Computer Hardware
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

VOLUME V INFORMATIQUE NON AMERICAINE Première Partie Par L' Ingénieur Général De L'armement BOUCHER Henri TABLE
VOLUME V INFORMATIQUE NON AMERICAINE Première partie par l' Ingénieur Général de l'Armement BOUCHER Henri TABLE DES MATIERES INFORMATIQUE NON AMERICAINE Première partie 731 Informatique européenne (statistiques, exemples) 122 700 Histoire de l'Informatique allemande 1 701 Petits constructeurs 5 702 Les facturières de Kienzle Data System 16 703 Les minis de gestion de Nixdorf 18 704 Siemens & Halske AG 23 705 Systèmes informatiques d'origine allemande 38 706 Histoire de l'informatique britannique 40 707 Industriels anglais de l'informatique 42 708 Travaux des Laboratoires d' Etat 60 709 Travaux universitaires 63 710 Les coeurs synthétisables d' ARM 68 711 Computer Technology 70 712 Elliott Brothers et Elliott Automation 71 713 Les machines d' English Electric Company 74 714 Les calculateurs de Ferranti 76 715 Les études de General Electric Company 83 716 La patiente construction de ICL 85 Catalogue informatique – Volume E - Ingénieur Général de l'Armement Henri Boucher Page : 1/333 717 La série 29 d' ICL 89 718 Autres produits d' ICL, et fin 94 719 Marconi Company 101 720 Plessey 103 721 Systèmes en Grande-Bretagne 105 722 Histoire de l'informatique australienne 107 723 Informatique en Autriche 109 724 Informatique belge 110 725 Informatique canadienne 111 726 Informatique chinoise 116 727 Informatique en Corée du Sud 118 728 Informatique à Cuba 119 729 Informatique danoise 119 730 Informatique espagnole 121 732 Informatique finlandaise 128 733 Histoire de l'informatique française 130 734 La période héroïque : la SEA 140 735 La Compagnie -

SIMD Extensions
SIMD Extensions PDF generated using the open source mwlib toolkit. See http://code.pediapress.com/ for more information. PDF generated at: Sat, 12 May 2012 17:14:46 UTC Contents Articles SIMD 1 MMX (instruction set) 6 3DNow! 8 Streaming SIMD Extensions 12 SSE2 16 SSE3 18 SSSE3 20 SSE4 22 SSE5 26 Advanced Vector Extensions 28 CVT16 instruction set 31 XOP instruction set 31 References Article Sources and Contributors 33 Image Sources, Licenses and Contributors 34 Article Licenses License 35 SIMD 1 SIMD Single instruction Multiple instruction Single data SISD MISD Multiple data SIMD MIMD Single instruction, multiple data (SIMD), is a class of parallel computers in Flynn's taxonomy. It describes computers with multiple processing elements that perform the same operation on multiple data simultaneously. Thus, such machines exploit data level parallelism. History The first use of SIMD instructions was in vector supercomputers of the early 1970s such as the CDC Star-100 and the Texas Instruments ASC, which could operate on a vector of data with a single instruction. Vector processing was especially popularized by Cray in the 1970s and 1980s. Vector-processing architectures are now considered separate from SIMD machines, based on the fact that vector machines processed the vectors one word at a time through pipelined processors (though still based on a single instruction), whereas modern SIMD machines process all elements of the vector simultaneously.[1] The first era of modern SIMD machines was characterized by massively parallel processing-style supercomputers such as the Thinking Machines CM-1 and CM-2. These machines had many limited-functionality processors that would work in parallel. -

Parallel Computer Architecture
Parallel Computer Architecture Introduction to Parallel Computing CIS 410/510 Department of Computer and Information Science Lecture 2 – Parallel Architecture Outline q Parallel architecture types q Instruction-level parallelism q Vector processing q SIMD q Shared memory ❍ Memory organization: UMA, NUMA ❍ Coherency: CC-UMA, CC-NUMA q Interconnection networks q Distributed memory q Clusters q Clusters of SMPs q Heterogeneous clusters of SMPs Introduction to Parallel Computing, University of Oregon, IPCC Lecture 2 – Parallel Architecture 2 Parallel Architecture Types • Uniprocessor • Shared Memory – Scalar processor Multiprocessor (SMP) processor – Shared memory address space – Bus-based memory system memory processor … processor – Vector processor bus processor vector memory memory – Interconnection network – Single Instruction Multiple processor … processor Data (SIMD) network processor … … memory memory Introduction to Parallel Computing, University of Oregon, IPCC Lecture 2 – Parallel Architecture 3 Parallel Architecture Types (2) • Distributed Memory • Cluster of SMPs Multiprocessor – Shared memory addressing – Message passing within SMP node between nodes – Message passing between SMP memory memory nodes … M M processor processor … … P … P P P interconnec2on network network interface interconnec2on network processor processor … P … P P … P memory memory … M M – Massively Parallel Processor (MPP) – Can also be regarded as MPP if • Many, many processors processor number is large Introduction to Parallel Computing, University of Oregon, -

Validated Products List, 1993 No. 2
mmmmm NJST PUBLICATIONS NISTIR 5167 (Supersedes NISTIR 5103) Validated Products List 1993 No. 2 Programming Languages Database Language SQL Graphics GOSIP POSIX Judy B. Kailey Computer Security Editor U.S. DEPARTMENT OF COMMERCE Technology Administration National Institute of Standards and Technology Computer Systems Laboratory Software Standards Validation Group Gaithersburg, MD 20899 April 1993 (Supersedes January 1993 issue) —QC 100 NIST . U56 #5167 1993 NISTIR 5167 (Supersedes NISTIR 5103) Validated Products List 1993 No. 2 Programming Languages Database Language SQL Graphics GOSIP POSIX Judy B. Kailey Computer Security Editor U.S. DEPARTMENT OF COMMERCE Technology Administration National Institute of Standards and Technology Computer Systems Laboratory Software Standards Validation Group Gaithersburg, MD 20899 April 1993 (Supersedes January 1993 issue) U.S. DEPARTMENT OF COMMERCE Ronald H. Brown, Secretary NATIONAL INSTITUTE OF STANDARDS AND TECHNOLOGY Raymond Kammer, Acting Director FOREWORD The Validated Products List is a collection of registers describing implementations of Federal Information Processing Standards (FIPS) that have been validated for conformance to FTPS. The Validated Products List also contains information about the organizations, test methods and procedures that support the validation programs for the FIPS identified in this document. The Validated Products List is updated quarterly. iii iv TABLE OF CONTENTS 1. INTRODUCTION 1 1.1 Purpose 1 1.2 Document Organization 2 1.2.1 Programming Languages 2 1.2.2 Database -

Processor Design:System-On-Chip Computing For
Processor Design Processor Design System-on-Chip Computing for ASICs and FPGAs Edited by Jari Nurmi Tampere University of Technology Finland A C.I.P. Catalogue record for this book is available from the Library of Congress. ISBN 978-1-4020-5529-4 (HB) ISBN 978-1-4020-5530-0 (e-book) Published by Springer, P.O. Box 17, 3300 AA Dordrecht, The Netherlands. www.springer.com Printed on acid-free paper All Rights Reserved © 2007 Springer No part of this work may be reproduced, stored in a retrieval system, or transmitted in any form or by any means, electronic, mechanical, photocopying, microfilming, recording or otherwise, without written permission from the Publisher, with the exception of any material supplied specifically for the purpose of being entered and executed on a computer system, for exclusive use by the purchaser of the work. To Pirjo, Lauri, Eero, and Santeri Preface When I started my computing career by programming a PDP-11 computer as a freshman in the university in early 1980s, I could not have dreamed that one day I’d be able to design a processor. At that time, the freshmen were only allowed to use PDP. Next year I was given the permission to use the famous brand-new VAX-780 computer. Also, my new roommate at the dorm had got one of the first personal computers, a Commodore-64 which we started to explore together. Again, I could not have imagined that hundreds of times the processing power will be available in an everyday embedded device just a quarter of century later. -
CS252 Lecture Notes Multithreaded Architectures
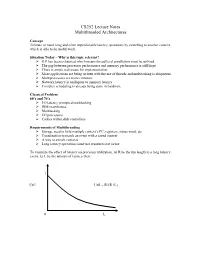
CS252LectureNotes MultithreadedArchitectures Concept Tolerateormasklongandoftenunpredictablelatencyoperationsbyswitchingtoanothercontext, whichisabletodousefulwork. SituationToday–Whyisthistopicrelevant? ILPhasbeenexhaustedwhichmeansthreadlevelparallelismmustbeutilized ‹ Thegapbetweenprocessorperformanceandmemoryperformanceisstilllarge ‹ Thereisamplereal-estateforimplementation ‹ Moreapplicationsarebeingwrittenwiththeuseofthreadsandmultitaskingisubiquitous ‹ Multiprocessorsaremorecommon ‹ Networklatencyisanalogoustomemorylatency ‹ Complexschedulingisalreadybeingdoneinhardware ClassicalProblem 60’sand70’s ‹ I/Olatencypromptedmultitasking ‹ IBMmainframes ‹ Multitasking ‹ I/Oprocessors ‹ Cacheswithindiskcontrollers RequirementsofMultithreading ‹ Storageneedtoholdmultiplecontext’sPC,registers,statusword,etc. ‹ Coordinationtomatchaneventwithasavedcontext ‹ Awaytoswitchcontexts ‹ Longlatencyoperationsmustuseresourcesnotinuse Tovisualizetheeffectoflatencyonprocessorutilization,letRbetherunlengthtoalonglatency event,letLbetheamountoflatencythen: 1 Util Util=R/(R+L) 0 L 80’s Problemwasrevisitedduetotheadventofgraphicsworkstations XeroxAlto,TIExplorer ‹ Concurrentprocessesareinterleavedtoallowfortheworkstationstobemoreresponsive. ‹ Theseprocessescoulddriveormonitordisplay,input,filesystem,network,user processing ‹ Processswitchwasslowsothesubsystemsweremicroprogrammedtosupportmultiple contexts ScalableMultiprocessor ‹ Dancehall–asharedinterconnectwithmemoryononesideandprocessorsontheother. ‹ Orprocessorsmayhavelocalmemory M M P/M P/M -

Computer Architectures an Overview
Computer Architectures An Overview PDF generated using the open source mwlib toolkit. See http://code.pediapress.com/ for more information. PDF generated at: Sat, 25 Feb 2012 22:35:32 UTC Contents Articles Microarchitecture 1 x86 7 PowerPC 23 IBM POWER 33 MIPS architecture 39 SPARC 57 ARM architecture 65 DEC Alpha 80 AlphaStation 92 AlphaServer 95 Very long instruction word 103 Instruction-level parallelism 107 Explicitly parallel instruction computing 108 References Article Sources and Contributors 111 Image Sources, Licenses and Contributors 113 Article Licenses License 114 Microarchitecture 1 Microarchitecture In computer engineering, microarchitecture (sometimes abbreviated to µarch or uarch), also called computer organization, is the way a given instruction set architecture (ISA) is implemented on a processor. A given ISA may be implemented with different microarchitectures.[1] Implementations might vary due to different goals of a given design or due to shifts in technology.[2] Computer architecture is the combination of microarchitecture and instruction set design. Relation to instruction set architecture The ISA is roughly the same as the programming model of a processor as seen by an assembly language programmer or compiler writer. The ISA includes the execution model, processor registers, address and data formats among other things. The Intel Core microarchitecture microarchitecture includes the constituent parts of the processor and how these interconnect and interoperate to implement the ISA. The microarchitecture of a machine is usually represented as (more or less detailed) diagrams that describe the interconnections of the various microarchitectural elements of the machine, which may be everything from single gates and registers, to complete arithmetic logic units (ALU)s and even larger elements. -

Dynamic Adaptation Techniques and Opportunities to Improve HPC Runtimes
Dynamic Adaptation Techniques and Opportunities to Improve HPC Runtimes Mohammad Alaul Haque Monil, Email: [email protected], University of Oregon. Abstract—Exascale, a new era of computing, is knocking at subsystem, later generations of integrated heterogeneous sys- the door. Leaving behind the days of high frequency, single- tems such as NVIDIA’s Tegra Xavier have taken heterogeneity core processors, the new paradigm of multicore/manycore pro- within the same chip to the extreme. Processing units with cessors in complex heterogeneous systems dominates today’s HPC landscape. With the advent of accelerators and special-purpose diverse instruction set architectures (ISAs) are present in nodes processors alongside general processors, the role of high perfor- in supercomputers such as Summit, where IBM Power9 CPUs mance computing (HPC) runtime systems has become crucial are connected to 6 NVIDIA V100 GPUs. Similarly in inte- to support different computing paradigms under one umbrella. grated systems such as NVIDIA Xavier, processing units with On one hand, modern HPC runtime systems have introduced diverse instruction set architectures work together to accelerate a rich set of abstractions for supporting different technologies and hiding details from the HPC application developers. On the kernels belonging to emerging application domains. Moreover, other hand, the underlying runtime layer has been equipped large-scale distributed memory systems with complex network with techniques to efficiently synchronize, communicate, and map structures and modern network interface cards adds to this work to compute resources. Modern runtime layers can also complexity. To efficiently manage these systems, efficient dynamically adapt to achieve better performance and reduce runtime systems are needed. -

Dynamicsilicon Gilder Publishing, LLC
Written by Published by Nick Tredennick DynamicSilicon Gilder Publishing, LLC Vol. 2, No. 9 The Investor's Guide to Breakthrough Micro Devices September 2002 Lessons From the PC he worldwide market for personal computers has grown to 135 million units annually. Personal com- puters represent half of the worldwide revenue for semiconductors. In July of this year, PC makers Tshipped their billionth PC. I trace the story of the personal computer (PC) from its beginning. The lessons from the PC apply to contemporary products such as switches, routers, network processors, microprocessors, and cell phones. The story doesn’t repeat exactly because semiconductor-process advances change the rules. PC beginnings Intel introduced the first commercial microprocessor in 1971. The first microprocessors were designed solely as cost-effective substitutes for numerous chips in bills of material. But it wasn’t long before micro- processors became central processing units in small computer systems. The first advertisement for a micro- processor-based computer appeared in March 1974. Soon, companies, such as Scelbi Computer Consulting, MITS, and IMSAI, offered kit computers. Apple Computer incorporated in January 1977 and introduced the Apple II computer in April. The Apple II came fully assembled, which, together with the invention of the spreadsheet, changed the personal computer from a kit hobby to a personal business machine. In 1981, IBM legitimized personal computers by introducing the IBM Personal Computer. Once endorsed by IBM, many businesses bought personal computers. Even though it came out in August, IBM sold 15,000 units that year. Apple had a four-year head start. When IBM debuted its personal computer, the Apple II dom- inated the market. -

Extracting and Mapping Industry 4.0 Technologies Using Wikipedia
Computers in Industry 100 (2018) 244–257 Contents lists available at ScienceDirect Computers in Industry journal homepage: www.elsevier.com/locate/compind Extracting and mapping industry 4.0 technologies using wikipedia T ⁎ Filippo Chiarelloa, , Leonello Trivellib, Andrea Bonaccorsia, Gualtiero Fantonic a Department of Energy, Systems, Territory and Construction Engineering, University of Pisa, Largo Lucio Lazzarino, 2, 56126 Pisa, Italy b Department of Economics and Management, University of Pisa, Via Cosimo Ridolfi, 10, 56124 Pisa, Italy c Department of Mechanical, Nuclear and Production Engineering, University of Pisa, Largo Lucio Lazzarino, 2, 56126 Pisa, Italy ARTICLE INFO ABSTRACT Keywords: The explosion of the interest in the industry 4.0 generated a hype on both academia and business: the former is Industry 4.0 attracted for the opportunities given by the emergence of such a new field, the latter is pulled by incentives and Digital industry national investment plans. The Industry 4.0 technological field is not new but it is highly heterogeneous (actually Industrial IoT it is the aggregation point of more than 30 different fields of the technology). For this reason, many stakeholders Big data feel uncomfortable since they do not master the whole set of technologies, they manifested a lack of knowledge Digital currency and problems of communication with other domains. Programming languages Computing Actually such problem is twofold, on one side a common vocabulary that helps domain experts to have a Embedded systems mutual understanding is missing Riel et al. [1], on the other side, an overall standardization effort would be IoT beneficial to integrate existing terminologies in a reference architecture for the Industry 4.0 paradigm Smit et al. -

Comparison Between CISC and RISC
ComparisonbetweenCISCandRISC YiGao,ShilangTang,ZhongliDing {ygao1,stang2,zding1}@cs.umbc.edu ABSTRACT PerformancecomparisonbetweenRISC(ReducedInstructionSetComputer)andCISC (ComplexInstructionSetComputer)isaquitepopulartopic,andmanyconclusionsaremadein previouswork.Thispapercomparesthesetwodifferentarchitecturesinacomprehensiveway, trytocapturethepurelyarchitecturaladvantagesofRISCandCISC,andthedevelopmenttrends ofthefuturearchitectures.Ourcomparisonisnotonlybasedontheoreticalpointofview,but alsobasedonexperimentalresultstosupportourconclusions.WechooseMIPSR2000(RISC) andIntel80386(CISC)asthecomparisonmicroprocessors,wecomparethemonseveralinteger andfloating-pointbenchmarkstoverifyanddrawconclusions. 1.Introduction RISCandCISCstandfortwodifferentcompetingphilosophiesindesigningmoderncomputer architecture.Thedebatebetweenthemhasbeengoingonforalongtimeandwilllikely continue.ThedifferencebetweenRISCandCISCcanlaysonmanylevels,lotsofplausible argumentsareputforwardbybothsides,suchascodedensity,transistorcounts,memory bottlenecks,compileranddecodecomplexityetc.Thispaperintendstocomparethesetwo differentideasindetail,theirdistinctcharacters,theirpossiblespecificapplicationdomains,their currentscopeandtheirfuturedevelopmenttotheCPUdesign. TheexperimentismainlybasedontheMIPSR2000andIntel80386instructionsets,MIPS R2000isatypicalproductofpureRISCwhileIntel80386isatypicalkindofpureCISCchip. Theyappearedalmostatthesametime(mid80's),also,theyareboth32-bitprocessors,sowe choosethemasourtargets.Weselectaseriesofintegerandfloat-pointingbenchmarks,use -

MMX™ Technology Architecture Overview
MMX™ Technology Architecture Overview Millind Mittal, MAP Group, Santa Clara, Intel Corp. Alex Peleg, IDC Architecture Group, Israel, Intel Corp. Uri Weiser, IDC Architecture Group, Israel, Intel Corp. Index words: MMX™ technology, SIMD, IA compatibility, parallelism, media applications Abstract The definition of MMX technology evolved from earlier work in the i860™ architecture [3]. The i860 architecture Media (video, audio, graphics, communication) was the industry’s first general purpose processor to applications present a unique opportunity for provide support for graphics rendering. The i860 performance boost via use of Single Instruction Multiple processor provided instructions that operated on multiple Data (SIMD) techniques. While several of the compute- adjacent data operands in parallel, for example, four intensive parts of media applications benefit from SIMD adjacent pixels of an image. techniques, a significant portion of the code still is best suited for general purpose instruction set architectures. After the introduction of the i860 processor, Intel MMX™ technology extends the Intel Architecture (IA), explored extending the i860 architecture in order to the industry’s leading general purpose processor deliver high performance for other media applications, for architecture, to provide the benefits of SIMD for media example, image processing, texture mapping, and audio applications. and video decompression. Several of these algorithms naturally lent themselves to SIMD processing. This effort MMX technology adopts the SIMD approach in a way laid the foundation for similar support for Intel’s that makes it coexist synergistically and compatibly with mainstream general purpose architecture, IA. the IA. This makes the technology suitable for providing a boost for a large number of media applications on the The MMX technology extension was the first major leading computer platform.