Forensic Timeline Analysis of the Zettabyte File System
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Absolute BSD—The Ultimate Guide to Freebsd Table of Contents Absolute BSD—The Ultimate Guide to Freebsd
Absolute BSD—The Ultimate Guide to FreeBSD Table of Contents Absolute BSD—The Ultimate Guide to FreeBSD............................................................................1 Dedication..........................................................................................................................................3 Foreword............................................................................................................................................4 Introduction........................................................................................................................................5 What Is FreeBSD?...................................................................................................................5 How Did FreeBSD Get Here?..................................................................................................5 The BSD License: BSD Goes Public.......................................................................................6 The Birth of Modern FreeBSD.................................................................................................6 FreeBSD Development............................................................................................................7 Committers.........................................................................................................................7 Contributors........................................................................................................................8 Users..................................................................................................................................8 -

ZFS 2018 and Onward
SEE TEXT ONLY 2018 and Onward BY ALLAN JUDE 2018 is going to be a big year for ZFS RAID-Z Expansion not only FreeBSD, but for OpenZFS • 2018Q4 as well. OpenZFS is the collaboration of developers from IllumOS, FreeBSD, The ability to add an additional disk to an existing RAID-Z VDEV to grow its size with- Linux, Mac OS X, many industry ven- out changing its redundancy level. For dors, and a number of other projects example, a RAID-Z2 consisting of 6 disks to maintain and advance the open- could be expanded to contain 7 disks, source version of Sun’s ZFS filesystem. increasing the available space. This is accomplished by reflowing the data across Improved Pool Import the disks, so as to not change an individual • 2018Q1 block’s offset from the start of the VDEV. The new disk will appear as a new column on the A new patch set changes the way pools are right, and the data will be relocated to main- imported, such that they depend less on con- tain the offset within the VDEV. Similar to figuration data from the system. Instead, the reflowing a paragraph by making it wider, possibly outdated configuration from the sys- without changing the order of the words. In tem is used to find the pool, and partially open the end this means all of the new space shows it read-only. Then the correct on-disk configura- up at the end of the disk, without any frag- tion is loaded. This reduces the number of mentation. -

Best Practices for Openzfs L2ARC in the Era of Nvme
Best Practices for OpenZFS L2ARC in the Era of NVMe Ryan McKenzie iXsystems 2019 Storage Developer Conference. © Insert Your Company Name. All Rights Reserved. 1 Agenda ❏ Brief Overview of OpenZFS ARC / L2ARC ❏ Key Performance Factors ❏ Existing “Best Practices” for L2ARC ❏ Rules of Thumb, Tribal Knowledge, etc. ❏ NVMe as L2ARC ❏ Testing and Results ❏ Revised “Best Practices” 2019 Storage Developer Conference. © iXsystems. All Rights Reserved. 2 ARC Overview ● Adaptive Replacement Cache ● Resides in system memory NIC/HBA ● Shared by all pools ● Used to store/cache: ARC OpenZFS ○ All incoming data ○ “Hottest” data and Metadata (a tunable ratio) SLOG vdevs ● Balances between ○ Most Frequently Used (MFU) Data vdevs L2ARC vdevs ○ Most Recently zpool Used (MRU) FreeBSD + OpenZFS Server 2019 Storage Developer Conference. © iXsystems. All Rights Reserved. 3 L2ARC Overview ● Level 2 Adaptive Replacement Cache ● Resides on one or more storage devices NIC/HBA ○ Usually Flash ● Device(s) added to pool ARC OpenZFS ○ Only services data held by that pool ● Used to store/cache: ○ “Warm” data and SLOG vdevs metadata ( about to be evicted from ARC) Data vdevs L2ARC vdevs ○ Indexes to L2ARC zpool blocks stored in ARC headers FreeBSD + OpenZFS Server 2019 Storage Developer Conference. © iXsystems. All Rights Reserved. 4 ZFS Writes ● All writes go through ARC, written blocks are “dirty” until on stable storage ACK NIC/HBA ○ async write ACKs immediately ARC OpenZFS ○ sync write copied to ZIL/SLOG then ACKs ○ copied to data SLOG vdevs vdev in TXG ● When no longer dirty, written blocks stay in Data vdevs L2ARC vdevs ARC and move through zpool MRU/MFU lists normally FreeBSD + OpenZFS Server 2019 Storage Developer Conference. -
![[11] Case Study: Unix](https://docslib.b-cdn.net/cover/4964/11-case-study-unix-794964.webp)
[11] Case Study: Unix
[11] CASE STUDY: UNIX 1 . 1 OUTLINE Introduction Design Principles Structural, Files, Directory Hierarchy Filesystem Files, Directories, Links, On-Disk Structures Mounting Filesystems, In-Memory Tables, Consistency IO Implementation, The Buffer Cache Processes Unix Process Dynamics, Start of Day, Scheduling and States The Shell Examples, Standard IO Summary 1 . 2 INTRODUCTION Introduction Design Principles Filesystem IO Processes The Shell Summary 2 . 1 HISTORY (I) First developed in 1969 at Bell Labs (Thompson & Ritchie) as reaction to bloated Multics. Originally written in PDP-7 asm, but then (1973) rewritten in the "new" high-level language C so it was easy to port, alter, read, etc. Unusual due to need for performance 6th edition ("V6") was widely available (1976), including source meaning people could write new tools and nice features of other OSes promptly rolled in V6 was mainly used by universities who could afford a minicomputer, but not necessarily all the software required. The first really portable OS as same source could be built for three different machines (with minor asm changes) Bell Labs continued with V8, V9 and V10 (1989), but never really widely available because V7 pushed to Unix Support Group (USG) within AT&T AT&T did System III first (1982), and in 1983 (after US government split Bells), System V. There was no System IV 2 . 2 HISTORY (II) By 1978, V7 available (for both the 16-bit PDP-11 and the new 32-bit VAX-11). Subsequently, two main families: AT&T "System V", currently SVR4, and Berkeley: "BSD", currently 4.4BSD Later standardisation efforts (e.g. -

Referência Debian I
Referência Debian i Referência Debian Osamu Aoki Referência Debian ii Copyright © 2013-2021 Osamu Aoki Esta Referência Debian (versão 2.85) (2021-09-17 09:11:56 UTC) pretende fornecer uma visão geral do sistema Debian como um guia do utilizador pós-instalação. Cobre muitos aspetos da administração do sistema através de exemplos shell-command para não programadores. Referência Debian iii COLLABORATORS TITLE : Referência Debian ACTION NAME DATE SIGNATURE WRITTEN BY Osamu Aoki 17 de setembro de 2021 REVISION HISTORY NUMBER DATE DESCRIPTION NAME Referência Debian iv Conteúdo 1 Manuais de GNU/Linux 1 1.1 Básico da consola ................................................... 1 1.1.1 A linha de comandos da shell ........................................ 1 1.1.2 The shell prompt under GUI ......................................... 2 1.1.3 A conta root .................................................. 2 1.1.4 A linha de comandos shell do root ...................................... 3 1.1.5 GUI de ferramentas de administração do sistema .............................. 3 1.1.6 Consolas virtuais ............................................... 3 1.1.7 Como abandonar a linha de comandos .................................... 3 1.1.8 Como desligar o sistema ........................................... 4 1.1.9 Recuperar uma consola sã .......................................... 4 1.1.10 Sugestões de pacotes adicionais para o novato ................................ 4 1.1.11 Uma conta de utilizador extra ........................................ 5 1.1.12 Configuração -

Openzfs on Linux Hepix 2014 October 16, 2014 Brian Behlendorf [email protected]
OpenZFS on Linux HEPiX 2014 October 16, 2014 Brian Behlendorf [email protected] LLNL-PRES-XXXXXX This work was performed under the auspices of the U.S. Department of Energy by Lawrence Livermore National Laboratory under Contract DE-AC52-07NA27344. Lawrence Livermore National Security, LLC 1 Lawrence Livermore National Laboratory LLNL-PRES-xxxxxx High Performance Computing Advanced Simulation Massive Scale Data Intensive Top 500 (June 2014) #3 Sequoia 20.1 Peak PFLOP/s 1,572,864 cores 55 PB of storage at 850 GB/s #9 Vulcan 5.0 Peak PFLOPS/s 393,216 cores 6.7 PB of storage at 106 GB/s World class computing resources 2 Lawrence Livermore National Laboratory LLNL-PRES-xxxxxx Linux Clusters 2001 – First Linux cluster Today – ~10 large Linux clusters (100– 3,000 nodes) and 10-20 smaller ones Near-commodity hardware Open source software stack (TOSS) Tri-Labratory Operating System Stack Modified RHEL targeted for HPC RHEL kernel optimized for clusters Moab and SLURM for scheduling Lustre parallel filesystem Additional packages for monitoring, power/console, compilers, etc LLNL Loves Linux 3 Lawrence Livermore National Laboratory LLNL-PRES-xxxxxx Lustre Lustre is our parallel filesystem of choice Livermore Computing Filesystems: Open – 20PB in 5 filesystems Secure – 22PB in 3 filesystems Plus the 55PB Sequoia filesystem 1000+ storage servers Billions of files Users want: Access to their data from every cluster Good performance High availability How do we design a system to handle this? Lustre is used extensively -

Utilizing Zfs for the Storage of Acquired Data*
UTILIZING ZFS FOR THE STORAGE OF ACQUIRED DATA* C. Pugh, P. Henderson, K. Silber, T. Carroll, K. Ying Information Technology Division Princeton Plasma Physics Laboratory (PPPL) Princeton, NJ [email protected] Abstract— Every day, the amount of data that is acquired from command, no longer does a system administrator have to guess plasma experiments grows dramatically. It has become difficult how large a project will grow. No longer does a project have to for systems administrators to keep up with the growing demand be interrupted in order to grow a partition, or move data to a for hard drive storage space. In the past, project storage has larger partition. been supplied using UNIX filesystem (ufs) partitions. In order to increase the size of the disks using this system, users were II. FINDING A SOLUTION required to discontinue use of the disk, so the existing data could be transferred to a disk of larger capacity or begin use of a The administrators at Princeton Plasma Physics completely new and separate disk, thus creating a segmentation Laboratory (PPPL) were struggling with meeting the demands of data storage. of ever growing acquired project data. Under their current system of exporting a UNIX file system (ufs) partition via With the application of ZFS pools, the data capacity Network File System protocol (NFS), any project at the lab woes are over. ZFS provides simple administration that could request a partition for the storage of acquired project data eliminates the need to unmount to resize, or transfer data to a which could be automatically mounted on our internal “portal” larger disk. -
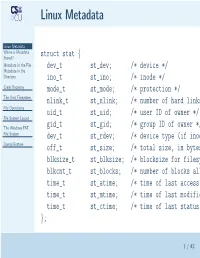
Linux Metadata
Linux Metadata Linux Metadata Where is Metadata Stored? struct stat { Metadata in the File dev_t st_dev; /* device */ Metadata in the Directory ino_t st_ino; /* inode */ Crash Recovery mode_t st_mode; /* protection */ The Unix Filesystem nlink_t st_nlink; /* number of hard links File Operations uid_t st_uid; /* user ID of owner */ File System Layout The Windows FAT gid_t st_gid; /* group ID of owner */ File System dev_t st_rdev; /* device type (if inode Dump/Restore off_t st_size; /* total size, in bytes blksize_t st_blksize; /* blocksize for filesystem blkcnt_t st_blocks; /* number of blocks allocated time_t st_atime; /* time of last access time_t st_mtime; /* time of last modification time_t st_ctime; /* time of last status }; 1 / 42 Where is Metadata Stored? Linux Metadata ■ Where is Metadata In the file? Stored? Metadata in the File ■ In the directory entry? Metadata in the Directory ■ Elsewhere? Crash Recovery ■ The Unix Filesystem Split? File Operations File System Layout The Windows FAT File System Dump/Restore 2 / 42 Metadata in the File Linux Metadata Where is Metadata ■ (Sort of) done by Apple: resource and data Stored? Metadata in the File forks Metadata in the Directory ■ Not very portable — when you copy the file Crash Recovery The Unix Filesystem to/from other systems, what happens to the File Operations metadata? File System Layout ■ No standardized metadata exchange format The Windows FAT File System Dump/Restore 3 / 42 Metadata in the Directory Linux Metadata ■ Where is Metadata Speeds access to metadata Stored? Metadata -

ZFS Basics Various ZFS RAID Lebels = & . = a Little About Zetabyte File System ( ZFS / Openzfs)
= BDNOG11 | Cox's Bazar | Day # 3 | ZFS Basics & Various ZFS RAID Lebels. = = ZFS Basics & Various ZFS RAID Lebels . = A Little About Zetabyte File System ( ZFS / OpenZFS) =1= = BDNOG11 | Cox's Bazar | Day # 3 | ZFS Basics & Various ZFS RAID Lebels. = Disclaimer: The scope of this topic here is not to discuss in detail about the architecture of the ZFS (OpenZFS) rather Features, Use Cases and Operational Method. =2= = BDNOG11 | Cox's Bazar | Day # 3 | ZFS Basics & Various ZFS RAID Lebels. = What is ZFS? =0= ZFS is a combined file system and logical volume manager designed by Sun Microsystems and now owned by Oracle Corporation. It was designed and implemented by a team at Sun Microsystems led by Jeff Bonwick and Matthew Ahrens. Matt is the founding member of OpenZFS. =0= Its development started in 2001 and it was officially announced in 2004. In 2005 it was integrated into the main trunk of Solaris and released as part of OpenSolaris. =0= It was described by one analyst as "the only proven Open Source data-validating enterprise file system". This file =3= = BDNOG11 | Cox's Bazar | Day # 3 | ZFS Basics & Various ZFS RAID Lebels. = system also termed as the “world’s safest file system” by some analyst. =0= ZFS is scalable, and includes extensive protection against data corruption, support for high storage capacities, efficient data compression and deduplication. =0= ZFS is available for Solaris (and its variants), BSD (and its variants) & Linux (Canonical’s Ubuntu Integrated as native kernel module from version 16.04x) =0= OpenZFS was announced in September 2013 as the truly open source successor to the ZFS project. -

Matt Ahrens [email protected] Brian Behlendorf Behlendorf1@Llnl
LinuxCon 2013 September 17, 2013 Brian Behlendorf, Open ZFS on Linux LLNL-PRES-643675 This work was performed under the auspices of the U.S. Department of Energy by Lawrence Livermore National Laboratory under Contract DE-AC52-07NA27344. Lawrence Livermore National Security, LLC High Performance Computing ● Advanced Simulation – Massive Scale – Data Intensive ● Top 500 – #3 Sequoia ● 20.1 Peak PFLOP/s ● 1,572,864 cores ● 55 PB of storage at 850 GB/s – #8 Vulcan ● 5.0 Peak PFLOPS/s ● 393,216 cores ● 6.7 PB of storage at 106 GB/s ● ● World class computing resources 2 Lawrence Livermore National Laboratory LLNL-PRES-xxxxxx Linux Clusters ● First Linux cluster deployed in 2001 ● Near-commodity hardware ● Open Source ● Clustered HiGh Availability OperatinG System (CHAOS) – Modified RHEL Kernel – New packaGes – monitorinG, power/console, compilers, etc – Lustre Parallel Filesystem – ZFS Filesystem LLNL Loves Linux 3 Lawrence Livermore National Laboratory LLNL-PRES-643675 Lustre Filesystem ● Massively parallel distributed filesystem ● Lustre servers use a modified ext4 – Stable and fast, but... – No sCalability – No data integrity – No online manageability ● Something better was needed – Use XFS, BTRFS, etC? – Write a filesystem from sCratCh? – Port ZFS to Linux? Existing Linux filesystems do not meet our requirements 4 Lawrence Livermore National Laboratory LLNL-PRES-643675 ZFS on Linux History ● 2008 – Prototype to determine viability ● 2009 – Initial ZVOL and Lustre support ● 2010 – Development moved to Github ● 2011 – POSIX layer -

Distributed File Service Messages and Codes
z/OS Version 2 Release 3 Distributed File Service Messages and Codes IBM SC23-6885-30 Note Before using this information and the product it supports, read the information in “Notices” on page 295. This edition applies to Version 2 Release 3 of z/OS (5650-ZOS) and to all subsequent releases and modifications until otherwise indicated in new editions. Last updated: 2019-03-26 © Copyright International Business Machines Corporation 1996, 2018. US Government Users Restricted Rights – Use, duplication or disclosure restricted by GSA ADP Schedule Contract with IBM Corp. Contents About this document..............................................................................................v How to send your comments to IBM......................................................................vii Summary of changes...........................................................................................viii Chapter 1. Introduction......................................................................................... 1 Chapter 2. IOENnnnnnt: General DFS messages..................................................... 5 Chapter 3. IOEPnnnnnt: DFS kernel (dfskern) and general DFS error messages..... 27 Chapter 4. IOEWnnnnnt: SMB File/Print Server messages.................................... 59 Chapter 5. IOEXnnnnnt: File Exporter (dfsexport).................................................89 Chapter 6. IOEZnnnnnt: zFS messages............................................................... 101 Chapter 7. IOEZHnnnnt: zFS Health Checker messages.......................................213 -

Freebsd VS. Linux: ZFS by ALLAN JUDE
SEE TEXT ONLY FreeBSD VS. Linux: ZFS BY ALLAN JUDE Why Use ZFS? It is not that other filesystems are bad; they just make the mistake of trusting your storage hardware to return your data when you ask for it. As it turns out, hard drives are pretty good at that, but pretty good is often not good enough. ZFS is the only open-source, OpenZFS is available on many plat- production-quality filesystem that can not only forms, including FreeBSD and Solaris detect but correct the errors when a disk derivatives like IllumOS, as well as Mac returns incorrect data. By combining the roles of filesystem and volume manager, ZFS is also OS X and Linux. However, not all of the able to ensure your data is safe, even in the functionality is available on the latter absence of one or more disks, depending on platforms. The FreeBSD Project has fully your configuration. ZFS doesn’t trust your adopted ZFS, putting significant effort hardware; it verifies that the correct data was into integrating it with the system and returned from each read from the disk. The primary design consideration for ZFS is management tools to make ZFS a seam- the safety of the data. Every block that is writ- less part of the OS, rather than a bolt- ten to the filesystem is accompanied by a ed-on extra. OpenZFS is better inte- checksum of the data, stored with the other grated, instrumented, and documented metadata. That metadata block also has a on FreeBSD than on any of the various checksum, as does its parent, all the way up to the top-level block, called the uber block.