Extracting Fine-Grained Implicit Georeferencing Information from Microblogs Exploiting Crowdsourced Gazetteers and Social Interactions
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Georeferencing Accuracy of Geoeye-1 Stereo Imagery: Experiences in a Japanese Test Field
International Archives of the Photogrammetry, Remote Sensing and Spatial Information Science, Volume XXXVIII, Part 8, Kyoto Japan 2010 GEOREFERENCING ACCURACY OF GEOEYE-1 STEREO IMAGERY: EXPERIENCES IN A JAPANESE TEST FIELD Y. Meguro a, *, C.S.Fraser b a Japan Space Imaging Corp., 8-1Yaesu 2-Chome, Chuo-Ku, Tokyo 104-0028, Japan - [email protected] b Department of Geomatics, University of Melbourne VIC 3010, Australia - [email protected] Commission VIII, Working Group ICWG IV/VIII KEY WORDS: GeoEye-1, Stereo, RPCs, geopositioning, accuracy evaluation, bias compensation, satellite imagery ABSTRACT: High-resolution satellite imagery (HRSI) is being increasingly employed for large-scale topographic mapping, and especially for geodatabase updating. As the spatial resolution of HRSI sensors increases, so the potential georeferencing accuracy also improves. However, accuracy is not a function of spatial resolution alone, as it is also dependent upon radiometric image quality, the dynamics of the image scanning, and the fidelity of the sensor orientation model, both directly from orbit and attitude observations and indirectly from ground control points (GCPs). Users might anticipate accuracies of, say, 1 pixel in planimetry and 1-3 pixels in height when using GCPs. However, there are practical and in some cases administrative/legal imperatives for the georeferencing accuracy of HRSI systems to be quantified through well controlled tests. This paper discusses an investigation into the georeferencing accuracy attainable from the GeoEye-1 satellite, and specifically the 3D accuracy achievable from stereo imagery. Both direct georeferencing via supplied RPCs and indirect georeferencing via ground control and bias-corrected RPCs were examined for a stereo pair of pansharpened GeoEye-1 Basic images covering the Tsukuba Test Field in Japan, which contains more than 100 precisely surveyed and image identifiable GCPs. -

Knowledge-Driven Geospatial Location Resolution for Phylogeographic
Bioinformatics, 31, 2015, i348–i356 doi: 10.1093/bioinformatics/btv259 ISMB/ECCB 2015 Knowledge-driven geospatial location resolution for phylogeographic models of virus migration Davy Weissenbacher1,*, Tasnia Tahsin1, Rachel Beard1,2, Mari Figaro1,2, Robert Rivera1, Matthew Scotch1,2 and Graciela Gonzalez1 1Department of Biomedical Informatics, Arizona State University, Scottsdale, AZ 85259, USA and 2Center for Environmental Security, Biodesign Institute, Arizona State University, Tempe, AZ 85287-5904, USA *To whom correspondence should be addressed. Abstract Summary: Diseases caused by zoonotic viruses (viruses transmittable between humans and ani- mals) are a major threat to public health throughout the world. By studying virus migration and mutation patterns, the field of phylogeography provides a valuable tool for improving their surveil- lance. A key component in phylogeographic analysis of zoonotic viruses involves identifying the specific locations of relevant viral sequences. This is usually accomplished by querying public data- bases such as GenBank and examining the geospatial metadata in the record. When sufficient detail is not available, a logical next step is for the researcher to conduct a manual survey of the corresponding published articles. Motivation: In this article, we present a system for detection and disambiguation of locations (topo- nym resolution) in full-text articles to automate the retrieval of sufficient metadata. Our system has been tested on a manually annotated corpus of journal articles related to phylogeography using inte- grated heuristics for location disambiguation including a distance heuristic, a population heuristic and a novel heuristic utilizing knowledge obtained from GenBank metadata (i.e. a ‘metadata heuristic’). Results: For detecting and disambiguating locations, our system performed best using the meta- data heuristic (0.54 Precision, 0.89 Recall and 0.68 F-score). -

Introduction to Georeferencing
Introduction to Georeferencing Turning paper maps to interactive layers DMDS Workshop Jay Brodeur 2019-02-29 Today’s Outline ➢ Basic fundamentals of GIS and geospatial data ⚬ Vectors vs. rasters ⚬ Coordinate reference systems ➢ Introduction to Quantum GIS (QGIS) ➢ Hands-on Problem-Solving Assignments Quantum GIS (QGIS) ➢ Free and open-source GIS software ➢ User-friendly, fully-functional; relatively lightweight ➢ Product of the Open Source Geospatial Foundation (OSGeo) ➢ Built in C++; uses python for scripting and plugins ➢ Version 1.0 released in 2009 ➢ Current version: 3.16; Long-term release (LTR): 3.14 GDAL - Geospatial Data Abstraction Library www.gdal.org SAGA - System for Automated Geoscientific Analyses saga-gis.org/ GRASS - Geographic Resources Analysis Support System www.grass.osgeo.org QGIS - Quantum GIS qgis.org GeoTools www.geotools.org Helpful QGIS Tutorials and Resources ➢ QGIS Tutorials: http://www.qgistutorials.com/en/ ➢ QGIS Quicktips with Klas Karlsson: https://www.youtube.com/channel/UCxs7cfMwzgGZhtUuwhny4-Q ➢ QGIS Training Guide: https://docs.qgis.org/2.8/en/docs/training_manual/ Geospatial Data Fundamentals Representing real-world geographic information in a computer Task 1: Compare vector and raster data layers Objective: Download some openly-available raster and vector data. Explore the differences. Topics Covered: ➢ The QGIS Interface ➢ Geospatial data ➢ Layer styling ➢ Vectors vs rasters Online version of notes: https://goo.gl/H5vqNs Task 1.1: Downloading vector raster data & adding it to your map 1. Navigate a browser to Scholars Geoportal: http://geo.scholarsportal.info/ 2. Search for ‘index’ using the ‘Historical Maps’ category 3. Load the 1:25,000 topo map index 4. Use the interactive index to download the 1972 map sheet of Hamilton 5. -
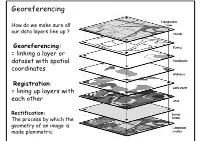
Georeferencing
Georeferencing How do we make sure all our data layers line up ? Georeferencing: = linking a layer or dataset with spatial coordinates Registration: = lining up layers with each other Rectification: The process by which the geometry of an image is made planimetric Georeferencing • ‘To georeference’ the act of assigning locations to atoms of information • Is essential in GIS, since all information must be linked to the Earth’s surface • The method of georeferencing must be: – Unique, linking information to exactly one location – Shared, so different users understand the meaning of a georeference – Persistent through time, so today’s georeferences are still meaningful tomorrow Georeferencing Based on Data Types • Raster and Raster • Vector and Vector • Raster and Vector Geocoding Concepts and Definitions Definition of Geocoding • Geocoding can be broadly defined as the assignment of a code to a geographic location. Usually however, Geocoding refers to a more specific assignment of geographic coordinates (latitude,Longitude) to an individual address.. UN Report Definition of Geocoding • What is Geocoding • Geocoding is a process of creating map features from addresses, place names, or similar textual information based on attributes associated with a referenced geographic database, typically a street network that has address ranges associated with each street segment or 'link' running from one intersection to the next. Definition of Geocoding • What is Geocoding • Geocoding typically uses Interpolation as a method to find the location information about an address. – (If the address along one side of a block range from 1 to 199, then Street Number = 66 is about one-third of the way along that side of the block.) • Data required: – Reasonably clean, consistent list of legal addresses (i.e. -

A Comparison of Address Point and Street Geocoding Techniques
A COMPARISON OF ADDRESS POINT AND STREET GEOCODING TECHNIQUES IN A COMPUTER AIDED DISPATCH ENVIRONMENT by Jimmy Tuan Dao A Thesis Presented to the FACULTY OF THE USC GRADUATE SCHOOL UNIVERSITY OF SOUTHERN CALIFORNIA In Partial Fulfillment of the Requirements for the Degree MASTER OF SCIENCE (GEOGRAPHIC INFORMATION SCIENCE AND TECHNOLOGY) August 2015 Copyright 2015 Jimmy Tuan Dao DEDICATION I dedicate this document to my mother, sister, and Marie Knudsen who have inspired and motivated me throughout this process. The encouragement that I received from my mother and sister (Kim and Vanna) give me the motivation to pursue this master's degree, so I can better myself. I also owe much of this success to my sweetheart and life-partner, Marie who is always available to help review my papers and offer support when I was frustrated and wanting to quit. Thank you and I love you! ii ACKNOWLEDGMENTS I will be forever grateful to the faculty and classmates at the Spatial Science Institute for their support throughout my master’s program, which has been a wonderful period of my life. Thank you to my thesis committee members: Professors Darren Ruddell, Jennifer Swift, and Daniel Warshawsky for their assistance and guidance throughout this process. I also want to thank the City of Brea, my family, friends, and Marie Knudsen without whom I could not have made it this far. Thank you! iii TABLE OF CONTENTS DEDICATION ii ACKNOWLEDGMENTS iii LIST OF TABLES iii LIST OF FIGURES iv LIST OF ABBREVIATIONS vi ABSTRACT vii CHAPTER 1: INTRODUCTION 1 1.1 Brea, California -

Toponym Resolution in Scientific Papers
SemEval-2019 Task 12: Toponym Resolution in Scientific Papers Davy Weissenbachery, Arjun Maggez, Karen O’Connory, Matthew Scotchz, Graciela Gonzalez-Hernandezy yDBEI, The Perelman School of Medicine, University of Pennsylvania, Philadelphia, PA 19104, USA zBiodesign Center for Environmental Health Engineering, Arizona State University, Tempe, AZ 85281, USA yfdweissen, karoc, [email protected] zfamaggera, [email protected] Abstract Disambiguation of toponyms is a more recent task (Leidner, 2007). We present the SemEval-2019 Task 12 which With the growth of the internet, the public adop- focuses on toponym resolution in scientific ar- ticles. Given an article from PubMed, the tion of smartphones equipped with Geographic In- task consists of detecting mentions of names formation Systems and the collaborative devel- of places, or toponyms, and mapping the opment of comprehensive maps and geographi- mentions to their corresponding entries in cal databases, toponym resolution has seen an im- GeoNames.org, a database of geospatial loca- portant gain of interest in the last two decades. tions. We proposed three subtasks. In Sub- Not only academic but also commercial and open task 1, we asked participants to detect all to- source toponym resolvers are now available. How- ponyms in an article. In Subtask 2, given to- ponym mentions as input, we asked partici- ever, their performance varies greatly when ap- pants to disambiguate them by linking them plied on corpora of different genres and domains to entries in GeoNames. In Subtask 3, we (Gritta et al., 2018). Toponym disambiguation asked participants to perform both the de- tackles ambiguities between different toponyms, tection and the disambiguation steps for all like Manchester, NH, USA vs. -

An Integrated INS/GPS Approach to the Georeferencing of Remotely
I PEER-REVIEWED ARTICLE An Integrated INSIGPS Approach to the Georeferencing of Remotely Sensed Data Abstract remote areas such as are found in many developing coun- A general model for the georeferencing of remotely sensed tries. data by an onboard positioning and orientation system is In the case of pushbroom imagery, the georeferencing presented as a problem of rigid body motion. The determina- problem is further complicated due to the need for the in- tion of the six independent parameters of motion by discrete stantaneous position and attitude information at each line of measurements from ineNealand satellife systems is directly imagery. Ground control alone is not sufficient to resolve all related to the problem of exterior orientation. The contribu- of the three position and three orientation (attitude) parame- tion of each measuring system to the determination of the ters associated with each exposure station, of which there three translational and three rotational parameters is treated may be thousands in a single mission. In order to overcome in detail, with emphasis on the contribution of inertial navi- these problems, systems have been proposed whereby multi- gation systems (INS] and single- and multi-antenna receivers ple look angles are simultaneously recorded with slight vari- of the Global Positioning System [GPS). The advantages of an ations in alignment (Hofmann et al., 1988). integrated INSIGPS approach are briefly discussed. Position- Another approach has been through the use of auxiliary ing and orientation accuracies obtainable from available position and navigation sensors which have been simulta- systems are then highlighted using selected results to em- neously flown during imaging missions. -

Guide to Best Practices for Georeferencing Includes Index ISBN: 87-92020-00-3
Guide to Best Practices for Georeferencing Guide to Best Practices for Georeferencing BioGeomancer Consortium August 2006 Published by: Global Biodiversity Information Facility, Copenhagen http://www.gbif.org Copyright © 2006 The Regents of the University of California. All rights reserved. The information in this book represents the professional opinion of the authors, and does not necessarily represent the views of the publisher or of the Regents of the University of California. While the authors and the publisher have attempted to make this book as accurate and as thorough as possible, the information contained herein is provided on an "As Is" basis, and without any warranties with respect to its accuracy or completeness. The authors, the publisher and the Regents of the University of California shall have no liability to any person or entity for any loss or damage caused by using the information provided in this book. Guide to Best Practices for Georeferencing Includes Index ISBN: 87-92020-00-3 Recommended Citation: Chapman, A.D. and J. Wieczorek (eds). 2006. Guide to Best Practices for Georeferencing. Copenhagen: Global Biodiversity Information Facility. Edited by: Arthur D. Chapman and John Wieczorek Contributors: J.Wieczorek, R.Guralnick, A.Chapman, C.Frazier, N.Rios, R.Beaman, Q.Guo. Contents CONTENTS ..............................................................................................................................................I GLOSSARY ...........................................................................................................................................III -

Using GIS with GPS
GIS Best Practices Using GIS with GPS March 2009 Table of Contents What Is GIS? 1 GPS-GAP Changes the Way We View the Earth 3 GIS and GPS Integration Eases Public Road Inventory 9 Dominion and Verizon Use Mobile GIS and GPS to Conduct Joint-Use Pole Survey 13 A Cost-Effective Approach to GPS/GIS Integration for Archaeological Surveying 17 Facilities Survey Feasible With GIS and GPS 23 i What Is GIS? Making decisions based on geography is basic to human thinking. Where shall we go, what will it be like, and what shall we do when we get there are applied to the simple event of going to the store or to the major event of launching a bathysphere into the ocean's depths. By understanding geography and people's relationship to location, we can make informed decisions about the way we live on our planet. A geographic information system (GIS) is a technological tool for comprehending geography and making intelligent decisions. GIS organizes geographic data so that a person reading a map can select data necessary for a specifi c project or task. A thematic map has a table of contents that allows the reader to add layers of information to a basemap of real-world locations. For example, a social analyst might use the basemap of Eugene, Oregon, and select datasets from the U.S. Census Bureau to add data layers to a map that shows residents' education levels, ages, and employment status. With an ability to combine a variety of datasets in an infi nite number of ways, GIS is a useful tool for nearly every fi eld of knowledge from archaeology to zoology. -

An Overview of Geotagging Geospatial Location
An Overview of Geotagging Geospatial location Archival collections may include a huge amount of original documents which contain geospa- tial location (toponym) data. Scientists, researchers and archivists are aware of the value of this information, and various tools have been developed to extract this key data from archival records (Kemp, 2008). Geospatial identification metadata generally involves latitude and longitude coordi- nates, coded placenames and data sources, etc. (Hunter, 2012). Tagging Tagging, a natural result of social media and semantic web technologies, involves labelling content with arbitrarily selected tags. Geotags, which describe the geospatial information of the content, are one of the most common online tag types (Hu & Ge, 2008), (Intagorn , et al., 2010). Geotagging Geotagging refers to the process of adding geospatial identification metadata to various types of media such as e-books, narrative documents, web content, images and video and social media applications (Facebook, Twitter, Foursquare etc) (Hunter, 2012). With various social web tools and applications, users can add geospatial information to web content, photographs, audio and video. Using hardware integrated with Global Positioning System (GPS) receivers, this can be done automatically (Hu & Ge, 2008). 2 Social media tools with geo-tagging capabilities Del.icio.us1 A social bookmarking site that allows users to save and tag web pages and resources. CiteULike2 An online service to organise academic publications that allows users to tag academic papers and books. Twitter3 A real-time micro-blogging platform/information network that allows users all over the world to share and discover what is happening. Users can publish their geotag while tweeting. Flickr4 A photo-sharing service that allows users to store, tag and geotag their personal photos, maintain a network of contacts and tag others photos. -

Enabling Post-Recording Deep Georeferencing of Walkthrough Videos: an Interactive Approach
Enabling post-recording deep georeferencing of walkthrough videos: an interactive approach by Samuel Navas Medrano A thesis submitted in partial fulfillment for the Master degree of Science in Geospatial Technologies in the Institute for Geoinformatiks February 2016 Declaration of Authorship I, SAMUEL NAVAS MEDRANO, declare that this thesis titled, `ENABLING POST- RECORDING DEEP GEOREFERENCING OF WALKTHROUGH VIDEOS: AN IN- TERACTIVE APPROACH' and the work presented in it are my own. I confirm that: This work was done wholly or mainly while in candidature for a Master degree at this University. Where any part of this thesis has previously been submitted for a degree or any other qualification at this University or any other institution, this has been clearly stated. Where I have consulted the published work of others, this is always clearly at- tributed. Where I have quoted from the work of others, the source is always given. With the exception of such quotations, this thesis is entirely my own work. I have acknowledged all main sources of help. Where the thesis is based on work done by myself jointly with others, I have made clear exactly what was done by others and what I have contributed myself. Signed: Samuel Navas Medrano Date: 26th of February, 2016 i \I'll sleep well tonight." Henry Ford Abstract Institute for Geoinformatiks MSc in Science of Geospatial Technologies by Samuel Navas Medrano The usage of large scale databases of georeferenced video stream has an infinite number of applications in industry and research since efficient storing in geodatabases to allowing the performing of spatial queries. -

A Geocoding Best Practices Guide
A Geocoding Best Practices Guide By Daniel W. Goldberg November 2008 University of Southern California GIS Research Laboratory SPONSORING ORGANIZATIONS: Canadian Association of Provincial Cancer Agencies Canadian Partnership Against Cancer Centers for Disease Control and Prevention College of American Pathologists National Cancer Institute National Cancer Registrars Association Public Health Agency of Canada SPONSORS WITH DISTINCTION: American Cancer Society American College of Surgeons American Joint Committee on Cancer North American Association of Central Cancer Registries, Inc. A GEOCODING BEST PRACTICES GUIDE SUBMITTED TO THE NORTH AMERICAN ASSOCIATION OF CENTRAL CANCER REGISTRIES NOVEMBER 10, 2008 BY DANIEL W. GOLDBERG UNIVERSITY OF SOUTHERN CALIFORNIA GIS RESEARCH LABORATORY This page is left blank intentionally. D. W. Goldberg TABLE OF CONTENTS List of Tables .............................................................................................................. vii List of Figures .............................................................................................................. ix List of Equations .......................................................................................................... x List of Best Practices ................................................................................................... xi List of Acronyms ........................................................................................................ xiii Foreward ...................................................................................................................