Compiler Construction
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-
Syntax-Directed Translation, Parse Trees, Abstract Syntax Trees
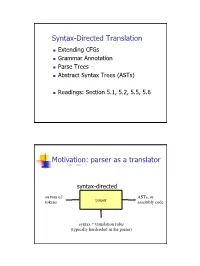
Syntax-Directed Translation Extending CFGs Grammar Annotation Parse Trees Abstract Syntax Trees (ASTs) Readings: Section 5.1, 5.2, 5.5, 5.6 Motivation: parser as a translator syntax-directed translation stream of ASTs, or tokens parser assembly code syntax + translation rules (typically hardcoded in the parser) 1 Mechanism of syntax-directed translation syntax-directed translation is done by extending the CFG a translation rule is defined for each production given X Æ d A B c the translation of X is defined in terms of translation of nonterminals A, B values of attributes of terminals d, c constants To translate an input string: 1. Build the parse tree. 2. Working bottom-up • Use the translation rules to compute the translation of each nonterminal in the tree Result: the translation of the string is the translation of the parse tree's root nonterminal Why bottom up? a nonterminal's value may depend on the value of the symbols on the right-hand side, so translate a non-terminal node only after children translations are available 2 Example 1: arith expr to its value Syntax-directed translation: the CFG translation rules E Æ E + T E1.trans = E2.trans + T.trans E Æ T E.trans = T.trans T Æ T * F T1.trans = T2.trans * F.trans T Æ F T.trans = F.trans F Æ int F.trans = int.value F Æ ( E ) F.trans = E.trans Example 1 (cont) E (18) Input: 2 * (4 + 5) T (18) T (2) * F (9) F (2) ( E (9) ) int (2) E (4) * T (5) Annotated Parse Tree T (4) F (5) F (4) int (5) int (4) 3 Example 2: Compute type of expr E -> E + E if ((E2.trans == INT) and (E3.trans == INT) then E1.trans = INT else E1.trans = ERROR E -> E and E if ((E2.trans == BOOL) and (E3.trans == BOOL) then E1.trans = BOOL else E1.trans = ERROR E -> E == E if ((E2.trans == E3.trans) and (E2.trans != ERROR)) then E1.trans = BOOL else E1.trans = ERROR E -> true E.trans = BOOL E -> false E.trans = BOOL E -> int E.trans = INT E -> ( E ) E1.trans = E2.trans Example 2 (cont) Input: (2 + 2) == 4 1. -

Derivatives of Parsing Expression Grammars
Derivatives of Parsing Expression Grammars Aaron Moss Cheriton School of Computer Science University of Waterloo Waterloo, Ontario, Canada [email protected] This paper introduces a new derivative parsing algorithm for recognition of parsing expression gram- mars. Derivative parsing is shown to have a polynomial worst-case time bound, an improvement on the exponential bound of the recursive descent algorithm. This work also introduces asymptotic analysis based on inputs with a constant bound on both grammar nesting depth and number of back- tracking choices; derivative and recursive descent parsing are shown to run in linear time and constant space on this useful class of inputs, with both the theoretical bounds and the reasonability of the in- put class validated empirically. This common-case constant memory usage of derivative parsing is an improvement on the linear space required by the packrat algorithm. 1 Introduction Parsing expression grammars (PEGs) are a parsing formalism introduced by Ford [6]. Any LR(k) lan- guage can be represented as a PEG [7], but there are some non-context-free languages that may also be represented as PEGs (e.g. anbncn [7]). Unlike context-free grammars (CFGs), PEGs are unambiguous, admitting no more than one parse tree for any grammar and input. PEGs are a formalization of recursive descent parsers allowing limited backtracking and infinite lookahead; a string in the language of a PEG can be recognized in exponential time and linear space using a recursive descent algorithm, or linear time and space using the memoized packrat algorithm [6]. PEGs are formally defined and these algo- rithms outlined in Section 3. -

Scheme of Teaching and Examination for BE
Scheme of Teaching and Examination for B.E (CS&E) SEMESTER: III Sl. Subject Course Title Teaching Credits Contact Marks Exam No. Code Department Hours Duration in hrs L T P TOTAL CIE SEE Total 1 MA310 Mathematics III Mathematics 4 0 0 4 4 50 50 100 03 2 CS310 Digital System CSE 4 0 1 5 6 50 50 100 03 Design 3 CS320 Discrete CSE 4 0 0 4 4 50 50 100 03 Mathematical Structures and Combinatorics 4 CS330 Computer CSE 4 0 0 4 4 50 50 100 03 Organization 5 CS340 Data Structures CSE 4 0 1 5 6 50 50 100 03 6 CS350 Object Oriented CSE 4 0 1 5 6 50 50 100 03 Programming with C++ Total Total 27 Total Marks 600 Credits Scheme of Teaching and Examination for B.E (CS&E) SEMESTER: IV Sl. Subject Course Title Teaching Credits Contact Marks Exam No. Code Department Hours Duration in hrs L T P TOTAL CIE SEE Total 1 MA410 Probability, Mathematics 4 0 0 4 4 50 50 100 03 Statistics and Queuing 2 CS410 Operating CSE 4 0 1 5 6 50 50 100 03 Systems 3 CS420 Design and CSE 4 0 1 5 6 50 50 100 03 Analysis of Algorithms 4 CS430 Theory of CSE 4 0 0 4 4 50 50 100 03 Computation 5 CS440 Microprocessors CSE 4 0 1 5 6 50 50 100 03 6 CS450 Data CSE 4 0 0 4 4 50 50 100 03 Communication Total Total 27 Total Marks 600 Credits Scheme of Teaching and Examination for B.E (CS&E) SEMESTER: V Sl. -

CWI Scanprofile/PDF/300
Centrum voor Wiskunde en lnformatica Centre for Mathematics and Computer Science J. Heering, P. Klint, J.G. Rekers Incremental generation of parsers , Computer Science/Department of Software Technology Report CS-R8822 May Biblk>tlleek Centrum ypor Wisl~unde en lnformatk:a Am~tel>dam The Centre for Mathematics and Computer Science is a research institute of the Stichting Mathematisch Centrum, which was founded on February 11, 1946, as a nonprofit institution aim ing at the promotion of mathematics, computer science, and their applications. It is sponsored by the Dutch Government through the Netherlands Organization for the Advancement of Pure Research (Z.W.0.). q\ ' Copyright (t:: Stichting Mathematisch Centrum, Amsterdam 1 Incremental Generation of Parsers J. Heering Department of Software Technology, Centre for Mathematics and Computer Science P.O. Box 4079, 1009 AS Amsterdam, The Netherlands P. Klint Department of Software Technology, Centre for Mathematics and Computer Science P.O. Box 4079, 1009 AS Amsterdam, The Netherlands and Programming Research Group, University of Amsterdam P.O. BOX 41882, 1009 DB Amsterdam, The Netherlands J. Rekers Department of Software Technology, Centre for Mathematics and Computer Science P.O. Box 4079, 1009 AB Amsterdam, The Netherlands A parser checks whether a text is a sentence in a language. Therefore, the parser is provided with the grammar of the language, and it usually generates a structure (parse tree) that represents the text according to that grammar. Most present-day parsers are not directly driven by the grammar but by a 'parse table', which is generated by a parse table generator. A table based parser wolks more efficiently than a grammar based parser does, and provided that the parser is used often enough, the cost of gen erating the parse table is outweighed by the gain in parsing efficiency. -

Parsing 1. Grammars and Parsing 2. Top-Down and Bottom-Up Parsing 3
Syntax Parsing syntax: from the Greek syntaxis, meaning “setting out together or arrangement.” 1. Grammars and parsing Refers to the way words are arranged together. 2. Top-down and bottom-up parsing Why worry about syntax? 3. Chart parsers • The boy ate the frog. 4. Bottom-up chart parsing • The frog was eaten by the boy. 5. The Earley Algorithm • The frog that the boy ate died. • The boy whom the frog was eaten by died. Slide CS474–1 Slide CS474–2 Grammars and Parsing Need a grammar: a formal specification of the structures allowable in Syntactic Analysis the language. Key ideas: Need a parser: algorithm for assigning syntactic structure to an input • constituency: groups of words may behave as a single unit or phrase sentence. • grammatical relations: refer to the subject, object, indirect Sentence Parse Tree object, etc. Beavis ate the cat. S • subcategorization and dependencies: refer to certain kinds of relations between words and phrases, e.g. want can be followed by an NP VP infinitive, but find and work cannot. NAME V NP All can be modeled by various kinds of grammars that are based on ART N context-free grammars. Beavis ate the cat Slide CS474–3 Slide CS474–4 CFG example CFG’s are also called phrase-structure grammars. CFG’s Equivalent to Backus-Naur Form (BNF). A context free grammar consists of: 1. S → NP VP 5. NAME → Beavis 1. a set of non-terminal symbols N 2. VP → V NP 6. V → ate 2. a set of terminal symbols Σ (disjoint from N) 3. -

Abstract Syntax Trees & Top-Down Parsing
Abstract Syntax Trees & Top-Down Parsing Review of Parsing • Given a language L(G), a parser consumes a sequence of tokens s and produces a parse tree • Issues: – How do we recognize that s ∈ L(G) ? – A parse tree of s describes how s ∈ L(G) – Ambiguity: more than one parse tree (possible interpretation) for some string s – Error: no parse tree for some string s – How do we construct the parse tree? Compiler Design 1 (2011) 2 Abstract Syntax Trees • So far, a parser traces the derivation of a sequence of tokens • The rest of the compiler needs a structural representation of the program • Abstract syntax trees – Like parse trees but ignore some details – Abbreviated as AST Compiler Design 1 (2011) 3 Abstract Syntax Trees (Cont.) • Consider the grammar E → int | ( E ) | E + E • And the string 5 + (2 + 3) • After lexical analysis (a list of tokens) int5 ‘+’ ‘(‘ int2 ‘+’ int3 ‘)’ • During parsing we build a parse tree … Compiler Design 1 (2011) 4 Example of Parse Tree E • Traces the operation of the parser E + E • Captures the nesting structure • But too much info int5 ( E ) – Parentheses – Single-successor nodes + E E int 2 int3 Compiler Design 1 (2011) 5 Example of Abstract Syntax Tree PLUS PLUS 5 2 3 • Also captures the nesting structure • But abstracts from the concrete syntax a more compact and easier to use • An important data structure in a compiler Compiler Design 1 (2011) 6 Semantic Actions • This is what we’ll use to construct ASTs • Each grammar symbol may have attributes – An attribute is a property of a programming language construct -

B.E Computer Science and Engineering
CURRICULUM B.E. – Computer Science and Engineering Regulations 2019 VISION MISSION “To become a center of excellence • To produce technocrats in the in Computer Science and industry and academia by Engineering and Research to create educating computer concepts and global leaders with holistic growth techniques. and ethical values for the industry • To facilitate the students to and academics.” trigger more creativity by applying modern tools and technologies in the field of computer science and engineering. • To inculcate the spirit of ethical values contributing to the welfare of the society. Department of Computer Science and Engineering Department of CSE, Francis Xavier Engineering College | Regulation 2019 2 Department of CSE, Francis Xavier Engineering College | Regulation 2019 5 B.E.-COMPUTER SCIENCE AND ENGINEERING (REGULATIONS 2019) CHOICE BASED CREDIT SYSTEM SUMMARY OF CREDIT DISTRIBUTION Range Of CREDITS PER SEMESTER Total S. TOTAL CREDITS CATEGORY Credits No CREDIT IN % I II III IV V VI VII VIII Min Max 1 HSS 3 2 3 8 4.5% 9 11 2 BS 12 4 4 4 24 14.5% 21 21 3 ES 8 11 3 22 13.9% 23 26 4 PC 13 17 10 11 8 59 35.75% 59 59 5 PE 6 6 6 6 24 14.5% 24 27 6 OE 3 3 3 3 12 7.3% 12 15 7 EEC 2 2 1 10 15 9.1% 12 15 TOTAL 23 18 20 23 22 22 21 16 165 100% - - BS - Basic Sciences ES - Engineering Sciences HSS - Humanities and Social Sciences PC - Professional Core PE - Professional Elective OE - Open Elective EEC - Employability Enhancement Course Department of CSE, Francis Xavier Engineering College | Regulation 2019 6 B.E.- COMPUTER SCIENCE AND ENGINEERING (REGULATIONS 2019) CHOICE BASED CREDIT SYSTEM I – VIII SEMESTERS CURRICULUM AND SYLLABI FIRST SEMESTER Code No. -

Compiler Design
CCOOMMPPIILLEERR DDEESSIIGGNN -- PPAARRSSEERR http://www.tutorialspoint.com/compiler_design/compiler_design_parser.htm Copyright © tutorialspoint.com In the previous chapter, we understood the basic concepts involved in parsing. In this chapter, we will learn the various types of parser construction methods available. Parsing can be defined as top-down or bottom-up based on how the parse-tree is constructed. Top-Down Parsing We have learnt in the last chapter that the top-down parsing technique parses the input, and starts constructing a parse tree from the root node gradually moving down to the leaf nodes. The types of top-down parsing are depicted below: Recursive Descent Parsing Recursive descent is a top-down parsing technique that constructs the parse tree from the top and the input is read from left to right. It uses procedures for every terminal and non-terminal entity. This parsing technique recursively parses the input to make a parse tree, which may or may not require back-tracking. But the grammar associated with it ifnotleftfactored cannot avoid back- tracking. A form of recursive-descent parsing that does not require any back-tracking is known as predictive parsing. This parsing technique is regarded recursive as it uses context-free grammar which is recursive in nature. Back-tracking Top- down parsers start from the root node startsymbol and match the input string against the production rules to replace them ifmatched. To understand this, take the following example of CFG: S → rXd | rZd X → oa | ea Z → ai For an input string: read, a top-down parser, will behave like this: It will start with S from the production rules and will match its yield to the left-most letter of the input, i.e. -

Advanced Parsing Techniques
Advanced Parsing Techniques Announcements ● Written Set 1 graded. ● Hard copies available for pickup right now. ● Electronic submissions: feedback returned later today. Where We Are Where We Are Parsing so Far ● We've explored five deterministic parsing algorithms: ● LL(1) ● LR(0) ● SLR(1) ● LALR(1) ● LR(1) ● These algorithms all have their limitations. ● Can we parse arbitrary context-free grammars? Why Parse Arbitrary Grammars? ● They're easier to write. ● Can leave operator precedence and associativity out of the grammar. ● No worries about shift/reduce or FIRST/FOLLOW conflicts. ● If ambiguous, can filter out invalid trees at the end. ● Generate candidate parse trees, then eliminate them when not needed. ● Practical concern for some languages. ● We need to have C and C++ compilers! Questions for Today ● How do you go about parsing ambiguous grammars efficiently? ● How do you produce all possible parse trees? ● What else can we do with a general parser? The Earley Parser Motivation: The Limits of LR ● LR parsers use shift and reduce actions to reduce the input to the start symbol. ● LR parsers cannot deterministically handle shift/reduce or reduce/reduce conflicts. ● However, they can nondeterministically handle these conflicts by guessing which option to choose. ● What if we try all options and see if any of them work? The Earley Parser ● Maintain a collection of Earley items, which are LR(0) items annotated with a start position. ● The item A → α·ω @n means we are working on recognizing A → αω, have seen α, and the start position of the item was the nth token. ● Using techniques similar to LR parsing, try to scan across the input creating these items. -

Lecture 3: Recursive Descent Limitations, Precedence Climbing
Lecture 3: Recursive descent limitations, precedence climbing David Hovemeyer September 9, 2020 601.428/628 Compilers and Interpreters Today I Limitations of recursive descent I Precedence climbing I Abstract syntax trees I Supporting parenthesized expressions Before we begin... Assume a context-free struct Node *Parser::parse_A() { grammar has the struct Node *next_tok = lexer_peek(m_lexer); following productions on if (!next_tok) { the nonterminal A: error("Unexpected end of input"); } A → b C A → d E struct Node *a = node_build0(NODE_A); int tag = node_get_tag(next_tok); (A, C, E are if (tag == TOK_b) { nonterminals; b, d are node_add_kid(a, expect(TOK_b)); node_add_kid(a, parse_C()); terminals) } else if (tag == TOK_d) { What is the problem node_add_kid(a, expect(TOK_d)); node_add_kid(a, parse_E()); with the parse function } shown on the right? return a; } Limitations of recursive descent Recall: a better infix expression grammar Grammar (start symbol is A): A → i = A T → T*F A → E T → T/F E → E + T T → F E → E-T F → i E → T F → n Precedence levels: Nonterminal Precedence Meaning Operators Associativity A lowest Assignment = right E Expression + - left T Term * / left F highest Factor No Parsing infix expressions Can we write a recursive descent parser for infix expressions using this grammar? Parsing infix expressions Can we write a recursive descent parser for infix expressions using this grammar? No Left recursion Left-associative operators want to have left-recursive productions, but recursive descent parsers can’t handle left recursion -
Top-Down Parsing & Bottom-Up Parsing I
Top-Down Parsing and Introduction to Bottom-Up Parsing Lecture 7 Instructor: Fredrik Kjolstad Slide design by Prof. Alex Aiken, with modifications 1 Predictive Parsers • Like recursive-descent but parser can “predict” which production to use – By looking at the next few tokens – No backtracking • Predictive parsers accept LL(k) grammars – L means “left-to-right” scan of input – L means “leftmost derivation” – k means “predict based on k tokens of lookahead” – In practice, LL(1) is used 2 LL(1) vs. Recursive Descent • In recursive-descent, – At each step, many choices of production to use – Backtracking used to undo bad choices • In LL(1), – At each step, only one choice of production – That is • When a non-terminal A is leftmost in a derivation • And the next input symbol is t • There is a unique production A ® a to use – Or no production to use (an error state) • LL(1) is a recursive descent variant without backtracking 3 Predictive Parsing and Left Factoring • Recall the grammar E ® T + E | T T ® int | int * T | ( E ) • Hard to predict because – For T two productions start with int – For E it is not clear how to predict • We need to left-factor the grammar 4 Left-Factoring Example • Recall the grammar E ® T + E | T T ® int | int * T | ( E ) • Factor out common prefixes of productions E ® T X X ® + E | e T ® int Y | ( E ) Y ® * T | e 5 LL(1) Parsing Table Example • Left-factored grammar E ® T X X ® + E | e T ® ( E ) | int Y Y ® * T | e • The LL(1) parsing table: next input token int * + ( ) $ E T X T X X + E e e T int Y ( E ) Y * T e e e rhs of production to use 6 leftmost non-terminal E ® T X X ® + E | e T ® ( E ) | int Y Y ® * T | e LL(1) Parsing Table Example • Consider the [E, int] entry – “When current non-terminal is E and next input is int, use production E ® T X” – This can generate an int in the first position int * + ( ) $ E T X T X X + E e e T int Y ( E ) Y * T e e e 7 E ® T X X ® + E | e T ® ( E ) | int Y Y ® * T | e LL(1) Parsing Tables. -

Parse Trees (=Derivation Tree) by Constructing a Derivation
CFG: Parsing •Generative aspect of CFG: By now it should be clear how, from a CFG G, you can derive strings wÎL(G). CFG: Parsing •Analytical aspect: Given a CFG G and strings w, how do you decide if wÎL(G) and –if so– how do you determine the derivation tree or the sequence of production rules Recognition of strings in a that produce w? This is called the problem of parsing. language 1 2 CFG: Parsing CFG: Parsing • Parser A program that determines if a string w Î L(G) Parse trees (=Derivation Tree) by constructing a derivation. Equivalently, A parse tree is a graphical representation it searches the graph of G. of a derivation sequence of a sentential form. – Top-down parsers • Constructs the derivation tree from root to leaves. • Leftmost derivation. Tree nodes represent symbols of the – Bottom-up parsers grammar (nonterminals or terminals) and • Constructs the derivation tree from leaves to tree edges represent derivation steps. root. • Rightmost derivation in reverse. 3 4 CFG: Parsing CFG: Parsing Parse Tree: Example Parse Tree: Example 1 E ® E + E | E * E | ( E ) | - E | id Given the following grammar: Lets examine this derivation: E Þ -E Þ -(E) Þ -(E + E) Þ -(id + id) E ® E + E | E * E | ( E ) | - E | id E E E E E Is the string -(id + id) a sentence in this grammar? - E - E - E - E Yes because there is the following derivation: ( E ) ( E ) ( E ) E Þ -E Þ -(E) Þ -(E + E) Þ -(id + id) E + E E + E This is a top-down derivation because we start building the id id parse tree at the top parse tree 5 6 1 CFG: Parsing CFG: Parsing S ® SS | a | b Parse Tree: Example 2 Rightmost Parse Tree: Example 2 abÎ L( S) derivation S Þ SS Þ Sb Þ ab S S S S S S S S Derivation S S S S Derivation S S S S Trees S S Trees a a b S S b a b S S S Leftmost S derivation S Þ SS Þ aS Þ ab Rightmost Derivation a b S S in Reverse 7 8 CFG: Parsing CFG: Parsing Practical Parsers Example 3 Consider the CFG grammar G • Language/Grammar designed to enable deterministic (directed S ® A and backtrack-free) searches.