882 ISI November 1983 DOMAIN NAMES
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

ICANN, Ipv6 and the Root
ICANN, IPv6 and the Root John L. Crain Chief Technical Officer Beijing, China April 12, 2007 1 12 APRIL 2007 In the beginning . 2 12 APRIL 2007 Internet’s unique identifiers were coordinated through the Internet Address Naming Authority JonJon PostelPostel 19431943––19981998 3 12 APRIL 2007 Need for change circa 1996–97 • Globalisation of Internet • Commercialisation of Internet • Lack of competition in domain name space • Trademark–domain name conflicts • Need for a new model of governance 4 12 APRIL 2007 ICANN mission statement • To coordinate, overall, the global Internet's system of unique identifiers, and to ensure stable and secure operation of the Internet's unique identifier systems. In particular, ICANN coordinates: 1. Allocation and assignment of the three sets of unique identifiers for the Internet: • Domain names (forming a system called the DNS) • Internet protocol (IP) addresses and autonomous system (AS) numbers • Protocol port and parameter numbers 2. Operation and evolution of the DNS root name server system 3. Policy development reasonably and appropriately related to these technical functions 5 12 APRIL 2007 Principles of operation 1. Contribute to stability and security of the unique identifiers system and root management 2. Promote competition and choice for registrants and other users 3. Forum for multi-stakeholder bottom-up development of related policy 4. Ensuring on a global basis an opportunity for participation by all interested parties 6 12 APRIL 2007 The Secretariat (People doing the day to day work) 58 Staff from 26 Countries 7 12 APRIL 2007 • The secretariat’s work is administration and aiding policy processes. • We do not set policy, that is the job of the community. -

Identifier System Attack Mitigation Methodology DATE: 13 February 2017 Identifier System Attack Mitigation Methodology
Identifier System Attack Mitigation Methodology DATE: 13 February 2017 Identifier System Attack Mitigation Methodology Introduction This document is part of ICANN’s effort to contribute to enhancing the Stability, Security, and Resiliency (SSR) of the Internet’s system of unique identifiers (“Internet Identifiers”) by working with the Community to identify and increase awareness of related attacks and to promote broader adoption of attack mitigation practices. This effort also addresses Recommendation #12 of the Security, Stability & Resiliency (SSR) Review Team (SSR-RT) by creating an Identifier System Attack Mitigation Methodology. Specifically, this document identifies and prioritizes types of attacks against the Identifier System, providing a stepping-off point for ICANN to coordinate with the Community to develop a series of short technical documents (“Tech Notes”) on actual high-impact attacks and emerging high-risk vulnerabilities. This document will be periodically updated to reflect evolution of both the Identifier System and the cybercrime landscape, supporting on-going efforts within both ICANN and the Community to mitigate attacks that pose the greatest risk to Identifier System SSR. Authors: Lisa Phifer and David Piscitello Page 1 Identifier System Attack Mitigation Methodology DATE: 13 February 2017 Attack Mitigation Methodology ICANN is proposing a new Identifier System Attack Mitigation Methodology to: • Identify, prioritize, and periodically refresh a list of top Identifier System attacks; • Develop guidance on actual high-impact attacks and emerging high-risk vulnerabilities; • Describe corresponding attack mitigation practices that are commonly considered useful; and • Encourage broader adoption of those practices via contracts, agreements, incentives, etc. This document represents the first component of this methodology. -

CS4700/CS5700 Fundamentals of Computer Networks
CS4700/CS5700 Fundamentals of Computer Networks Lecture 17: Domain Name System Slides used with permissions from Edward W. Knightly, T. S. Eugene Ng, Ion Stoica, Hui Zhang Alan Mislove amislove at ccs.neu.edu Northeastern1 University Human Involvement • Just like your friend needs to tell you his phone number for you to call him • Somehow, an application needs to know the IP address of the communication peer • There is no magic, some out-of-band mechanism is needed – Word of mouth – Read it in the advertisement in the paper – Etc. • But IP addresses are bad for humans to remember and tell each other • So need names that makes some sense to humans Alan Mislove amislove at ccs.neu.edu Northeastern2 University Internet Names & Addresses • Names: e.g. www.rice.edu – human-usable labels for machines – conforms to “organizational” structure • Addresses: e.g. 128.42.247.150 – router-usable labels for machines – conforms to “network” structure • How do you map from one to another? – Domain Name System (DNS) Alan Mislove amislove at ccs.neu.edu Northeastern3 University DNS: History • Initially all host-addess mappings were in a file called hosts.txt (in /etc/hosts) – Changes were submitted to SRI by email – New versions of hosts.txt ftp’d periodically from SRI – An administrator could pick names at their discretion – Any name is allowed: eugenesdesktopatrice • As the Internet grew this system broke down because: – SRI couldn’t handled the load – Hard to enforce uniqueness of names – Many hosts had inaccurate copies of hosts.txt • Domain Name System (DNS) was born Alan Mislove amislove at ccs.neu.edu Northeastern4 University Basic DNS Features • Hierarchical namespace – as opposed to original flat namespace • Distributed storage architecture – as opposed to centralized storage (plus replication) • Client--server interaction on UDP Port 53 – but can use TCP if desired Alan Mislove amislove at ccs.neu.edu Northeastern5 University Naming Hierarchy root edu com gov mil org net uk fr etc. -

DNS) Deployment Guide
Archived NIST Technical Series Publication The attached publication has been archived (withdrawn), and is provided solely for historical purposes. It may have been superseded by another publication (indicated below). Archived Publication Series/Number: NIST Special Publication 800-81 Revision 1 Title: Secure Domain Name System (DNS) Deployment Guide Publication Date(s): April 2010 Withdrawal Date: September 2013 Withdrawal Note: SP 800-81 Revision 1 is superseded in its entirety by the publication of SP 800-81-2 (September 2013). Superseding Publication(s) The attached publication has been superseded by the following publication(s): Series/Number: NIST Special Publication 800-81-2 Title: Secure Domain Name System (DNS) Deployment Guide Author(s): Ramaswamy Chandramouli, Scott Rose Publication Date(s): September 2013 URL/DOI: http://dx.doi.org/10.6028/NIST.SP.800-81-2 Additional Information (if applicable) Contact: Computer Security Division (Information Technology Lab) Latest revision of the SP 800-81-2 (as of August 7, 2015) attached publication: Related information: http://csrc.nist.gov/ Withdrawal N/A announcement (link): Date updated: ƵŐƵƐƚϳ, 2015 Special Publication 800-81r1 Sponsored by the Department of Homeland Security Secure Domain Name System (DNS) Deployment Guide Recommendations of the National Institute of Standards and Technology Ramaswamy Chandramouli Scott Rose i NIST Special Publication 800-81r1 Secure Domain Name System (DNS) Deployment Guide Sponsored by the Department of Homeland Security Recommendations of the National Institute of Standards and Technology Ramaswamy Chandramouli Scott Rose C O M P U T E R S E C U R I T Y Computer Security Division/Advanced Network Technologies Division Information Technology Laboratory National Institute of Standards and Technology Gaithersburg, MD 20899 April 2010 U.S. -

DNS: Domain Name System a Scalable Naming System for the Internet
Introduction Queries and Caching Protocol History and Growth DNS: Domain Name System A Scalable Naming System for the Internet Daniel Zappala Brigham Young University Computer Science Department 1/26 Introduction Introduction Queries and Caching Protocol History and Growth Domain Name System • people like to use names for computers (www.byu.edu), but computers need to use numbers (128.187.22.132) • the Domain Name System (DNS) is a distributed database providing this service • a program send a query a local name server • the local name server contacts other servers as needed • many DNS services • host name to IP address translation • host aliasing (canonical name versus alias names) • lookup mail server for a host • load distribution - can provide a set of IP addresses for one canonical name Demonstration: dig 3/26 Introduction Queries and Caching Protocol History and Growth Names • domain name: top-level domain (TLD) + one or more subdomains • example: cs.byu.edu • host name: a domain name with one or more IP addresses associated with it • TLDs • ccTLD: country codes (.us, .uk, .tv) • gTLD: generic (.com, .edu, .org, .net, .gov, .mil) { see full list at Wikipedia • iTLD: infrastructure (.arpa) • may be 127 levels deep, 63 characters per label, 255 characters per name 4/26 Introduction Queries and Caching Protocol History and Growth DNS Hierarchy • root, top-level domain (TLD), and local name servers • each level represents a zone • what zone is BYU in charge of? 5/26 Introduction Queries and Caching Protocol History and Growth Root Name -

Analyzing and Mitigating Privacy with the DNS Root Service
Analyzing and Mitigating Privacy with the DNS Root Service Wes Hardaker USC/Information Sciences Institute [email protected] Keywords privacy, dns, root, analysis, leakage ABSTRACT Processing of all DNS requests start at the root of the DNS tree and make use of either cached data from previous re- quests, or by traversing the DNS tree for the missing in- formation. When QNAME minimization is not in use, queries forwarded to the parental nodes in the DNS tree may leak private DNS query data. In this paper we examine 31 days during the month of January 2017 of queries sent from two recursive resolvers placed in two residential networks to the DNS root server operated by USC/ISI’s, analyzing Figure 1: Domain Name System Resolution Process the leaked QNAMEs for an impact on the network’s privacy. We then compare a few DNS privacy preserving techniques against the privacy analysis against these networks. Finally, client query. The architecture of this query process is we introduce a new solution called\LocalRoot" that enables depicted in Figure 1. The leakage of DNS requests to users to entirely mitigate privacy concerns when interacting the Root Server System is the focus point of this paper. with the DNS root server system, while other solutions fail Most DNS recursive resolvers today send the entire to completely protect users from all privacy analysis meth- requested DNS name (e.g. www.example.com) unen- ods. crypted to all the servers it needs to correspond with, as it is unknown to them where in the name the dif- 1. -

Wow, That's a Lot of Packets
Wow, That’s a Lot of Packets Duane Wessels, Marina Fomenkov Abstract—Organizations operating Root DNS servers re- an authoritative answer. If the application does not know port loads exceeding 100 million queries per day. Given the where to send a query it asks the servers in the parent design goals of the DNS, and what we know about today’s In- zone. In the example above, not knowing anything about ternet, this number is about two orders of magnitude more ucsd.edu, the application should send a query to the au- than we would expect. thoritative server for the edu zone. If the application does With the assistance of one root server operator, we took a edu 24-hour trace of queries arriving at one of the thirteen root not know about the zone, it queries the “root zone.” servers. In this paper we analyze these data and use a simple This process is called recursive iteration. model of the DNS to classify each query into one of nine cat- The DNS root zone is served by 13 name servers (not to egories. We find that, by far, most of the queries are repeats be confused with the 13 generic top-level domain servers) and that only a small percentage are legitimate. distributed across the globe. Thirteen is the maximum We also characterize a few of the “root server abusers,” number of root servers possible in the current DNS archi- that is, clients sending a particularly large number of tecture because that is the most that can fit inside a 512- queries to the root server. -
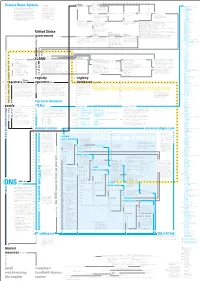
Domain Name System Concept
8 originally chartered standards charters 0 Concept Map organizations include ISoc members form 243 active ccTLDs Domain Name System rely on .ac Ascension Island (licensed) 28 Internet Society (ISoc) is a professional .ad Andorra A concept map is a web of terms. Verbs membership society with more than 150 This diagram is a model of the Domain .ae United Arab Emirates connect nouns to form propositions. organizations and 11,000 individual mem- .af Afghanistan 27 Name System (DNS), a system vital to the Groups of propositions form larger struc- bers from over 182 countries. tures. Examples and details accompany .ag Antigua and Barbuda smooth operation of the Internet. The goal most terms. More important terms re- .ai Anguilla of the diagram is to explain what DNS ceive visual emphasis; less important 11 .al Albania terms, details, and examples are in gray. IETF sponsors working groups are managed by IESG decisions can be appealed to IAB provides advice to IANA functions were moved to .am Armenia is, how it works, and how it’s governed. Terms related to names and addresses write approves .an Netherlands Antilles The diagram knits together many facts (the heart of DNS) are in blue. Terms Internet Engineering Task Force (IETF) Internet Engineering Steering Internet Architecture Board (IAB) Internet Assigned Numbers .ao Angola followed by a number link to terms pre- is a voluntary, non-commercial organization Group (IESG) Authority (IANA) originally handled .aq Antarctica about DNS in hopes of presenting a com- ceded by the same number. comprised of individuals concerned with the many of the functions that are now 626,000 .ar Argentina prehensive picture of the system and the evolution of the architecture and operation ICANN’s responsibility. -

SAC 045 – Invalid Top Level Domain Queries at the Root Level
Invalid Top Level Domain Queries at the Root Level of the Domain Name System SAC 045 Invalid Top Level Domain Queries at the Root Level of the Domain Name System A Report from the ICANN Security and Stability Advisory Committee (SSAC) 15 November 2010 SAC045 1 This document contains corrections to footnote 2 on page 6 and Section 8.1 Acknowledgements on page 10 Invalid Top Level Domain Queries at the Root Level of the Domain Name System Preface This is a report by the Security and Stability Advisory Committee (SSAC) on invalid Top Level Domain (TLD) queries at the root level of the domain name system (DNS). The report calls attention to the potential problems that may arise should a new TLD applicant use a string that has been seen with measurable (and meaningful) frequency in a query for resolution by the root system and the root system has previously generated a response. The SSAC advises the ICANN community and Board on matters relating to the security and integrity of the Internet's naming and address allocation systems. This includes operational matters (e.g., matters pertaining to the correct and reliable operation of the root name system), administrative matters (e.g., matters pertaining to address allocation and Internet number assignment), and registration matters (e.g., matters pertaining to registry and registrar services such as WHOIS). SSAC engages in ongoing threat assessment and risk analysis of the Internet naming and address allocation services to assess where the principal threats to stability and security lie, and advises the ICANN community accordingly. -

Exploring the Threats of Decentalised DNS
Unravelling Ariadne's Thread: Exploring the Threats of Decentalised DNS Constantinos Patsakis1,2, Fran Casino1, Nikolaos Lykousas1, and Vasilios Katos3 1University of Piraeus 2Athena Research Center 3Bournemouth University Abstract The current landscape of the core Internet technologies shows con- siderable centralisation with the big tech companies controlling the vast majority of traffic and services. This has sparked a wide range of de- centralisation initiatives with perhaps the most profound and successful being the blockchain technology. In the past years, a core Internet in- frastructure, domain name system (DNS), is being revised mainly due to its inherent security and privacy issues. One of the proposed panaceas is Blockchain-based DNS, which claims to solve many issues of traditional DNS. However, this does not come without security concerns and issues, as any introduction and adoption of a new technology does - let alone a disruptive one such as blockchain. In this work, we discuss a num- ber of associated threats, including emerging ones, and we validate many of them with real-world data. In this regard, we explore a part of the blockchain DNS ecosystem in terms of the browser extensions using such technologies, the chain itself (Namecoin and Emercoin), the domains, and users which have been registered in both platforms. Finally, we provide some countermeasures to address the identified threats, and we propose a fertile common ground for further research. arXiv:1912.03552v1 [cs.CR] 7 Dec 2019 Keywords: Malware, DNS, Blockchain, Blockchain Forensics, Cybercrime 1 Introduction One could argue that there is a periodic paradigm shift between centralisation and decentralisation in computer science. -

Afilias Managed DNS Frequently Asked Questions Frequently Asked
Afilias Managed DNS Frequently Asked Questions Frequently Asked Questions 1 Specific Questions about Afilias Managed DNS 2 1.1 What is the Afilias DNS network? . 2 1.2 How long has Afilias been working within the DNS market? . 2 1.3 What are the names of the Afilias name servers? . 2 1.4 How does my configuration get propagated to DNS and how long does it take? . 2 1.5 How can I confirm that changes I make to my domains are being resolved on the Afilias network?............................................. 2 1.6 For secondary DNS service, what happens if there is a failure when transferring the zone file from my primary server? . 2 1.7 How easy is it to move domains over from another DNS provider and will there be any downtime? . 3 1.8 What support does Afilias provide? . 3 1.9 Does the Afilias network support IPv6? . 3 1.10 What resource records does Afilias support? . 3 1.11 Can I do bulk changes? . 3 2 General DNS Questions 3 2.1 What is DNS? . 3 2.2 Where can I get more information about DNS? . 4 2.3 What is DNSSEC? . 4 2.4 When will DNSSEC be available? . 4 2.5 What is BIND? . 4 2.6 What is the difference between a domain and a zone? . 4 2.7 What is a \glue record"? . 4 2.8 What is the difference between Primary, Secondary, Master and Slave DNS? . 4 3 Questions about Security 5 3.1 What is a distributed denial of service attack, or DDoS? . -

Root Zone – the Root DNS Node with Pointers to the Authoritative Servers for All Top-Level Domains (Gtlds, Cctlds)
K-Root Name Server Operations Andrei Robachevsky CTO, RIPE NCC [email protected] 1 Andrei Robachevsky . RIPE NCC Roundtable Meeting, March 2005. http://www.ripe.net Outline • An Overview of the Root Server System – Architecture – Anycasting • k.root-servers.net Server – Major milestones – K-Anycast deployment – Current status 2 Andrei Robachevsky . RIPE NCC Roundtable Meeting, March 2005. http://www.ripe.net Root Server System • Provides nameservice for the root zone – The root DNS node with pointers to the authoritative servers for all top-level domains (gTLDs, ccTLDs). • Thirteen name server operators – Selected by IANA – Diversity in organisations and location – 13 is a practical limit –[a ÷ m].root-servers.net - equal publishers – All 13 are authoritative servers for the root zone • An average client comes here < 8 times/week 3 Andrei Robachevsky . RIPE NCC Roundtable Meeting, March 2005. http://www.ripe.net Root servers and operators • Thirteen root nameservers – a.root-servers.net Verisign – b.root-servers.net USC-ISI – c.root-servers.net Cogent Communications – d.root-servers.net University of Maryland – e.root-servers.net NASA – f.root-servers.net ISC – g.root-servers.net US DoD (DISA) – h.root-servers.net US DoD (ARL) – i.root-servers.net Autonomica – j.root-servers.net Verisign – k.root-servers.net RIPE NCC – l.root-servers.net ICANN – m.root-servers.net WIDE Project • Look at www.root-servers.org 4 Andrei Robachevsky . RIPE NCC Roundtable Meeting, March 2005. http://www.ripe.net Current Root System Architecture • Hidden distribution master • All ‘letter’ servers are equal • Authenticated transactions between the servers (TSIG) 5 Andrei Robachevsky .