CWI Scanprofile/PDF/300
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Scheme of Teaching and Examination for BE
Scheme of Teaching and Examination for B.E (CS&E) SEMESTER: III Sl. Subject Course Title Teaching Credits Contact Marks Exam No. Code Department Hours Duration in hrs L T P TOTAL CIE SEE Total 1 MA310 Mathematics III Mathematics 4 0 0 4 4 50 50 100 03 2 CS310 Digital System CSE 4 0 1 5 6 50 50 100 03 Design 3 CS320 Discrete CSE 4 0 0 4 4 50 50 100 03 Mathematical Structures and Combinatorics 4 CS330 Computer CSE 4 0 0 4 4 50 50 100 03 Organization 5 CS340 Data Structures CSE 4 0 1 5 6 50 50 100 03 6 CS350 Object Oriented CSE 4 0 1 5 6 50 50 100 03 Programming with C++ Total Total 27 Total Marks 600 Credits Scheme of Teaching and Examination for B.E (CS&E) SEMESTER: IV Sl. Subject Course Title Teaching Credits Contact Marks Exam No. Code Department Hours Duration in hrs L T P TOTAL CIE SEE Total 1 MA410 Probability, Mathematics 4 0 0 4 4 50 50 100 03 Statistics and Queuing 2 CS410 Operating CSE 4 0 1 5 6 50 50 100 03 Systems 3 CS420 Design and CSE 4 0 1 5 6 50 50 100 03 Analysis of Algorithms 4 CS430 Theory of CSE 4 0 0 4 4 50 50 100 03 Computation 5 CS440 Microprocessors CSE 4 0 1 5 6 50 50 100 03 6 CS450 Data CSE 4 0 0 4 4 50 50 100 03 Communication Total Total 27 Total Marks 600 Credits Scheme of Teaching and Examination for B.E (CS&E) SEMESTER: V Sl. -

B.E Computer Science and Engineering
CURRICULUM B.E. – Computer Science and Engineering Regulations 2019 VISION MISSION “To become a center of excellence • To produce technocrats in the in Computer Science and industry and academia by Engineering and Research to create educating computer concepts and global leaders with holistic growth techniques. and ethical values for the industry • To facilitate the students to and academics.” trigger more creativity by applying modern tools and technologies in the field of computer science and engineering. • To inculcate the spirit of ethical values contributing to the welfare of the society. Department of Computer Science and Engineering Department of CSE, Francis Xavier Engineering College | Regulation 2019 2 Department of CSE, Francis Xavier Engineering College | Regulation 2019 5 B.E.-COMPUTER SCIENCE AND ENGINEERING (REGULATIONS 2019) CHOICE BASED CREDIT SYSTEM SUMMARY OF CREDIT DISTRIBUTION Range Of CREDITS PER SEMESTER Total S. TOTAL CREDITS CATEGORY Credits No CREDIT IN % I II III IV V VI VII VIII Min Max 1 HSS 3 2 3 8 4.5% 9 11 2 BS 12 4 4 4 24 14.5% 21 21 3 ES 8 11 3 22 13.9% 23 26 4 PC 13 17 10 11 8 59 35.75% 59 59 5 PE 6 6 6 6 24 14.5% 24 27 6 OE 3 3 3 3 12 7.3% 12 15 7 EEC 2 2 1 10 15 9.1% 12 15 TOTAL 23 18 20 23 22 22 21 16 165 100% - - BS - Basic Sciences ES - Engineering Sciences HSS - Humanities and Social Sciences PC - Professional Core PE - Professional Elective OE - Open Elective EEC - Employability Enhancement Course Department of CSE, Francis Xavier Engineering College | Regulation 2019 6 B.E.- COMPUTER SCIENCE AND ENGINEERING (REGULATIONS 2019) CHOICE BASED CREDIT SYSTEM I – VIII SEMESTERS CURRICULUM AND SYLLABI FIRST SEMESTER Code No. -

Compiler Design
CCOOMMPPIILLEERR DDEESSIIGGNN -- PPAARRSSEERR http://www.tutorialspoint.com/compiler_design/compiler_design_parser.htm Copyright © tutorialspoint.com In the previous chapter, we understood the basic concepts involved in parsing. In this chapter, we will learn the various types of parser construction methods available. Parsing can be defined as top-down or bottom-up based on how the parse-tree is constructed. Top-Down Parsing We have learnt in the last chapter that the top-down parsing technique parses the input, and starts constructing a parse tree from the root node gradually moving down to the leaf nodes. The types of top-down parsing are depicted below: Recursive Descent Parsing Recursive descent is a top-down parsing technique that constructs the parse tree from the top and the input is read from left to right. It uses procedures for every terminal and non-terminal entity. This parsing technique recursively parses the input to make a parse tree, which may or may not require back-tracking. But the grammar associated with it ifnotleftfactored cannot avoid back- tracking. A form of recursive-descent parsing that does not require any back-tracking is known as predictive parsing. This parsing technique is regarded recursive as it uses context-free grammar which is recursive in nature. Back-tracking Top- down parsers start from the root node startsymbol and match the input string against the production rules to replace them ifmatched. To understand this, take the following example of CFG: S → rXd | rZd X → oa | ea Z → ai For an input string: read, a top-down parser, will behave like this: It will start with S from the production rules and will match its yield to the left-most letter of the input, i.e. -

Compiler Construction
UNIVERSITY OF CAMBRIDGE Compiler Construction An 18-lecture course Alan Mycroft Computer Laboratory, Cambridge University http://www.cl.cam.ac.uk/users/am/ Lent Term 2007 Compiler Construction 1 Lent Term 2007 Course Plan UNIVERSITY OF CAMBRIDGE Part A : intro/background Part B : a simple compiler for a simple language Part C : implementing harder things Compiler Construction 2 Lent Term 2007 A compiler UNIVERSITY OF CAMBRIDGE A compiler is a program which translates the source form of a program into a semantically equivalent target form. • Traditionally this was machine code or relocatable binary form, but nowadays the target form may be a virtual machine (e.g. JVM) or indeed another language such as C. • Can appear a very hard program to write. • How can one even start? • It’s just like juggling too many balls (picking instructions while determining whether this ‘+’ is part of ‘++’ or whether its right operand is just a variable or an expression ...). Compiler Construction 3 Lent Term 2007 How to even start? UNIVERSITY OF CAMBRIDGE “When finding it hard to juggle 4 balls at once, juggle them each in turn instead ...” character -token -parse -intermediate -target stream stream tree code code syn trans cg lex A multi-pass compiler does one ‘simple’ thing at once and passes its output to the next stage. These are pretty standard stages, and indeed language and (e.g. JVM) system design has co-evolved around them. Compiler Construction 4 Lent Term 2007 Compilers can be big and hard to understand UNIVERSITY OF CAMBRIDGE Compilers can be very large. In 2004 the Gnu Compiler Collection (GCC) was noted to “[consist] of about 2.1 million lines of code and has been in development for over 15 years”. -

Unit-5 Parsers
UNIT-5 PARSERS LR Parsers: • The most powerful shift-reduce parsing (yet efficient) is: • LR parsing is attractive because: – LR parsing is most general non-backtracking shift-reduce parsing, yet it is still efficient. – The class of grammars that can be parsed using LR methods is a proper superset of the class of grammars that can be parsed with predictive parsers. LL(1)-Grammars ⊂ LR(1)-Grammars – An LR-parser can detect a syntactic error as soon as it is possible to do so a left-to-right scan of the input. – covers wide range of grammars. • SLR – simple LR parser • LR – most general LR parser • LALR – intermediate LR parser (look-head LR parser) • SLR, LR and LALR work same (they used the same algorithm), only their parsing tables are different. LR Parsing Algorithm: A Configuration of LR Parsing Algorithm: A configuration of a LR parsing is: • Sm and ai decides the parser action by consulting the parsing action table. (Initial Stack contains just So ) • A configuration of a LR parsing represents the right sentential form: X1 ... Xm ai ai+1 ... an $ Actions of A LR-Parser: 1. shift s -- shifts the next input symbol and the state s onto the stack ( So X1 S1 ... Xm Sm, ai ai+1 ... an $ ) è ( So X1 S1 ..Xm Sm ai s, ai+1 ...an $ ) 2. reduce Aβ→ (or rn where n is a production number) – pop 2|β| (=r) items from the stack; – then push A and s where s=goto[sm-r,A] ( So X1 S1 ... Xm Sm, ai ai+1 .. -
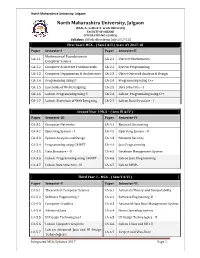
2017-18 MCA – I Integrated.Pdf
North Maharashtra University, Jalgaon North Maharashtra University, Jalgaon (NAAC Accredited ‘A’ Grade University) FACULTY OF SCIENCE INTEGRATED MCA (I-MCA) Syllabus (With effect from July 2017-18) First Year I-MCA – ( Sem I & II ) w.e.f. AY 2017-18 Paper Semester-I Paper Semester-II Mathematical Foundations in CA-1.1 CA-2.1 Discrete Mathematics Computer Science CA-1.2 Computer & Internet Fundamentals CA-2.2 System Programming CA-1.3 Computer Organization & Architecture CA-2.3 Object Oriented Analysis & Design CA-1.4 Programming using C CA-2.4 Programming using C++ CA-1.5 Essentials of Web Designing CA-2.5 Data Structure – I CA-1.6 Lab on Programming using C CA-2.6 Lab on Programming using C++ CA-1.7 Lab on Essentials of Web Designing CA-2.7 Lab on Data Structure - I Second Year I-MCA – ( Sem III & IV ) Paper Semester-III Paper Semester-IV CA-3.1 Computer Networks CA-4.1 Basics of Accounting CA-3.2 Operating System – I CA-4.2 Operating System - II CA-3.3 System Analysis and Design CA-4.3 Network Security CA-3.4 Programming using C#.NET CA-4.4 Java Programming CA-3.5 Data Structure – II CA-4.5 Database Management System CA-3.6 Lab on Programming using C#.NET CA-4.6 Lab on Java Programming CA-3.7 Lab on Data Structure - II CA-4.7 Lab on DBMS Third Year I – MCA – ( Sem V & VI ) Paper Semester-V Paper Semester-VI CA-5.1 Theoretical Computer Science CA-6.1 Automata Theory and Computability CA-5.2 Software Engineering-I CA-6.2 Software Engineering-II CA-5.3 Computer Graphics CA-6.3 Advanced Data Base Management System CA-5.4 Advanced Java CA-6.4 -

Compiler Construction
Compiler construction PDF generated using the open source mwlib toolkit. See http://code.pediapress.com/ for more information. PDF generated at: Sat, 10 Dec 2011 02:23:02 UTC Contents Articles Introduction 1 Compiler construction 1 Compiler 2 Interpreter 10 History of compiler writing 14 Lexical analysis 22 Lexical analysis 22 Regular expression 26 Regular expression examples 37 Finite-state machine 41 Preprocessor 51 Syntactic analysis 54 Parsing 54 Lookahead 58 Symbol table 61 Abstract syntax 63 Abstract syntax tree 64 Context-free grammar 65 Terminal and nonterminal symbols 77 Left recursion 79 Backus–Naur Form 83 Extended Backus–Naur Form 86 TBNF 91 Top-down parsing 91 Recursive descent parser 93 Tail recursive parser 98 Parsing expression grammar 100 LL parser 106 LR parser 114 Parsing table 123 Simple LR parser 125 Canonical LR parser 127 GLR parser 129 LALR parser 130 Recursive ascent parser 133 Parser combinator 140 Bottom-up parsing 143 Chomsky normal form 148 CYK algorithm 150 Simple precedence grammar 153 Simple precedence parser 154 Operator-precedence grammar 156 Operator-precedence parser 159 Shunting-yard algorithm 163 Chart parser 173 Earley parser 174 The lexer hack 178 Scannerless parsing 180 Semantic analysis 182 Attribute grammar 182 L-attributed grammar 184 LR-attributed grammar 185 S-attributed grammar 185 ECLR-attributed grammar 186 Intermediate language 186 Control flow graph 188 Basic block 190 Call graph 192 Data-flow analysis 195 Use-define chain 201 Live variable analysis 204 Reaching definition 206 Three address -

Principled Procedural Parsing Nicolas Laurent
Principled Procedural Parsing Nicolas Laurent August 2019 Thesis submitted in partial fulfillment of the requirements for the degree of Doctor of Applied Science in Engineering Institute of Information and Communication Technologies, Electronics and Applied Mathematics (ICTEAM) Louvain School of Engineering (EPL) Université catholique de Louvain (UCLouvain) Louvain-la-Neuve Belgium Thesis Committee Prof. Kim Mens, Advisor UCLouvain/ICTEAM, Belgium Prof. Charles Pecheur, Chair UCLouvain/ICTEAM, Belgium Prof. Peter Van Roy UCLouvain/ICTEAM Belgium Prof. Anya Helene Bagge UIB/II, Norway Prof. Tijs van der Storm CWI/SWAT & UG, The Netherlands Contents Contents3 1 Introduction7 1.1 Parsing............................7 1.2 Inadequacy: Flexibility Versus Simplicity.........8 1.3 The Best of Both Worlds.................. 10 1.4 The Approach: Principled Procedural Parsing....... 13 1.5 Autumn: Architecture of a Solution............ 15 1.6 Overview & Contributions.................. 17 2 Background 23 2.1 Context Free Grammars (CFGs).............. 23 2.1.1 The CFG Formalism................. 23 2.1.2 CFG Parsing Algorithms.............. 25 2.1.3 Top-Down Parsers.................. 26 2.1.4 Bottom-Up Parsers.................. 30 2.1.5 Chart Parsers..................... 33 2.2 Top-Down Recursive-Descent Ad-Hoc Parsers....... 35 2.3 Parser Combinators..................... 36 2.4 Parsing Expression Grammars (PEGs)........... 39 2.4.1 Expressions, Ordered Choice and Lookahead... 39 2.4.2 PEGs and Recursive-Descent Parsers........ 42 2.4.3 The Single Parse Rule, Greed and (Lack of) Ambi- guity.......................... 43 2.4.4 The PEG Algorithm................. 44 2.4.5 Packrat Parsing.................... 45 2.5 Expression Parsing...................... 47 2.6 Error Reporting........................ 50 2.6.1 Overview....................... 51 2.6.2 The Furthest Error Heuristic........... -

UNIT – IV PARSERS Role of Parsers, Classification of Parsers: Top Down Parsers- Recursive Descent Parser and Predictive Parser
UNIT – IV PARSERS Role of parsers, Classification of Parsers: Top down parsers- recursive descent parser and predictive parser. Bottom up Parsers – Shift Reduce: SLR, CLR and LALR parsers. Error Detection and Recovery in Parser. YACC specification and Automatic construction of Parser (YACC). YACC • What is YACC ? – developed by Stephen C. Johnson. – Yacc (for "yet another compiler compiler." ) is the standard parser generator for the Unix operating system. – An open source program, yacc generates code for the parser in the C programming language. – It is a Look Ahead Left-to-Right (LALR) parser generator, 2 How YACC Works y.tab.h YACC source (*.y) yacc y.tab.c y.output (1) Parser generation time y.tab.c C compiler/linker a.out (2) Compile time Abstract Token stream a.out Syntax Tree (3) Run time 3 YACC File Format %{ C declarations %} yacc declarations %% Grammar rules %% Additional C code – Comments enclosed in /* ... */ may appear in any of the sections. 4 Definitions Section %{ #include <stdio.h> #include <stdlib.h> %} It is a terminal %token ID NUM %start expr 5 YACC Declaration Summary `%start' Specify the grammar's start symbol `%union' Declare the collection of data types that semantic values may have `%token' Declare a terminal symbol (token type name) with no precedence or associativity specified `%type' Declare the type of semantic values for a nonterminal symbol 6 YACC Declaration `%right' Declare a terminal symbol (token type name) that is right-associative `%left' Declare a terminal symbol (token type name) that is left-associative `%nonassoc' Declare a terminal symbol (token type name) that is nonassociative (using it in a way that would be associative is a syntax error, ex: x op. -

B. Tech. W. E. F. 2015-16 Admitted Batch
REGULATIONS AND SYLLABUS of Bachelor of Technology in Computer Science and Engineering (w.e.f 2015-16 admitted batch) A University Committed to Excellence . B.Tech. in Computer Science and Engineering REGULATIONS (w.e.f. 2015-16 admitted batch) 1. ADMISSION 1.1 Admission into B.Tech. in Computer Science and Engineering program of GITAM University is governed by GITAM University admission regulations. 2. ELIGIBILITY CRITERIA 2.1 A first class in 10+2 or equivalent examination approved by GITAM University with Physics, Chemistry and Mathematics. 2.2 Admission into B.Tech. will be based on an All India Entrance Test (GAT) conducted by GITAM University and the rule of reservation, wherever applicable, will be followed. 3. CHOICE BASED CREDIT SYSTEM 3.1 Choice Based Credit System (CBCS) is introduced with effect from the admitted Batch of 2015-16 based on UGC guidelines in order to promote: • Student centered learning • Cafeteria approach • Students to learn courses of their choice • Learning at their own pace • Interdisciplinary learning 3.2 Learning goals/objectives and outcomes are specified, focusing on what a student should be able to do at the end of the program. 4. STRUCTURE OF THE PROGRAM 4.1 The Program consists of i) Foundation Courses (compulsory) which give general exposure to a student in communication and subject related area. ii) Core Courses (compulsory). iii) Discipline centric electives which a) are supportive to the discipline Programme b) give expanded scope of the subject} Electives c) give interdisciplinary exposure} Interdisciplinary d) nurture the student skills Electives 1 iv) Open electives are of general nature either related or unrelated to the discipline. -

MCA Part III Paper- XIX Topic: Parsing Prepared By
MCA Part III Paper- XIX Topic: Parsing Prepared by: Dr. Kiran Pandey School of Computer science Email-Id: [email protected] INTRODUCTION The output of syntax analysis is a parse tree. Parse tree is used in the subsequent phases of compilation. This process of analyzing the syntax of the language is done by a module in the compiler called parser. The process of verifying whether an input string matches the grammar of the language is called parsing. The syntax analyzer gets the string of tokens from the lexical analyzer. It then verifies the syntax of input string by verifying whether the input string can be derived from the grammar or not. If the input string is derived from the grammar then the syntax is correct otherwise it is not derivable and the syntax is wrong. The parser will report syntactical errors in a manner that is easily understood by the user. It has procedures to recover from these errors and to continue parsing action. The output of a parser is a parse tree. The figure below shows the position of a parser in the compiler. Figure 1: Position of parser in a Compiler. TYPES OF PARSING Syntax analyzers follow production rules defined by means of context-free grammar. The way the production rules are implemented (derivation) divides parsing into two types: top-down parsing and bottom-up parsing. Figure 2: Types of Parsing TOP DOWN PARSING, We have learnt in the last chapter that the top-down parsing technique parses the input, and starts constructing a parse tree from the root node gradually moving down to the leaf nodes. -

Cs6601 Distributed Systems Part A
VSB ENGINEERING COLLEGE, KARUR – 639 111 DEPARTMENT OF INFORMATION TECHNOLOGY Academic Year: 2017-18(EVEN Semester) CS6601 DISTRIBUTED SYSTEMS PART A UNIT-I INTRODUCTION 1. Define distributed system. A distributed system is a collection of independent computers that appears to its users as a single coherent system. A distributed system is one in which components located at networked communicate and coordinate their actions only by passing message. 2. List the characteristics of distributed system. Programs are executed concurrently There is no global time Components can fail independently 3. Mention the challenges in distributed system. Heterogeneity Openness Security Scalability Failure handling Concurrency Transparency 4. Define heterogeneity. The Internet enables users to access services and run applications over a heterogeneous collection of computers and networks. Heterogeneity (that is, variety and difference) applies to all of the following: Networks; Computer Hardware; Operating Systems; Programming Languages; Implementations By Different Developers. 5. Why do we need openness? The openness of a computer system is the characteristic that determines whether the system can be extended and reimplemented in various ways. The openness of distributed systems is determined primarily by the degree to which new resource-sharing services can be added and be made available for use by a variety of client programs. 6. Define scalability. Distributed systems operate effectively and efficiently at many different scales, ranging from a small intranet to the Internet. A system is described as scalable if it will remain effective when there is a significant increase in the number of resources and the number of users. 7. What are the types of transparencies? Various transparencies types are as follows, Access transparency Location transparency 1 Concurrency transparency Replication transparency Failure transparency Performance transparency Scaling transparency 8.