Effectiveness of Cloud Services for Scientific and Vod Applications
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Simple Statements, Large Numbers
University of Nebraska - Lincoln DigitalCommons@University of Nebraska - Lincoln MAT Exam Expository Papers Math in the Middle Institute Partnership 7-2007 Simple Statements, Large Numbers Shana Streeks University of Nebraska-Lincoln Follow this and additional works at: https://digitalcommons.unl.edu/mathmidexppap Part of the Science and Mathematics Education Commons Streeks, Shana, "Simple Statements, Large Numbers" (2007). MAT Exam Expository Papers. 41. https://digitalcommons.unl.edu/mathmidexppap/41 This Article is brought to you for free and open access by the Math in the Middle Institute Partnership at DigitalCommons@University of Nebraska - Lincoln. It has been accepted for inclusion in MAT Exam Expository Papers by an authorized administrator of DigitalCommons@University of Nebraska - Lincoln. Master of Arts in Teaching (MAT) Masters Exam Shana Streeks In partial fulfillment of the requirements for the Master of Arts in Teaching with a Specialization in the Teaching of Middle Level Mathematics in the Department of Mathematics. Gordon Woodward, Advisor July 2007 Simple Statements, Large Numbers Shana Streeks July 2007 Page 1 Streeks Simple Statements, Large Numbers Large numbers are numbers that are significantly larger than those ordinarily used in everyday life, as defined by Wikipedia (2007). Large numbers typically refer to large positive integers, or more generally, large positive real numbers, but may also be used in other contexts. Very large numbers often occur in fields such as mathematics, cosmology, and cryptography. Sometimes people refer to numbers as being “astronomically large”. However, it is easy to mathematically define numbers that are much larger than those even in astronomy. We are familiar with the large magnitudes, such as million or billion. -

Big Numbers Tom Davis [email protected] September 21, 2011
Big Numbers Tom Davis [email protected] http://www.geometer.org/mathcircles September 21, 2011 1 Introduction The problem is that we tend to live among the set of puny integers and generally ignore the vast infinitude of larger ones. How trite and limiting our view! — P.D. Schumer It seems that most children at some age get interested in large numbers. “What comes after a thousand? After a million? After a billion?”, et cetera, are common questions. Obviously there is no limit; whatever number you name, a larger one can be obtained simply by adding one. But what is interesting is just how large a number can be expressed in a fairly compact way. Using the standard arithmetic operations (addition, subtraction, multiplication, division and exponentia- tion), what is the largest number you can make using three copies of the digit “9”? It’s pretty clear we should just stick to exponents, and given that, here are some possibilities: 999, 999, 9 999, and 99 . 9 9 Already we need to be a little careful with the final one: 99 . Does this mean: (99)9 or 9(9 )? Since (99)9 = 981 this interpretation would gain us very little. If this were the standard definition, then why c not write ab as abc? Because of this, a tower of exponents is always interpreted as being evaluated from d d c c c (c ) right to left. In other words, ab = a(b ), ab = a(b ), et cetera. 9 With this definition of towers of exponents, it is clear that 99 is the best we can do. -

The Costs of Inaction
Climate Change – the Costs of Inaction Report to Friends of the Earth England, Wales and Northern Ireland Frank Ackerman and Elizabeth Stanton Global Development and Environment Institute, Tufts University October 11, 2006 Table of Contents Executive Summary ................................................................................................. iii Introduction................................................................................................................1 Categorizing climate risks........................................................................................................... 2 The UK in 2050: hot, and getting hotter....................................................................7 Impacts of Climate Change......................................................................................11 Agriculture ................................................................................................................................ 11 Industry and infrastructure........................................................................................................ 15 Fresh water................................................................................................................................ 17 Human health............................................................................................................................ 18 Ecosystems and extinctions ...................................................................................................... 22 Summary measures of -

What Fun! It's Practice with Scientific Notation!
What Fun! It's Practice with Scientific Notation! Review of Scientific Notation Scientific notation provides a place to hold the zeroes that come after a whole number or before a fraction. The number 100,000,000 for example, takes up a lot of room and takes time to write out, while 108 is much more efficient. Though we think of zero as having no value, zeroes can make a number much bigger or smaller. Think about the difference between 10 dollars and 100 dollars. Even one zero can make a big difference in the value of the number. In the same way, 0.1 (one-tenth) of the US military budget is much more than 0.01 (one-hundredth) of the budget. The small number to the right of the 10 in scientific notation is called the exponent. Note that a negative exponent indicates that the number is a fraction (less than one). The line below shows the equivalent values of decimal notation (the way we write numbers usually, like "1,000 dollars") and scientific notation (103 dollars). For numbers smaller than one, the fraction is given as well. smaller bigger Fraction 1/100 1/10 Decimal notation 0.01 0.1 1 10 100 1,000 ____________________________________________________________________________ Scientific notation 10-2 10-1 100 101 102 103 Practice With Scientific Notation Write out the decimal equivalent (regular form) of the following numbers that are in scientific notation. Section A: Model: 101 = 10 1) 102 = _______________ 4) 10-2 = _________________ 2) 104 = _______________ 5) 10-5 = _________________ 3) 107 = _______________ 6) 100 = __________________ Section B: Model: 2 x 102 = 200 7) 3 x 102 = _________________ 10) 6 x 10-3 = ________________ 8) 7 x 104 = _________________ 11) 900 x 10-2 = ______________ 9) 2.4 x 103 = _______________ 12) 4 x 10-6 = _________________ Section C: Now convert from decimal form into scientific notation. -

Ever Heard of a Prillionaire? by Carol Castellon Do You Watch the TV Show
Ever Heard of a Prillionaire? by Carol Castellon Do you watch the TV show “Who Wants to Be a Millionaire?” hosted by Regis Philbin? Have you ever wished for a million dollars? "In today’s economy, even the millionaire doesn’t receive as much attention as the billionaire. Winners of a one-million dollar lottery find that it may not mean getting to retire, since the million is spread over 20 years (less than $3000 per month after taxes)."1 "If you count to a trillion dollars one by one at a dollar a second, you will need 31,710 years. Our government spends over three billion per day. At that rate, Washington is going through a trillion dollars in a less than one year. or about 31,708 years faster than you can count all that money!"1 I’ve heard people use names such as “zillion,” “gazillion,” “prillion,” for large numbers, and more recently I hear “Mega-Million.” It is fairly obvious that most people don’t know the correct names for large numbers. But where do we go from million? After a billion, of course, is trillion. Then comes quadrillion, quintrillion, sextillion, septillion, octillion, nonillion, and decillion. One of my favorite challenges is to have my math class continue to count by "illions" as far as they can. 6 million = 1x10 9 billion = 1x10 12 trillion = 1x10 15 quadrillion = 1x10 18 quintillion = 1x10 21 sextillion = 1x10 24 septillion = 1x10 27 octillion = 1x10 30 nonillion = 1x10 33 decillion = 1x10 36 undecillion = 1x10 39 duodecillion = 1x10 42 tredecillion = 1x10 45 quattuordecillion = 1x10 48 quindecillion = 1x10 51 -
Large Numbers from Wikipedia, the Free Encyclopedia
Large numbers From Wikipedia, the free encyclopedia This article is about large numbers in the sense of numbers that are significantly larger than those ordinarily used in everyday life, for instance in simple counting or in monetary transactions. The term typically refers to large positive integers, or more generally, large positive real numbers, but it may also be used in other contexts. Very large numbers often occur in fields such as mathematics, cosmology, cryptography, and statistical mechanics. Sometimes people refer to numbers as being "astronomically large". However, it is easy to mathematically define numbers that are much larger even than those used in astronomy. Contents 1 Using scientific notation to handle large and small numbers 2 Large numbers in the everyday world 3 Astronomically large numbers 4 Computers and computational complexity 5 Examples 6 Systematically creating ever faster increasing sequences 7 Standardized system of writing very large numbers 7.1 Examples of numbers in numerical order 8 Comparison of base values 9 Accuracy 9.1 Accuracy for very large numbers 9.2 Approximate arithmetic for very large numbers 10 Large numbers in some noncomputable sequences 11 Infinite numbers 12 Notations 13 See also 14 Notes and references Using scientific notation to handle large and small numbers See also: scientific notation, logarithmic scale and orders of magnitude Scientific notation was created to handle the wide range of values that occur in scientific study. 1.0 × 109, for example, means one billion, a 1 followed by nine zeros: 1 000 000 000, and 1.0 × 10−9 means one billionth, or 0.000 000 001. -

What Do the Measured Units Mean? What Is an Acceptable Measurement?
What Do the Measured Units Mean? What is an Acceptable Measurement? Upon the adoption of the Clean Water Act in 1972 and the Safe Drinking Water Act of 1974, Federal and State agencies established standards and limits for contamination of the waters of the United States, including those used for drinking water supply. Those limits were based upon health assessments using analytical technology of the time, with many limits established at levels measured in the parts per million (ppm). As technology and research improved, Federal and State agencies occasionally adjust those limits, now measured in the parts per billion (ppb), as deemed necessary and justified by scientific review. Water professionals have the technology today to detect more substances at lower levels than ever before. As analytical methods improve, various compounds, including hexavalent chromium, are likely to be found at very low levels in many of our nation’s lakes, rivers and streams. Because units of measurement are often difficult to place into context, the following comparisons are provided: One-Part-Per-Million (mg/L or ppm) • one automobile in bumper-to-bumper traffic from Cleveland to San Francisco • one inch in 16 miles • one minute in two years • one ounce in 32 tons • one cent in $10,000 One-Part-Per-Billion (ug/L or ppb) = 1/1000 ppm • one 4-inch hamburger in a chain of hamburgers circling the earth at the equator 2.5 times • one silver dollar in a roll of silver dollars stretching from Detroit to Salt Lake City • one kernel of corn in a 45-foot high, 16-foot -

Scientific Notation
Scientific Methods: Scientific Notation Scientific notation is the way that scientists handle very large or very small numbers, such as the size or age of the Universe, or the size of the national debt. For example, instead of writing 1,500,000,000,000, or 1.5 trillion, we write 1.5 x 1012. There are two parts to this number: 1.5 (digits term) and 1012 (exponential term). Here are some examples of scientific notation used in astronomy (and a few just for comparison!). THE CHART OF REALLY BIG NUMBERS 1,000,000,000,000,000,000,000,000,000,000 = We don't even have a word for this. It's the 1 x 1030 mass of the Sun in kilograms. One hundred trillion billion: The 100,000,000,000,000,000,000,000 = 1 x 1023 approximate number of stars in the Universe 40.1 Trillion: the distance (in km) to the 40,100,000,000,000 = 4.01 x 1013 nearest star, Proxima Centauri. 5.7 Trillion: the number of dollars in the 1,600,000,000,000 = 5.7 x 1012 U.S. national debt, circa 2000. Two Hundred Billion: Approximate number 200,000,000,000 = 2 x 1011 of stars in the Milky Way Galaxy. 15 Billion: Approximate age of the 15,000,000,000 = 1.5 x 1010 Universe (in years). Six Billion: Approximate number of people 6,000,000,000 = 6 x 109 on the planet, circa 2000. One Billion: The number of Earth-sized 1,000,000,000 = 1 x 109 planets that would fit into the Sun; Also the speed of light in km/hr One hundred million: the radius of the Sun 100,000,000 = 1 x 108 in meters. -

Powers of 10 & Scientific Notation
Physics 151 Powers of 10 & Scientific Notation In all of the physical sciences, we encounter many numbers that are so large or small that it would be exceedingly cumbersome to write them with dozens of trailing or leading zeroes. Since our number system is “base-10” (based on powers of 10), it is far more convenient to write very large and very small numbers in a special exponential notation called scientific notation. In scientific notation, a number is rewritten as a simple decimal multiplied by 10 raised to some power, n, like this: x.xxxx... × 10n Powers of Ten Remember that the powers of 10 are as follows: 0 10 = 1 1 –1 1 10 = 10 10 = 0.1 = 10 2 –2 1 10 = 100 10 = 0.01 = 100 3 –3 1 10 = 1000 10 = 0.001 = 1000 4 –4 1 10 = 10,000 10 = 0.0001 = 10,000 ...and so forth. There are some important powers that we use often: 103 = 1000 = one thousand 10–3 = 0.001 = one thousandth 106 = 1,000,000 = one million 10–6 = 0.000 001 = one millionth 109 = 1,000,000,000 = one billion 10–9 = 0.000 000 001 = one billionth 1012 = 1,000,000,000,000 = one trillion 10–12 = 0.000 000 000 001 = one trillionth In the left-hand columns above, where n is positive, note that n is simply the same as the number of zeroes in the full written-out form of the number! However, in the right-hand columns where n is negative, note that |n| is one greater than the number of place-holding zeroes. -

Removing Impediments to Sustainable Economic Development the Case of Corruption
WPS6704 Policy Research Working Paper 6704 Public Disclosure Authorized Removing Impediments to Sustainable Economic Development Public Disclosure Authorized The Case of Corruption Augusto López Claros Public Disclosure Authorized The World Bank Public Disclosure Authorized Financial and Private Sector Development Global Indicators and Analysis Department November 2013 Policy Research Working Paper 6704 Abstract This paper examines causes and consequences of agent of resource allocation. What is the impact of corruption within the process of economic development. corruption on public finances and on the characteristics It starts by reviewing some of the factors that, over the and performance of the private sector? What distortions past couple of decades, have transformed corruption does corruption introduce in the allocation of resources from a subject on the sidelines of economic research to and in the relationships among economic agents in the a central preoccupation of policy makers and donors marketplace? The paper also addresses the question of in many countries. Drawing on a vast treasure trove of what can be done about corruption and discusses the experiences and insights accumulated during the postwar role of economic policies in developing the right sorts period and reflected in a growing body of academic of incentives and institutions to reduce the incidence research, the paper analyzes many of the institutional of corruption. Particular attention is paid to business mechanisms that sustain corruption and the impact regulation, subsidies, the budget process, international of corruption on development. This paper argues that conventions, and the role of new technologies. The paper many forms of corruption stem from the distributional concludes with some thoughts on the moral dimensions attributes of the state in its role as the economy’s central of corruption. -

How to Measure Natural Gas?
How to Measure Natural Gas? Describing the amount of natural gas consumed by an entire country or a single residential appliance can be confusing, since natural gas can be measured in several different ways. Quantities of natural gas are usually measured in cubic feet. CRMU lists how much gas residential customers use each month in 100 cubic feet increments or (100 cubic feet – 1 hcf). For example, a typical natural gas futures contract is a financial instrument based on the value of about 10 million cubic feet (Mmcf) of natural gas. The energy content of natural gas and other forms of energy (i.e., the potential heat that can be generated from the fuel) is measured in Btus (British thermal units). The number of "therms" that residential natural gas customers consume each month is approximately equal to hcf. Here are some frequently used units for measuring natural gas: 1 cubic foot (cf) = 1,027 Btu 100 cubic feet (1 hcf) = 1 therm (approximate) 1,000 cubic feet (1 Mcf) = 1,027,000 Btu (1 MMBtu) 1,000 cubic feet (1 Mcf) = 1 dekatherm (10 therms) 1 million (1,000,000) cubic feet (1 Mmcf) = 1,027,000,000 Btu 1 billion (1,000,000,000 cubic feet (1 bcf) = 1.027 trillion Btu 1 trillion (1,000,000,000,000) cubic feet (1Tcf) = 1.027 quadrillion Btu To put this in context: • 1,000 cubic feet of natural gas is approximately enough to meet the natural gas needs of an average home (space-heating, water-heating, cooking, etc.) for four days. -
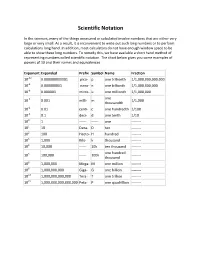
Scientific Notation
Scientific Notation In the sciences, many of the things measured or calculated involve numbers that are either very large or very small. As a result, it is inconvenient to write out such long numbers or to perform calculations long hand. In addition, most calculators do not have enough window space to be able to show these long numbers. To remedy this, we have available a short hand method of representing numbers called scientific notation. The chart below gives you some examples of powers of 10 and their names and equivalences. Exponent Expanded Prefix Symbol Name Fraction 10-12 0.000000000001 pico- p one trillionth 1/1,000,000,000,000 10-9 0.000000001 nano- n one billionth 1/1,000,000,000 10-6 0.000001 micro- u one millionth 1/1,000,000 one 10-3 0.001 milli- m 1/1,000 thousandth 10-2 0.01 centi- c one hundredth 1/100 10-1 0.1 deci- d one tenth 1/10 100 1 ------ ------ one -------- 101 10 Deca- D ten -------- 102 100 Hecto- H hundred -------- 103 1,000 Kilo- k thousand -------- 104 10,000 ------ 10k ten thousand -------- one hundred 105 100,000 ------ 100k -------- thousand 106 1,000,000 Mega- M one million -------- 109 1,000,000,000 Giga- G one billion -------- 1012 1,000,000,000,000 Tera- T one trillion -------- 1015 1,000,000,000,000,000 Peta- P one quadrillion -------- Powers of 10 and Place Value.......... Multiplying by 10, 100, or 1000 in the following problems just means to add the number of zeroes to the number being multiplied.