A Guide to Modern UNIX Systems
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

UNIX Version 7 Volume 1
UNIXTM TIME-SHARING SYSTEM: UNIX PROGRAMMER'S MANUAL Seventh Edition, Volume 1 January, 1979 Bell Telephone Laboratories, Incorporated Murray Hill, New Jersey PREFACE Although this Seventh Edition no longer bears their byline, Ken Thompson and Dennis Ritchie remain the fathers and preceptors of the UNIX² time-sharing system. Many of the improvements here described bear their mark. Among many, many other people who have contributed to the further ¯owering of UNIX, we wish especially to acknowledge the contributions of A. V. Aho, S. R. Bourne, L. L. Cherry, G. L. Chesson, S. I. Feldman, C. B. Haley, R. C. Haight, S. C. Johnson, M. E. Lesk, T. L. Lyon, L. E. McMahon, R. Morris, R. Muha, D. A. Nowitz, L. Wehr, and P. J. Weinberger. We appreciate also the effective advice and criticism of T. A. Dolotta, A. G. Fraser, J. F. Maranzano, and J. R. Mashey; and we remember the important work of the late Joseph F. Ossanna. B. W. Kernighan M. D. McIlroy __________________ ²UNIX is a Trademark of Bell Laboratories. INTRODUCTION TO VOLUME 1 This volume gives descriptions of the publicly available features of the UNIX² system. It does not attempt to provide perspective or tutorial information upon the UNIX operating system, its facilities, or its implementation. Various documents on those topics are contained in Volume 2. In particular, for an overview see `The UNIX Time-Sharing System' by Ritchie and Thompson; for a tutorial see `UNIX for Beginners' by Kernighan. Within the area it surveys, this volume attempts to be timely, complete and concise. Where the latter two objectives con¯ict, the obvious is often left unsaid in favor of brevity. -

Solaris Advanced User's Guide
Solaris Advanced User’s Guide Sun Microsystems, Inc. 4150 Network Circle Santa Clara, CA 95054 U.S.A. Part No: 806–7612–10 May 2002 Copyright 2002 Sun Microsystems, Inc. 4150 Network Circle, Santa Clara, CA 95054 U.S.A. All rights reserved. This product or document is protected by copyright and distributed under licenses restricting its use, copying, distribution, and decompilation. No part of this product or document may be reproduced in any form by any means without prior written authorization of Sun and its licensors, if any. Third-party software, including font technology, is copyrighted and licensed from Sun suppliers. Parts of the product may be derived from Berkeley BSD systems, licensed from the University of California. UNIX is a registered trademark in the U.S. and other countries, exclusively licensed through X/Open Company, Ltd. Sun, Sun Microsystems, the Sun logo, docs.sun.com, AnswerBook, AnswerBook2, SunOS, and Solaris are trademarks, registered trademarks, or service marks of Sun Microsystems, Inc. in the U.S. and other countries. All SPARC trademarks are used under license and are trademarks or registered trademarks of SPARC International, Inc. in the U.S. and other countries. Products bearing SPARC trademarks are based upon an architecture developed by Sun Microsystems, Inc. The OPEN LOOK and Sun™ Graphical User Interface was developed by Sun Microsystems, Inc. for its users and licensees. Sun acknowledges the pioneering efforts of Xerox in researching and developing the concept of visual or graphical user interfaces for the computer industry. Sun holds a non-exclusive license from Xerox to the Xerox Graphical User Interface, which license also covers Sun’s licensees who implement OPEN LOOK GUIs and otherwise comply with Sun’s written license agreements. -

Absolute BSD—The Ultimate Guide to Freebsd Table of Contents Absolute BSD—The Ultimate Guide to Freebsd
Absolute BSD—The Ultimate Guide to FreeBSD Table of Contents Absolute BSD—The Ultimate Guide to FreeBSD............................................................................1 Dedication..........................................................................................................................................3 Foreword............................................................................................................................................4 Introduction........................................................................................................................................5 What Is FreeBSD?...................................................................................................................5 How Did FreeBSD Get Here?..................................................................................................5 The BSD License: BSD Goes Public.......................................................................................6 The Birth of Modern FreeBSD.................................................................................................6 FreeBSD Development............................................................................................................7 Committers.........................................................................................................................7 Contributors........................................................................................................................8 Users..................................................................................................................................8 -
![[11] Case Study: Unix](https://docslib.b-cdn.net/cover/4964/11-case-study-unix-794964.webp)
[11] Case Study: Unix
[11] CASE STUDY: UNIX 1 . 1 OUTLINE Introduction Design Principles Structural, Files, Directory Hierarchy Filesystem Files, Directories, Links, On-Disk Structures Mounting Filesystems, In-Memory Tables, Consistency IO Implementation, The Buffer Cache Processes Unix Process Dynamics, Start of Day, Scheduling and States The Shell Examples, Standard IO Summary 1 . 2 INTRODUCTION Introduction Design Principles Filesystem IO Processes The Shell Summary 2 . 1 HISTORY (I) First developed in 1969 at Bell Labs (Thompson & Ritchie) as reaction to bloated Multics. Originally written in PDP-7 asm, but then (1973) rewritten in the "new" high-level language C so it was easy to port, alter, read, etc. Unusual due to need for performance 6th edition ("V6") was widely available (1976), including source meaning people could write new tools and nice features of other OSes promptly rolled in V6 was mainly used by universities who could afford a minicomputer, but not necessarily all the software required. The first really portable OS as same source could be built for three different machines (with minor asm changes) Bell Labs continued with V8, V9 and V10 (1989), but never really widely available because V7 pushed to Unix Support Group (USG) within AT&T AT&T did System III first (1982), and in 1983 (after US government split Bells), System V. There was no System IV 2 . 2 HISTORY (II) By 1978, V7 available (for both the 16-bit PDP-11 and the new 32-bit VAX-11). Subsequently, two main families: AT&T "System V", currently SVR4, and Berkeley: "BSD", currently 4.4BSD Later standardisation efforts (e.g. -

Utilizing Zfs for the Storage of Acquired Data*
UTILIZING ZFS FOR THE STORAGE OF ACQUIRED DATA* C. Pugh, P. Henderson, K. Silber, T. Carroll, K. Ying Information Technology Division Princeton Plasma Physics Laboratory (PPPL) Princeton, NJ [email protected] Abstract— Every day, the amount of data that is acquired from command, no longer does a system administrator have to guess plasma experiments grows dramatically. It has become difficult how large a project will grow. No longer does a project have to for systems administrators to keep up with the growing demand be interrupted in order to grow a partition, or move data to a for hard drive storage space. In the past, project storage has larger partition. been supplied using UNIX filesystem (ufs) partitions. In order to increase the size of the disks using this system, users were II. FINDING A SOLUTION required to discontinue use of the disk, so the existing data could be transferred to a disk of larger capacity or begin use of a The administrators at Princeton Plasma Physics completely new and separate disk, thus creating a segmentation Laboratory (PPPL) were struggling with meeting the demands of data storage. of ever growing acquired project data. Under their current system of exporting a UNIX file system (ufs) partition via With the application of ZFS pools, the data capacity Network File System protocol (NFS), any project at the lab woes are over. ZFS provides simple administration that could request a partition for the storage of acquired project data eliminates the need to unmount to resize, or transfer data to a which could be automatically mounted on our internal “portal” larger disk. -
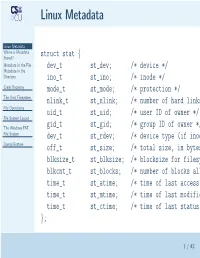
Linux Metadata
Linux Metadata Linux Metadata Where is Metadata Stored? struct stat { Metadata in the File dev_t st_dev; /* device */ Metadata in the Directory ino_t st_ino; /* inode */ Crash Recovery mode_t st_mode; /* protection */ The Unix Filesystem nlink_t st_nlink; /* number of hard links File Operations uid_t st_uid; /* user ID of owner */ File System Layout The Windows FAT gid_t st_gid; /* group ID of owner */ File System dev_t st_rdev; /* device type (if inode Dump/Restore off_t st_size; /* total size, in bytes blksize_t st_blksize; /* blocksize for filesystem blkcnt_t st_blocks; /* number of blocks allocated time_t st_atime; /* time of last access time_t st_mtime; /* time of last modification time_t st_ctime; /* time of last status }; 1 / 42 Where is Metadata Stored? Linux Metadata ■ Where is Metadata In the file? Stored? Metadata in the File ■ In the directory entry? Metadata in the Directory ■ Elsewhere? Crash Recovery ■ The Unix Filesystem Split? File Operations File System Layout The Windows FAT File System Dump/Restore 2 / 42 Metadata in the File Linux Metadata Where is Metadata ■ (Sort of) done by Apple: resource and data Stored? Metadata in the File forks Metadata in the Directory ■ Not very portable — when you copy the file Crash Recovery The Unix Filesystem to/from other systems, what happens to the File Operations metadata? File System Layout ■ No standardized metadata exchange format The Windows FAT File System Dump/Restore 3 / 42 Metadata in the Directory Linux Metadata ■ Where is Metadata Speeds access to metadata Stored? Metadata -

Distributed File Service Messages and Codes
z/OS Version 2 Release 3 Distributed File Service Messages and Codes IBM SC23-6885-30 Note Before using this information and the product it supports, read the information in “Notices” on page 295. This edition applies to Version 2 Release 3 of z/OS (5650-ZOS) and to all subsequent releases and modifications until otherwise indicated in new editions. Last updated: 2019-03-26 © Copyright International Business Machines Corporation 1996, 2018. US Government Users Restricted Rights – Use, duplication or disclosure restricted by GSA ADP Schedule Contract with IBM Corp. Contents About this document..............................................................................................v How to send your comments to IBM......................................................................vii Summary of changes...........................................................................................viii Chapter 1. Introduction......................................................................................... 1 Chapter 2. IOENnnnnnt: General DFS messages..................................................... 5 Chapter 3. IOEPnnnnnt: DFS kernel (dfskern) and general DFS error messages..... 27 Chapter 4. IOEWnnnnnt: SMB File/Print Server messages.................................... 59 Chapter 5. IOEXnnnnnt: File Exporter (dfsexport).................................................89 Chapter 6. IOEZnnnnnt: zFS messages............................................................... 101 Chapter 7. IOEZHnnnnt: zFS Health Checker messages.......................................213 -

Design and Implementation of the Spad Filesystem
Charles University in Prague Faculty of Mathematics and Physics DOCTORAL THESIS Mikul´aˇsPatoˇcka Design and Implementation of the Spad Filesystem Department of Software Engineering Advisor: RNDr. Filip Zavoral, Ph.D. Abstract Title: Design and Implementation of the Spad Filesystem Author: Mgr. Mikul´aˇsPatoˇcka email: [email protected]ff.cuni.cz Department: Department of Software Engineering Faculty of Mathematics and Physics Charles University in Prague, Czech Republic Advisor: RNDr. Filip Zavoral, Ph.D. email: Filip.Zavoral@mff.cuni.cz Mailing address (advisor): Dept. of Software Engineering Charles University in Prague Malostransk´en´am. 25 118 00 Prague, Czech Republic WWW: http://artax.karlin.mff.cuni.cz/~mikulas/spadfs/ Abstract: This thesis describes design and implementation of the Spad filesystem. I present my novel method for maintaining filesystem consistency — crash counts. I describe architecture of other filesystems and present my own de- sign decisions in directory management, file allocation information, free space management, block allocation strategy and filesystem checking algorithm. I experimentally evaluate performance of the filesystem. I evaluate performance of the same filesystem on two different operating systems, enabling the reader to make a conclusion on how much the performance of various tasks is affected by operating system and how much by physical layout of data on disk. Keywords: filesystem, operating system, crash counts, extendible hashing, SpadFS Acknowledgments I would like to thank my advisor Filip Zavoral for supporting my work and for reading and making comments on this thesis. I would also like to thank to colleague Leo Galamboˇsfor testing my filesystem on his search engine with 1TB RAID array, which led to fixing some bugs and improving performance. -

The Unix Operating System SE 101 Spiros Mancoridis What Is an OS?
The Unix Operating System SE 101 Spiros Mancoridis What is an OS? An operating system (OS) is software that manages the resources of a computer Like most managers, the OS aims to manage its resources in a safe and efficient way Examples of computer resources are: CPU, RAM, disk memory, printers, displays, keyboard, mouse, etc The OS also isolates users and application programmers from the underlying computer Operating Systems Microsoft Windows Unix OS Architecture Without an OS, every application would have to implement some part of this software hierarchy ... Unix A popular multi-user, multi-tasking OS Attributes: stability, portability, security Created at Bell Labs by Dennis Ritchie and Ken Thompson (won the ACM Turing Award in 1983) Unix is considered one of the greatest achievements in computer science Has been around since the 1960s in various forms, e.g., AIX, SCO Unix, SunOS, FreeBSD, OpenBSD, NetBSD, Linux, Mac OS X Unix Multiuser and Multitasking Toolbox philosophy Concise syntax Designed by programmers for programmers 1983 ACM Turning Award (Unix) ACM is the Association for Computing Machinery World’s largest educational and scientific computer society Thompson and Ritchie You can become a student member too www.acm.org The ACM awards the Turing Award every year. It is the “Nobel Prize” of computing Named after british mathematician Alan M. Turing (1912-1954) Alan M. Turing Unix Kernel Includes device drivers for computer hardware devices, e.g., graphics cards, network cards, disks A device driver is a program that allows computer -

Oracle Solaris 10 113 Patch List
Oracle® Solaris 10 1/13 Patch List Part No: E27062–01 January 2013 Copyright © 2000, 2013, Oracle and/or its affiliates. All rights reserved. This software and related documentation are provided under a license agreement containing restrictions on use and disclosure and are protected by intellectual property laws. Except as expressly permitted in your license agreement or allowed by law, you may not use, copy, reproduce, translate, broadcast, modify, license, transmit, distribute, exhibit, perform, publish, or display any part, in any form, or by any means. Reverse engineering, disassembly, or decompilation of this software, unless required by law for interoperability, is prohibited. The information contained herein is subject to change without notice and is not warranted to be error-free. If you find any errors, please report them to us in writing. If this is software or related documentation that is delivered to the U.S. Government or anyone licensing it on behalf of the U.S. Government, the following notice is applicable: U.S. GOVERNMENT END USERS. Oracle programs, including any operating system, integrated software, any programs installed on the hardware, and/or documentation, delivered to U.S. Government end users are "commercial computer software" pursuant to the applicable Federal Acquisition Regulation and agency-specific supplemental regulations. As such, use, duplication, disclosure, modification, and adaptation of the programs, including anyoperating system, integrated software, any programs installed on the hardware, and/or documentation, shall be subject to license terms and license restrictions applicable to the programs. No other rights are granted to the U.S. Government. This software or hardware is developed for general use in a variety of information management applications. -

The Evolution of File Systems
The Evolution of File Systems Thomas Rivera, Hitachi Data Systems Craig Harmer, April 2011 SNIA Legal Notice The material contained in this tutorial is copyrighted by the SNIA. Member companies and individuals may use this material in presentations and literature under the following conditions: Any slide or slides used must be reproduced without modification The SNIA must be acknowledged as source of any material used in the body of any document containing material from these presentations. This presentation is a project of the SNIA Education Committee. Neither the Author nor the Presenter is an attorney and nothing in this presentation is intended to be nor should be construed as legal advice or opinion. If you need legal advice or legal opinion please contact an attorney. The information presented herein represents the Author's personal opinion and current understanding of the issues involved. The Author, the Presenter, and the SNIA do not assume any responsibility or liability for damages arising out of any reliance on or use of this information. NO WARRANTIES, EXPRESS OR IMPLIED. USE AT YOUR OWN RISK. The Evolution of File Systems 2 © 2012 Storage Networking Industry Association. All Rights Reserved. 2 Abstract The File Systems Evolution Over time additional file systems appeared focusing on specialized requirements such as: data sharing, remote file access, distributed file access, parallel files access, HPC, archiving, security, etc. Due to the dramatic growth of unstructured data, files as the basic units for data containers are morphing into file objects, providing more semantics and feature- rich capabilities for content processing This presentation will: Categorize and explain the basic principles of currently available file system architectures (e.g. -

Version Management with CVS
Version Management with CVS for cvs 1.11.22 Per Cederqvist et al Copyright c 1993, 1994, 1995, 1996, 1997, 1998, 1999, 2000, 2001, 2002, 2003, 2004, 2005 Free Software Foundation, Inc. Portions Copyright c 1999, 2000, 2001, 2002, 2003, 2004, 2005 Derek R. Price, Copyright c 2002, 2003, 2004, 2005 Ximbiot http://ximbiot.com, Copyright c 1992, 1993, 1999 Signum Support AB, and Copyright c others. Permission is granted to make and distribute verbatim copies of this manual provided the copyright notice and this permission notice are preserved on all copies. Permission is granted to copy and distribute modified versions of this manual under the conditions for verbatim copying, provided also that the entire resulting derived work is distributed under the terms of a permission notice identical to this one. Permission is granted to copy and distribute translations of this manual into another lan- guage, under the above conditions for modified versions, except that this permission notice may be stated in a translation approved by the Free Software Foundation. i Short Contents 1 Overview ..................................... 1 2 The Repository................................. 7 3 Starting a project with CVS ....................... 29 4 Revisions .................................... 33 5 Branching and merging .......................... 41 6 Recursive behavior ............................. 51 7 Adding, removing, and renaming files and directories ...... 53 8 History browsing ............................... 59 9 Handling binary files ............................ 61 10 Multiple developers ............................. 63 11 Revision management ........................... 73 12 Keyword substitution............................ 75 13 Tracking third-party sources ....................... 79 14 How your build system interacts with CVS ............. 83 15 Special Files .................................. 85 A Guide to CVS commands ......................... 87 B Quick reference to CVS commands .................