Release Notes Date Published: 2021-03-25 Date Modified
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Enterprise Integration Patterns N About Apache Camel N Essential Patterns Enterprise Integration Patterns N Conclusions and More
Brought to you by... #47 CONTENTS INCLUDE: n About Enterprise Integration Patterns n About Apache Camel n Essential Patterns Enterprise Integration Patterns n Conclusions and more... with Apache Camel Visit refcardz.com By Claus Ibsen ABOUT ENTERPRISE INTEGRATION PaTTERNS Problem A single event often triggers a sequence of processing steps Solution Use Pipes and Filters to divide a larger processing steps (filters) that are connected by channels (pipes) Integration is a hard problem. To help deal with the complexity Camel Camel supports Pipes and Filters using the pipeline node. of integration problems the Enterprise Integration Patterns Java DSL from(“jms:queue:order:in”).pipeline(“direct:transformOrd (EIP) have become the standard way to describe, document er”, “direct:validateOrder”, “jms:queue:order:process”); and implement complex integration problems. Hohpe & Where jms represents the JMS component used for consuming JMS messages Woolf’s book the Enterprise Integration Patterns has become on the JMS broker. Direct is used for combining endpoints in a synchronous fashion, allow you to divide routes into sub routes and/or reuse common routes. the bible in the integration space – essential reading for any Tip: Pipeline is the default mode of operation when you specify multiple integration professional. outputs, so it can be omitted and replaced with the more common node: from(“jms:queue:order:in”).to(“direct:transformOrder”, “direct:validateOrder”, “jms:queue:order:process”); Apache Camel is an open source project for implementing TIP: You can also separate each step as individual to nodes: the EIP easily in a few lines of Java code or Spring XML from(“jms:queue:order:in”) configuration. -

An Evaluation of the Design Space for Scalable Data Loading Into Graph Databases
Otto-von-Guericke-Universit¨at Magdeburg Faculty of Computer Science Databases D B and Software S E Engineering Master's Thesis An Evaluation of the Design Space for Scalable Data Loading into Graph Databases Author: Jingyi Ma February 23, 2018 Advisors: M.Sc. Gabriel Campero Durand Data and Knowledge Engineering Group Prof. Dr. rer. nat. habil. Gunter Saake Data and Knowledge Engineering Group Ma, Jingyi: An Evaluation of the Design Space for Scalable Data Loading into Graph Databases Master's Thesis, Otto-von-Guericke-Universit¨at Magdeburg, 2018. Abstract In recent years, computational network science has become an active area. It offers a wealth of tools to help us gain insight into the interconnected systems around us. Graph databases are non-relational database systems which have been developed to support such network-oriented workloads. Graph databases build a data model based on graph abstractions (i.e. nodes/vertexes and edges) and can use different optimizations to speed up the basic graph processing tasks, such as traversals. In spite of such benefits, some tasks remain challenging in graph databases, such as the task of loading the complete dataset. The loading process has been considered to be a performance bottleneck, specifically a scalability bottleneck, and application developers need to conduct performance tuning to improve it. In this study, we study some optimization alternatives that developers have for load data into a graph databases. With this goal, we propose simple microbenchmarks of application-level load optimizations and evaluate these optimizations experimentally for loading real world graph datasets. We run our tests using JanusGraphLab, a JanusGraph prototype. -
Unravel Data Systems Version 4.5
UNRAVEL DATA SYSTEMS VERSION 4.5 Component name Component version name License names jQuery 1.8.2 MIT License Apache Tomcat 5.5.23 Apache License 2.0 Tachyon Project POM 0.8.2 Apache License 2.0 Apache Directory LDAP API Model 1.0.0-M20 Apache License 2.0 apache/incubator-heron 0.16.5.1 Apache License 2.0 Maven Plugin API 3.0.4 Apache License 2.0 ApacheDS Authentication Interceptor 2.0.0-M15 Apache License 2.0 Apache Directory LDAP API Extras ACI 1.0.0-M20 Apache License 2.0 Apache HttpComponents Core 4.3.3 Apache License 2.0 Spark Project Tags 2.0.0-preview Apache License 2.0 Curator Testing 3.3.0 Apache License 2.0 Apache HttpComponents Core 4.4.5 Apache License 2.0 Apache Commons Daemon 1.0.15 Apache License 2.0 classworlds 2.4 Apache License 2.0 abego TreeLayout Core 1.0.1 BSD 3-clause "New" or "Revised" License jackson-core 2.8.6 Apache License 2.0 Lucene Join 6.6.1 Apache License 2.0 Apache Commons CLI 1.3-cloudera-pre-r1439998 Apache License 2.0 hive-apache 0.5 Apache License 2.0 scala-parser-combinators 1.0.4 BSD 3-clause "New" or "Revised" License com.springsource.javax.xml.bind 2.1.7 Common Development and Distribution License 1.0 SnakeYAML 1.15 Apache License 2.0 JUnit 4.12 Common Public License 1.0 ApacheDS Protocol Kerberos 2.0.0-M12 Apache License 2.0 Apache Groovy 2.4.6 Apache License 2.0 JGraphT - Core 1.2.0 (GNU Lesser General Public License v2.1 or later AND Eclipse Public License 1.0) chill-java 0.5.0 Apache License 2.0 Apache Commons Logging 1.2 Apache License 2.0 OpenCensus 0.12.3 Apache License 2.0 ApacheDS Protocol -

Talend Open Studio for Big Data Release Notes
Talend Open Studio for Big Data Release Notes 6.0.0 Talend Open Studio for Big Data Adapted for v6.0.0. Supersedes previous releases. Publication date July 2, 2015 Copyleft This documentation is provided under the terms of the Creative Commons Public License (CCPL). For more information about what you can and cannot do with this documentation in accordance with the CCPL, please read: http://creativecommons.org/licenses/by-nc-sa/2.0/ Notices Talend is a trademark of Talend, Inc. All brands, product names, company names, trademarks and service marks are the properties of their respective owners. License Agreement The software described in this documentation is licensed under the Apache License, Version 2.0 (the "License"); you may not use this software except in compliance with the License. You may obtain a copy of the License at http://www.apache.org/licenses/LICENSE-2.0.html. Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the specific language governing permissions and limitations under the License. This product includes software developed at AOP Alliance (Java/J2EE AOP standards), ASM, Amazon, AntlR, Apache ActiveMQ, Apache Ant, Apache Avro, Apache Axiom, Apache Axis, Apache Axis 2, Apache Batik, Apache CXF, Apache Cassandra, Apache Chemistry, Apache Common Http Client, Apache Common Http Core, Apache Commons, Apache Commons Bcel, Apache Commons JxPath, Apache -

Data-Centric Graphical User Interface of the ATLAS Event Index Service
EPJ Web of Conferences 245, 04036 (2020) https://doi.org/10.1051/epjconf/202024504036 CHEP 2019 Data-centric Graphical User Interface of the ATLAS Event Index Service Julius Hrivnᡠcˇ1,∗, Evgeny Alexandrov2, Igor Alexandrov2, Zbigniew Baranowski3, Dario Barberis4, Gancho Dimitrov3, Alvaro Fernandez Casani5, Elizabeth Gallas6, Carlos Gar- cía Montoro5, Santiago Gonzalez de la Hoz5, Andrei Kazymov2, Mikhail Mineev2, Fedor Prokoshin2, Grigori Rybkin1, Javier Sanchez5, Jose Salt5, Miguel Villaplana Perez7 1Université Paris-Saclay, CNRS/IN2P3, IJCLab, 91405 Orsay, France 2Joint Institute for Nuclear Research, 6 Joliot-Curie St., Dubna, Moscow Region, 141980, Russia 3CERN, 1211 Geneva 23, Switzerland 4Physics Department of the University of Genoa and INFN Sezione di Genova, Via Dodecaneso 33, I-16146 Genova, Italy 5Instituto de Fisica Corpuscular (IFIC), Centro Mixto Universidad de Valencia - CSIC, Valencia, Spain 6Department of Physics, Oxford University, Oxford, United Kingdom 7Department of Physics, University of Alberta, Edmonton AB, Canada Abstract. The Event Index service of the ATLAS experiment at the LHC keeps references to all real and simulated events. Hadoop Map files and HBase tables are used to store the Event Index data, a subset of data is also stored in the Oracle database. Several user interfaces are currently used to access and search the data, from a simple command line interface, through a programmable API, to sophisticated graphical web services. It provides a dynamic graph-like overview of all available data (and data collections). Data are shown together with their relations, like paternity or overlaps. Each data entity then gives users a set of actions available for the referenced data. Some actions are provided directly by the Event Index system, others are just interfaces to different ATLAS services. -

Talend ESB System Management Integration User Guide
Talend ESB System Management Integration User Guide 6.0.1 Publication date: September 10, 2015 Copyright © 2011-2015 Talend Inc. All rights reserved. Copyleft This documentation is provided under the terms of the Creative Commons Public License (CCPL). For more information about what you can and cannot do with this documentation in accordance with the CCPL, please read: http://creativecommons.org/licenses/by-nc-sa/2.0/ This document may include documentation produced at The Apache Software Foundation which is licensed under The Apache License 2.0. Notices Talend and Talend ESB are trademarks of Talend, Inc. Apache CXF, CXF, Apache Karaf, Karaf, Apache Camel, Camel, Apache Maven, Maven, Apache Archiva, Archiva, Apache Syncope, Syncope, Apache ActiveMQ, ActiveMQ, Apache Log4j, Log4j, Apache Felix, Felix, Apache ServiceMix, ServiceMix, Apache Ant, Ant, Apache Derby, Derby, Apache Tomcat, Tomcat, Apache ZooKeeper, ZooKeeper, Apache Jackrabbit, Jackrabbit, Apache Santuario, Santuario, Apache DS, DS, Apache Avro, Avro, Apache Abdera, Abdera, Apache Chemistry, Chemistry, Apache CouchDB, CouchDB, Apache Kafka, Kafka, Apache Lucene, Lucene, Apache MINA, MINA, Apache Velocity, Velocity, Apache FOP, FOP, Apache HBase, HBase, Apache Hadoop, Hadoop, Apache Shiro, Shiro, Apache Axiom, Axiom, Apache Neethi, Neethi, Apache WSS4J, WSS4J are trademarks of The Apache Foundation. Eclipse Equinox is a trademark of the Eclipse Foundation, Inc. SoapUI is a trademark of SmartBear Software. Hyperic is a trademark of VMware, Inc. Nagios is a trademark of Nagios Enterprises, LLC. All other brands, product names, company names, trademarks and service marks are the properties of their respective owners. Table of Contents 1. Introduction .............................................................................................................. 1 2. Hyperic HQ Integration .............................................................................................. 3 2.1. -

The Ubiquity of Large Graphs and Surprising Challenges of Graph Processing: Extended Survey
The VLDB Journal https://doi.org/10.1007/s00778-019-00548-x SPECIAL ISSUE PAPER The ubiquity of large graphs and surprising challenges of graph processing: extended survey Siddhartha Sahu1 · Amine Mhedhbi1 · Semih Salihoglu1 · Jimmy Lin1 · M. Tamer Özsu1 Received: 21 January 2019 / Revised: 9 May 2019 / Accepted: 13 June 2019 © Springer-Verlag GmbH Germany, part of Springer Nature 2019 Abstract Graph processing is becoming increasingly prevalent across many application domains. In spite of this prevalence, there is little research about how graphs are actually used in practice. We performed an extensive study that consisted of an online survey of 89 users, a review of the mailing lists, source repositories, and white papers of a large suite of graph software products, and in-person interviews with 6 users and 2 developers of these products. Our online survey aimed at understanding: (i) the types of graphs users have; (ii) the graph computations users run; (iii) the types of graph software users use; and (iv) the major challenges users face when processing their graphs. We describe the participants’ responses to our questions highlighting common patterns and challenges. Based on our interviews and survey of the rest of our sources, we were able to answer some new questions that were raised by participants’ responses to our online survey and understand the specific applications that use graph data and software. Our study revealed surprising facts about graph processing in practice. In particular, real-world graphs represent a very diverse range of entities and are often very large, scalability and visualization are undeniably the most pressing challenges faced by participants, and data integration, recommendations, and fraud detection are very popular applications supported by existing graph software. -

Storage and Ingestion Systems in Support of Stream Processing
Storage and Ingestion Systems in Support of Stream Processing: A Survey Ovidiu-Cristian Marcu, Alexandru Costan, Gabriel Antoniu, María Pérez-Hernández, Radu Tudoran, Stefano Bortoli, Bogdan Nicolae To cite this version: Ovidiu-Cristian Marcu, Alexandru Costan, Gabriel Antoniu, María Pérez-Hernández, Radu Tudoran, et al.. Storage and Ingestion Systems in Support of Stream Processing: A Survey. [Technical Report] RT-0501, INRIA Rennes - Bretagne Atlantique and University of Rennes 1, France. 2018, pp.1-33. hal-01939280v2 HAL Id: hal-01939280 https://hal.inria.fr/hal-01939280v2 Submitted on 14 Dec 2018 HAL is a multi-disciplinary open access L’archive ouverte pluridisciplinaire HAL, est archive for the deposit and dissemination of sci- destinée au dépôt et à la diffusion de documents entific research documents, whether they are pub- scientifiques de niveau recherche, publiés ou non, lished or not. The documents may come from émanant des établissements d’enseignement et de teaching and research institutions in France or recherche français ou étrangers, des laboratoires abroad, or from public or private research centers. publics ou privés. Storage and Ingestion Systems in Support of Stream Processing: A Survey Ovidiu-Cristian Marcu, Alexandru Costan, Gabriel Antoniu, María S. Pérez-Hernández, Radu Tudoran, Stefano Bortoli, Bogdan Nicolae TECHNICAL REPORT N° 0501 November 2018 Project-Team KerData ISSN 0249-0803 ISRN INRIA/RT--0501--FR+ENG Storage and Ingestion Systems in Support of Stream Processing: A Survey Ovidiu-Cristian Marcu∗, Alexandru -

Java Message Service Based Performance Comparison of Apache Activemq and Apache Apollo Brokers
Available online at sjuoz.uoz.edu.krd Vol. 5, No. 4, pp. 307 –312, Dec.-2017 p-ISSN: 2410-7549 e-ISSN: 2414•6943 journals.uoz.edu.krd JAVA MESSAGE SERVICE BASED PERFORMANCE COMPARISON OF APACHE ACTIVEMQ AND APACHE APOLLO BROKERS Qusay I. Sarhan a ,* and Idrees S. Gawdan b a Dept. of Computer Science, College of Science, University of Duhok, Kurdistan Region, Iraq – ([email protected]). b Dept. of Refrigeration & Air-Conditioning, Technical College of Engineering, Duhok Polytechnic University, Duhok, Kurdistan Region-Iraq – ([email protected]) Received: Aug. 2017 / Accepted: Dec., 2017 / Published: Dec., 2017 https://doi.org/10.25271/2017.5.4.376 ABSTRACT: Software integration is a crucial aspect of collaborative software applications and systems. It enables a number of different software applications, created by different developers, using different programming languages, and even located at different places to work with each other collaboratively to achieve common goals. Nowadays, a number of techniques are available to enable software integration. Messaging is the most prominent technique in this respect. In this paper, two leading open-source messaging brokers, Apache ActiveMQ and Apache Apollo, have been experimentally compared with each other with regard to their messaging capabilities (message sending and receiving throughputs). Both brokers support exchanging messages between heterogeneous and distributed software applications using several messaging mechanisms including Java Message Service (henceforth JMS). A number of experimental test scenarios have been conducted to obtain the comparison results that indicate the one-to-one JMS messaging performance of each broker. Overall performance evaluation and analysis showed that Apache Apollo outperformed Apache ActiveMQ in all test scenarios regarding message sending throughputs. -

A Survey of Distributed Message Broker Queues
A Survey of Distributed Message Broker Queues Vineet John Xia Liu University of Waterloo University of Waterloo [email protected] [email protected] ABSTRACT This paper surveys the message brokers that are in vogue today for distributed communication. Their primary goal is to facilitate the construction of decentralized topolo- gies without single points of failure, enabling fault tol- erance and high availability. These characteristics make them optimal for usage within distributed architectures. However, there are multiple protocols built to achieve this, and it would be beneficial to have a empirical comparison between their features and performance to determine their real-world applicability. Figure 1: Kafka Architecture This paper focuses on two popular protocols (Kafka and AMQP) and explores the divergence in their fea- RQ0 What are the message broker implementations tures as well as their performance under varied testing commonly in use today? workloads. RQ1 What are the common requirements for the im- plementation of message queues? KEYWORDS RQ2 What are the divergent functionalities in the distributed message broker, message queue, kafka, amqp, current message queue offerings? rabbitmq RQ3 How do each of the implementations offer relia- bility, partitioning and fault tolerance? 1 INTRODUCTION 3 KAFKA Kafka was developed at LinkedIn and primarily used Distributed Message Brokers are typically used to decou- for log processing. This worked well for Kafka’s user en- ple separate stages of a software architecture. They per- gagement metrics collection use-case. The fundamental mit communication between these stages asynchronously, features behind Kafka are performance over reliability by using the publish-subscribe paradigm.[1]. These mes- and it offers high throughput, low latency message queu- sage brokers are also finding new applications in the ing. -

Hortonworks Data Platform Data Movement and Integration (December 15, 2017)
Hortonworks Data Platform Data Movement and Integration (December 15, 2017) docs.cloudera.com Hortonworks Data Platform December 15, 2017 Hortonworks Data Platform: Data Movement and Integration Copyright © 2012-2017 Hortonworks, Inc. Some rights reserved. The Hortonworks Data Platform, powered by Apache Hadoop, is a massively scalable and 100% open source platform for storing, processing and analyzing large volumes of data. It is designed to deal with data from many sources and formats in a very quick, easy and cost-effective manner. The Hortonworks Data Platform consists of the essential set of Apache Hadoop projects including MapReduce, Hadoop Distributed File System (HDFS), HCatalog, Pig, Hive, HBase, ZooKeeper and Ambari. Hortonworks is the major contributor of code and patches to many of these projects. These projects have been integrated and tested as part of the Hortonworks Data Platform release process and installation and configuration tools have also been included. Unlike other providers of platforms built using Apache Hadoop, Hortonworks contributes 100% of our code back to the Apache Software Foundation. The Hortonworks Data Platform is Apache-licensed and completely open source. We sell only expert technical support, training and partner-enablement services. All of our technology is, and will remain, free and open source. Please visit the Hortonworks Data Platform page for more information on Hortonworks technology. For more information on Hortonworks services, please visit either the Support or Training page. You can contact us directly to discuss your specific needs. Except where otherwise noted, this document is licensed under Creative Commons Attribution ShareAlike 4.0 License. http://creativecommons.org/licenses/by-sa/4.0/legalcode ii Hortonworks Data Platform December 15, 2017 Table of Contents 1. -
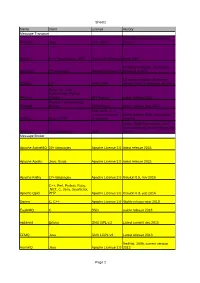
Sheet1 Page 1 Name Client License History Message Transport Jeromq
Sheet1 Name client License History Message Transport Java implementation of zeromq JeroMQ Java GNU LGPL library MSMQ C++, Visual Basic, .NET, Part of OS Windows since 1997 Currently only beta, version 0.6. Nanomsg 23 languages Apache License 2.0 released ul 2015 C# implementation of zeromq, NetMQ C# GNU LGPL version 3.3.2.1. released sep 2015 Ruby, Go, Java, CoffeeScript, Python, Resque Clojure MIT license stable release 2013 Python, Cyclone, Ruby, RestMQ Erlang BSD license stable release may 2015 GNU LGPL v3, or commercial license stable release 2015, community Sidekiq Ruby, HTTP for business growing IMatix, 2008, first version; 2011 mass produced, latest release aug ZeroMQ 30+ languages LGPL 2015 Message Broker Apache ActiveMQ 20+ languages Apache License 2.0 latest release 2015 Apache Apollo Java, Scala Apache License 2.0 latest release 2015 Apache Kafka 17+ languages Apache License 2.0 Version 0.9, nov 2015 C++, Perl, Python, Ruby, .NET, C, Java, JavaScript, Apache Qpid PHP Apache License 2.0 Version 0.3, sep 2014 Darner C, C++ Apache License 2.0 Stable release mar 2013 EagleMQ C BSD stable release 2013 ejabberd Erlang GNU GPL v.2 Latest commit dec 2015 FFMQ Java GNU LGPL v3 Latest release 2013 RedHat, 2009, current version HornetQ Java Apache License 2.0 2013 Page 1 Sheet1 IBM Websphere C, Visual Basic, .NET, C++, Various IBM IBM, 1990's, latest MQ V8 released in MQ Java, JMS, ActiveX licences 2014 OW2, 1999, latest release may JORAM Java, XML, 13+ others LGPL 2015 Kestrel ASP.NET, Java Apache License 2.0 2.4.1 released nov 2012 MemcacheQ Perl, Python, C, BSD license ~2009, version 0.2.0.