Fusing Social Media and Traditional Traffic Data for Advanced Traveler
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Uila Supported Apps
Uila Supported Applications and Protocols updated Oct 2020 Application/Protocol Name Full Description 01net.com 01net website, a French high-tech news site. 050 plus is a Japanese embedded smartphone application dedicated to 050 plus audio-conferencing. 0zz0.com 0zz0 is an online solution to store, send and share files 10050.net China Railcom group web portal. This protocol plug-in classifies the http traffic to the host 10086.cn. It also 10086.cn classifies the ssl traffic to the Common Name 10086.cn. 104.com Web site dedicated to job research. 1111.com.tw Website dedicated to job research in Taiwan. 114la.com Chinese web portal operated by YLMF Computer Technology Co. Chinese cloud storing system of the 115 website. It is operated by YLMF 115.com Computer Technology Co. 118114.cn Chinese booking and reservation portal. 11st.co.kr Korean shopping website 11st. It is operated by SK Planet Co. 1337x.org Bittorrent tracker search engine 139mail 139mail is a chinese webmail powered by China Mobile. 15min.lt Lithuanian news portal Chinese web portal 163. It is operated by NetEase, a company which 163.com pioneered the development of Internet in China. 17173.com Website distributing Chinese games. 17u.com Chinese online travel booking website. 20 minutes is a free, daily newspaper available in France, Spain and 20minutes Switzerland. This plugin classifies websites. 24h.com.vn Vietnamese news portal 24ora.com Aruban news portal 24sata.hr Croatian news portal 24SevenOffice 24SevenOffice is a web-based Enterprise resource planning (ERP) systems. 24ur.com Slovenian news portal 2ch.net Japanese adult videos web site 2Shared 2shared is an online space for sharing and storage. -

Social Media Reputation Management
SOCIAL MEDIA REPUTATION MANAGEMENT If you are using social media sites such as Facebook or Twitter, there are some simple steps you can take to manage your reputation and protect your identity. Even if you are not using these sites, it is important to manage your digital footprint and identify any false or misleading information about you online. In this booklet you will find our top 10 tips for protecting your reputation online. We also provide practical guides for setting up Facebook, Twitter, Instagram and mobile devices to help you ensure your information is safe online. Contents Top 10 tips for protecting your reputation online ... 2 Managing your Facebook account ................ 5 Make sure your profile is set to private 5 Only accept friend requests from people you know and trust and learn to block offensive users 8 Report fake profiles 9 Delete unused accounts 10 Managing your Twitter account .................. 12 Make sure your profile is set to private 12 Only accept friend requests from people you know and trust and learn to block offensive users 12 Report fake profiles 13 Delete unused accounts 15 Managing your LinkedIn account ................ 16 Make sure your profile is set to private 16 Limiting who can view your activity feed and connections 16 Limiting certain people from communicating with you 17 Protecting your account information 17 Delete your account 17 Managing your Instagram account ............... 18 Make sure your profile is set to private 18 Only accept friend requests from people you know and trust and learn to block offensive users 19 Report fake profiles 19 Managing your Snapchat account ............... -

La Conciencia De Marca En Redes Sociales: Impacto En La Comunicación Boca a Boca
Estudios Gerenciales ISSN: 0123-5923 Universidad Icesi La conciencia de marca en redes sociales: impacto en la comunicación boca a boca Rubalcava de León, Cristian-Alejandro; Sánchez-Tovar, Yesenia; Sánchez-Limón, Mónica-Lorena La conciencia de marca en redes sociales: impacto en la comunicación boca a boca Estudios Gerenciales, vol. 35, núm. 152, 2019 Universidad Icesi Disponible en: http://www.redalyc.org/articulo.oa?id=21262296009 DOI: 10.18046/j.estger.2019.152.3108 PDF generado a partir de XML-JATS4R por Redalyc Proyecto académico sin fines de lucro, desarrollado bajo la iniciativa de acceso abierto Artículo de investigación La conciencia de marca en redes sociales: impacto en la comunicación boca a boca Brand awareness in social networks: impact on the word of mouth Reconhecimento de marca nas redes sociais: impacto na comunicação boca a boca Cristian-Alejandro Rubalcava de León * [email protected] Universidad Autónoma de Tamaulipas, Mexico Yesenia Sánchez-Tovar ** Universidad Autónoma de Tamaulipas, Mexico Mónica-Lorena Sánchez-Limón *** Universidad Autónoma de Tamaulipas, Mexico Estudios Gerenciales, vol. 35, núm. 152, 2019 Resumen: El objetivo del presente artículo fue identificar los determinantes de la Universidad Icesi conciencia de marca y el impacto que esta tiene en la comunicación boca a boca. Recepción: 10 Agosto 2018 El estudio se realizó usando la técnica de ecuaciones estructurales y los datos fueron Aprobación: 16 Septiembre 2019 recolectados a partir de una encuesta que se aplicó a la muestra validada, conformada por DOI: 10.18046/j.estger.2019.152.3108 208 usuarios de redes sociales en México. Los resultados confirmaron un efecto positivo y significativo de la calidad de la información en la conciencia de marca y, a su vez, se CC BY demostró el efecto directo de la conciencia de marca en la comunicación boca a boca. -
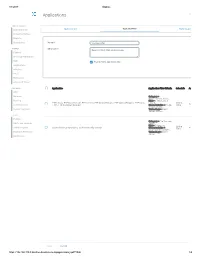
Applications Log Viewer
4/1/2017 Sophos Applications Log Viewer MONITOR & ANALYZE Control Center Application List Application Filter Traffic Shaping Default Current Activities Reports Diagnostics Name * Mike App Filter PROTECT Description Based on Block filter avoidance apps Firewall Intrusion Prevention Web Enable Micro App Discovery Applications Wireless Email Web Server Advanced Threat CONFIGURE Application Application Filter Criteria Schedule Action VPN Network Category = Infrastructure, Netw... Routing Risk = 1-Very Low, 2- FTPS-Data, FTP-DataTransfer, FTP-Control, FTP Delete Request, FTP Upload Request, FTP Base, Low, 4... All the Allow Authentication FTPS, FTP Download Request Characteristics = Prone Time to misuse, Tra... System Services Technology = Client Server, Netwo... SYSTEM Profiles Category = File Transfer, Hosts and Services Confe... Risk = 3-Medium Administration All the TeamViewer Conferencing, TeamViewer FileTransfer Characteristics = Time Allow Excessive Bandwidth,... Backup & Firmware Technology = Client Server Certificates Save Cancel https://192.168.110.3:4444/webconsole/webpages/index.jsp#71826 1/4 4/1/2017 Sophos Application Application Filter Criteria Schedule Action Applications Log Viewer Facebook Applications, Docstoc Website, Facebook Plugin, MySpace Website, MySpace.cn Website, Twitter Website, Facebook Website, Bebo Website, Classmates Website, LinkedIN Compose Webmail, Digg Web Login, Flickr Website, Flickr Web Upload, Friendfeed Web Login, MONITOR & ANALYZE Hootsuite Web Login, Friendster Web Login, Hi5 Website, Facebook Video -

Obtaining and Using Evidence from Social Networking Sites
U.S. Department of Justice Criminal Division Washington, D.C. 20530 CRM-200900732F MAR 3 2010 Mr. James Tucker Mr. Shane Witnov Electronic Frontier Foundation 454 Shotwell Street San Francisco, CA 94110 Dear Messrs Tucker and Witnov: This is an interim response to your request dated October 6, 2009 for access to records concerning "use of social networking websites (including, but not limited to Facebook, MySpace, Twitter, Flickr and other online social media) for investigative (criminal or otherwise) or data gathering purposes created since January 2003, including, but not limited to: 1) documents that contain information on the use of "fake identities" to "trick" users "into accepting a [government] official as friend" or otherwise provide information to he government as described in the Boston Globe article quoted above; 2) guides, manuals, policy statements, memoranda, presentations, or other materials explaining how government agents should collect information on social networking websites: 3) guides, manuals, policy statements, memoranda, presentations, or other materials, detailing how or when government agents may collect information through social networking websites; 4) guides, manuals, policy statements, memoranda, presentations and other materials detailing what procedures government agents must follow to collect information through social- networking websites; 5) guides, manuals, policy statements, memorandum, presentations, agreements (both formal and informal) with social-networking companies, or other materials relating to privileged user access by the Criminal Division to the social networking websites; 6) guides, manuals, memoranda, presentations or other materials for using any visualization programs, data analysis programs or tools used to analyze data gathered from social networks; 7) contracts, requests for proposals, or purchase orders for any visualization programs, data analysis programs or tools used to analyze data gathered from social networks. -

Social Media and Customer Engagement in Tourism: Evidence from Facebook Corporate Pages of Leading Cruise Companies
Social Media and Customer Engagement in Tourism: Evidence from Facebook Corporate Pages of Leading Cruise Companies Giovanni Satta, Francesco Parola, Nicoletta Buratti, Luca Persico Department of Economics and Business Studies and CIELI, University of Genoa, Italy, email: [email protected] (Corresponding author), [email protected], [email protected], [email protected] Roberto Viviani email: [email protected] Department of Economics and Business Studies, University of Genoa, Italy Abstract In the last decade, an increasing number of scholars has challenged the role of Social Media Marketing (SMM) in tourism. Indeed, Social Media (SM) provide undoubted opportunities for fostering firms’ relationships with their customers, and online customer engagement (CE) has become a common objective when developing communication strategies. Although extant literature appear very rich and heterogeneous, only a limited number of scholars have explored which kind of contents, media and posting day would engage tourists on social media. Hence, a relevant literature gap still persists, as tourism companies would greatly benefit from understanding how posting strategies on major social media may foster online CE. The paper investigates the antecedents of online CE in the tourism industry by addressing the posting activities of cruise companies on their Facebook pages. For this purpose, we scrutinize the impact of post content, format and timing on online CE, modelled as liking, commenting and sharing. In particular, we test the proposed model grounding on an empirical investigation performed on 982 Facebook posts uploaded by MSC Crociere (446), Costa Crociere (331) and Royal Caribbean Cruises (205) in a period of 12 month. -

The Example of Swedish Independent Music Fandom by Nancy K
First Monday Online groups are taking new forms as participants spread themselves amongst multiple Internet and offline platforms. The multinational online community of Swedish independent music fans exemplifies this trend. This participant–observation analysis of this fandom shows how sites are interlinked at multiple levels, and identifies several implications for theorists, researchers, developers, industry and independent professionals, and participants. Contents Introduction Fandom Swedish popular music The Swedish indie music fan community Discussion Conclusion Introduction The rise of social network sites is often taken to exemplify a shift from the interest–based online communities of the Web’s “first” incarnation to a new “Web 2.0” in which individuals are the basic unit, rather than communities. In a recent First Monday article, for instance, boyd (2006) states, “egocentric networks replace groups.” I argue that online groups have not been “replaced.” Even as their members build personal profiles and egocentric networks on MySpace, Facebook, BlackPlanet, Orkut, Bebo, and countless other emerging social network sites, online groups continue to thrive on Web boards, in multiplayer online games, and even on the all–but–forgotten Usenet. However, online communities are also taking a new form somewhere between the site-based online group and the egocentric network, distributing themselves throughout a variety of sites in a quasi–coherent networked fashion. This new form of distributed community poses particular problems for its members, developers, and analysts. This paper, based on over two years of participant–observation, describes this new shape of online community through a close look at the multinational online community of fans of independent rock music from Sweden. -

Twitter – a Personal Perspective
Twitter – a personal perspective Catriona Fisher Customer Services Manager University of Glasgow Library Email: catriona.fisher@glasgow. ac.uk twitter: @catrionafisher I joined Twitter in March 2009, but like most people I spent the first few months wondering what on earth this strange new world was all about. As a devoted user of Multiply, then Bebo and later Facebook, I was no stranger to social net- working, but Twitter was quite obviously some- thing different. I quickly realised the following: • you need your tweets to be public • the best way to get followers is to follow other people • hashtags are a must if you want your voice to be heard amongst the millions of tweets. I started out tweeting solely about work and had intended to have two accounts, one for work and a personal account (as I do with Facebook), but I quickly realised that many professionals on Twit- ter were tweeting about their work lives and their personal lives from the same account. This takes a bit of getting used to, but is very much the norm on Twitter. I now tweet from my own account @catrionafisher and also on behalf of the University of Glasgow Library @uofglibrary, along with a group of staff from Library Services. We’ve found Twitter to be a really powerful way of reaching out to students and other library users and it is now one of our primary channels of communication when we need to share informa- tion quickly. For example, we are using it to keep students up to date with any disruption during the work to re-clad the library building. -

NAS 232 Using Aifoto on Your Mobile Devices
NAS 232 Using AiFoto on Your Mobile Devices Manage photos on your NAS using your mobile device ASUSTOR COLLEGE NAS 232: Using AiFoto on Your Mobile Devices Devices COURSE OBJECTIVES Upon completion of this course you should be able to: 1. Use AiFoto to manage photos and albums on your NAS and mobile device. PREREQUISITES Course Prerequisites: NAS 137: Introduction to Photo Gallery Students are expected to have a working knowledge of: N/A OUTLINE 1. Introduction to AiFoto 1.1 Introduction to AiFoto 2. Basic Functions 2.1 Settings and instructions 2.2 Connecting to your NAS with AiFoto 2.3 Browsing photos with AiFoto 3. Managing albums and photos 3.1 Album management 3.1.1 Creating albums 3.1.2 Editing album information 3.1.3 Deleting albums 3.1.4 Uploading and downloading albums 3.2 Photo management ASUSTOR COLLEGE / 2 NAS 232: Using AiFoto on Your Mobile Devices Devices 3.3 Using Camera Mode 3.4 Uploading your local camera roll to your NAS 3.5 Privacy settings 4. Notes ASUSTOR COLLEGE / 3 NAS 232: Using AiFoto on Your Mobile Devices Devices 1. Introduction to AiFoto 1.1 Introduction to AiFoto AiFoto lets you access Photo Gallery from your ASUSTOR NAS on your mobile device! With AiFoto you can user your mobile device to browse and manage your NAS web photo albums and instantly upload photos from your mobile device camera roll to your NAS. AiFoto also provides you with a Camera Mode allowing you to specify an album and then have any photos you take automatically uploaded to the album. -

How to Update Your Personal Profile on the Centre's Website?
How to update your personal profile on the Centre’s website? www.coralcoe.org.au WordPress software is used to update the Centre website. Before you proceed it’s easier to write up a draft in your favourite word processor (e.g. Microsoft Word) using the templates provided p7 and 8, with the selected headings. If you are a researcher, have a look at existing profiles in http://www.coralcoe.org.au/person_type/researchers for inspiration. If you are a student, have a look at existing profiles in http://www.coralcoe.org.au/person_type/students for inspiration. 1 STEP 1: Find your profile page Choose one of the two options below Option 1 1. Open up the ARC's new website: www.coralcoe.org.au 2. Find your existing profile in www.coralcoe.org.au/person_type/researchers and click on ‘VIEW PROFILE’. If your profile is not already on the website, please contact the communications manager ([email protected]) to create one. 3. Click ‘MEMBER LOGIN’ on the top right corner of the window 4. Log in using previous login details and password. - You don’t have a login and password? Please contact the communications manager ([email protected]). - Lost your password? Click ‘LOST YOUR PASSWORD?’ and follow the prompt. 5. Click on ‘Edit Person’ on the top menu. You can now edit your profile. 2 Option 2 1. Open up the ARC's new website: www.coralcoe.org.au 2. Click ‘MEMBER LOGIN’ on the top right corner of the window 3. Log in using previous login details and password. -

Systematic Scoping Review on Social Media Monitoring Methods and Interventions Relating to Vaccine Hesitancy
TECHNICAL REPORT Systematic scoping review on social media monitoring methods and interventions relating to vaccine hesitancy www.ecdc.europa.eu ECDC TECHNICAL REPORT Systematic scoping review on social media monitoring methods and interventions relating to vaccine hesitancy This report was commissioned by the European Centre for Disease Prevention and Control (ECDC) and coordinated by Kate Olsson with the support of Judit Takács. The scoping review was performed by researchers from the Vaccine Confidence Project, at the London School of Hygiene & Tropical Medicine (contract number ECD8894). Authors: Emilie Karafillakis, Clarissa Simas, Sam Martin, Sara Dada, Heidi Larson. Acknowledgements ECDC would like to acknowledge contributions to the project from the expert reviewers: Dan Arthus, University College London; Maged N Kamel Boulos, University of the Highlands and Islands, Sandra Alexiu, GP Association Bucharest and Franklin Apfel and Sabrina Cecconi, World Health Communication Associates. ECDC would also like to acknowledge ECDC colleagues who reviewed and contributed to the document: John Kinsman, Andrea Würz and Marybelle Stryk. Suggested citation: European Centre for Disease Prevention and Control. Systematic scoping review on social media monitoring methods and interventions relating to vaccine hesitancy. Stockholm: ECDC; 2020. Stockholm, February 2020 ISBN 978-92-9498-452-4 doi: 10.2900/260624 Catalogue number TQ-04-20-076-EN-N © European Centre for Disease Prevention and Control, 2020 Reproduction is authorised, provided the -
Looks at Marathon Station Possibilities County
Single copy $1.00 Vol. 113 No. 3 • Thursday, January 9, 2014 • Silver Lake, MN 55381 Council reorganizes; looks at Marathon Station possibilities By Alyssa Schauer sary liaison: Councilor John- departmental employees so Staff Writer son. that he or she can update the At its first meeting of the • Community development Council as to the workings of year, the Silver Lake City and planning commission liai- the assigned area and report on Council discussed Mayor son: Councilor Eric Nelson. the departments budget Bruce Bebo’s liaison appoint- • Assistant to all liaisons: throughout the year.” ments and other annual ap- Mayor Bebo. Bebo also noted the plan- pointments for 2014. The regular meeting dates ning commission liaison is to The following appointments and times also were set and meet with Gary Kosek, direc- were recommended and ap- regular Council meetings will tor of pool operations and proved by the Council: be the third Monday of every summer recreation, as part of • Official city depositories: month at 6:30 p.m. Meetings the community development First Community Bank of Sil- scheduled on federal holidays portion of liaison duties. ver Lake and Minnesota Mu- will be held Tuesday. Venier also noted that the li- nicipal Money Market Fund. Quarterly meetings were aison acts as a “leader” or • Official newspaper: Silver scheduled for April 7, July 7 “guide” for the planning com- Lake Leader. and Oct. 6. mission. • City attorney: Gavin, Members of the City Coun- “The commission has been Olson & Winters, LTD. cil are appointed to the eco- missing that leader in the past • Acting mayor: Councilor nomic development authority, year.