CS 258 Parallel Computer Architecture Lecture 2
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Real-Time Visualization of Aerospace Simulations Using Computational Steering and Beowulf Clusters
The Pennsylvania State University The Graduate School Department of Computer Science and Engineering REAL-TIME VISUALIZATION OF AEROSPACE SIMULATIONS USING COMPUTATIONAL STEERING AND BEOWULF CLUSTERS A Thesis in Computer Science and Engineering by Anirudh Modi Submitted in Partial Fulfillment of the Requirements for the Degree of Doctor of Philosophy August 2002 We approve the thesis of Anirudh Modi. Date of Signature Paul E. Plassmann Associate Professor of Computer Science and Engineering Thesis Co-Advisor Co-Chair of Committee Lyle N. Long Professor of Aerospace Engineering Professor of Computer Science and Engineering Thesis Co-Advisor Co-Chair of Committee Rajeev Sharma Associate Professor of Computer Science and Engineering Padma Raghavan Associate Professor of Computer Science and Engineering Mark D. Maughmer Professor of Aerospace Engineering Raj Acharya Professor of Computer Science and Engineering Head of the Department of Computer Science and Engineering iii ABSTRACT In this thesis, a new, general-purpose software system for computational steering has been developed to carry out simulations on parallel computers and visualize them remotely in real-time. The steering system is extremely lightweight, portable, robust and easy to use. As a demonstration of the capabilities of this system, two applications have been developed. A parallel wake-vortex simulation code has been written and integrated with a Virtual Reality (VR) system via a separate graphics client. The coupling of computational steering of paral- lel wake-vortex simulation with VR setup provides us with near real-time visualization of the wake-vortex data in stereoscopic mode. It opens a new way for the future Air-Traffic Control systems to help reduce the capacity constraint and safety problems resulting from the wake- vortex hazard that are plaguing the airports today. -

Computer Hardware
Computer Hardware MJ Rutter mjr19@cam Michaelmas 2014 Typeset by FoilTEX c 2014 MJ Rutter Contents History 4 The CPU 10 instructions ....................................... ............................................. 17 pipelines .......................................... ........................................... 18 vectorcomputers.................................... .............................................. 36 performancemeasures . ............................................... 38 Memory 42 DRAM .................................................. .................................... 43 caches............................................. .......................................... 54 Memory Access Patterns in Practice 82 matrixmultiplication. ................................................. 82 matrixtransposition . ................................................107 Memory Management 118 virtualaddressing .................................. ...............................................119 pagingtodisk ....................................... ............................................128 memorysegments ..................................... ............................................137 Compilers & Optimisation 158 optimisation....................................... .............................................159 thepitfallsofF90 ................................... ..............................................183 I/O, Libraries, Disks & Fileservers 196 librariesandkernels . ................................................197 -

Parallel Computer Architecture
Parallel Computer Architecture Introduction to Parallel Computing CIS 410/510 Department of Computer and Information Science Lecture 2 – Parallel Architecture Outline q Parallel architecture types q Instruction-level parallelism q Vector processing q SIMD q Shared memory ❍ Memory organization: UMA, NUMA ❍ Coherency: CC-UMA, CC-NUMA q Interconnection networks q Distributed memory q Clusters q Clusters of SMPs q Heterogeneous clusters of SMPs Introduction to Parallel Computing, University of Oregon, IPCC Lecture 2 – Parallel Architecture 2 Parallel Architecture Types • Uniprocessor • Shared Memory – Scalar processor Multiprocessor (SMP) processor – Shared memory address space – Bus-based memory system memory processor … processor – Vector processor bus processor vector memory memory – Interconnection network – Single Instruction Multiple processor … processor Data (SIMD) network processor … … memory memory Introduction to Parallel Computing, University of Oregon, IPCC Lecture 2 – Parallel Architecture 3 Parallel Architecture Types (2) • Distributed Memory • Cluster of SMPs Multiprocessor – Shared memory addressing – Message passing within SMP node between nodes – Message passing between SMP memory memory nodes … M M processor processor … … P … P P P interconnec2on network network interface interconnec2on network processor processor … P … P P … P memory memory … M M – Massively Parallel Processor (MPP) – Can also be regarded as MPP if • Many, many processors processor number is large Introduction to Parallel Computing, University of Oregon, -

Programming Languages, Database Language SQL, Graphics, GOSIP
b fl ^ b 2 5 I AH1Q3 NISTIR 4951 (Supersedes NISTIR 4871) VALIDATED PRODUCTS LIST 1992 No. 4 PROGRAMMING LANGUAGES DATABASE LANGUAGE SQL GRAPHICS Judy B. Kailey GOSIP Editor POSIX COMPUTER SECURITY U.S. DEPARTMENT OF COMMERCE Technology Administration National Institute of Standards and Technology Computer Systems Laboratory Software Standards Validation Group Gaithersburg, MD 20899 100 . U56 4951 1992 NIST (Supersedes NISTIR 4871) VALIDATED PRODUCTS LIST 1992 No. 4 PROGRAMMING LANGUAGES DATABASE LANGUAGE SQL GRAPHICS Judy B. Kailey GOSIP Editor POSIX COMPUTER SECURITY U.S. DEPARTMENT OF COMMERCE Technology Administration National Institute of Standards and Technology Computer Systems Laboratory Software Standards Validation Group Gaithersburg, MD 20899 October 1992 (Supersedes July 1992 issue) U.S. DEPARTMENT OF COMMERCE Barbara Hackman Franklin, Secretary TECHNOLOGY ADMINISTRATION Robert M. White, Under Secretary for Technology NATIONAL INSTITUTE OF STANDARDS AND TECHNOLOGY John W. Lyons, Director - ;,’; '^'i -; _ ^ '’>.£. ; '':k ' ' • ; <tr-f'' "i>: •v'k' I m''M - i*i^ a,)»# ' :,• 4 ie®®;'’’,' ;SJ' v: . I 'i^’i i 'OS -.! FOREWORD The Validated Products List is a collection of registers describing implementations of Federal Information Processing Standards (FTPS) that have been validated for conformance to FTPS. The Validated Products List also contains information about the organizations, test methods and procedures that support the validation programs for the FTPS identified in this document. The Validated Products List is updated quarterly. iii ' ;r,<R^v a;-' i-'r^ . /' ^'^uffoo'*^ ''vCJIt<*bjteV sdT : Jr /' i^iL'.JO 'j,-/5l ':. ;urj ->i: • ' *?> ^r:nT^^'Ad JlSid Uawfoof^ fa«Di)itbiI»V ,, ‘ isbt^u ri il .r^^iytsrH n 'V TABLE OF CONTENTS 1. -

ECE 590: Digital Systems Design Using Hardware Description Language (VHDL) Systolic Implementation of Faddeev's Algorithm in V
Project Report ECE 590: Digital Systems Design using Hardware Description Language (VHDL) Systolic Implementation of Faddeev’s Algorithm in VHDL. Final Project Tejas Tapsale. PSU ID: 973524088. Project Report Introduction: = In this project we are implementing Nash’s systolic implementation and Chuang an He,s systolic implementation for Faddeev’s algorithm. These two implementations have their own advantages and drawbacks. Here in this project report we first see detail of Nash implementation and then we will go for Chaung and He’s implementation. The organization of this report is like this:- 1. First we take detail idea about what is systolic architecture and how it can be used for matrix multiplication and its advantages and disadvantages. 2. Then we discuss about Gaussian Elimination for matrix computation and its properties. 3. Then we will see Faddeev’s algorithm and how it is used. 4. Systolic arrays for MATRIX TRIANGULARIZATION 5. We will discuss Nash implementation in detail and its VHDL coding. 6. Advantages and disadvantage of Nash systolic implementation. 7. Chaung and He’s implementation in detail and its VHDL coding. 8. Difficulties chased in this project. 9. Conclusion. 10. VHDL code for Nash Implementation. 11. VHDL code for Chaung and He’s Implementation. 12. Simulation Results. 13. References. 14. PowerPoint Presentation Project Report 1: Systolic Architecture: = A systolic array is composed of matrix-like rows of data processing units called cells. Data processing units (DPU) are similar to central processing units (CPU)s, (except for the usual lack of a program counter, since operation is transport-triggered, i.e., by the arrival of a data object). -

On the Efficiency of Register File Versus Broadcast Interconnect For
On the Efficiency of Register File versus Broadcast Interconnect for Collective Communications in Data-Parallel Hardware Accelerators Ardavan Pedram, Andreas Gerstlauer Robert A. van de Geijn Department of Electrical and Computer Engineering Department of Computer Science The University of Texas at Austin The University of Texas at Austin fardavan,[email protected] [email protected] Abstract—Reducing power consumption and increasing effi- on broadcast communication among a 2D array of PEs. In ciency is a key concern for many applications. How to design this paper, we focus on the LAC’s data-parallel broadcast highly efficient computing elements while maintaining enough interconnect and on showing how representative collective flexibility within a domain of applications is a fundamental question. In this paper, we present how broadcast buses can communication operations can be efficiently mapped onto eliminate the use of power hungry multi-ported register files this architecture. Such collective communications are a core in the context of data-parallel hardware accelerators for linear component of many matrix or other data-intensive operations algebra operations. We demonstrate an algorithm/architecture that often demand matrix manipulations. co-design for the mapping of different collective communication We compare our design with typical SIMD cores with operations, which are crucial for achieving performance and efficiency in most linear algebra routines, such as GEMM, equivalent data parallelism and with L1 and L2 caches that SYRK and matrix transposition. We compare a broadcast bus amount to an equivalent aggregate storage space. To do so, based architecture with conventional SIMD, 2D-SIMD and flat we examine efficiency and performance of the cores for data register file for these operations in terms of area and energy movement and data manipulation in both GEneral matrix- efficiency. -

Computer Architectures
Parallel (High-Performance) Computer Architectures Tarek El-Ghazawi Department of Electrical and Computer Engineering The George Washington University Tarek El-Ghazawi, Introduction to High-Performance Computing slide 1 Introduction to Parallel Computing Systems Outline Definitions and Conceptual Classifications » Parallel Processing, MPP’s, and Related Terms » Flynn’s Classification of Computer Architectures Operational Models for Parallel Computers Interconnection Networks MPP’s Performance Tarek El-Ghazawi, Introduction to High-Performance Computing slide 2 Definitions and Conceptual Classification What is Parallel Processing? - A form of data processing which emphasizes the exploration and exploitation of inherent parallelism in the underlying problem. Other related terms » Massively Parallel Processors » Heterogeneous Processing – In the1990s, heterogeneous workstations from different processor vendors – Now, accelerators such as GPUs, FPGAs, Intel’s Xeon Phi, … » Grid computing » Cloud Computing Tarek El-Ghazawi, Introduction to High-Performance Computing slide 3 Definitions and Conceptual Classification Why Massively Parallel Processors (MPPs)? » Increase processing speed and memory allowing studies of problems with higher resolutions or bigger sizes » Provide a low cost alternative to using expensive processor and memory technologies (as in traditional vector machines) Tarek El-Ghazawi, Introduction to High-Performance Computing slide 4 Stored Program Computer The IAS machine was the first electronic computer developed, under -

Systolic Computing on Gpus for Productive Performance
Systolic Computing on GPUs for Productive Performance Hongbo Rong Xiaochen Hao Yun Liang Intel Intel, Peking University Peking University [email protected] [email protected] [email protected] Lidong Xu Hong H Jiang Pradeep Dubey Intel Intel Intel [email protected] [email protected] [email protected] Abstract an SIMT (single-instruction multiple-threads) programming We propose a language and compiler to productively build interface, and rely on an underlying compiler to transparently high-performance software systolic arrays that run on GPUs. map a wrap of threads to SIMD execution units. If data need to Based on a rigorous mathematical foundation (uniform re- be exchanged among threads in the same wrap, programmers currence equations and space-time transform), our language have to write explicit shuffle instructions [19]. has a high abstraction level and covers a wide range of ap- This paper proposes a new programming style that pro- plications. A programmer specifies a projection of a dataflow grams GPUs as building software systolic arrays. Systolic ar- compute onto a linear systolic array, while leaving the detailed rays have been extensively studied since 1978 [15], and shown implementation of the projection to a compiler; the compiler an abundance of practice-oriented applications, mainly in implements the specified projection and maps the linear sys- fields dominated by iterative procedures [32], e.g. image and tolic array to the SIMD execution units and vector registers signal processing, matrix arithmetic, non-numeric applica- of GPUs. In this way, both productivity and performance are tions, relational database [7, 8, 10, 11, 16, 17, 30], and so on. -
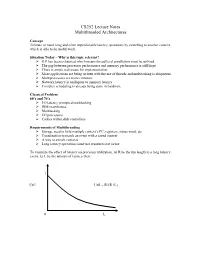
CS252 Lecture Notes Multithreaded Architectures
CS252LectureNotes MultithreadedArchitectures Concept Tolerateormasklongandoftenunpredictablelatencyoperationsbyswitchingtoanothercontext, whichisabletodousefulwork. SituationToday–Whyisthistopicrelevant? ILPhasbeenexhaustedwhichmeansthreadlevelparallelismmustbeutilized ‹ Thegapbetweenprocessorperformanceandmemoryperformanceisstilllarge ‹ Thereisamplereal-estateforimplementation ‹ Moreapplicationsarebeingwrittenwiththeuseofthreadsandmultitaskingisubiquitous ‹ Multiprocessorsaremorecommon ‹ Networklatencyisanalogoustomemorylatency ‹ Complexschedulingisalreadybeingdoneinhardware ClassicalProblem 60’sand70’s ‹ I/Olatencypromptedmultitasking ‹ IBMmainframes ‹ Multitasking ‹ I/Oprocessors ‹ Cacheswithindiskcontrollers RequirementsofMultithreading ‹ Storageneedtoholdmultiplecontext’sPC,registers,statusword,etc. ‹ Coordinationtomatchaneventwithasavedcontext ‹ Awaytoswitchcontexts ‹ Longlatencyoperationsmustuseresourcesnotinuse Tovisualizetheeffectoflatencyonprocessorutilization,letRbetherunlengthtoalonglatency event,letLbetheamountoflatencythen: 1 Util Util=R/(R+L) 0 L 80’s Problemwasrevisitedduetotheadventofgraphicsworkstations XeroxAlto,TIExplorer ‹ Concurrentprocessesareinterleavedtoallowfortheworkstationstobemoreresponsive. ‹ Theseprocessescoulddriveormonitordisplay,input,filesystem,network,user processing ‹ Processswitchwasslowsothesubsystemsweremicroprogrammedtosupportmultiple contexts ScalableMultiprocessor ‹ Dancehall–asharedinterconnectwithmemoryononesideandprocessorsontheother. ‹ Orprocessorsmayhavelocalmemory M M P/M P/M -

Dynamic Adaptation Techniques and Opportunities to Improve HPC Runtimes
Dynamic Adaptation Techniques and Opportunities to Improve HPC Runtimes Mohammad Alaul Haque Monil, Email: [email protected], University of Oregon. Abstract—Exascale, a new era of computing, is knocking at subsystem, later generations of integrated heterogeneous sys- the door. Leaving behind the days of high frequency, single- tems such as NVIDIA’s Tegra Xavier have taken heterogeneity core processors, the new paradigm of multicore/manycore pro- within the same chip to the extreme. Processing units with cessors in complex heterogeneous systems dominates today’s HPC landscape. With the advent of accelerators and special-purpose diverse instruction set architectures (ISAs) are present in nodes processors alongside general processors, the role of high perfor- in supercomputers such as Summit, where IBM Power9 CPUs mance computing (HPC) runtime systems has become crucial are connected to 6 NVIDIA V100 GPUs. Similarly in inte- to support different computing paradigms under one umbrella. grated systems such as NVIDIA Xavier, processing units with On one hand, modern HPC runtime systems have introduced diverse instruction set architectures work together to accelerate a rich set of abstractions for supporting different technologies and hiding details from the HPC application developers. On the kernels belonging to emerging application domains. Moreover, other hand, the underlying runtime layer has been equipped large-scale distributed memory systems with complex network with techniques to efficiently synchronize, communicate, and map structures and modern network interface cards adds to this work to compute resources. Modern runtime layers can also complexity. To efficiently manage these systems, efficient dynamically adapt to achieve better performance and reduce runtime systems are needed. -

Research Article a Systolic Array-Based FPGA Parallel Architecture for the BLAST Algorithm
International Scholarly Research Network ISRN Bioinformatics Volume 2012, Article ID 195658, 11 pages doi:10.5402/2012/195658 Research Article A Systolic Array-Based FPGA Parallel Architecture for the BLAST Algorithm Xinyu Guo,1 Hong Wang,2 and Vijay Devabhaktuni1 1 Electrical Engineering and Computer Science Department, The University of Toledo, MS.308, 2801 W. Bancroft Street, Toledo, OH 43607, USA 2 Department of Engineering Technology, The University of Toledo, MS.402, 2801 W. Bancroft Street, Toledo, OH 43606, USA Correspondence should be addressed to Hong Wang, [email protected] Received 23 May 2012; Accepted 25 July 2012 Academic Editors: F. Couto, B. Haubold, and J. T. L. Wang Copyright © 2012 Xinyu Guo et al. This is an open access article distributed under the Creative Commons Attribution License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited. A design of systolic array-based Field Programmable Gate Array (FPGA) parallel architecture for Basic Local Alignment Search Tool (BLAST) Algorithm is proposed. BLAST is a heuristic biological sequence alignment algorithm which has been used by bio- informatics experts. In contrast to other designs that detect at most one hit in one-clock-cycle, our design applies a Multiple Hits Detection Module which is a pipelining systolic array to search multiple hits in a single-clock-cycle. Further, we designed a Hits Combination Block which combines overlapping hits from systolic array into one hit. These implementations completed the first and second step of BLAST architecture and achieved significant speedup comparing with previously published architectures. -

R00456--FM Getting up to Speed
GETTING UP TO SPEED THE FUTURE OF SUPERCOMPUTING Susan L. Graham, Marc Snir, and Cynthia A. Patterson, Editors Committee on the Future of Supercomputing Computer Science and Telecommunications Board Division on Engineering and Physical Sciences THE NATIONAL ACADEMIES PRESS Washington, D.C. www.nap.edu THE NATIONAL ACADEMIES PRESS 500 Fifth Street, N.W. Washington, DC 20001 NOTICE: The project that is the subject of this report was approved by the Gov- erning Board of the National Research Council, whose members are drawn from the councils of the National Academy of Sciences, the National Academy of Engi- neering, and the Institute of Medicine. The members of the committee responsible for the report were chosen for their special competences and with regard for ap- propriate balance. Support for this project was provided by the Department of Energy under Spon- sor Award No. DE-AT01-03NA00106. Any opinions, findings, conclusions, or recommendations expressed in this publication are those of the authors and do not necessarily reflect the views of the organizations that provided support for the project. International Standard Book Number 0-309-09502-6 (Book) International Standard Book Number 0-309-54679-6 (PDF) Library of Congress Catalog Card Number 2004118086 Cover designed by Jennifer Bishop. Cover images (clockwise from top right, front to back) 1. Exploding star. Scientific Discovery through Advanced Computing (SciDAC) Center for Supernova Research, U.S. Department of Energy, Office of Science. 2. Hurricane Frances, September 5, 2004, taken by GOES-12 satellite, 1 km visible imagery. U.S. National Oceanographic and Atmospheric Administration. 3. Large-eddy simulation of a Rayleigh-Taylor instability run on the Lawrence Livermore National Laboratory MCR Linux cluster in July 2003.