Utilizing Zfs for the Storage of Acquired Data*
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Absolute BSD—The Ultimate Guide to Freebsd Table of Contents Absolute BSD—The Ultimate Guide to Freebsd
Absolute BSD—The Ultimate Guide to FreeBSD Table of Contents Absolute BSD—The Ultimate Guide to FreeBSD............................................................................1 Dedication..........................................................................................................................................3 Foreword............................................................................................................................................4 Introduction........................................................................................................................................5 What Is FreeBSD?...................................................................................................................5 How Did FreeBSD Get Here?..................................................................................................5 The BSD License: BSD Goes Public.......................................................................................6 The Birth of Modern FreeBSD.................................................................................................6 FreeBSD Development............................................................................................................7 Committers.........................................................................................................................7 Contributors........................................................................................................................8 Users..................................................................................................................................8 -
![[11] Case Study: Unix](https://docslib.b-cdn.net/cover/4964/11-case-study-unix-794964.webp)
[11] Case Study: Unix
[11] CASE STUDY: UNIX 1 . 1 OUTLINE Introduction Design Principles Structural, Files, Directory Hierarchy Filesystem Files, Directories, Links, On-Disk Structures Mounting Filesystems, In-Memory Tables, Consistency IO Implementation, The Buffer Cache Processes Unix Process Dynamics, Start of Day, Scheduling and States The Shell Examples, Standard IO Summary 1 . 2 INTRODUCTION Introduction Design Principles Filesystem IO Processes The Shell Summary 2 . 1 HISTORY (I) First developed in 1969 at Bell Labs (Thompson & Ritchie) as reaction to bloated Multics. Originally written in PDP-7 asm, but then (1973) rewritten in the "new" high-level language C so it was easy to port, alter, read, etc. Unusual due to need for performance 6th edition ("V6") was widely available (1976), including source meaning people could write new tools and nice features of other OSes promptly rolled in V6 was mainly used by universities who could afford a minicomputer, but not necessarily all the software required. The first really portable OS as same source could be built for three different machines (with minor asm changes) Bell Labs continued with V8, V9 and V10 (1989), but never really widely available because V7 pushed to Unix Support Group (USG) within AT&T AT&T did System III first (1982), and in 1983 (after US government split Bells), System V. There was no System IV 2 . 2 HISTORY (II) By 1978, V7 available (for both the 16-bit PDP-11 and the new 32-bit VAX-11). Subsequently, two main families: AT&T "System V", currently SVR4, and Berkeley: "BSD", currently 4.4BSD Later standardisation efforts (e.g. -
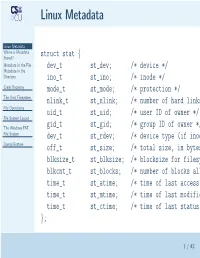
Linux Metadata
Linux Metadata Linux Metadata Where is Metadata Stored? struct stat { Metadata in the File dev_t st_dev; /* device */ Metadata in the Directory ino_t st_ino; /* inode */ Crash Recovery mode_t st_mode; /* protection */ The Unix Filesystem nlink_t st_nlink; /* number of hard links File Operations uid_t st_uid; /* user ID of owner */ File System Layout The Windows FAT gid_t st_gid; /* group ID of owner */ File System dev_t st_rdev; /* device type (if inode Dump/Restore off_t st_size; /* total size, in bytes blksize_t st_blksize; /* blocksize for filesystem blkcnt_t st_blocks; /* number of blocks allocated time_t st_atime; /* time of last access time_t st_mtime; /* time of last modification time_t st_ctime; /* time of last status }; 1 / 42 Where is Metadata Stored? Linux Metadata ■ Where is Metadata In the file? Stored? Metadata in the File ■ In the directory entry? Metadata in the Directory ■ Elsewhere? Crash Recovery ■ The Unix Filesystem Split? File Operations File System Layout The Windows FAT File System Dump/Restore 2 / 42 Metadata in the File Linux Metadata Where is Metadata ■ (Sort of) done by Apple: resource and data Stored? Metadata in the File forks Metadata in the Directory ■ Not very portable — when you copy the file Crash Recovery The Unix Filesystem to/from other systems, what happens to the File Operations metadata? File System Layout ■ No standardized metadata exchange format The Windows FAT File System Dump/Restore 3 / 42 Metadata in the Directory Linux Metadata ■ Where is Metadata Speeds access to metadata Stored? Metadata -

Distributed File Service Messages and Codes
z/OS Version 2 Release 3 Distributed File Service Messages and Codes IBM SC23-6885-30 Note Before using this information and the product it supports, read the information in “Notices” on page 295. This edition applies to Version 2 Release 3 of z/OS (5650-ZOS) and to all subsequent releases and modifications until otherwise indicated in new editions. Last updated: 2019-03-26 © Copyright International Business Machines Corporation 1996, 2018. US Government Users Restricted Rights – Use, duplication or disclosure restricted by GSA ADP Schedule Contract with IBM Corp. Contents About this document..............................................................................................v How to send your comments to IBM......................................................................vii Summary of changes...........................................................................................viii Chapter 1. Introduction......................................................................................... 1 Chapter 2. IOENnnnnnt: General DFS messages..................................................... 5 Chapter 3. IOEPnnnnnt: DFS kernel (dfskern) and general DFS error messages..... 27 Chapter 4. IOEWnnnnnt: SMB File/Print Server messages.................................... 59 Chapter 5. IOEXnnnnnt: File Exporter (dfsexport).................................................89 Chapter 6. IOEZnnnnnt: zFS messages............................................................... 101 Chapter 7. IOEZHnnnnt: zFS Health Checker messages.......................................213 -

Design and Implementation of the Spad Filesystem
Charles University in Prague Faculty of Mathematics and Physics DOCTORAL THESIS Mikul´aˇsPatoˇcka Design and Implementation of the Spad Filesystem Department of Software Engineering Advisor: RNDr. Filip Zavoral, Ph.D. Abstract Title: Design and Implementation of the Spad Filesystem Author: Mgr. Mikul´aˇsPatoˇcka email: [email protected]ff.cuni.cz Department: Department of Software Engineering Faculty of Mathematics and Physics Charles University in Prague, Czech Republic Advisor: RNDr. Filip Zavoral, Ph.D. email: Filip.Zavoral@mff.cuni.cz Mailing address (advisor): Dept. of Software Engineering Charles University in Prague Malostransk´en´am. 25 118 00 Prague, Czech Republic WWW: http://artax.karlin.mff.cuni.cz/~mikulas/spadfs/ Abstract: This thesis describes design and implementation of the Spad filesystem. I present my novel method for maintaining filesystem consistency — crash counts. I describe architecture of other filesystems and present my own de- sign decisions in directory management, file allocation information, free space management, block allocation strategy and filesystem checking algorithm. I experimentally evaluate performance of the filesystem. I evaluate performance of the same filesystem on two different operating systems, enabling the reader to make a conclusion on how much the performance of various tasks is affected by operating system and how much by physical layout of data on disk. Keywords: filesystem, operating system, crash counts, extendible hashing, SpadFS Acknowledgments I would like to thank my advisor Filip Zavoral for supporting my work and for reading and making comments on this thesis. I would also like to thank to colleague Leo Galamboˇsfor testing my filesystem on his search engine with 1TB RAID array, which led to fixing some bugs and improving performance. -

The Unix Operating System SE 101 Spiros Mancoridis What Is an OS?
The Unix Operating System SE 101 Spiros Mancoridis What is an OS? An operating system (OS) is software that manages the resources of a computer Like most managers, the OS aims to manage its resources in a safe and efficient way Examples of computer resources are: CPU, RAM, disk memory, printers, displays, keyboard, mouse, etc The OS also isolates users and application programmers from the underlying computer Operating Systems Microsoft Windows Unix OS Architecture Without an OS, every application would have to implement some part of this software hierarchy ... Unix A popular multi-user, multi-tasking OS Attributes: stability, portability, security Created at Bell Labs by Dennis Ritchie and Ken Thompson (won the ACM Turing Award in 1983) Unix is considered one of the greatest achievements in computer science Has been around since the 1960s in various forms, e.g., AIX, SCO Unix, SunOS, FreeBSD, OpenBSD, NetBSD, Linux, Mac OS X Unix Multiuser and Multitasking Toolbox philosophy Concise syntax Designed by programmers for programmers 1983 ACM Turning Award (Unix) ACM is the Association for Computing Machinery World’s largest educational and scientific computer society Thompson and Ritchie You can become a student member too www.acm.org The ACM awards the Turing Award every year. It is the “Nobel Prize” of computing Named after british mathematician Alan M. Turing (1912-1954) Alan M. Turing Unix Kernel Includes device drivers for computer hardware devices, e.g., graphics cards, network cards, disks A device driver is a program that allows computer -

The Evolution of File Systems
The Evolution of File Systems Thomas Rivera, Hitachi Data Systems Craig Harmer, April 2011 SNIA Legal Notice The material contained in this tutorial is copyrighted by the SNIA. Member companies and individuals may use this material in presentations and literature under the following conditions: Any slide or slides used must be reproduced without modification The SNIA must be acknowledged as source of any material used in the body of any document containing material from these presentations. This presentation is a project of the SNIA Education Committee. Neither the Author nor the Presenter is an attorney and nothing in this presentation is intended to be nor should be construed as legal advice or opinion. If you need legal advice or legal opinion please contact an attorney. The information presented herein represents the Author's personal opinion and current understanding of the issues involved. The Author, the Presenter, and the SNIA do not assume any responsibility or liability for damages arising out of any reliance on or use of this information. NO WARRANTIES, EXPRESS OR IMPLIED. USE AT YOUR OWN RISK. The Evolution of File Systems 2 © 2012 Storage Networking Industry Association. All Rights Reserved. 2 Abstract The File Systems Evolution Over time additional file systems appeared focusing on specialized requirements such as: data sharing, remote file access, distributed file access, parallel files access, HPC, archiving, security, etc. Due to the dramatic growth of unstructured data, files as the basic units for data containers are morphing into file objects, providing more semantics and feature- rich capabilities for content processing This presentation will: Categorize and explain the basic principles of currently available file system architectures (e.g. -

File System Multithreading in Systemvrelease4mp
File SystemMultithreading in SystemVRelease4MP . J. Kent Peacock- Intel MultiprocessorConsortium ABSTRACT An Intel-sponsoredConsortium of computer companies has developed a multiprocessor version of System V Release4 (SVR4MP) which has been releasedby UNIX Sysæm Laboratories. The Consortium'sgoal was to add fine-grainedlocking ûo SVR4 with minimal change to the kemel, and with complete backward compatibility for user progrâms. To do this, a locking sEategy was developedwhich complemented,rather than replaced, existing UNIX synchronizationmechanisms. To multitlread the flle systems,some general locking sEategieswere developedand applied to the generic Virtual File Sysæm(VFS) and vnode interfaces. Of particular interest were the disk-basedSi and UFS file system types, especially with respect to their scalability. Contentionpoints were found and successivelyeliminated to the point wherethe tle systems were found to be disk-bound. In particular, several file system caches were restructured using a low-contention,highly-scalable approach called a SoftwareSet-Associartve Cache. This æchniquereduced the measuredlocking contention of each of these caches from the l0-I57o rangeto lessthan 0.17o. A numberof experimentalchanges to disk queuesorting algorithms were attemptedto reduce the disk bottleneck, with limited success. However, these experiments provided the following insight into the need for balancebetween I/O and CPU utilization in the system: that anempting to increaseCPU utilization to show higher parallelism could actually lower system throughput. Using the GAEDE benchmarkwith a sufflcient number of disks configured, the kernel was found to obtain throughputscalability of 887oof the theoreticalmaximum on 5 processors. Introduction Graphics, Solboume and Corollary have all offered multiprocessorUND( systems,though not all have goal assembledby Intel The of the Consortium describedthe changesmade to the operatingsystem produce multiprocessorversion of System was to a in the literahre. -

Introduction to UNIX: Basic Concepts
Introduction to UNIX: basic concepts P. Regnauld <[email protected]> AfNOG 2004 1. Content • history • introduction to UNIX design (kernel, virtual memory,multi-user,filesystem, access-rights) • basic concepts of UNIX (sessions, manuals, users, groups, processes, terminals, shells, sig- nals, job control, ...) 2. History • long history: over 25 years old (On the Early History and Impact of Unix1 ,Ronda Hauben). • 1969 at Bell Laboratories (pun on «Multics») -- K. Thompson / B. Kernighan • Clanguage around 1974 (B. Kernighan / D.Richie) • Ported to several platforms in C («Portable OS») • dsitributed to laboratories / Universities for small fee ($150) • 1978: V7 is the first commercial version • two main «branches»: BSD (4.4BSD) and SVSTEM V (SVR4), and now Linux • most ported operating system -- free versions available Today: over 50 variants (see UGU). Most known: • Solaris -- Sun Microsystems • HP-UX -- Hewlett Packard • AIX -- IBM • Irix -- Silicon Graphics, Inc. • MacOS X / Darwin -- Apple • GNU/Linux -- various (Debian, RedHat, SuSE, Gentoo, Mandrake, Turbolinux) • FreeBSD, NetBSD, OpenBSD 1. <URL:http://internet-history.org/archives/early.history.of.unix.html> Introduction to UNIX: basic concepts 1 Introduction to UNIX: basic concepts 2 3. UNIX design Thereare 4 main layers to the UNIX system 1. the kernel 2. the shell 3. applications 4. users The UNIX system Launch processes Background processing User interaction (terminal) Non−interactive Job control (no terminal) (scripting) DAEMONS SHELLS KERNEL APPS File management Editors USERS -

Unix / Linux File System Basics
UUNNIIXX // LLIINNUUXX -- FFIILLEE SSYYSSTTEEMM BBAASSIICCSS http://www.tutorialspoint.com/unix/unix-file-system.htm Copyright © tutorialspoint.com Advertisements A file system is a logical collection of files on a partition or disk. A partition is a container for information and can span an entire hard drive if desired. Your hard drive can have various partitions which usually contain only one file system, such as one file system housing the /file system or another containing the /home file system. One file system per partition allows for the logical maintenance and management of differing file systems. Everything in Unix is considered to be a file, including physical devices such as DVD-ROMs, USB devices, and floppy drives. Directory Structure Unix uses a hierarchical file system structure, much like an upside-down tree, with root (/) at the base of the file system and all other directories spreading from there. A Unix filesystem is a collection of files and directories that has the following properties − It has a root directory (/) that contains other files and directories. Each file or directory is uniquely identified by its name, the directory in which it resides, and a unique identifier, typically called an inode. By convention, the root directory has an inode number of 2 and the lost+found directory has an inode number of 3. Inode numbers 0 and 1 are not used. File inode numbers can be seen by specifying the -i option to ls command. It is self-contained. There are no dependencies between one filesystem and another. The directories have specific purposes and generally hold the same types of information for easily locating files. -
Unix Filesystem from Wikipedia, the Free Encyclopedia
Unix filesystem From Wikipedia, the free encyclopedia In Unix and operating systems inspired by it, the file system is considered a central component of the operating system.[1] It was also one of the first parts of the system to be designed and implemented by Ken Thompson in the first experimental version of Unix, dated 1969.[2] As in other operating systems, the filesystem provides information storage and retrieval, and one of several forms of interprocess communication, in that the many small programs that traditionally form a Unix system can store information in files so that other programs can read them, although pipes complemented it in this role starting with the Third Edition. Also, the filesystem provides access to other resources through so-called device files that are entry points to terminals, printers, and mice. Version 7 Unix filesystem The rest of this article uses Unix as a generic name to refer to both the original Unix operating system and its many workalikes. layout: subdirectories of "/" and "/usr" Contents 1 Principles 1.1 File types 2 Conventional directory layout 3 See also 4 References Principles The filesystem appears as one rooted tree of directories.[1] Instead of addressing separate volumes such as disk partitions, removable media, and network shares as separate trees (as done in DOS and Windows: each drive has a drive letter that denotes the root of its file system tree), such volumes can be mounted on a directory, causing the volume's file system tree to appear as that directory in the larger tree.[1] The root of the entire tree is denoted /. -

Forensic Timeline Analysis of the Zettabyte File System
Forensic Timeline Analysis of the Zettabyte File System Dylan Leigh College of Engineering and Science, Victoria University, Melbourne, Australia Submitted in partial fulfilment of the requirements of the degree of Bachelor of Science (Honours) (Computer Science) January 2015 ABSTRACT During forensic analysis of computer systems, it is often necessary to construct a chronological account of events, including when files were created, modified, accessed and deleted. Timeline analysis is the process of collating and analysing this data, using timestamps from the filesys- tem and other sources such as log files and internal file metadata. The Zettabyte File System (ZFS) uses a novel and complex structure to store file data and metadata across multiple devices. Due to the unusual structure and operation of ZFS, many existing forensic tools and techniques cannot be used to analyse ZFS filesystems. In this project, it has been demonstrated that four of the internal structures of ZFS can be used as effective sources of timeline information. Methods to extract these structures and use them for timeline analysis are provided, including algorithms to detect falsified file timestamps and to determine when individual blocks of file data were last modified. ii STUDENT DECLARATION I, Dylan Leigh, declare that this BSc (Honours) thesis entitled Forensic Timeline Analysis of the Zettabyte File System is no more than 60,000 words in length including quotes and exclusive of tables, figures, appendices, bibliography, references and footnotes. This thesis contains no material that has been submitted previously, in whole or in part, for the award of any other academic degree or diploma. Except where otherwise indicated, this thesis is my own work.