Explosion in Weighted Hyperbolic Random Graphs and Geometric Inhomogeneous Random Graphs
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Einstein's Velocity Addition Law and Its Hyperbolic Geometry
View metadata, citation and similar papers at core.ac.uk brought to you by CORE provided by Elsevier - Publisher Connector Computers and Mathematics with Applications 53 (2007) 1228–1250 www.elsevier.com/locate/camwa Einstein’s velocity addition law and its hyperbolic geometry Abraham A. Ungar∗ Department of Mathematics, North Dakota State University, Fargo, ND 58105, USA Received 6 March 2006; accepted 19 May 2006 Abstract Following a brief review of the history of the link between Einstein’s velocity addition law of special relativity and the hyperbolic geometry of Bolyai and Lobachevski, we employ the binary operation of Einstein’s velocity addition to introduce into hyperbolic geometry the concepts of vectors, angles and trigonometry. In full analogy with Euclidean geometry, we show in this article that the introduction of these concepts into hyperbolic geometry leads to hyperbolic vector spaces. The latter, in turn, form the setting for hyperbolic geometry just as vector spaces form the setting for Euclidean geometry. c 2007 Elsevier Ltd. All rights reserved. Keywords: Special relativity; Einstein’s velocity addition law; Thomas precession; Hyperbolic geometry; Hyperbolic trigonometry 1. Introduction The hyperbolic law of cosines is nearly a century old result that has sprung from the soil of Einstein’s velocity addition law that Einstein introduced in his 1905 paper [1,2] that founded the special theory of relativity. It was established by Sommerfeld (1868–1951) in 1909 [3] in terms of hyperbolic trigonometric functions as a consequence of Einstein’s velocity addition of relativistically admissible velocities. Soon after, Varicakˇ (1865–1942) established in 1912 [4] the interpretation of Sommerfeld’s consequence in the hyperbolic geometry of Bolyai and Lobachevski. -

Old-Fashioned Relativity & Relativistic Space-Time Coordinates
Relativistic Coordinates-Classic Approach 4.A.1 Appendix 4.A Relativistic Space-time Coordinates The nature of space-time coordinate transformation will be described here using a fictional spaceship traveling at half the speed of light past two lighthouses. In Fig. 4.A.1 the ship is just passing the Main Lighthouse as it blinks in response to a signal from the North lighthouse located at one light second (about 186,000 miles or EXACTLY 299,792,458 meters) above Main. (Such exactitude is the result of 1970-80 work by Ken Evenson's lab at NIST (National Institute of Standards and Technology in Boulder) and adopted by International Standards Committee in 1984.) Now the speed of light c is a constant by civil law as well as physical law! This came about because time and frequency measurement became so much more precise than distance measurement that it was decided to define the meter in terms of c. Fig. 4.A.1 Ship passing Main Lighthouse as it blinks at t=0. This arrangement is a simplified model for a 1Hz laser resonator. The two lighthouses use each other to maintain a strict one-second time period between blinks. And, strict it must be to do relativistic timing. (Even stricter than NIST is the universal agency BIGANN or Bureau of Intergalactic Aids to Navigation at Night.) The simulations shown here are done using RelativIt. Relativistic Coordinates-Classic Approach 4.A.2 Fig. 4.A.2 Main and North Lighthouses blink each other at precisely t=1. At p recisel y t=1 sec. -

Hyperbolic Trigonometry in Two-Dimensional Space-Time Geometry
Hyperbolic trigonometry in two-dimensional space-time geometry F. Catoni, R. Cannata, V. Catoni, P. Zampetti ENEA; Centro Ricerche Casaccia; Via Anguillarese, 301; 00060 S.Maria di Galeria; Roma; Italy January 22, 2003 Summary.- By analogy with complex numbers, a system of hyperbolic numbers can be intro- duced in the same way: z = x + hy; h2 = 1 x, y R . As complex numbers are linked to the { ∈ } Euclidean geometry, so this system of numbers is linked to the pseudo-Euclidean plane geometry (space-time geometry). In this paper we will show how this system of numbers allows, by means of a Cartesian representa- tion, an operative definition of hyperbolic functions using the invariance respect to special relativity Lorentz group. From this definition, by using elementary mathematics and an Euclidean approach, it is straightforward to formalise the pseudo-Euclidean trigonometry in the Cartesian plane with the same coherence as the Euclidean trigonometry. PACS 03 30 - Special Relativity PACS 02.20. Hj - Classical groups and Geometries 1 Introduction Complex numbers are strictly related to the Euclidean geometry: indeed their invariant (the module) arXiv:math-ph/0508011v1 3 Aug 2005 is the same as the Pythagoric distance (Euclidean invariant) and their unimodular multiplicative group is the Euclidean rotation group. It is well known that these properties allow to use complex numbers for representing plane vectors. In the same way hyperbolic numbers, an extension of complex numbers [1, 2] defined as z = x + hy; h2 =1 x, y R , { ∈ } are strictly related to space-time geometry [2, 3, 4]. Indeed their square module given by1 z 2 = 2 2 | | zz˜ x y is the Lorentz invariant of two dimensional special relativity, and their unimodular multiplicative≡ − group is the special relativity Lorentz group [2]. -

Hyperbolic Geometry
Flavors of Geometry MSRI Publications Volume 31,1997 Hyperbolic Geometry JAMES W. CANNON, WILLIAM J. FLOYD, RICHARD KENYON, AND WALTER R. PARRY Contents 1. Introduction 59 2. The Origins of Hyperbolic Geometry 60 3. Why Call it Hyperbolic Geometry? 63 4. Understanding the One-Dimensional Case 65 5. Generalizing to Higher Dimensions 67 6. Rudiments of Riemannian Geometry 68 7. Five Models of Hyperbolic Space 69 8. Stereographic Projection 72 9. Geodesics 77 10. Isometries and Distances in the Hyperboloid Model 80 11. The Space at Infinity 84 12. The Geometric Classification of Isometries 84 13. Curious Facts about Hyperbolic Space 86 14. The Sixth Model 95 15. Why Study Hyperbolic Geometry? 98 16. When Does a Manifold Have a Hyperbolic Structure? 103 17. How to Get Analytic Coordinates at Infinity? 106 References 108 Index 110 1. Introduction Hyperbolic geometry was created in the first half of the nineteenth century in the midst of attempts to understand Euclid’s axiomatic basis for geometry. It is one type of non-Euclidean geometry, that is, a geometry that discards one of Euclid’s axioms. Einstein and Minkowski found in non-Euclidean geometry a This work was supported in part by The Geometry Center, University of Minnesota, an STC funded by NSF, DOE, and Minnesota Technology, Inc., by the Mathematical Sciences Research Institute, and by NSF research grants. 59 60 J. W. CANNON, W. J. FLOYD, R. KENYON, AND W. R. PARRY geometric basis for the understanding of physical time and space. In the early part of the twentieth century every serious student of mathematics and physics studied non-Euclidean geometry. -

Using Differentials to Differentiate Trigonometric and Exponential Functions Tevian Dray
Using Differentials to Differentiate Trigonometric and Exponential Functions Tevian Dray Tevian Dray ([email protected]) received his B.S. in mathematics from MIT in 1976, his Ph.D. in mathematics from Berkeley in 1981, spent several years as a physics postdoc, and is now a professor of mathematics at Oregon State University. A Fellow of the American Physical Society for his early work in general relativity, his current research interests include the octonions as well as science education. He directs the Vector Calculus Bridge Project. (http://www.math.oregonstate.edu/bridge) Differentiating a polynomial is easy. To differentiate u2 with respect to u, start by computing d.u2/ D .u C du/2 − u2 D 2u du C du2; and then dropping the last term, an operation that can be justified in terms of limits. Differential notation, in general, can be regarded as a shorthand for a formal limit argument. Still more informally, one can argue that du is small compared to u, so that the last term can be ignored at the level of approximation needed. After dropping du2 and dividing by du, one obtains the derivative, namely d.u2/=du D 2u. Even if one regards this process as merely a heuristic procedure, it is a good one, as it always gives the correct answer for a polynomial. (Physicists are particularly good at knowing what approximations are appropriate in a given physical context. A physicist might describe du as being much smaller than the scale imposed by the physical situation, but not so small that quantum mechanics matters.) However, this procedure does not suffice for trigonometric functions. -
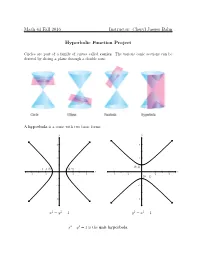
Cheryl Jaeger Balm Hyperbolic Function Project
Math 43 Fall 2016 Instructor: Cheryl Jaeger Balm Hyperbolic Function Project Circles are part of a family of curves called conics. The various conic sections can be derived by slicing a plane through a double cone. A hyperbola is a conic with two basic forms: y y 4 4 2 2 • (0; 1) (−1; 0) (1; 0) • • x x -4 -2 2 4 -4 -2 2 4 (0; −1) • -2 -2 -4 -4 x2 − y2 = 1 y2 − x2 = 1 x2 − y2 = 1 is the unit hyperbola. Hyperbolic Functions: Similar to how the trigonometric functions, cosine and sine, correspond to the x and y values of the unit circle (x2 + y2 = 1), there are hyperbolic functions, hyperbolic cosine (cosh) and hyperbolic sine (sinh), which correspond to the x and y values of the right side of the unit hyperbola (x2 − y2 = 1). y y -1 1 x x π π 3π 2π π π 3π 2π 2 2 2 2 -1 -1 cos x sin x y y 6 2 4 x 2 -2 2 • (0; 1) -2 x -2 2 cosh x sinh x Hyperbolic Angle: Just like how the argument for the trigonometric functions is an angle, the argument for the hyperbolic functions is something called a hyperbolic angle. Instead of being defined by arc length, the hyperbolic angle is defined by area. If that seems confusing, consider the area of the circular sector of the unit circle. The r2θ equation for the area of a circular sector is Area = 2 , so because the radius of the unit circle is 1, any sector of the unit circle will have an area equal to half of the sector's central θ angle, A = 2 . -

Hyperbolic Geometry
Flavors of Geometry MSRI Publications Volume 31, 1997 Hyperbolic Geometry JAMES W. CANNON, WILLIAM J. FLOYD, RICHARD KENYON, AND WALTER R. PARRY Contents 1. Introduction 59 2. The Origins of Hyperbolic Geometry 60 3. Why Call it Hyperbolic Geometry? 63 4. Understanding the One-Dimensional Case 65 5. Generalizing to Higher Dimensions 67 6. Rudiments of Riemannian Geometry 68 7. Five Models of Hyperbolic Space 69 8. Stereographic Projection 72 9. Geodesics 77 10. Isometries and Distances in the Hyperboloid Model 80 11. The Space at Infinity 84 12. The Geometric Classification of Isometries 84 13. Curious Facts about Hyperbolic Space 86 14. The Sixth Model 95 15. Why Study Hyperbolic Geometry? 98 16. When Does a Manifold Have a Hyperbolic Structure? 103 17. How to Get Analytic Coordinates at Infinity? 106 References 108 Index 110 1. Introduction Hyperbolic geometry was created in the first half of the nineteenth century in the midst of attempts to understand Euclid’s axiomatic basis for geometry. It is one type of non-Euclidean geometry, that is, a geometry that discards one of Euclid’s axioms. Einstein and Minkowski found in non-Euclidean geometry a ThisworkwassupportedinpartbyTheGeometryCenter,UniversityofMinnesota,anSTC funded by NSF, DOE, and Minnesota Technology, Inc., by the Mathematical Sciences Research Institute, and by NSF research grants. 59 60 J. W. CANNON, W. J. FLOYD, R. KENYON, AND W. R. PARRY geometric basis for the understanding of physical time and space. In the early part of the twentieth century every serious student of mathematics and physics studied non-Euclidean geometry. This has not been true of the mathematicians and physicists of our generation. -

Using Differentials to Differentiate Trigonometric and Exponential Functions
Using differentials to differentiate trigonometric and exponential functions Tevian Dray Department of Mathematics Oregon State University Corvallis, OR 97331 [email protected] 3 April 2012 Differentiating a polynomial is easy. To differentiate u2 with respect to u, start by computing d(u2)=(u + du)2 − u2 = 2u du + du2 then dropping the last term, an operation that can be justified in terms of limits. Differential notation, in general, can be regarded as a shorthand for a formal limit argument. Still more informally, one can argue that du is small compared to u, so that the last term can be ignored at the level of approximation needed. After dropping du2 and dividing by du, one obtains the derivative, namely d(u2)/du = 2u. Even if one regards this process as merely a heuristic procedure, it is a good one, as it always gives the correct answer for a polynomial. (Physicists are particularly good at knowing what approximations are appropriate in a given physical context. A physicist might describe du as being much smaller than the scale imposed by the physical situation, but not so small that quantum mechanics matters.) However, this procedure does not suffice for trigonometric functions. For example, we may write d(sin θ) = sin(θ + dθ) − sin θ = sin θ cos(dθ) − 1 + cos θ sin(dθ), ³ ´ 1 but to go further we must know something about sin θ and cos θ for small values of θ. Exponential functions offer a similar challenge, since d(eβ)= eβ+dβ − eβ = eβ(edβ − 1), and again we need additional information, in this case about eβ for small values of β. -

A Geometric Introduction to Spacetime and Special Relativity
A GEOMETRIC INTRODUCTION TO SPACETIME AND SPECIAL RELATIVITY. WILLIAM K. ZIEMER Abstract. A narrative of special relativity meant for graduate students in mathematics or physics. The presentation builds upon the geometry of space- time; not the explicit axioms of Einstein, which are consequences of the geom- etry. 1. Introduction Einstein was deeply intuitive, and used many thought experiments to derive the behavior of relativity. Most introductions to special relativity follow this path; taking the reader down the same road Einstein travelled, using his axioms and modifying Newtonian physics. The problem with this approach is that the reader falls into the same pits that Einstein fell into. There is a large difference in the way Einstein approached relativity in 1905 versus 1912. I will use the 1912 version, a geometric spacetime approach, where the differences between Newtonian physics and relativity are encoded into the geometry of how space and time are modeled. I believe that understanding the differences in the underlying geometries gives a more direct path to understanding relativity. Comparing Newtonian physics with relativity (the physics of Einstein), there is essentially one difference in their basic axioms, but they have far-reaching im- plications in how the theories describe the rules by which the world works. The difference is the treatment of time. The question, \Which is farther away from you: a ball 1 foot away from your hand right now, or a ball that is in your hand 1 minute from now?" has no answer in Newtonian physics, since there is no mechanism for contrasting spatial distance with temporal distance. -

1 Hyperbolic Geometry
1 Hyperbolic Geometry The purpose of this chapter is to give a bare bones introduction to hyperbolic geometry. Most of material in this chapter can be found in a variety of sources, for example: Alan Beardon’s book, The Geometry of Discrete Groups, • Bill Thurston’s book, The Geometry and Topology of Three Manifolds, • Svetlana Katok’s book, Fuchsian Groups, • John Ratcliffe’s book, Hyperbolic Geometry. • The first 2 sections of this chapter might not look like geometry at all, but they turn out to be very important for the subject. 1.1 Linear Fractional Transformations Suppose that a b A = c d isa2 2 matrix with complex number entries and determinant 1. The set of × these matrices is denoted by SL2(C). In fact, this set forms a group under matrix multiplication. The matrix A defines a complex linear fractional transformation az + b T (z)= . A cz + d We will sometimes omit the word complex from the name, though we will always have in mind a complex linear fractional transformation when we say linear fractional transformation. Such maps are also called M¨obius transfor- mations, Note that the denominator of T (z) is nonzero as long as z = d/c. It is A 6 − convenient to introduce an extra point and define TA( d/c) = . This definition is a natural one because of the∞ limit − ∞ lim TA(z) = . z d/c →− | | ∞ 1 The determinant condition guarantees that a( d/c)+ b = 0, which explains − 6 why the above limit works. We define TA( ) = a/c. This makes sense because of the limit ∞ lim TA(z)= a/c. -

Getting Started with the CORDIC Accelerator Using Stm32cubeg4 MCU Package
AN5325 Application note Getting started with the CORDIC accelerator using STM32CubeG4 MCU Package Introduction This document applies to STM32CubeG4 MCU Package, for use with STM32G4 Series microcontrollers. The CORDIC is a hardware accelerator designed to speed up the calculation of certain mathematical functions, notably trigonometric and hyperbolic, compared to a software implementation. The accelerator is particularly useful in motor control and related applications, where algorithms require frequent and rapid conversions between rectangular (x, y) and angular (amplitude, phase) co-ordinates. This application note describes how the CORDIC accelerator works on STM32G4 Series microcontrollers, its capabilities and limitations, and evaluates the speed of execution for certain calculations compared with equivalent software implementations. The example code to accompany this application note is included in the STM32CubeG4 MCU Package available on www.st.com. The examples run on the NUCLEO-G474RE board. AN5325 - Rev 2 - March 2021 www.st.com For further information contact your local STMicroelectronics sales office. AN5325 General information 1 General information The STM32CubeG4 MCU Package runs on STM32G4 Series microncontrollers, based on Arm® Cortex®-M4 processors. Note: Arm is a registered trademark of Arm Limited (or its subsidiaries) in the US and/or elsewhere. AN5325 - Rev 2 page 2/20 AN5325 CORDIC introduction 2 CORDIC introduction The CORDIC (coordinate rotation digital computer) is a low-cost successive approximation algorithm for evaluating trigonometric and hyperbolic functions. Originally presented by Jack Volder in 1959, it was widely used in early calculators. In trigonometric (circular) mode, the sine and cosine of an angle are determined by rotating the vector [0.61, 0] through decreasing angles tan-1(2-n) (n = 0, 1, 2,...) until the cumulative sum of the rotation angles equals the input angle. -

The Hyperbolic Number Plane
The Hyperbolic Number Plane Garret Sobczyk Universidad de las Americas email: [email protected] INTRODUCTION. The complex numbers were grudgingly accepted by Renaissance mathematicians because of their utility in solving the cubic equation.1 Whereas the complex numbers were discovered primar- ily for algebraic reasons, they take on geometric significance when they are used to name points in the plane. The complex number system is at the heart of complex analysis and has enjoyed more than 150 years of intensive development, finding applications in diverse areas of science and engineering. At the beginning of the Twentieth Century, Albert Einstein developed his theory of special relativity, built upon Lorentzian geometry, yet at the end of the century almost all high school and undergraduate students are still taught only Euclidean geometry. At least part of the reason for this state of affairs has been the lack of a simple mathematical formalism in which the basic ideas can be expressed. I argue that the hyperbolic numbers, blood relatives of the popular complex numbers, deserve to become a part of the undergraduate math- ematics curriculum. They serve not only to put Lorentzian geometry on an equal mathematical footing with Euclidean geometry; their study also helps students develop algebraic skills and concepts necessary in higher mathematics. I have been teaching the hyperbolic number plane to my linear algebra and calculus students and have enjoyed an enthusiastic response. THE HYPERBOLIC NUMBERS. The real number system can be extended in a new way. Whereas the algebraic equation x2 − 1 = 0 has the real number solutions x = ±1, we assume the existence of a new number, the unipotent u, which has the algebraic property that u 6= ±1 but u2 = 1.