Trajectory Box Plot: a New Pattern to Summarize Movements Laurent Etienne, Thomas Devogele, Maike Buckin, Gavin Mcardle
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-
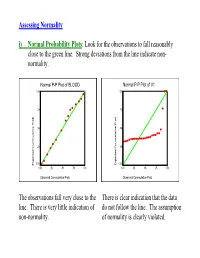
Assessing Normality I) Normal Probability Plots : Look for The
Assessing Normality i) Normal Probability Plots: Look for the observations to fall reasonably close to the green line. Strong deviations from the line indicate non- normality. Normal P-P Plot of BLOOD Normal P-P Plot of V1 1.00 1.00 .75 .75 .50 .50 .25 .25 0.00 0.00 Expected Cummulative Prob Expected Cummulative Expected Cummulative Prob Expected Cummulative 0.00 .25 .50 .75 1.00 0.00 .25 .50 .75 1.00 Observed Cummulative Prob Observed Cummulative Prob The observations fall very close to the There is clear indication that the data line. There is very little indication of do not follow the line. The assumption non-normality. of normality is clearly violated. ii) Histogram: Look for a “bell-shape”. Severe skewness and/or outliers are indications of non-normality. 5 16 14 4 12 10 3 8 2 6 4 1 Std. Dev = 60.29 Std. Dev = 992.11 2 Mean = 274.3 Mean = 573.1 0 N = 20.00 0 N = 25.00 150.0 200.0 250.0 300.0 350.0 0.0 1000.0 2000.0 3000.0 4000.0 175.0 225.0 275.0 325.0 375.0 500.0 1500.0 2500.0 3500.0 4500.0 BLOOD V1 Although the histogram is not perfectly There is a clear indication that the data symmetric and bell-shaped, there is no are right-skewed with some strong clear violation of normality. outliers. The assumption of normality is clearly violated. Caution: Histograms are not useful for small sample sizes as it is difficult to get a clear picture of the distribution. -
![Arxiv:1605.06950V4 [Stat.ML] 12 Apr 2017 Racy of RAND Depends on the Diameter of the Network, 1 X Which Motivated Cohen Et Al](https://docslib.b-cdn.net/cover/8813/arxiv-1605-06950v4-stat-ml-12-apr-2017-racy-of-rand-depends-on-the-diameter-of-the-network-1-x-which-motivated-cohen-et-al-128813.webp)
Arxiv:1605.06950V4 [Stat.ML] 12 Apr 2017 Racy of RAND Depends on the Diameter of the Network, 1 X Which Motivated Cohen Et Al
A Sub-Quadratic Exact Medoid Algorithm James Newling Fran¸coisFleuret Idiap Research Institute & EPFL Idiap Research Institute & EPFL Abstract network analysis. In clustering, the Voronoi iteration K-medoids algorithm (Hastie et al., 2001; Park and Jun, 2009) requires determining the medoid of each of We present a new algorithm trimed for ob- K clusters at each iteration. In operations research, taining the medoid of a set, that is the el- the facility location problem requires placing one or ement of the set which minimises the mean several facilities so as to minimise the cost of connect- distance to all other elements. The algorithm ing to clients. In network analysis, the medoid may is shown to have, under certain assumptions, 3 d represent an influential person in a social network, or expected run time O(N 2 ) in where N is R the most central station in a rail network. the set size, making it the first sub-quadratic exact medoid algorithm for d > 1. Experi- ments show that it performs very well on spa- 1.1 Medoid algorithms and our contribution tial network data, frequently requiring two A simple algorithm for obtaining the medoid of a set orders of magnitude fewer distance calcula- of N elements computes the energy of all elements and tions than state-of-the-art approximate al- selects the one with minimum energy, requiring Θ(N 2) gorithms. As an application, we show how time. In certain settings Θ(N) algorithms exist, such trimed can be used as a component in an as in 1-D where the problem is solved by Quickse- accelerated K-medoids algorithm, and then lect (Hoare, 1961), and more generally on trees. -

Robust Geometry Estimation Using the Generalized Voronoi Covariance Measure Louis Cuel, Jacques-Olivier Lachaud, Quentin Mérigot, Boris Thibert
Robust Geometry Estimation using the Generalized Voronoi Covariance Measure Louis Cuel, Jacques-Olivier Lachaud, Quentin Mérigot, Boris Thibert To cite this version: Louis Cuel, Jacques-Olivier Lachaud, Quentin Mérigot, Boris Thibert. Robust Geometry Estimation using the Generalized Voronoi Covariance Measure. SIAM Journal on Imaging Sciences, Society for In- dustrial and Applied Mathematics, 2015, 8 (2), pp.1293-1314. 10.1137/140977552. hal-01058145v2 HAL Id: hal-01058145 https://hal.archives-ouvertes.fr/hal-01058145v2 Submitted on 4 Nov 2015 HAL is a multi-disciplinary open access L’archive ouverte pluridisciplinaire HAL, est archive for the deposit and dissemination of sci- destinée au dépôt et à la diffusion de documents entific research documents, whether they are pub- scientifiques de niveau recherche, publiés ou non, lished or not. The documents may come from émanant des établissements d’enseignement et de teaching and research institutions in France or recherche français ou étrangers, des laboratoires abroad, or from public or private research centers. publics ou privés. Robust Geometry Estimation using the Generalized Voronoi Covariance Measure∗y Louis Cuel1,2, Jacques-Olivier Lachaud 2, Quentin M´erigot1,3, and Boris Thibert2 1Laboratoire Jean Kuntzman, Universit´eGrenoble-Alpes, France 2Laboratoire de Math´ematiques(LAMA), Universit´ede Savoie, France 3CNRS November 4, 2015 Abstract d The Voronoi Covariance Measure of a compact set K of R is a tensor-valued measure that encodes geometrical information on K and which is known to be resilient to Hausdorff noise but sensitive to outliers. In this article, we generalize this notion to any distance-like function δ and define the δ-VCM. -

Infield Biomass Bales Aggregation Logistics and Equipment Track
INFIELD BIOMASS BALES AGGREGATION LOGISTICS AND EQUIPMENT TRACK IMPACTED AREA EVALUATION A Thesis Submitted to the Graduate Faculty of the North Dakota State University of Agriculture and Applied Science By Subhashree Navaneetha Srinivasagan In Partial Fulfillment of the Requirements for the Degree of MASTER OF SCIENCE Major Department: Agricultural and Biosystems Engineering November 2017 Fargo, North Dakota NORTH DAKOTA STATE UNIVERSITY Graduate School Title INFIELD BIOMASS BALES AGGREGATION LOGISTICS AND EQUIPMENT TRACK IMPACTED AREA EVALUATION By Subhashree Navaneetha Srinivasagan The supervisory committee certifies that this thesis complies with North Dakota State University’s regulations and meets the accepted standards for the degree of MASTER OF SCIENCE SUPERVISORY COMMITTEE: Dr. Igathinathane Cannayen Chair Dr. Halis Simsek Dr. David Ripplinger Approved: 11/22/2017 Dr. Sreekala Bajwa Date Department Chair ABSTRACT Efficient bale stack location, infield bale logistics, and equipment track impacted area were conducted in three different studies using simulation in R. Even though the geometric median produced the best logistics, among the five mathematical grouping methods, the field middle was recommended as it was comparable and easily accessible in the field. Curvilinear method developed (8–259 ha), incorporating equipment turning (tractor: 1 and 2 bales/trip, automatic bale picker (ABP): 8–23 bales/trip, harvester, and baler), evaluated the aggregation distance, impacted area, and operation time. The harvester generated the most, followed by the baler, and the ABP the least impacted area and operation time. The ABP was considered as the most effective bale aggregation equipment compared to the tractor. Simple specific and generalized prediction models, developed for aggregation logistics, impacted area, and operation time, have performed 2 well (0.88 R 0.99). -

Robustness Meets Algorithms
Robustness Meets Algorithms Ankur Moitra (MIT) Robust Statistics Summer School CLASSIC PARAMETER ESTIMATION Given samples from an unknown distribution in some class e.g. a 1-D Gaussian can we accurately estimate its parameters? CLASSIC PARAMETER ESTIMATION Given samples from an unknown distribution in some class e.g. a 1-D Gaussian can we accurately estimate its parameters? Yes! CLASSIC PARAMETER ESTIMATION Given samples from an unknown distribution in some class e.g. a 1-D Gaussian can we accurately estimate its parameters? Yes! empirical mean: empirical variance: R. A. Fisher The maximum likelihood estimator is asymptotically efficient (1910-1920) R. A. Fisher J. W. Tukey The maximum likelihood What about errors in the estimator is asymptotically model itself? (1960) efficient (1910-1920) ROBUST PARAMETER ESTIMATION Given corrupted samples from a 1-D Gaussian: + = ideal model noise observed model can we accurately estimate its parameters? How do we constrain the noise? How do we constrain the noise? Equivalently: L1-norm of noise at most O(ε) How do we constrain the noise? Equivalently: Arbitrarily corrupt O(ε)-fraction L1-norm of noise at most O(ε) of samples (in expectation) How do we constrain the noise? Equivalently: Arbitrarily corrupt O(ε)-fraction L1-norm of noise at most O(ε) of samples (in expectation) This generalizes Huber’s Contamination Model: An adversary can add an ε-fraction of samples How do we constrain the noise? Equivalently: Arbitrarily corrupt O(ε)-fraction L1-norm of noise at most O(ε) of samples (in expectation) -

Boxplots for Grouped and Clustered Data in Toxicology
Penultimate version. If citing, please refer instead to the published version in Archives of Toxicology, DOI: 10.1007/s00204-015-1608-4. Boxplots for grouped and clustered data in toxicology Philip Pallmann1, Ludwig A. Hothorn2 1 Department of Mathematics and Statistics, Lancaster University, Lancaster LA1 4YF, UK, Tel.: +44 (0)1524 592318, [email protected] 2 Institute of Biostatistics, Leibniz University Hannover, 30419 Hannover, Germany Abstract The vast majority of toxicological papers summarize experimental data as bar charts of means with error bars. While these graphics are easy to generate, they often obscure essen- tial features of the data, such as outliers or subgroups of individuals reacting differently to a treatment. Especially raw values are of prime importance in toxicology, therefore we argue they should not be hidden in messy supplementary tables but rather unveiled in neat graphics in the results section. We propose jittered boxplots as a very compact yet comprehensive and intuitively accessible way of visualizing grouped and clustered data from toxicological studies together with individual raw values and indications of statistical significance. A web application to create these plots is available online. Graphics, statistics, R software, body weight, micronucleus assay 1 Introduction Preparing a graphical summary is usually the first if not the most important step in a data analysis procedure, and it can be challenging especially with many-faceted datasets as they occur frequently in toxicological studies. However, even in simple experimental setups many researchers have a hard time presenting their results in a suitable manner. Browsing recent volumes of this journal, we have realized that the least favorable ways of displaying toxicological data appear to be the most popular ones (according to the number of publications that use them). -

Geometric Median Shapes
GEOMETRIC MEDIAN SHAPES Alexandre Cunha Center for Advanced Methods in Biological Image Analysis Center for Data Driven Discovery California Institute of Technology, Pasadena, CA, USA ABSTRACT an efficient linear program in practice. They observed that smooth We present an algorithm to compute the geometric median of shapes do not necessarily lead to smooth medians, an aspect we also shapes which is based on the extension of median to high dimen- verified in some of our experiments. sions. The median finding problem is formulated as an optimization We propose a method to quickly build median shapes from over distances and it is solved directly using the watershed method closed planar contours representing silhouettes of shapes discretized as an optimizer. We show that the geometric median shape faithfully in images. Our median shape is computed using the notion of represents the true central tendency of the data, contaminated or not. geometric median [12], also known as the spatial median, Fermat- It is superior to the mean shape which can be negatively affected by Weber point, and L1 median (see [13] for the history and survey the presence of outliers. Our approach can be applied to manifold of multidimensional medians), which is an extension of the median and non manifold shapes, with single or multiple connected com- of numbers to points in higher dimensional spaces. The geometric ponents. The application of distance transform and watershed algo- median has the property, in any dimension, that it minimizes the n rithm, two well established constructs of image processing, lead to sum of its Euclidean distances to given anchor points xj 2 R , an algorithm that can be quickly implemented to generate fast solu- ∗ X x = arg min kx − xj k : (1) tions with linear storage requirement. -

Length of Stay Outlier Detection Through Cluster Analysis: a Case Study in Pediatrics Daniel Gartnera, Rema Padmanb
Length of Stay Outlier Detection through Cluster Analysis: A Case Study in Pediatrics Daniel Gartnera, Rema Padmanb aSchool of Mathematics, Cardiff University, United Kingdom bThe H. John Heinz III College, Carnegie Mellon University, Pittsburgh, USA Abstract The increasing availability of detailed inpatient data is enabling the develop- ment of data-driven approaches to provide novel insights for the management of Length of Stay (LOS), an important quality metric in hospitals. This study examines clustering of inpatients using clinical and demographic attributes to identify LOS outliers and investigates the opportunity to reduce their LOS by comparing their order sequences with similar non-outliers in the same cluster. Learning from retrospective data on 353 pediatric inpatients admit- ted for appendectomy, we develop a two-stage procedure that first identifies a typical cluster with LOS outliers. Our second stage analysis compares orders pairwise to determine candidates for switching to make LOS outliers simi- lar to non-outliers. Results indicate that switching orders in homogeneous inpatient sub-populations within the limits of clinical guidelines may be a promising decision support strategy for LOS management. Keywords: Machine Learning; Clustering; Health Care; Length of Stay Email addresses: [email protected] (Daniel Gartner), [email protected] (Rema Padman) 1. Introduction Length of Stay (LOS) is an important quality metric in hospitals that has been studied for decades Kim and Soeken (2005); Tu et al. (1995). However, the increasing digitization of healthcare with Electronic Health Records and other clinical information systems is enabling the collection and analysis of vast amounts of data using advanced data-driven methods that may be par- ticularly valuable for LOS management Gartner (2015); Saria et al. -

Rotation Averaging
Noname manuscript No. (will be inserted by the editor) Rotation Averaging Richard Hartley, Jochen Trumpf, Yuchao Dai, Hongdong Li Received: date / Accepted: date Abstract This paper is conceived as a tutorial on rota- Single rotation averaging. In the single rotation averaging tion averaging, summarizing the research that has been car- problem, several estimates are obtained of a single rotation, ried out in this area; it discusses methods for single-view which are then averaged to give the best estimate. This may and multiple-view rotation averaging, as well as providing be thought of as finding a mean of several points Ri in the proofs of convergence and convexity in many cases. How- rotation space SO(3) (the group of all 3-dimensional rota- ever, at the same time it contains many new results, which tions) and is an instance of finding a mean in a manifold. were developed to fill gaps in knowledge, answering funda- Given an exponent p ≥ 1 and a set of n ≥ 1 rotations p mental questions such as radius of convergence of the al- fR1;:::; Rng ⊂ SO(3) we wish to find the L -mean rota- gorithms, and existence of local minima. These matters, or tion with respect to d which is defined as even proofs of correctness have in many cases not been con- n p X p sidered in the Computer Vision literature. d -mean(fR1;:::; Rng) = argmin d(Ri; R) : We consider three main problems: single rotation av- R2SO(3) i=1 eraging, in which a single rotation is computed starting Since SO(3) is compact, a minimum will exist as long as the from several measurements; multiple-rotation averaging, in distance function is continuous (which any sensible distance which absolute orientations are computed from several rel- function is). -

Non-Parametric Vs. Parametric Tests in SAS® Venita Depuy and Paul A
NESUG 17 Analysis Perusing, Choosing, and Not Mis-using: ® Non-parametric vs. Parametric Tests in SAS Venita DePuy and Paul A. Pappas, Duke Clinical Research Institute, Durham, NC ABSTRACT spread is less easy to quantify but is often represented by Most commonly used statistical procedures, such as the t- the interquartile range, which is simply the difference test, are based on the assumption of normality. The field between the first and third quartiles. of non-parametric statistics provides equivalent procedures that do not require normality, but often require DETERMINING NORMALITY assumptions such as equal variances. Parametric tests (OR LACK THEREOF) (which assume normality) are often used on non-normal One of the first steps in test selection should be data; even non-parametric tests are used when their investigating the distribution of the data. PROC assumptions are violated. This paper will provide an UNIVARIATE can be implemented to help determine overview of parametric tests and their non-parametric whether or not your data are normal. This procedure equivalents; what assumptions are required for each test; ® generates a variety of summary statistics, such as the how to perform the tests in SAS ; and guidelines for when mean and median, as well as numerical representations of both sets of assumptions are violated. properties such as skewness and kurtosis. Procedures covered will include PROCs ANOVA, CORR, If the population from which the data are obtained is NPAR1WAY, TTEST and UNIVARIATE. Discussion will normal, the mean and median should be equal or close to include assumptions and assumption violations, equal. The skewness coefficient, which is a measure of robustness, and exact versus approximate tests. -

Understanding and Comparing Distributions
Understanding and Comparing Distributions Chapter 4 Objectives: • Boxplot • Calculate Outliers • Comparing Distributions • Timeplot The Big Picture • We can answer much more interesting questions about variables when we compare distributions for different groups. • Below is a histogram of the Average Wind Speed for every day in 1989. The Big Picture (cont.) • The distribution is unimodal and skewed to the right. • The high value may be an outlier Comparing distributions can be much more interesting than just describing a single distribution. The Five-Number Summary • The five-number summary of a distribution reports its Max 8.67 median, quartiles, and Q3 2.93 extremes (maximum and minimum). Median 1.90 • Example: The five-number Q1 1.15 summary for for the daily Min 0.20 wind speed is: The Five-Number Summary • Consists of the minimum value, Q1, the median, Q3, and the maximum value, listed in that order. • Offers a reasonably complete description of the center and spread. • Calculate on the TI-83/84 using 1-Var Stats. • Used to construct the Boxplot. • Example: Five-Number Summary • 1: 20, 27, 34, 50, 86 • 2: 5, 10, 18.5, 29, 33 Daily Wind Speed: Making Boxplots • A boxplot is a graphical display of the five- number summary. • Boxplots are useful when comparing groups. • Boxplots are particularly good at pointing out outliers. Boxplot • A graph of the Five-Number Summary. • Can be drawn either horizontally or vertically. • The box represents the IQR (middle 50%) of the data. • Show less detail than histograms or stemplots, they are best used for side-by-side comparison of more than one distribution. -

Understanding the K-Medians Problem
Int'l Conf. Scientific Computing | CSC'15 | 219 Understanding the K-Medians Problem Christopher Whelan, Greg Harrell, and Jin Wang Department of Mathematics and Computer Science Valdosta State University, Valdosta, Georgia 31698, USA Abstract - In this study, the general ideas surrounding the 2.1 Benefits over K-Means k-medians problem are discussed. This involves a look into The k-means problem was conceived far before the k- what k-medians attempts to solve and how it goes about medians problem. In fact, k-medians is simply a variant of doing so. We take a look at why k-medians is used as k-means as we know it. Why would k-medians be used, opposed to its k-means counterpart, specifically how its then, instead of a more studied and further refined method robustness enables it to be far more resistant to outliers. of locating k cluster centers? K-medians owes its use to We then discuss the areas of study that are prevalent in the robustness of the median as a statistic [1]. The mean is a realm of the k-medians problem. Finally, we view an measurement that is highly vulnerable to outliers. Even just approach to the problem that has decreased its time one drastic outlier can pull the value of the mean away complexity by instead performing the k-medians algorithm from the majority of the data set, which can be a high on small coresets representative of the data set. concern when operating on very large data sets. The median, on the other hand, is a statistic incredibly resistant Keywords: K-medians; K-means; clustering to outliers, for in order to deter the median away from the bulk of the information, it requires at least 50% of the data to be contaminated [1].