N Rn N 2 February 2012 (02.02.2012) / A
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Strategies to Increase ß-Cell Mass Expansion
This electronic thesis or dissertation has been downloaded from the King’s Research Portal at https://kclpure.kcl.ac.uk/portal/ Strategies to increase -cell mass expansion Drynda, Robert Lech Awarding institution: King's College London The copyright of this thesis rests with the author and no quotation from it or information derived from it may be published without proper acknowledgement. END USER LICENCE AGREEMENT Unless another licence is stated on the immediately following page this work is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International licence. https://creativecommons.org/licenses/by-nc-nd/4.0/ You are free to copy, distribute and transmit the work Under the following conditions: Attribution: You must attribute the work in the manner specified by the author (but not in any way that suggests that they endorse you or your use of the work). Non Commercial: You may not use this work for commercial purposes. No Derivative Works - You may not alter, transform, or build upon this work. Any of these conditions can be waived if you receive permission from the author. Your fair dealings and other rights are in no way affected by the above. Take down policy If you believe that this document breaches copyright please contact [email protected] providing details, and we will remove access to the work immediately and investigate your claim. Download date: 02. Oct. 2021 Strategies to increase β-cell mass expansion A thesis submitted by Robert Drynda For the degree of Doctor of Philosophy from King’s College London Diabetes Research Group Division of Diabetes & Nutritional Sciences Faculty of Life Sciences & Medicine King’s College London 2017 Table of contents Table of contents ................................................................................................. -

Stabilization of G Protein-Coupled Receptors by Point Mutations
REVIEW published: 20 April 2015 doi: 10.3389/fphar.2015.00082 Stabilization of G protein-coupled receptors by point mutations Franziska M. Heydenreich 1, 2 †, Ziva Vuckovic 1, 2 †, Milos Matkovic 1, 2 and Dmitry B. Veprintsev 1, 2* 1 Laboratory of Biomolecular Research, Paul Scherrer Institut, Villigen, Switzerland, 2 Department of Biology, ETH Zürich, Zürich, Switzerland G protein-coupled receptors (GPCRs) are flexible integral membrane proteins involved in transmembrane signaling. Their involvement in many physiological processes makes Edited by: Claudio M. Costa-Neto, them interesting targets for drug development. Determination of the structure of University of Sao Paulo, Brazil these receptors will help to design more specific drugs, however, their structural Reviewed by: characterization has so far been hampered by the low expression and their inherent Daniel James Scott, The University of Melbourne, Australia instability in detergents which made protein engineering indispensable for structural and Philippe Rondard, biophysical characterization. Several approaches to stabilize the receptors in a particular Centre National de la Recherche conformation have led to breakthroughs in GPCR structure determination. These include Scientifique/Institut National de la Santé et de la Recherche Médicale, truncations of the flexible regions, stabilization by antibodies and nanobodies, fusion France partners, high affinity and covalently bound ligands as well as conformational stabilization Guillaume Lebon, Centre National de la Recherche by mutagenesis. In this review we focus on stabilization of GPCRs by insertion of Scientifique, France point mutations, which lead to increased conformational and thermal stability as well as *Correspondence: improved expression levels. We summarize existing mutagenesis strategies with different Dmitry B. Veprintsev, coverage of GPCR sequence space and depth of information, design and transferability Laboratory of Biomolecular Research, Switzerland, Department of Biology, of mutations and the molecular basis for stabilization. -

Investigation of Candidate Genes and Mechanisms Underlying Obesity
Prashanth et al. BMC Endocrine Disorders (2021) 21:80 https://doi.org/10.1186/s12902-021-00718-5 RESEARCH ARTICLE Open Access Investigation of candidate genes and mechanisms underlying obesity associated type 2 diabetes mellitus using bioinformatics analysis and screening of small drug molecules G. Prashanth1 , Basavaraj Vastrad2 , Anandkumar Tengli3 , Chanabasayya Vastrad4* and Iranna Kotturshetti5 Abstract Background: Obesity associated type 2 diabetes mellitus is a metabolic disorder ; however, the etiology of obesity associated type 2 diabetes mellitus remains largely unknown. There is an urgent need to further broaden the understanding of the molecular mechanism associated in obesity associated type 2 diabetes mellitus. Methods: To screen the differentially expressed genes (DEGs) that might play essential roles in obesity associated type 2 diabetes mellitus, the publicly available expression profiling by high throughput sequencing data (GSE143319) was downloaded and screened for DEGs. Then, Gene Ontology (GO) and REACTOME pathway enrichment analysis were performed. The protein - protein interaction network, miRNA - target genes regulatory network and TF-target gene regulatory network were constructed and analyzed for identification of hub and target genes. The hub genes were validated by receiver operating characteristic (ROC) curve analysis and RT- PCR analysis. Finally, a molecular docking study was performed on over expressed proteins to predict the target small drug molecules. Results: A total of 820 DEGs were identified between -
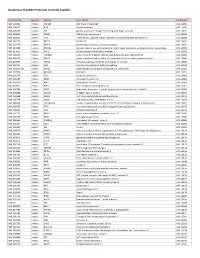
Quantigene Flowrna Probe Sets Currently Available
QuantiGene FlowRNA Probe Sets Currently Available Accession No. Species Symbol Gene Name Catalog No. NM_003452 Human ZNF189 zinc finger protein 189 VA1-10009 NM_000057 Human BLM Bloom syndrome VA1-10010 NM_005269 Human GLI glioma-associated oncogene homolog (zinc finger protein) VA1-10011 NM_002614 Human PDZK1 PDZ domain containing 1 VA1-10015 NM_003225 Human TFF1 Trefoil factor 1 (breast cancer, estrogen-inducible sequence expressed in) VA1-10016 NM_002276 Human KRT19 keratin 19 VA1-10022 NM_002659 Human PLAUR plasminogen activator, urokinase receptor VA1-10025 NM_017669 Human ERCC6L excision repair cross-complementing rodent repair deficiency, complementation group 6-like VA1-10029 NM_017699 Human SIDT1 SID1 transmembrane family, member 1 VA1-10032 NM_000077 Human CDKN2A cyclin-dependent kinase inhibitor 2A (melanoma, p16, inhibits CDK4) VA1-10040 NM_003150 Human STAT3 signal transducer and activator of transcripton 3 (acute-phase response factor) VA1-10046 NM_004707 Human ATG12 ATG12 autophagy related 12 homolog (S. cerevisiae) VA1-10047 NM_000737 Human CGB chorionic gonadotropin, beta polypeptide VA1-10048 NM_001017420 Human ESCO2 establishment of cohesion 1 homolog 2 (S. cerevisiae) VA1-10050 NM_197978 Human HEMGN hemogen VA1-10051 NM_001738 Human CA1 Carbonic anhydrase I VA1-10052 NM_000184 Human HBG2 Hemoglobin, gamma G VA1-10053 NM_005330 Human HBE1 Hemoglobin, epsilon 1 VA1-10054 NR_003367 Human PVT1 Pvt1 oncogene homolog (mouse) VA1-10061 NM_000454 Human SOD1 Superoxide dismutase 1, soluble (amyotrophic lateral sclerosis 1 (adult)) -

Characterisation, Localisation and Expression of Porcine TACR1, TACR2 and TACR3 Genes
Veterinarni Medicina, 62, 2017 (08): 443–455 Original Paper doi: 10.17221/23/2017-VETMED Characterisation, localisation and expression of porcine TACR1, TACR2 and TACR3 genes A. Jakimiuk*, P. Podlasz, M. Chmielewska-Krzesinska, K. Wasowicz Faculty of Veterinary Medicine, University of Warmia and Mazury in Olsztyn, Olsztyn, Poland *Corresponding author: [email protected] ABSTRACT: Substance P is involved in many physiological and pathophysiological processes. This functional diversity is mediated by three neurokinin receptor subtypes (NK1R, NK2R and NK3R) encoded by the TACR1, TACR2 and TACR3 genes, respectively. Despite the increasing interest in using pigs (Sus scrofa) to study human disease mechanisms, the sequences of these receptors are still unconfirmed or in the case of the NK1 receptor, not yet even unpredicted. We employed in silico analysis to define the localisation of the porcine tachykinin receptor genes, and to predict the structures and amino acid sequences of the respective proteins. A reverse transcription polymerase chain reaction (RT-PCR) assay was performed to analyse the expression of tachykinin receptor genes in different porcine tissues. The data show that the TACR1 gene is located on chromosome 3, TACR2 on chromo- some 14 and TACR3 on chromosome 8. All three genes encode proteins with structures that incorporate features of G-protein-coupled receptors with sizes of 407, 381 and 464 amino acids, respectively. The receptors display a high degree of similarity to other mammalian neurokinin receptors. The NK1R subtype is expressed in both the central nervous system and peripheral tissues, while NK2R expression seems to be localised mostly to peripheral tissues. The expression of NK3R is found mainly in the central nervous system. -

The Significance of NK1 Receptor Ligands and Their Application In
pharmaceutics Review The Significance of NK1 Receptor Ligands and Their Application in Targeted Radionuclide Tumour Therapy Agnieszka Majkowska-Pilip * , Paweł Krzysztof Halik and Ewa Gniazdowska Centre of Radiochemistry and Nuclear Chemistry, Institute of Nuclear Chemistry and Technology, Dorodna 16, 03-195 Warsaw, Poland * Correspondence: [email protected]; Tel.: +48-22-504-10-11 Received: 7 June 2019; Accepted: 16 August 2019; Published: 1 September 2019 Abstract: To date, our understanding of the Substance P (SP) and neurokinin 1 receptor (NK1R) system shows intricate relations between human physiology and disease occurrence or progression. Within the oncological field, overexpression of NK1R and this SP/NK1R system have been implicated in cancer cell progression and poor overall prognosis. This review focuses on providing an update on the current state of knowledge around the wide spectrum of NK1R ligands and applications of radioligands as radiopharmaceuticals. In this review, data concerning both the chemical and biological aspects of peptide and nonpeptide ligands as agonists or antagonists in classical and nuclear medicine, are presented and discussed. However, the research presented here is primarily focused on NK1R nonpeptide antagonistic ligands and the potential application of SP/NK1R system in targeted radionuclide tumour therapy. Keywords: neurokinin 1 receptor; Substance P; SP analogues; NK1R antagonists; targeted therapy; radioligands; tumour therapy; PET imaging 1. Introduction Neurokinin 1 receptor (NK1R), also known as tachykinin receptor 1 (TACR1), belongs to the tachykinin receptor subfamily of G protein-coupled receptors (GPCRs), also called seven-transmembrane domain receptors (Figure1)[ 1–3]. The human NK1 receptor structure [4] is available in Protein Data Bank (6E59). -

Hypothalamic Regulation of Food Intake During Cancer
Hypothalamic regulation of food intake during cancer Jvalini Dwarkasing Thesis committee Promotor Prof. Dr R.F. Witkamp Professor of Nutrition and Pharmacology Wageningen University Co-promotors Dr K. van Norren Assistant professor, Division of Human Nutrition Wageningen University Dr M.V. Boekschoten Staff scientist, Division of Human Nutrition Wageningen University Other members Prof. Dr J. Mercer, University of Aberdeen, UK Prof. Dr D. Chen, Norwegian university of science and technology, Trondheim, Norway Prof. Dr E. Kampman, Wageningen University Prof. Dr J. Keijer, Wageningen University This research was conducted under the auspices of the Graduate School VLAG (Ad- vanced studies in Food Technology, Agrobiotechnology, Nutrition and Health Sciences). Hypothalamic regulation of food intake during cancer Jvalini Dwarkasing Thesis submitted in fulfilment of the requirements for the degree of doctor at Wageningen University by the authority of the Rector Magnificus Prof. Dr A.P.J. Mol, in the presence of the Thesis Committee appointed by the Academic Board to be defended in public on Wednesday 11 November 2015 at 4 p.m. in the Aula. Jvalini Dwarkasing Hypothalamic regulation of food intake during cancer 148 pages PhD thesis, Wageningen University, Wageningen, NL (2015) With references, with summaries in Dutch and English ISBN 978-94-6257-548-6 Summary Appetite is often reduced in patients with chronic illness, including cancer. Cancer anorexia, loss of appetite, frequently co-exists with cachexia, and the combined clinical picture is known as anorexia-cachexia syndrome. In patients suffering from this syndrome, anorexia considerably contributes to the progression of cachexia, and strongly impinges on quality of life. Inflammatory processes in the hypothalamus are considered to play a crucial role in the development of disease-related anorexia. -

Supplementary Table 2
Supplementary Table 2. Differentially Expressed Genes following Sham treatment relative to Untreated Controls Fold Change Accession Name Symbol 3 h 12 h NM_013121 CD28 antigen Cd28 12.82 BG665360 FMS-like tyrosine kinase 1 Flt1 9.63 NM_012701 Adrenergic receptor, beta 1 Adrb1 8.24 0.46 U20796 Nuclear receptor subfamily 1, group D, member 2 Nr1d2 7.22 NM_017116 Calpain 2 Capn2 6.41 BE097282 Guanine nucleotide binding protein, alpha 12 Gna12 6.21 NM_053328 Basic helix-loop-helix domain containing, class B2 Bhlhb2 5.79 NM_053831 Guanylate cyclase 2f Gucy2f 5.71 AW251703 Tumor necrosis factor receptor superfamily, member 12a Tnfrsf12a 5.57 NM_021691 Twist homolog 2 (Drosophila) Twist2 5.42 NM_133550 Fc receptor, IgE, low affinity II, alpha polypeptide Fcer2a 4.93 NM_031120 Signal sequence receptor, gamma Ssr3 4.84 NM_053544 Secreted frizzled-related protein 4 Sfrp4 4.73 NM_053910 Pleckstrin homology, Sec7 and coiled/coil domains 1 Pscd1 4.69 BE113233 Suppressor of cytokine signaling 2 Socs2 4.68 NM_053949 Potassium voltage-gated channel, subfamily H (eag- Kcnh2 4.60 related), member 2 NM_017305 Glutamate cysteine ligase, modifier subunit Gclm 4.59 NM_017309 Protein phospatase 3, regulatory subunit B, alpha Ppp3r1 4.54 isoform,type 1 NM_012765 5-hydroxytryptamine (serotonin) receptor 2C Htr2c 4.46 NM_017218 V-erb-b2 erythroblastic leukemia viral oncogene homolog Erbb3 4.42 3 (avian) AW918369 Zinc finger protein 191 Zfp191 4.38 NM_031034 Guanine nucleotide binding protein, alpha 12 Gna12 4.38 NM_017020 Interleukin 6 receptor Il6r 4.37 AJ002942 -

A Bioinformatics Model of Human Diseases on the Basis Of
SUPPLEMENTARY MATERIALS A Bioinformatics Model of Human Diseases on the basis of Differentially Expressed Genes (of Domestic versus Wild Animals) That Are Orthologs of Human Genes Associated with Reproductive-Potential Changes Vasiliev1,2 G, Chadaeva2 I, Rasskazov2 D, Ponomarenko2 P, Sharypova2 E, Drachkova2 I, Bogomolov2 A, Savinkova2 L, Ponomarenko2,* M, Kolchanov2 N, Osadchuk2 A, Oshchepkov2 D, Osadchuk2 L 1 Novosibirsk State University, Novosibirsk 630090, Russia; 2 Institute of Cytology and Genetics, Siberian Branch of Russian Academy of Sciences, Novosibirsk 630090, Russia; * Correspondence: [email protected]. Tel.: +7 (383) 363-4963 ext. 1311 (M.P.) Supplementary data on effects of the human gene underexpression or overexpression under this study on the reproductive potential Table S1. Effects of underexpression or overexpression of the human genes under this study on the reproductive potential according to our estimates [1-5]. ↓ ↑ Human Deficit ( ) Excess ( ) # Gene NSNP Effect on reproductive potential [Reference] ♂♀ NSNP Effect on reproductive potential [Reference] ♂♀ 1 increased risks of preeclampsia as one of the most challenging 1 ACKR1 ← increased risk of atherosclerosis and other coronary artery disease [9] ← [3] problems of modern obstetrics [8] 1 within a model of human diseases using Adcyap1-knockout mice, 3 in a model of human health using transgenic mice overexpressing 2 ADCYAP1 ← → [4] decreased fertility [10] [4] Adcyap1 within only pancreatic β-cells, ameliorated diabetes [11] 2 within a model of human diseases -

Neural Basis of Opioid-Induced Respiratory Depression and Its Rescue
bioRxiv preprint doi: https://doi.org/10.1101/2020.10.28.359893; this version posted October 29, 2020. The copyright holder for this preprint (which was not certified by peer review) is the author/funder, who has granted bioRxiv a license to display the preprint in perpetuity. It is made available under aCC-BY-NC-ND 4.0 International license. 1 Neural basis of opioid-induced respiratory depression and its rescue. 2 Shijia Liu1,2, Dongil Kim1, Tae Gyu Oh3, Gerald Pao4, Jonghyun Kim1, Richard D. Palmiter5, Matthew R. Banghart2, 3 Kuo-Fen Lee1,2, Ronald M. Evans3, Sung Han1,2,* 4 1Peptide Biology Laboratories, The Salk Institute for Biological Studies, La Jolla, CA 92037, USA. 5 2Section of Neurobiology, Division of Biological Sciences, University of California, San Diego, La Jolla, CA 6 92093, USA. 7 3Howard Hughes Medical Institute, Gene Expression Laboratories, The Salk Institute for Biological Studies, La 8 Jolla, CA 92037, USA. 9 4Molecular and Cellular Biology Laboratories, The Salk Institute for Biological Studies, La Jolla, CA 92037, USA. 10 5Howard Hughes Medical Institute, Department of Biochemistry, School of Medicine, University of Washington, 11 Seattle, WA 98195, USA. 12 *Corresponding author: Sung Han, PhD 13 Author Contributions: S.H. conceived the idea, designed and constructed respiratory monitoring apparatus, and 14 secured funding. S.H. and S.L. designed the experiments and wrote the manuscript with inputs from other authors. 15 S.L. performed most of the experiments. D.K. and J.K. prepared the sample for RiboTag RNA sequencing. T.G.O. 16 analyzed the data from RiboTag RNA sequencing. -

Expression of Truncated Neurokinin-1 Receptor in Childhood
ANTICANCER RESEARCH 37 : 6079-6085 (2017) doi:10.21873/anticanres.12056 Expression of Truncated Neurokinin-1 Receptor in Childhood Neuroblastoma is Independent of Tumor Biology and Stage ALEXANDRA POHL, ROLAND KAPPLER, JAKOB MÜHLING, DIETRICH VON SCHWEINITZ and MICHAEL BERGER Department of Pediatric Surgery, Dr von Hauner Children’s Hospital, University Hospital, Ludwig -Maximilians -University Munich, Munich, Germany Abstract. Background: Neuroblastoma is an embryonal approaches in multimodal therapies demonstrated better malignancy arising from the aberrant growth of neural overall survival, more than 50% of children with high-risk crest progenitor cells of the sympathetic nervous system. disease do not respond to modern chemotherapy regimens, The tachykinin receptor 1 (TACR1) – substance P complex resulting in progressive disease. Overall, NB accounts for is associated with tumoral angiogenesis and cell 12% of all pediatric oncological deaths (1, 3-6). proliferation in a variety of cancer types. Inhibition of On the molecular level, several mutations have been TACR1 was recently described to impede growth of NB cell discovered for NB. For this and other reasons, NB has served lines. However, the relevance of TACR1 in clinical settings as a paradigm for biological risk assessment and treatment is unknown. Patients and Methods: We investigated gene assignment. For example, amplification of MYCN proto- expression levels of full-length and truncated TACR1 in 59 oncogene, bHLH transcription factor ( MYCN ) and neuroblastomas and correlated these data with the hemizygous deletion of chromosomes 1p and 11q are found patients ’ clinical parameters such as outcome, metastasis, in up to 30% of patients with NB and are known to correlate International Neuroblastoma Staging System (INSS) status, with worse outcome and poor prognosis(2). -

Development and Application of Computational Techniques to Drug Discovery and Structure-Function Relationships
Tesis doctoral Departament de Bioquímica i de Biologia Molecular DEVELOPMENT AND APPLICATION OF COMPUTATIONAL TECHNIQUES TO DRUG DISCOVERY AND STRUCTURE-FUNCTION RELATIONSHIPS Jose Carlos Gómez Tamayo Mireia Dunach Masjuan Tutor Gianluigi Caltabiano Arnau Cordomí Montoya Director * ! *%* & ! ' (, *%+ ! ! - *%, ! # ! 0 *%- $1 *%. " 2 + +%* ! +, +%+ !+- +%, +. +%- !$! +/ +%. !+1 +%/ ! ! %+2 +%0 ,) , ",, ) )$& !(* )$' # (, )$( ! )& )$) % *. -. )$* % ! &&, )$+ " # *% , ! % $ &(* * &** * , - $ " /&... ,05*15 - ,/-) & & # $ * ,*- ,/&0-) $$ # & & & ' &, -& & & $ & & ,1-) !$ !! $ $ ! & & ) $# !& ,2-) $& ! ! ( & &&%%+ 0& & $,/-) $ $ /3 & $ $02 &%%+ $ $02 & $ $/3 $& " & $ 4./ , /-) !$& ! ,3-) && & & & %%+ !$) # $ have permitted to elucidate the crystal structures of many receptors) -+,-& -+,-*)-*' # ( ) , which also terms this family of proteins as 7TM receptors* % ! " "# ' #. ." ' ") 253 '!" !" #"# ! /92 ## - " &! 48## " !0 !"" ""/80,$ '!" !" #"# ! # " ! !!! ) /90) /:0) /210) & %"!"!)"!"!)$ !!"! /220)!" #" ! /230) ! ! /240) & %" " /250 %" "- !"/260)" ! - !/21)27.2:0, #"!#"!!%"")!"" "!# ""'!$ '%)"