Content-Prioritised Video Coding for British Sign Language Communication
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Role of Stereopsis Losses in Older Adults’ Performance
ROLE OF STEREOPSIS LOSSES IN OLDER ADULTS’ PERFORMANCE ON THE FINE-GRAIN MOVEMENT ILLUSION TASK by Marlena Pearson Honours Bachelor of Science, Psychology, Nipissing University, North Bay, Ontario, 2014 Honours Bachelor of Arts, Criminal Justice, Nipissing University, North Bay, Ontario, 2014 A thesis presented to Ryerson University in partial fulfillment of the requirement for the degree of Master of Arts in the program of Psychology Toronto, Ontario, Canada, 2017 © Marlena Pearson, 2017 Author’s Declaration AUTHOR'S DECLARATION FOR ELECTRONIC SUBMISSION OF A THESIS I hereby declare that I am the sole author of this thesis. This is a true copy of the thesis, including any required final revisions, as accepted by my examiners. I authorize Ryerson University to lend this thesis to other institutions or individuals for the purpose of scholarly research I further authorize Ryerson University to reproduce this thesis by photocopying or by other means, in total or in part, at the request of other institutions or individuals for the purpose of scholarly research. I understand that my thesis may be made electronically available to the public. ii Role of Stereopsis Losses in Older Adults’ Performance on the Fine-Grain Movement Illusion Task Master of Arts, 2017 Marlena Pearson Psychology, Ryerson University Abstract Accurate motion perception is necessary for older adults to safely navigate their environments. Yet it is not clear how stereopsis losses contribute to findings of motion perception deficits in older adults. To assess the contribution of stereopsis losses, three groups (younger adults, older adults with intact stereopsis, older adults with poor stereopsis) were recruited for a fine-grain movement task. -

Polarity Selectivity of Spatial Interactions in Perceived Contrast
Journal of Vision (2012) 12(2):3, 1–10 http://www.journalofvision.org/content/12/2/3 1 Polarity selectivity of spatial interactions in perceived contrast Department of Psychology, The University of Tokyo, Japan,& Human and Information Science Laboratory, Hiromi Sato NTT Communication Science Laboratories, NTT, Japan Human and Information Science Laboratory, Isamu Motoyoshi NTT Communication Science Laboratories, NTT, Japan Department of Psychology, Takao Sato The University of Tokyo, Japan The apparent contrast of a texture is reduced when surrounded by another texture with high contrast. This contrast–contrast phenomenon has been thought to be a result of spatial interactions between visual channels that encode contrast energy. In the present study, we show that contrast–contrast is selective to luminance polarity by using texture patterns composed of sparse elongated blobs. The apparent contrast of a texture of bright (dark) elements was substantially reduced only when it was surrounded by a texture of elements with the same polarity. This polarity specificity was not evident for textures with high element densities, which were similar to those used in previous studies, probably because such stimuli should inevitably activate both on- and off-type sensors. We also found that polarity-selective suppression decreased as the difference in orientation between the center and surround elements increased but remained for orthogonally oriented elements. These results suggest that the contrast–contrast illusion largely depends on spatial interactions between visual channels that are selective to on–off polarity and only weakly selective to orientation. Keywords: polarity selectivity, spatial interactions, perceived contrast Citation: Sato, H., Motoyoshi, I., & Sato, T. -

Visual Context Processing in Schizophrenia
Empirical Article Clinical Psychological Science 1(1) 5 –15 Visual Context Processing in Schizophrenia © The Author(s) 2013 Reprints and permission: sagepub.com/journalsPermissions.nav DOI: 10.1177/2167702612464618 http://cpx.sagepub.com Eunice Yang1,2, Duje Tadin3,4, Davis M. Glasser3, Sang Wook Hong1,5, Randolph Blake1,2, and Sohee Park1 1Department of Psychology, Vanderbilt University; 2Department of Brain and Cognitive Sciences, Seoul National University, Republic of Korea; 3Center for Visual Science and Department of Brain and Cognitive Sciences, University of Rochester; 4Department of Ophthalmology, University of Rochester; and 5Department of Psychology, Florida Atlantic University Abstract Abnormal perceptual experiences are central to schizophrenia, but the nature of these anomalies remains undetermined. We investigated contextual processing abnormalities across a comprehensive set of visual tasks. For perception of luminance, size, contrast, orientation, and motion, we quantified the degree to which the surrounding visual context altered a center stimulus’s appearance. Healthy participants showed robust contextual effects across all tasks, as evidenced by pronounced misperceptions of center stimuli. Schizophrenia patients exhibited intact contextual modulations of luminance and size but showed weakened contextual modulations of contrast, performing more accurately than controls. Strong motion and orientation context effects correlated with worse symptoms and social functioning. Importantly, the overall strength of contextual -

Download Thesis
This electronic thesis or dissertation has been downloaded from the King’s Research Portal at https://kclpure.kcl.ac.uk/portal/ Contextual Processing in Psychosis and Cannabis use Kane, Fergus Awarding institution: King's College London The copyright of this thesis rests with the author and no quotation from it or information derived from it may be published without proper acknowledgement. END USER LICENCE AGREEMENT Unless another licence is stated on the immediately following page this work is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International licence. https://creativecommons.org/licenses/by-nc-nd/4.0/ You are free to copy, distribute and transmit the work Under the following conditions: Attribution: You must attribute the work in the manner specified by the author (but not in any way that suggests that they endorse you or your use of the work). Non Commercial: You may not use this work for commercial purposes. No Derivative Works - You may not alter, transform, or build upon this work. Any of these conditions can be waived if you receive permission from the author. Your fair dealings and other rights are in no way affected by the above. Take down policy If you believe that this document breaches copyright please contact [email protected] providing details, and we will remove access to the work immediately and investigate your claim. Download date: 05. Oct. 2021 This electronic theses or dissertation has been downloaded from the King’s Research Portal at https://kclpure.kcl.ac.uk/portal/ Title: Contextual Processing in Psychosis and Cannabis use Author: Kane, Fergus The copyright of this thesis rests with the author and no quotation from it or information derived from it may be published without proper acknowledgement. -
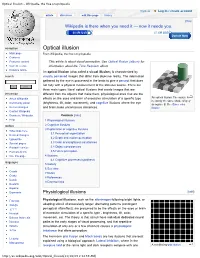
Optical Illusion - Wikipedia, the Free Encyclopedia
Optical illusion - Wikipedia, the free encyclopedia Try Beta Log in / create account article discussion edit this page history [Hide] Wikipedia is there when you need it — now it needs you. $0.6M USD $7.5M USD Donate Now navigation Optical illusion Main page From Wikipedia, the free encyclopedia Contents Featured content This article is about visual perception. See Optical Illusion (album) for Current events information about the Time Requiem album. Random article An optical illusion (also called a visual illusion) is characterized by search visually perceived images that differ from objective reality. The information gathered by the eye is processed in the brain to give a percept that does not tally with a physical measurement of the stimulus source. There are three main types: literal optical illusions that create images that are interaction different from the objects that make them, physiological ones that are the An optical illusion. The square A About Wikipedia effects on the eyes and brain of excessive stimulation of a specific type is exactly the same shade of grey Community portal (brightness, tilt, color, movement), and cognitive illusions where the eye as square B. See Same color Recent changes and brain make unconscious inferences. illusion Contact Wikipedia Donate to Wikipedia Contents [hide] Help 1 Physiological illusions toolbox 2 Cognitive illusions 3 Explanation of cognitive illusions What links here 3.1 Perceptual organization Related changes 3.2 Depth and motion perception Upload file Special pages 3.3 Color and brightness -

Gaze-Contingent Visual Communication
GAZE-CONTINGENT VISUAL COMMUNICATION A Dissertation by ANDREW TED DUCHOWSKI Submitted to the Office of Graduate Studies of Texas A&M University in partial fulfillment of the requirements for the degree of DOCTOR OF PHILOSOPHY August 1997 Major Subject: Computer Science GAZE-CONTINGENT VISUAL COMMUNICATION A Dissertation by ANDREW TED DUCHOWSKI Submitted to Texas A&M University in partial fulfillment of the requirements for the degree of DOCTOR OF PHILOSOPHY Approved as to style and content by: Bruce H. McCormick Udo W. Pooch (Chair of Committee) (Member) John J. Leggett Norman C. Griswold (Member) (Member) Wayne L. Shebilske Richard A. Volz (Member) (Head of Department) August 1997 Major Subject: Computer Science iii ABSTRACT Gaze-Contingent Visual Communication. (August 1997) Andrew Ted Duchowski, B.Sc., Simon Fraser University Chair of Advisory Committee: Dr. Bruce H. McCormick Virtual environments today lack realism. Real-time display of visually rich scenery is encumbered by the demand of rendering excessive amounts of information. This problem is especially severe in virtual reality. To minimize refresh latency, image quality is often sacrificed for speed. What’s missing is knowledge of the participant’s locus of visual attention, and an understanding of how an individual scans the visual field. Neurophysiological and psychophysical literature on the human visual system suggests the field of view is inspected minutatim through brief fixations over small regions of interest. Significant savings in scene pro- cessing can be realized if fine detail information is presented “just in time” in a gaze-contingent manner, delivering only as much information as required by the viewer. An attentive model of vision is proposed where Volumes Of Interest (VOIs) represent fixations through time. -

Analysis of the Mechanisms of Human Visual Processing
Christopher W . Tyler, Ph.D. Analysis of the Mechanisms of Human Visual Processing Christopher W. Tyler, Ph.D. Smith-Kettlewell Eye Research Institute 2318 Fillmore Street San Francisco, CA 94115, USA. Application for the degree of Doctor of Science University of Keele 1 Christopher W . Tyler, Ph.D. Education: Institution Degree Conferred Field of Study University of Leicester, U.K. B.A. 1966 Psychology University of Aston, U.K. M.Sc. 1967 Applied Psychology University of Keele, U.K. Ph.D. 1970 Communications Reseach and Professional Experience: 1990-2003 Associate Director, Smith-Kettlewell Eye Res. Institute, San Francisco, CA. 1981- Senior Scientist, Smith-Kettlewell Eye Res. Institute, San Francisco, CA. 1977- External Doctoral Thesis Advisor, Dept. of Psychology, University of California, Berkeley. 1986-87 Adjunct Professor, School of Optometry, University of California, Berkeley. 1985-89 Visiting Professor, UCLA Medical Center, Jules Stein Institute. 1978-80 External Doctoral Thesis Advisor, Dept. of Psychology, Stanford University, Stanford, CA. 1978-82 Honorary Res. Associate, Institute of Ophthalmology, London, U.K. 1975-81 Scientist, Smith-Kettlewell Eye Res. Institute, San Francisco, CA. 1974-75 Res. Fellow, Dept. of Sensory and Perceptual Processes, Bell Laboratories, Murray Hill, NJ. 1973-74 Res. Fellow, Dept. of Psychology, University of Bristol, U.K. 1972-73 Assistant Professor, Northeastern University, Boston, MA. (Psychology Courses: Experimental, Introductory, History, Social Issues, Vision). 1972 Visiting Assistant Professor, Dept. of Psychology, University of California, Los Angeles, CA. (Course: Perception). 1970-72 Res. Fellow, Dept. of Psychology, Northeastern University, Boston, MA. Dissertations M.Sc. A study of the electrical activity of the brain in a simple decision task. -

Free-Energy and Illusions: the Cornsweet Effect 058 002 059 003 060 004 Harriet Brown* and Karl J
ORIGINAL RESEARCH ARTICLE published: xx February 2012 doi: 10.3389/fpsyg.2012.00043 001 Free-energy and illusions: the Cornsweet effect 058 002 059 003 060 004 Harriet Brown* and Karl J. Friston 061 005 The Wellcome Trust Centre for Neuroimaging, University College London Queen Square, London, UK 062 006 063 007 064 Edited by: 008 In this paper, we review the nature of illusions using the free-energy formulation of Bayesian 065 Lars Muckli, University of Glasgow, perception. We reiterate the notion that illusory percepts are, in fact, Bayes-optimal and 009 UK 066 010 represent the most likely explanation for ambiguous sensory input. This point is illustrated 067 Reviewed by: 011 Gerrit W. Maus, University of using perhaps the simplest of visual illusions; namely, the Cornsweet effect. By using 068 012 California at Berkeley, USA plausible prior beliefs about the spatial gradients of illuminance and reflectance in visual 069 013 Peter De Weerd, Maastricht scenes, we show that the Cornsweet effect emerges as a natural consequence of Bayes- 070 University, Netherlands 014 optimal perception. Furthermore, we were able to simulate the appearance of secondary 071 015 *Correspondence: illusory percepts (Mach bands) as a function of stimulus contrast. The contrast-dependent 072 Harriet Brown, Wellcome Trust Centre 016 073 for Neuroimaging, Institute of emergence of the Cornsweet effect and subsequent appearance of Mach bands were 017 Neurology Queen Square, London simulated using a simple but plausible generative model. Because our generative model 074 018 WC1N 3BG, UK. was inverted using a neurobiologically plausible scheme, we could use the inversion as a 075 019 e-mail: [email protected] simulation of neuronal processing and implicit inference. -

Typical Lateral Interactions, but Increased Contrast Sensitivity, in Migraine-With-Aura
vision Article Typical Lateral Interactions, but Increased Contrast Sensitivity, in Migraine-With-Aura Jordi M. Asher 1,* ID , Louise O’Hare 2 ID , Vincenzo Romei 1,3 and Paul B. Hibbard 1 1 Department of Psychology, University of Essex, Wivenhoe Park, Colchester CO4 3SQ, UK; [email protected] (V.R.); [email protected] (P.B.H.) 2 Faculty of Health and Social Sciences, Lincoln University, Brayford Way, Brayford Pool, Lincoln LN6 7TS, UK; [email protected] 3 Dipartimento di Psicologia and Centro studi e Ricerche in Neuroscienze Cognitive, Università di Bologna, Campus di Cesena, 47521 Cesena, Italy * Correspondence: [email protected] Received: 19 December 2017; Accepted: 7 February 2018; Published: 9 February 2018 Abstract: Individuals with migraine show differences in visual perception compared to control groups. It has been suggested that differences in lateral interactions between neurons might account for some of these differences. This study seeks to further establish the strength and spatial extent of excitatory and inhibitory interactions in migraine-with-aura using a classic lateral masking task. Observers indicated which of two intervals contained a centrally presented, vertical Gabor target of varying contrast. In separate blocks of trials, the target was presented alone or was flanked by two additional collinear, high contrast Gabors. Flanker distances varied between 1 and 12 wavelengths of the Gabor stimuli. Overall, contrast thresholds for the migraine group were lower than those in the control group. There was no difference in the degree of lateral interaction in the migraine group. These results are consistent with the previous work showing enhanced contrast sensitivity in migraine-with-aura for small, rapidly presented targets, and they suggest that impaired performance in global perceptual tasks in migraine may be attributed to difficulties in segmenting relevant from irrelevant features, rather than altered local mechanisms. -

Do Illiterates Have Illusions? a Conceptual (Non)Replication of Luria (1976)
J Cult Cogn Sci (2021) 5:143–158 https://doi.org/10.1007/s41809-021-00080-x (0123456789().,-volV)( 0123456789().,-volV) RESEARCH PAPER Do illiterates have illusions? A conceptual (non)replication of Luria (1976) Mrudula Arunkumar . Jeroen van Paridon . Markus Ostarek . Falk Huettig Received: 17 February 2021 / Revised: 17 February 2021 / Accepted: 21 May 2021 / Published online: 1 June 2021 Ó The Author(s) 2021 Abstract Luria (Luria, Cognitive development: Its Keywords Culture Á Literacy Á Visual perception Á cultural and social foundations, Harvard University Visual illusions Press, 1976) famously observed that people who never learnt to read and write do not perceive visual illusions. We conducted a conceptual replication of the Luria study of the effect of literacy on the Introduction processing of visual illusions. We designed two carefully controlled experiments with 161 participants Psychology, the study of human behavior, is not with varying literacy levels ranging from complete immune to the influences of Zeitgeist and the domi- illiterates to high literates in Chennai, India. Accuracy nant political movements and ideologies of the time. and reaction time in the identification of visual shape The history of psychology in the 1920s and 30 s and color illusions and the identification of appropriate includes dark chapters such as the eugenic movement, control images were measured. Separate statistical which aimed to provide (pseudo)scientific explana- analyses of Experiments 1 and 2 as well as pooled tions for the claim that desirable qualities are hered- analyses of both experiments do not provide any itary traits to justify white supremacy and scientific support for the notion that literacy affects the percep- racism. -

Polarity Selectivity of Spatial Interactions in Perceived Contrast
Journal of Vision (2012) 12(2):3, 1–10 http://www.journalofvision.org/content/12/2/3 1 Polarity selectivity of spatial interactions in perceived contrast Department of Psychology, The University of Tokyo, Japan,& Human and Information Science Laboratory, Hiromi Sato NTT Communication Science Laboratories, NTT, Japan Human and Information Science Laboratory, Isamu Motoyoshi NTT Communication Science Laboratories, NTT, Japan Department of Psychology, Takao Sato The University of Tokyo, Japan The apparent contrast of a texture is reduced when surrounded by another texture with high contrast. This contrast–contrast phenomenon has been thought to be a result of spatial interactions between visual channels that encode contrast energy. In the present study, we show that contrast–contrast is selective to luminance polarity by using texture patterns composed of sparse elongated blobs. The apparent contrast of a texture of bright (dark) elements was substantially reduced only when it was surrounded by a texture of elements with the same polarity. This polarity specificity was not evident for textures with high element densities, which were similar to those used in previous studies, probably because such stimuli should inevitably activate both on- and off-type sensors. We also found that polarity-selective suppression decreased as the difference in orientation between the center and surround elements increased but remained for orthogonally oriented elements. These results suggest that the contrast–contrast illusion largely depends on spatial interactions between visual channels that are selective to on–off polarity and only weakly selective to orientation. Keywords: polarity selectivity, spatial interactions, perceived contrast Citation: Sato, H., Motoyoshi, I., & Sato, T. -

1 Daily Vision Testing Can Expose the Prodromal Phase of Migraine
Daily vision testing can expose the prodromal phase of migraine. Allison M. McKendrick1, Yu Man Chan1, Algis J Vingrys1, Andrew Turpin2, David R Badcock3 1 University of Melbourne, Department of Optometry and Vision Sciences, Melbourne, Australia 2 University of Melbourne, Department of Computing and Information System, Melbourne, Australia 3 University of Western Australia, School of Psychological Science, Perth, Australia Funding: Project supported by Australian National Health and Medical Research Council Project Grant APPID1081874 1 Abstract Background: Several visual tasks have been proposed as indirect assays of the balance between cortical inhibition and excitation in migraine. This study aimed to determine whether daily measurement of performance on such tasks can reveal perceptual changes in the build up to migraine events. Methods: Visual performance was measured daily at home in 16 non-headache controls and 18 individuals with migraine using a testing protocol on a portable tablet device. Observers performed two tasks: luminance increment detection in spatial luminance noise and centre surround contrast suppression. Results Luminance thresholds were reduced in migraine compared to control groups (p<0.05), but thresholds did not alter across the migraine cycle. While headache-free, centre-surround contrast suppression was stronger for the migraine group relative to controls (p<0.05). Surround suppression weakened at around 48 hours prior to a migraine attack and strengthened to approach their headache-free by 24 hours post-migraine (main effect of timing, p<0.05). Conclusions: Daily portable testing of vision enabled insight to perceptual performance in the lead up to migraine events, a time point that is typically difficult to capture experimentally.