Flowchart for Instruction Cycle
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Fill Your Boots: Enhanced Embedded Bootloader Exploits Via Fault Injection and Binary Analysis
IACR Transactions on Cryptographic Hardware and Embedded Systems ISSN 2569-2925, Vol. 2021, No. 1, pp. 56–81. DOI:10.46586/tches.v2021.i1.56-81 Fill your Boots: Enhanced Embedded Bootloader Exploits via Fault Injection and Binary Analysis Jan Van den Herrewegen1, David Oswald1, Flavio D. Garcia1 and Qais Temeiza2 1 School of Computer Science, University of Birmingham, UK, {jxv572,d.f.oswald,f.garcia}@cs.bham.ac.uk 2 Independent Researcher, [email protected] Abstract. The bootloader of an embedded microcontroller is responsible for guarding the device’s internal (flash) memory, enforcing read/write protection mechanisms. Fault injection techniques such as voltage or clock glitching have been proven successful in bypassing such protection for specific microcontrollers, but this often requires expensive equipment and/or exhaustive search of the fault parameters. When multiple glitches are required (e.g., when countermeasures are in place) this search becomes of exponential complexity and thus infeasible. Another challenge which makes embedded bootloaders notoriously hard to analyse is their lack of debugging capabilities. This paper proposes a grey-box approach that leverages binary analysis and advanced software exploitation techniques combined with voltage glitching to develop a powerful attack methodology against embedded bootloaders. We showcase our techniques with three real-world microcontrollers as case studies: 1) we combine static and on-chip dynamic analysis to enable a Return-Oriented Programming exploit on the bootloader of the NXP LPC microcontrollers; 2) we leverage on-chip dynamic analysis on the bootloader of the popular STM8 microcontrollers to constrain the glitch parameter search, achieving the first fully-documented multi-glitch attack on a real-world target; 3) we apply symbolic execution to precisely aim voltage glitches at target instructions based on the execution path in the bootloader of the Renesas 78K0 automotive microcontroller. -
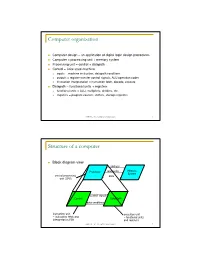
Computer Organization
Computer organization Computer design – an application of digital logic design procedures Computer = processing unit + memory system Processing unit = control + datapath Control = finite state machine inputs = machine instruction, datapath conditions outputs = register transfer control signals, ALU operation codes instruction interpretation = instruction fetch, decode, execute Datapath = functional units + registers functional units = ALU, multipliers, dividers, etc. registers = program counter, shifters, storage registers CSE370 - XI - Computer Organization 1 Structure of a computer Block diagram view address Processor read/write Memory System central processing data unit (CPU) control signals Control Data Path data conditions instruction unit execution unit œ instruction fetch and œ functional units interpretation FSM and registers CSE370 - XI - Computer Organization 2 Registers Selectively loaded – EN or LD input Output enable – OE input Multiple registers – group 4 or 8 in parallel LD OE D7 Q7 OE asserted causes FF state to be D6 Q6 connected to output pins; otherwise they D5 Q5 are left unconnected (high impedance) D4 Q4 D3 Q3 D2 Q2 LD asserted during a lo-to-hi clock D1 Q1 transition loads new data into FFs D0 CLK Q0 CSE370 - XI - Computer Organization 3 Register transfer Point-to-point connection MUX MUX MUX MUX dedicated wires muxes on inputs of each register rs rt rd R4 Common input from multiplexer load enables rs rt rd R4 for each register control signals MUX for multiplexer Common bus with output enables output enables and load rs rt rd R4 enables for each register BUS CSE370 - XI - Computer Organization 4 Register files Collections of registers in one package two-dimensional array of FFs address used as index to a particular word can have separate read and write addresses so can do both at same time 4 by 4 register file 16 D-FFs organized as four words of four bits each write-enable (load) 3E RB read-enable (output enable) RA WE (- WB (. -

Computer Organization and Architecture Designing for Performance Ninth Edition
COMPUTER ORGANIZATION AND ARCHITECTURE DESIGNING FOR PERFORMANCE NINTH EDITION William Stallings Boston Columbus Indianapolis New York San Francisco Upper Saddle River Amsterdam Cape Town Dubai London Madrid Milan Munich Paris Montréal Toronto Delhi Mexico City São Paulo Sydney Hong Kong Seoul Singapore Taipei Tokyo Editorial Director: Marcia Horton Designer: Bruce Kenselaar Executive Editor: Tracy Dunkelberger Manager, Visual Research: Karen Sanatar Associate Editor: Carole Snyder Manager, Rights and Permissions: Mike Joyce Director of Marketing: Patrice Jones Text Permission Coordinator: Jen Roach Marketing Manager: Yez Alayan Cover Art: Charles Bowman/Robert Harding Marketing Coordinator: Kathryn Ferranti Lead Media Project Manager: Daniel Sandin Marketing Assistant: Emma Snider Full-Service Project Management: Shiny Rajesh/ Director of Production: Vince O’Brien Integra Software Services Pvt. Ltd. Managing Editor: Jeff Holcomb Composition: Integra Software Services Pvt. Ltd. Production Project Manager: Kayla Smith-Tarbox Printer/Binder: Edward Brothers Production Editor: Pat Brown Cover Printer: Lehigh-Phoenix Color/Hagerstown Manufacturing Buyer: Pat Brown Text Font: Times Ten-Roman Creative Director: Jayne Conte Credits: Figure 2.14: reprinted with permission from The Computer Language Company, Inc. Figure 17.10: Buyya, Rajkumar, High-Performance Cluster Computing: Architectures and Systems, Vol I, 1st edition, ©1999. Reprinted and Electronically reproduced by permission of Pearson Education, Inc. Upper Saddle River, New Jersey, Figure 17.11: Reprinted with permission from Ethernet Alliance. Credits and acknowledgments borrowed from other sources and reproduced, with permission, in this textbook appear on the appropriate page within text. Copyright © 2013, 2010, 2006 by Pearson Education, Inc., publishing as Prentice Hall. All rights reserved. Manufactured in the United States of America. -

ARM Instruction Set
4 ARM Instruction Set This chapter describes the ARM instruction set. 4.1 Instruction Set Summary 4-2 4.2 The Condition Field 4-5 4.3 Branch and Exchange (BX) 4-6 4.4 Branch and Branch with Link (B, BL) 4-8 4.5 Data Processing 4-10 4.6 PSR Transfer (MRS, MSR) 4-17 4.7 Multiply and Multiply-Accumulate (MUL, MLA) 4-22 4.8 Multiply Long and Multiply-Accumulate Long (MULL,MLAL) 4-24 4.9 Single Data Transfer (LDR, STR) 4-26 4.10 Halfword and Signed Data Transfer 4-32 4.11 Block Data Transfer (LDM, STM) 4-37 4.12 Single Data Swap (SWP) 4-43 4.13 Software Interrupt (SWI) 4-45 4.14 Coprocessor Data Operations (CDP) 4-47 4.15 Coprocessor Data Transfers (LDC, STC) 4-49 4.16 Coprocessor Register Transfers (MRC, MCR) 4-53 4.17 Undefined Instruction 4-55 4.18 Instruction Set Examples 4-56 ARM7TDMI-S Data Sheet 4-1 ARM DDI 0084D Final - Open Access ARM Instruction Set 4.1 Instruction Set Summary 4.1.1 Format summary The ARM instruction set formats are shown below. 3 3 2 2 2 2 2 2 2 2 2 2 1 1 1 1 1 1 1 1 1 1 9876543210 1 0 9 8 7 6 5 4 3 2 1 0 9 8 7 6 5 4 3 2 1 0 Cond 0 0 I Opcode S Rn Rd Operand 2 Data Processing / PSR Transfer Cond 0 0 0 0 0 0 A S Rd Rn Rs 1 0 0 1 Rm Multiply Cond 0 0 0 0 1 U A S RdHi RdLo Rn 1 0 0 1 Rm Multiply Long Cond 0 0 0 1 0 B 0 0 Rn Rd 0 0 0 0 1 0 0 1 Rm Single Data Swap Cond 0 0 0 1 0 0 1 0 1 1 1 1 1 1 1 1 1 1 1 1 0 0 0 1 Rn Branch and Exchange Cond 0 0 0 P U 0 W L Rn Rd 0 0 0 0 1 S H 1 Rm Halfword Data Transfer: register offset Cond 0 0 0 P U 1 W L Rn Rd Offset 1 S H 1 Offset Halfword Data Transfer: immediate offset Cond 0 -

Review of Computer Architecture
Basic Computer Architecture CSCE 496/896: Embedded Systems Witawas Srisa-an Review of Computer Architecture Credit: Most of the slides are made by Prof. Wayne Wolf who is the author of the textbook. I made some modifications to the note for clarity. Assume some background information from CSCE 430 or equivalent von Neumann architecture Memory holds data and instructions. Central processing unit (CPU) fetches instructions from memory. Separate CPU and memory distinguishes programmable computer. CPU registers help out: program counter (PC), instruction register (IR), general- purpose registers, etc. von Neumann Architecture Memory Unit Input CPU Output Unit Control + ALU Unit CPU + memory address 200PC memory data CPU 200 ADD r5,r1,r3 ADD IRr5,r1,r3 Recalling Pipelining Recalling Pipelining What is a potential Problem with von Neumann Architecture? Harvard architecture address data memory data PC CPU address program memory data von Neumann vs. Harvard Harvard can’t use self-modifying code. Harvard allows two simultaneous memory fetches. Most DSPs (e.g Blackfin from ADI) use Harvard architecture for streaming data: greater memory bandwidth. different memory bit depths between instruction and data. more predictable bandwidth. Today’s Processors Harvard or von Neumann? RISC vs. CISC Complex instruction set computer (CISC): many addressing modes; many operations. Reduced instruction set computer (RISC): load/store; pipelinable instructions. Instruction set characteristics Fixed vs. variable length. Addressing modes. Number of operands. Types of operands. Tensilica Xtensa RISC based variable length But not CISC Programming model Programming model: registers visible to the programmer. Some registers are not visible (IR). Multiple implementations Successful architectures have several implementations: varying clock speeds; different bus widths; different cache sizes, associativities, configurations; local memory, etc. -

V850ES/SA2, V850ES/SA3 32-Bit Single-Chip Microcontrollers
To our customers, Old Company Name in Catalogs and Other Documents On April 1st, 2010, NEC Electronics Corporation merged with Renesas Technology Corporation, and Renesas Electronics Corporation took over all the business of both companies. Therefore, although the old company name remains in this document, it is a valid Renesas Electronics document. We appreciate your understanding. Renesas Electronics website: http://www.renesas.com April 1st, 2010 Renesas Electronics Corporation Issued by: Renesas Electronics Corporation (http://www.renesas.com) Send any inquiries to http://www.renesas.com/inquiry. Notice 1. All information included in this document is current as of the date this document is issued. Such information, however, is subject to change without any prior notice. Before purchasing or using any Renesas Electronics products listed herein, please confirm the latest product information with a Renesas Electronics sales office. Also, please pay regular and careful attention to additional and different information to be disclosed by Renesas Electronics such as that disclosed through our website. 2. Renesas Electronics does not assume any liability for infringement of patents, copyrights, or other intellectual property rights of third parties by or arising from the use of Renesas Electronics products or technical information described in this document. No license, express, implied or otherwise, is granted hereby under any patents, copyrights or other intellectual property rights of Renesas Electronics or others. 3. You should not alter, modify, copy, or otherwise misappropriate any Renesas Electronics product, whether in whole or in part. 4. Descriptions of circuits, software and other related information in this document are provided only to illustrate the operation of semiconductor products and application examples. -

Testing and Validation of a Prototype Gpgpu Design for Fpgas Murtaza Merchant University of Massachusetts Amherst
University of Massachusetts Amherst ScholarWorks@UMass Amherst Masters Theses 1911 - February 2014 2013 Testing and Validation of a Prototype Gpgpu Design for FPGAs Murtaza Merchant University of Massachusetts Amherst Follow this and additional works at: https://scholarworks.umass.edu/theses Part of the VLSI and Circuits, Embedded and Hardware Systems Commons Merchant, Murtaza, "Testing and Validation of a Prototype Gpgpu Design for FPGAs" (2013). Masters Theses 1911 - February 2014. 1012. Retrieved from https://scholarworks.umass.edu/theses/1012 This thesis is brought to you for free and open access by ScholarWorks@UMass Amherst. It has been accepted for inclusion in Masters Theses 1911 - February 2014 by an authorized administrator of ScholarWorks@UMass Amherst. For more information, please contact [email protected]. TESTING AND VALIDATION OF A PROTOTYPE GPGPU DESIGN FOR FPGAs A Thesis Presented by MURTAZA S. MERCHANT Submitted to the Graduate School of the University of Massachusetts Amherst in partial fulfillment of the requirements for the degree of MASTER OF SCIENCE IN ELECTRICAL AND COMPUTER ENGINEERING February 2013 Department of Electrical and Computer Engineering © Copyright by Murtaza S. Merchant 2013 All Rights Reserved TESTING AND VALIDATION OF A PROTOTYPE GPGPU DESIGN FOR FPGAs A Thesis Presented by MURTAZA S. MERCHANT Approved as to style and content by: _________________________________ Russell G. Tessier, Chair _________________________________ Wayne P. Burleson, Member _________________________________ Mario Parente, Member ______________________________ C. V. Hollot, Department Head Electrical and Computer Engineering ACKNOWLEDGEMENTS To begin with, I would like to sincerely thank my advisor, Prof. Russell Tessier for all his support, faith in my abilities and encouragement throughout my tenure as a graduate student. -

The Microarchitecture of the Pentium 4 Processor
The Microarchitecture of the Pentium 4 Processor Glenn Hinton, Desktop Platforms Group, Intel Corp. Dave Sager, Desktop Platforms Group, Intel Corp. Mike Upton, Desktop Platforms Group, Intel Corp. Darrell Boggs, Desktop Platforms Group, Intel Corp. Doug Carmean, Desktop Platforms Group, Intel Corp. Alan Kyker, Desktop Platforms Group, Intel Corp. Patrice Roussel, Desktop Platforms Group, Intel Corp. Index words: Pentium® 4 processor, NetBurst™ microarchitecture, Trace Cache, double-pumped ALU, deep pipelining provides an in-depth examination of the features and ABSTRACT functions of the Intel NetBurst microarchitecture. This paper describes the Intel® NetBurst™ ® The Pentium 4 processor is designed to deliver microarchitecture of Intel’s new flagship Pentium 4 performance across applications where end users can truly processor. This microarchitecture is the basis of a new appreciate and experience its performance. For example, family of processors from Intel starting with the Pentium it allows a much better user experience in areas such as 4 processor. The Pentium 4 processor provides a Internet audio and streaming video, image processing, substantial performance gain for many key application video content creation, speech recognition, 3D areas where the end user can truly appreciate the applications and games, multi-media, and multi-tasking difference. user environments. The Pentium 4 processor enables real- In this paper we describe the main features and functions time MPEG2 video encoding and near real-time MPEG4 of the NetBurst microarchitecture. We present the front- encoding, allowing efficient video editing and video end of the machine, including its new form of instruction conferencing. It delivers world-class performance on 3D cache called the Execution Trace Cache. -

3.2 the CORDIC Algorithm
UC San Diego UC San Diego Electronic Theses and Dissertations Title Improved VLSI architecture for attitude determination computations Permalink https://escholarship.org/uc/item/5jf926fv Author Arrigo, Jeanette Fay Freauf Publication Date 2006 Peer reviewed|Thesis/dissertation eScholarship.org Powered by the California Digital Library University of California 1 UNIVERSITY OF CALIFORNIA, SAN DIEGO Improved VLSI Architecture for Attitude Determination Computations A dissertation submitted in partial satisfaction of the requirements for the degree Doctor of Philosophy in Electrical and Computer Engineering (Electronic Circuits and Systems) by Jeanette Fay Freauf Arrigo Committee in charge: Professor Paul M. Chau, Chair Professor C.K. Cheng Professor Sujit Dey Professor Lawrence Larson Professor Alan Schneider 2006 2 Copyright Jeanette Fay Freauf Arrigo, 2006 All rights reserved. iv DEDICATION This thesis is dedicated to my husband Dale Arrigo for his encouragement, support and model of perseverance, and to my father Eugene Freauf for his patience during my pursuit. In memory of my mother Fay Freauf and grandmother Fay Linton Thoreson, incredible mentors and great advocates of the quest for knowledge. iv v TABLE OF CONTENTS Signature Page...............................................................................................................iii Dedication … ................................................................................................................iv Table of Contents ...........................................................................................................v -

Implementation, Verification and Validation of an Openrisc-1200
(IJACSA) International Journal of Advanced Computer Science and Applications, Vol. 10, No. 1, 2019 Implementation, Verification and Validation of an OpenRISC-1200 Soft-core Processor on FPGA Abdul Rafay Khatri Department of Electronic Engineering, QUEST, NawabShah, Pakistan Abstract—An embedded system is a dedicated computer system in which hardware and software are combined to per- form some specific tasks. Recent advancements in the Field Programmable Gate Array (FPGA) technology make it possible to implement the complete embedded system on a single FPGA chip. The fundamental component of an embedded system is a microprocessor. Soft-core processors are written in hardware description languages and functionally equivalent to an ordinary microprocessor. These soft-core processors are synthesized and implemented on the FPGA devices. In this paper, the OpenRISC 1200 processor is used, which is a 32-bit soft-core processor and Fig. 1. General block diagram of embedded systems. written in the Verilog HDL. Xilinx ISE tools perform synthesis, design implementation and configure/program the FPGA. For verification and debugging purpose, a software toolchain from (RISC) processor. This processor consists of all necessary GNU is configured and installed. The software is written in C components which are available in any other microproces- and Assembly languages. The communication between the host computer and FPGA board is carried out through the serial RS- sor. These components are connected through a bus called 232 port. Wishbone bus. In this work, the OR1200 processor is used to implement the system on a chip technology on a Virtex-5 Keywords—FPGA Design; HDLs; Hw-Sw Co-design; Open- FPGA board from Xilinx. -

Consider an Instruction Cycle Consisting of Fetch, Operators Fetch (Immediate/Direct/Indirect), Execute and Interrupt Cycles
Module-2, Unit-3 Instruction Execution Question 1: Consider an instruction cycle consisting of fetch, operators fetch (immediate/direct/indirect), execute and interrupt cycles. Explain the purpose of these four cycles. Solution 1: The life of an instruction passes through four phases—(i) Fetch, (ii) Decode and operators fetch, (iii) execute and (iv) interrupt. The purposes of these phases are as follows 1. Fetch We know that in the stored program concept, all instructions are also present in the memory along with data. So the first phase is the “fetch”, which begins with retrieving the address stored in the Program Counter (PC). The address stored in the PC refers to the memory location holding the instruction to be executed next. Following that, the address present in the PC is given to the address bus and the memory is set to read mode. The contents of the corresponding memory location (i.e., the instruction) are transferred to a special register called the Instruction Register (IR) via the data bus. IR holds the instruction to be executed. The PC is incremented to point to the next address from which the next instruction is to be fetched So basically the fetch phase consists of four steps: a) MAR <= PC (Address of next instruction from Program counter is placed into the MAR) b) MBR<=(MEMORY) (the contents of Data bus is copied into the MBR) c) PC<=PC+1 (PC gets incremented by instruction length) d) IR<=MBR (Data i.e., instruction is transferred from MBR to IR and MBR then gets freed for future data fetches) 2. -

Python Console Target Device 78K0 Microcontroller RL78 Family 78K0R Microcontroller V850 Family RX Family RH850 Family
User’s Manual CS+ V4.01.00 Integrated Development Environment User’s Manual: Python Console Target Device 78K0 Microcontroller RL78 Family 78K0R Microcontroller V850 Family RX Family RH850 Family All information contained in these materials, including products and product specifications, represents information on the product at the time of publication and is subject to change by Renesas Electronics Corp. without notice. Please review the latest information published by Renesas Electronics Corp. through various means, including the Renesas Electronics Corp. website (http://www.renesas.com). www.renesas.com Rev.1.00 2016.09 Notice 1. Descriptions of circuits, software and other related information in this document are provided only to illustrate the operation of semiconductor products and application examples. You are fully responsible for the incorporation of these circuits, software, and information in the design of your equipment. Renesas Electronics assumes no responsibility for any losses incurred by you or third parties arising from the use of these circuits, software, or information. 2. Renesas Electronics has used reasonable care in preparing the information included in this document, but Renesas Electronics does not warrant that such information is error free. Renesas Electronics assumes no liability whatsoever for any damages incurred by you resulting from errors in or omissions from the information included herein. 3. Renesas Electronics does not assume any liability for infringement of patents, copyrights, or other intellectual property rights of third parties by or arising from the use of Renesas Electronics products or technical information described in this document. No license, express, implied or otherwise, is granted hereby under any patents, copyrights or other intellectual property rights of Renesas Electronics or others.