insight. Over time, AIM technology adopted for IoT will be different from an organization's existing technology investments that perform a similar but less time-sensitive or data volume–intensive function. Enterprises will want to leverage as much of their existing AIM investments as possible, especially initially, but will want to adopt IoT-aligned technology as they operationalize and identify functionality gaps in how data is moved and managed, how analytics are applied, and how actions are defined and triggered at the moment of insight. -

Towards Scalable Loading Into Graph Database Systems
Piecing together large puzzles, efficiently: Towards scalable loading into graph database systems Work in progress paper Gabriel Campero Durand Jingy Ma Marcus Pinnecke University of Magdeburg University of Magdeburg University of Magdeburg [email protected] [email protected] [email protected] Gunter Saake University of Magdeburg [email protected] Transaction checks ABSTRACT Id assignation 5 Many applications rely on network analysis to extract busi- Physical storage ness intelligence from large datasets, requiring specialized graph tools such as processing frameworks (e.g. Apache Gi- 4 Process organization raph, Gradoop), database systems (e.g. Neo4j, JanusGraph) Batching or applications/libraries (e.g. NetworkX, nvGraph). A recent Partitioning survey reports scalability, particularly for loading, as the fo- Pre-processing 3 remost practical challenge faced by users. In this paper we consider the design space of tools for efficient and scalable 1 Parsing for different input characteristics File Interpretation 2 graph bulk loading. For this we implement a prototypical CSV, JSON, Adjacency lists, Implicit graphs... loader for a property graph DBMS, using a distributed mes- sage bus. With our implementation we evaluate the impact Figure 1: Bulk Loading into a Graph Storage and limits of basic optimizations. Our results confirm the expectation that bulk loading can be best supported as a server-side process. We also find, for our specific case, gains 1. INTRODUCTION from batching writes (up to 64x speedups in our evaluati- Network analysis is one of many methods used by scien- on), uniform behavior across partitioning strategies, and the tists to study large data collections. For this, data has to be need for careful tuning to find the optimal configuration of represented with models based on graph theory. -

A Simplified Database Pattern for the Microservice Architecture
DBKDA 2016 : The Eighth International Conference on Advances in Databases, Knowledge, and Data Applications A Simplified Database Pattern for the Microservice Architecture Antonio Messina, Riccardo Rizzo, Pietro Storniolo, Alfonso Urso ICAR - CNR Palermo, Italy Email: fmessina, ricrizzo, storniolo, [email protected] Abstract—Microservice architectures are used as alternative to The microservices pattern implies several important auxili- monolithic applications because they are simpler to scale and ary patterns, such as, for example, those which concern how more flexible. Microservices require a careful design because each clients access the services in a microservices architecture, how service component should be simple and easy to develop. In this clients requests are routed to an available service instance, or paper, a new microservice pattern is proposed: a database that how each service use a database. can be considered a microservice by itself. We named this new pattern as The Database is the Service. The proposed simplified In the new microservice pattern proposed in this paper, database pattern has been tested by adding ebXML registry a database, under certain circumstances and thanks to the capabilities to a noSQL database. integration of some business logic, can be considered a mi- Keywords–microservices, scalable applications, continuous de- croservice by itself. It will be labeled as The database is the livery, microservices patterns, noSQL, database service pattern. The remainder of the paper is organized as follows: Section 2 presents a brief overview about the old monolithic style and I. INTRODUCTION its drawbacks. The microservices architectures and the related The microservice architectural style [1] is a recent approach pattern are described in Section 3.