Error Correction Code in Soc FPGA-Based Memory Systems
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Radiation-Induced Soft Errors in Advanced Semiconductor Technologies Robert C
IEEE TRANSACTIONS ON DEVICE AND MATERIALS RELIABILITY, VOL. 5, NO. 3, SEPTEMBER 2005 305 Radiation-Induced Soft Errors in Advanced Semiconductor Technologies Robert C. Baumann, Fellow, IEEE Invited Paper Abstract—The once-ephemeral radiation-induced soft error has bit upset (SBU). While MBUs are usually a small fraction of become a key threat to advanced commercial electronic compo- the total observed SEU rate, their occurrence has implications nents and systems. Left unchallenged, soft errors have the poten- for memory architecture in systems utilizing error correction tial for inducing the highest failure rate of all other reliability mechanisms combined. This article briefly reviews the types of [3], [4]. Another type of soft error occurs when the bit that failure modes for soft errors, the three dominant radiation mech- is flipped is in a critical system control register such as that anisms responsible for creating soft errors in terrestrial applica- found in field-programmable gate arrays (FPGAs) or dynamic tions, and how these soft errors are generated by the collection of random access memory (DRAM) control circuitry, so that the radiation-induced charge. The soft error sensitivity as a function error causes the product to malfunction [5]. This type of soft of technology scaling for various memory and logic components is then presented with a consideration of which applications are most error, called a single event interrupt (SEFI), obviously impacts likely to require soft error mitigation. the product reliability since each SEFI leads to a direct product malfunction as opposed to typical memory soft errors that may Index Terms—Radiation effects, reliability, single-event effects, soft errors. -

Recommendation Itu-R Bt.2016*
Recommendation ITU-R BT.2016 (04/2012) Error-correction, data framing, modulation and emission methods for terrestrial multimedia broadcasting for mobile reception using handheld receivers in VHF/UHF bands BT Series Broadcasting service (television) ii Rec. ITU-R BT.2016 Foreword The role of the Radiocommunication Sector is to ensure the rational, equitable, efficient and economical use of the radio-frequency spectrum by all radiocommunication services, including satellite services, and carry out studies without limit of frequency range on the basis of which Recommendations are adopted. The regulatory and policy functions of the Radiocommunication Sector are performed by World and Regional Radiocommunication Conferences and Radiocommunication Assemblies supported by Study Groups. Policy on Intellectual Property Right (IPR) ITU-R policy on IPR is described in the Common Patent Policy for ITU-T/ITU-R/ISO/IEC referenced in Annex 1 of Resolution ITU-R 1. Forms to be used for the submission of patent statements and licensing declarations by patent holders are available from http://www.itu.int/ITU-R/go/patents/en where the Guidelines for Implementation of the Common Patent Policy for ITU-T/ITU-R/ISO/IEC and the ITU-R patent information database can also be found. Series of ITU-R Recommendations (Also available online at http://www.itu.int/publ/R-REC/en) Series Title BO Satellite delivery BR Recording for production, archival and play-out; film for television BS Broadcasting service (sound) BT Broadcasting service (television) F Fixed service M Mobile, radiodetermination, amateur and related satellite services P Radiowave propagation RA Radio astronomy RS Remote sensing systems S Fixed-satellite service SA Space applications and meteorology SF Frequency sharing and coordination between fixed-satellite and fixed service systems SM Spectrum management SNG Satellite news gathering TF Time signals and frequency standards emissions V Vocabulary and related subjects Note: This ITU-R Recommendation was approved in English under the procedure detailed in Resolution ITU-R 1. -
ACRONYMS and ABBREVIATIONS BLUETOOTH SPECIFICATION Version 1.1 Page 914 of 1084
Appendix III ACRONYMS AND ABBREVIATIONS BLUETOOTH SPECIFICATION Version 1.1 page 914 of 1084 Appendix III - Acronyms 914 22 February 2001 BLUETOOTH SPECIFICATION Version 1.1 page 915 of 1084 Appendix III - Acronyms List of Acronyms and Abbreviations Acronym or Writing out in full Which means abbreviation ACK Acknowledge ACL link Asynchronous Connection-Less Provides a packet-switched con- link nection.(Master to any slave) ACO Authenticated Ciphering Offset AM_ADDR Active Member Address AR_ADDR Access Request Address ARQ Automatic Repeat reQuest B BB BaseBand BCH Bose, Chaudhuri & Hocquenghem Type of code The persons who discovered these codes in 1959 (H) and 1960 (B&C) BD_ADDR Bluetooth Device Address BER Bit Error Rate BT Bandwidth Time BT Bluetooth C CAC Channel Access Code CC Call Control CL Connectionless CODEC COder DECoder COF Ciphering Offset CRC Cyclic Redundancy Check CVSD Continuous Variable Slope Delta Modulation D DAC Device Access Code DCE Data Communication Equipment 22 February 2001 915 BLUETOOTH SPECIFICATION Version 1.1 page 916 of 1084 Appendix III - Acronyms Acronym or Writing out in full Which means abbreviation DCE Data Circuit-Terminating Equip- In serial communications, DCE ment refers to a device between the communication endpoints whose sole task is to facilitate the commu- nications process; typically a modem DCI Default Check Initialization DH Data-High Rate Data packet type for high rate data DIAC Dedicated Inquiry Access Code DM Data - Medium Rate Data packet type for medium rate data DTE Data Terminal Equipment In serial communications, DTE refers to a device at the endpoint of the communications path; typi- cally a computer or terminal. -

HP Z620 Memory Configurations and Optimization
HP recommends Windows® 7. HP Z620 Memory Configurations and Optimization The purpose of this document is to provide an overview of the memory configuration for the HP Z620 Workstation and to provide recommendations to optimize performance. Supported Memory Modules1 Memory Features The types of memory supported on a HP Z620 are: ECC is supported on all of our supported DIMMs. • 2 GB and 4 GB PC3-12800E 1600MHz DDR3 • Single-bit errors are automatically corrected. Unbuffered ECC DIMMs • Multi-bit errors are detected and will cause the • 4 GB and 8 GB PC3-12800R 1600MHz DDR3 system to immediately reboot and halt with an Registered DIMMs F1 prompt error message. • 1.35V and 1.5V DIMMs are supported, but the Non-ECC memory does not detect or correct system will operate the DIMMs at 1.5V only. single-bit or multi-bit errors which can cause • 2 Gb and 4 Gb based DIMMs are supported. instability, or corruption of data, in the platform. See the Memory Technology White Paper for See the Memory Technology White Paper for additional technical information. additional technical information. Command and Address parity is supported with Platform Capabilities Registered DIMMs. Maximum capacity Optimize Performance • Single processor: 64 GB Generally, maximum memory performance is • Dual processors: 96 GB achieved by evenly distributing total desired memory capacity across all operational Total of 12 memory sockets channels. Proper individual DIMM capacity • 8 sockets on the motherboard: 4 channels per selection is essential to maximizing performance. processor and 2 sockets per channel On the second CPU, installing the same • 4 sockets on the 2nd CPU and memory amount of memory as the first CPU will optimize module: 4 channels per processor and 1 performance. -

Implementation and Evaluation of Polar Codes in 5G
Implementation and evaluation of Polar Codes in 5G Implementation och evaluering av Polar Codes för 5G Tobias Rosenqvist Joël Sloof Faculty of Health, Science and Technology Computer Science 15 hp Supervisor: Stefan Alfredsson Examiner: Kerstin Andersson Date: 2019-06-12 Serial number: N/A Implementation and evaluation of Polar Codes in 5G Tobias Rosenqvist, Joël Sloof © 2019 The author(s) and Karlstad University This report is submitted in partial fulfillment of the requirements for the Bachelor’s degree in Computer Science. All material in this report which is not our own work has been identified and no material is included for which a degree has previously been conferred. Tobias Rosenqvist Joël Sloof Approved, Date of defense Advisor: Stefan Alfredsson Examiner: Kerstin Andersson iii Abstract In today’s society the ability to communicate with one another has grown, were a lot of focus is aimed towards speed in the telecommunication industry. For transmissions to become even faster, there are many ways to enhance transmission speeds of which error correction is one. Padding messages such that they are protected from noise, while using as few bits as possible and ensuring safe transmit is handled by error correction codes. Short codes with low complexity is a solution to faster transmission speeds. An error correction code which has gained a lot of attention since its first appearance in 2009 is Polar Codes. Polar Codes was chosen as the 3GPP standard for 5G control channel. The goal of the thesis is to develop and implement Polar Codes and rate matching according to the 3GPP standard 38.212. -

Applicability of the Julia Programming Language to Forward Error-Correction Coding in Digital Communications Systems
Applicability of the Julia Programming Language to Forward Error-Correction Coding in Digital Communications Systems A project presented to Department of Computer and Information Sciences State University of New York Polytechnic Institute At Utica/Rome Utica, New York In partial fulfillment Of the requirements of the Master of Science Degree by Ryan Quinn May 2018 Declaration I declare that this project is my own work and has not been submitted in any form for another degree of diploma at any university of other institute of tertiary education. Information derived from published and unpublished work of others has been acknowledged in the text and a list of references given. _ Ryan Quinn 2 | P a g e SUNY POLYTECHNIC INSTITUTE DEPARTMENT OF COMPUTER AND INFORMATION SCIENCES Approved and recommended for acceptance as a project in partial fulfillment of the requirements for the degree of Master of Science in computer and information science _ DATE _ Dr. Bruno R. Andriamanalimanana Advisor _ Dr. Saumendra Sengupta _ Dr. Scott Spetka 3 | P a g e 1 ABSTRACT Traditionally SDR has been implemented in C and C++ for execution speed and processor efficiency. Interpreted and high-level languages were considered too slow to handle the challenges of digital signal processing (DSP). The Julia programming language is a new language developed for scientific and mathematical purposes that is supposed to write like Python or MATLAB and execute like C or FORTRAN. Given the touted strengths of the Julia language, it bore investigating as to whether it was suitable for DSP. This project specifically addresses the applicability of Julia to forward error correction (FEC), a highly mathematical topic to which Julia should be well suited. -

MARS-C: Modeling and Reduction of Soft Errors in Combinational Circuits
MARS-C: Modeling and Reduction of Soft Errors in Combinational Circuits Natasa Miskov-Zivanov, Diana Marculescu Department of Electrical and Computer Engineering Carnegie Mellon University {nmiskov,dianam}@ece.cmu.edu ABSTRACT completely masked before it reaches the latch; Due to the shrinking of feature size and reduction in supply voltages, • latching-window masking – only if the glitch reaches the latch nanoscale circuits have become more susceptible to radiation induced and satisfies setup and hold time conditions, it will be latched. transient faults. In this paper, we present a symbolic framework based In this work, we estimate the likelihood that a transient fault will on BDDs and ADDs that enables analysis of combinational circuit lead to a soft error. Our main goal is to allow for symbolic modeling reliability from different aspects: output susceptibility to error, and efficient estimation of the susceptibility of a combinational logic influence of individual gates on individual outputs and overall circuit circuit to soft errors. We further use this framework to reduce the cost reliability, and the dependence of circuit reliability on glitch duration, of radiation hardening techniques by selectively resizing the gates that amplitude, and input patterns. This is demonstrated by the set of have the largest impact on circuit error. experimental results, which show that the mean output error The rest of this paper is organized as follows. In Section 2 we susceptibility can vary from less than 0.1%, for large circuits and outline the contribution of our work. In Section 3 we give an overview small glitches, to about 30% for very small circuits and large enough of related work. -

16.548 Notes 15: Concatenated Codes, Turbo Codes and Iterative Processing Outline
16.548 Notes 15: Concatenated Codes, Turbo Codes and Iterative Processing Outline ! Introduction " Pushing the Bounds on Channel Capacity " Theory of Iterative Decoding " Recursive Convolutional Coding " Theory of Concatenated codes ! Turbo codes " Encoding " Decoding " Performance analysis " Applications ! Other applications of iterative processing " Joint equalization/FEC " Joint multiuser detection/FEC Shannon Capacity Theorem Capacity as a function of Code rate Motivation: Performance of Turbo Codes. Theoretical Limit! ! Comparison: " Rate 1/2 Codes. " K=5 turbo code. " K=14 convolutional code. ! Plot is from: L. Perez, “Turbo Codes”, chapter 8 of Trellis Coding by C. Schlegel. IEEE Press, 1997. Gain of almost 2 dB! Power Efficiency of Existing Standards Error Correction Coding ! Channel coding adds structured redundancy to a transmission. mxChannel Encoder " The input message m is composed of K symbols. " The output code word x is composed of N symbols. " Since N > K there is redundancy in the output. " The code rate is r = K/N. ! Coding can be used to: " Detect errors: ARQ " Correct errors: FEC Traditional Coding Techniques The Turbo-Principle/Iterative Decoding ! Turbo codes get their name because the decoder uses feedback, like a turbo engine. Theory of Iterative Coding Theory of Iterative Coding(2) Theory of Iterative Coding(3) Theory of Iterative Coding (4) Log Likelihood Algebra New Operator Modulo 2 Addition Example: Product Code Iterative Product Decoding RSC vs NSC Recursive/Systematic Convolutional Coding Concatenated Coding -
Scaling and Technology Issues for Soft Error Rates Allan
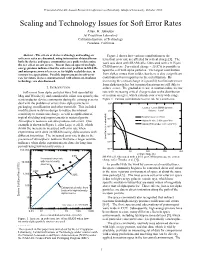
Presented at the 4th Annual Research Conference on Reliability, Stanford University, October 2000 Scaling and Technology Issues for Soft Error Rates Allan. H. Johnston Jet Propulsion Laboratory California Institute of Technology Pasadena, California Abstract - The effects of device technology and scaling on Figure 2 shows how various contributions to the soft error rates are discussed, using information obtained from terrestrial error rate are affected by critical charge [3]. The both the device and space communities as a guide to determine work was done with SRAM cells, fabricated with a 0.35 µm the net effect on soft errors. Recent data on upset from high- CMOS process. For critical charge < 35 fC it is possible to energy protons indicates that the soft-error problem in DRAMs and microprocessors is less severe for highly scaled devices, in upset the cell with alpha particles. The largest contribution contrast to expectations. Possible improvements in soft-error from alphas comes from solder, but there is also a significant rate for future devices, manufactured with silicon-on-insulator contribution from impurities in the metallization. By technology, are also discussed. increasing the critical charge it is possible to eliminate errors from alpha particles, but terrestrial neutrons are still able to I. INTRODUCTION induce errors. The gradual decrease in neutron-induced error Soft-errors from alpha particles were first reported by rate with increasing critical charge is due to the distribution May and Woods [1], and considerable effort was spent by the of neutron energies, which extends over a very wide range. semiconductor device community during the ensuing years to Figure 2. -

Interfacing EPROM to the 8088
Chapter 10: Memory Interface Introduction Simple or complex, every microprocessor-based system has a memory system. Almost all systems contain two main types of memory: read-only memory (ROM) and random access memory (RAM) or read/write memory. This chapter explains how to interface both memory types to the Intel family of microprocessors. MEMORY DEVICES Before attempting to interface memory to the microprocessor, it is essential to understand the operation of memory components. In this section, we explain functions of the four common types of memory: read-only memory (ROM) Flash memory (EEPROM) Static random access memory (SRAM) dynamic random access memory (DRAM) Memory Pin Connections – address inputs – data outputs or input/outputs – some type of selection input – at least one control input to select a read or write operation Figure 10–1 A pseudomemory component illustrating the address, data, and control connections. Address Connections Memory devices have address inputs to select a memory location within the device. Almost always labeled from A0, the least significant address input, to An where subscript n can be any value always labeled as one less than total number of address pins A memory device with 10 address pins has its address pins labeled from A0 to A9. The number of address pins on a memory device is determined by the number of memory locations found within it. Today, common memory devices have between 1K (1024) to 1G (1,073,741,824) memory locations. with 4G and larger devices on the horizon A 1K memory device has 10 address pins. therefore, 10 address inputs are required to select any of its 1024 memory locations It takes a 10-bit binary number to select any single location on a 1024-location device. -

Radiation Hardening Efficiency of Gate Sizing and Transistor Stacking Based on Standard Cells
Radiation hardening efficiency of gate sizing and transistor stacking based on standard cells Y.Q. Aguiar, Frédéric Wrobel, S. Guagliardo, J.-L. Autran, P. Leroux, F. Saigné, A.D. Touboul, V. Pouget To cite this version: Y.Q. Aguiar, Frédéric Wrobel, S. Guagliardo, J.-L. Autran, P. Leroux, et al.. Radiation hardening efficiency of gate sizing and transistor stacking based on standard cells. Microelectronics Reliability, Elsevier, 2019, 100-101, pp.113457. 10.1016/j.microrel.2019.113457. hal-02515096 HAL Id: hal-02515096 https://hal.archives-ouvertes.fr/hal-02515096 Submitted on 24 Mar 2020 HAL is a multi-disciplinary open access L’archive ouverte pluridisciplinaire HAL, est archive for the deposit and dissemination of sci- destinée au dépôt et à la diffusion de documents entific research documents, whether they are pub- scientifiques de niveau recherche, publiés ou non, lished or not. The documents may come from émanant des établissements d’enseignement et de teaching and research institutions in France or recherche français ou étrangers, des laboratoires abroad, or from public or private research centers. publics ou privés. Radiation Hardening Efficiency of Gate Sizing and Transistor Stacking based on Standard Cells Y. Q. Aguiara,*, F. Wrobela, S. Guagliardoa, J-L. Autranb, P. Lerouxc, F. Saignéa, A. D. Touboula and V. Pougeta a Institut d’Electronique et des Systèmes, University of Montpellier, Montpellier, France b Institut Materiaux Microelectronique Nanoscience de Provence, Aix-Marseille University, Marseille, France c Advanced Integrated Sensing Lab, KU Leuven University, Leuven, Belgium Abstract Soft error mitigation schemes inherently lead to penalties in terms of area usage, power consumption and/or performance metrics. -

Itanium-Based Solutions by Hp
Itanium-based solutions by hp an overview of the Itanium™-based hp rx4610 server a white paper from hewlett-packard june 2001 table of contents table of contents 2 executive summary 3 why Itanium is the future of computing 3 rx4610 at a glance 3 rx4610 product specifications 4 rx4610 physical and environmental specifications 4 the rx4610 and the hp server lineup 5 rx4610 architecture 6 64-bit address space and memory capacity 6 I/O subsystem design 7 special features of the rx4610 server 8 multiple upgrade and migration paths for investment protection 8 high availability and manageability 8 advanced error detection, correction, and containment 8 baseboard management controller (BMC) 8 redundant, hot-swap power supplies 9 redundant, hot-swap cooling 9 hot-plug disk drives 9 hot-plug PCI I/O slots 9 internal removable media 10 system control panel 10 ASCII console for hp-ux 10 space-saving rack density 10 complementary design and packaging 10 how hp makes the Itanium transition easy 11 binary compatibility 11 hp-ux operating system 11 seamless transition—even for home-grown applications 12 transition help from hp 12 Itanium quick start service 12 partner technology access centers 12 upgrades and financial incentives 12 conclusion 13 for more information 13 appendix: Itanium advantages in your computing future 14 hp’s CPU roadmap 14 Itanium processor architecture 15 predication enhances parallelism 15 speculation minimizes the effect of memory latency 15 inherent scalability delivers easy expansion 16 what this means in a server 16 2 executive The Itanium™ Processor Family is the next great stride in computing--and it’s here today.