Chart Parsing and Probabilistic Parsing
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-
Syntax-Directed Translation, Parse Trees, Abstract Syntax Trees
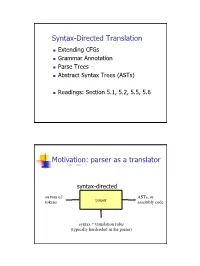
Syntax-Directed Translation Extending CFGs Grammar Annotation Parse Trees Abstract Syntax Trees (ASTs) Readings: Section 5.1, 5.2, 5.5, 5.6 Motivation: parser as a translator syntax-directed translation stream of ASTs, or tokens parser assembly code syntax + translation rules (typically hardcoded in the parser) 1 Mechanism of syntax-directed translation syntax-directed translation is done by extending the CFG a translation rule is defined for each production given X Æ d A B c the translation of X is defined in terms of translation of nonterminals A, B values of attributes of terminals d, c constants To translate an input string: 1. Build the parse tree. 2. Working bottom-up • Use the translation rules to compute the translation of each nonterminal in the tree Result: the translation of the string is the translation of the parse tree's root nonterminal Why bottom up? a nonterminal's value may depend on the value of the symbols on the right-hand side, so translate a non-terminal node only after children translations are available 2 Example 1: arith expr to its value Syntax-directed translation: the CFG translation rules E Æ E + T E1.trans = E2.trans + T.trans E Æ T E.trans = T.trans T Æ T * F T1.trans = T2.trans * F.trans T Æ F T.trans = F.trans F Æ int F.trans = int.value F Æ ( E ) F.trans = E.trans Example 1 (cont) E (18) Input: 2 * (4 + 5) T (18) T (2) * F (9) F (2) ( E (9) ) int (2) E (4) * T (5) Annotated Parse Tree T (4) F (5) F (4) int (5) int (4) 3 Example 2: Compute type of expr E -> E + E if ((E2.trans == INT) and (E3.trans == INT) then E1.trans = INT else E1.trans = ERROR E -> E and E if ((E2.trans == BOOL) and (E3.trans == BOOL) then E1.trans = BOOL else E1.trans = ERROR E -> E == E if ((E2.trans == E3.trans) and (E2.trans != ERROR)) then E1.trans = BOOL else E1.trans = ERROR E -> true E.trans = BOOL E -> false E.trans = BOOL E -> int E.trans = INT E -> ( E ) E1.trans = E2.trans Example 2 (cont) Input: (2 + 2) == 4 1. -

Journal of Computer Science and Engineering Parsing
IJRDO - Journal of Computer Science and Engineering ISSN: 2456-1843 JOURNAL OF COMPUTER SCIENCE AND ENGINEERING PARSING TECHNIQUES Ojesvi Bhardwaj Abstract: ‘Parsing’ is the term used to describe the process of automatically building syntactic analyses of a sentence in terms of a given grammar and lexicon. The resulting syntactic analyses may be used as input to a process of semantic interpretation, (or perhaps phonological interpretation, where aspects of this, like prosody, are sensitive to syntactic structure). Occasionally, ‘parsing’ is also used to include both syntactic and semantic analysis. We use it in the more conservative sense here, however. In most contemporary grammatical formalisms, the output of parsing is something logically equivalent to a tree, displaying dominance and precedence relations between constituents of a sentence, perhaps with further annotations in the form of attribute-value equations (‘features’) capturing other aspects of linguistic description. However, there are many different possible linguistic formalisms, and many ways of representing each of them, and hence many different ways of representing the results of parsing. We shall assume here a simple tree representation, and an underlying context-free grammatical (CFG) formalism. *Student, CSE, Dronachraya Collage of Engineering, Gurgaon Volume-1 | Issue-12 | December, 2015 | Paper-3 29 - IJRDO - Journal of Computer Science and Engineering ISSN: 2456-1843 1. INTRODUCTION Parsing or syntactic analysis is the process of analyzing a string of symbols, either in natural language or in computer languages, according to the rules of a formal grammar. The term parsing comes from Latin pars (ōrātiōnis), meaning part (of speech). The term has slightly different meanings in different branches of linguistics and computer science. -

An Efficient Implementation of the Head-Corner Parser
An Efficient Implementation of the Head-Corner Parser Gertjan van Noord" Rijksuniversiteit Groningen This paper describes an efficient and robust implementation of a bidirectional, head-driven parser for constraint-based grammars. This parser is developed for the OVIS system: a Dutch spoken dialogue system in which information about public transport can be obtained by telephone. After a review of the motivation for head-driven parsing strategies, and head-corner parsing in particular, a nondeterministic version of the head-corner parser is presented. A memorization technique is applied to obtain a fast parser. A goal-weakening technique is introduced, which greatly improves average case efficiency, both in terms of speed and space requirements. I argue in favor of such a memorization strategy with goal-weakening in comparison with ordinary chart parsers because such a strategy can be applied selectively and therefore enormously reduces the space requirements of the parser, while no practical loss in time-efficiency is observed. On the contrary, experiments are described in which head-corner and left-corner parsers imple- mented with selective memorization and goal weakening outperform "standard" chart parsers. The experiments include the grammar of the OV/S system and the Alvey NL Tools grammar. Head-corner parsing is a mix of bottom-up and top-down processing. Certain approaches to robust parsing require purely bottom-up processing. Therefore, it seems that head-corner parsing is unsuitable for such robust parsing techniques. However, it is shown how underspecification (which arises very naturally in a logic programming environment) can be used in the head-corner parser to allow such robust parsing techniques. -

Derivatives of Parsing Expression Grammars
Derivatives of Parsing Expression Grammars Aaron Moss Cheriton School of Computer Science University of Waterloo Waterloo, Ontario, Canada [email protected] This paper introduces a new derivative parsing algorithm for recognition of parsing expression gram- mars. Derivative parsing is shown to have a polynomial worst-case time bound, an improvement on the exponential bound of the recursive descent algorithm. This work also introduces asymptotic analysis based on inputs with a constant bound on both grammar nesting depth and number of back- tracking choices; derivative and recursive descent parsing are shown to run in linear time and constant space on this useful class of inputs, with both the theoretical bounds and the reasonability of the in- put class validated empirically. This common-case constant memory usage of derivative parsing is an improvement on the linear space required by the packrat algorithm. 1 Introduction Parsing expression grammars (PEGs) are a parsing formalism introduced by Ford [6]. Any LR(k) lan- guage can be represented as a PEG [7], but there are some non-context-free languages that may also be represented as PEGs (e.g. anbncn [7]). Unlike context-free grammars (CFGs), PEGs are unambiguous, admitting no more than one parse tree for any grammar and input. PEGs are a formalization of recursive descent parsers allowing limited backtracking and infinite lookahead; a string in the language of a PEG can be recognized in exponential time and linear space using a recursive descent algorithm, or linear time and space using the memoized packrat algorithm [6]. PEGs are formally defined and these algo- rithms outlined in Section 3. -

Generalized Probabilistic LR Parsing of Natural Language (Corpora) with Unification-Based Grammars
Generalized Probabilistic LR Parsing of Natural Language (Corpora) with Unification-Based Grammars Ted Briscoe* John Carroll* University of Cambridge University of Cambridge We describe work toward the construction of a very wide-coverage probabilistic parsing system for natural language (NL), based on LR parsing techniques. The system is intended to rank the large number of syntactic analyses produced by NL grammars according to the frequency of occurrence of the individual rules deployed in each analysis. We discuss a fully automatic procedure for constructing an LR parse table from a unification-based grammar formalism, and consider the suitability of alternative LALR(1) parse table construction methods for large grammars. The parse table is used as the basis for two parsers; a user-driven interactive system that provides a computationally tractable and labor-efficient method of supervised training of the statistical information required to drive the probabilistic parser. The latter is constructed by associating probabilities with the LR parse table directly. This technique is superior to parsers based on probabilistic lexical tagging or probabilistic context-free grammar because it allows for a more context-dependent probabilistic language model, as well as use of a more linguistically adequate grammar formalism. We compare the performance of an optimized variant of Tomita's (1987) generalized LR parsing algorithm to an (efficiently indexed and optimized) chart parser. We report promising results of a pilot study training on 150 noun definitions from the Longman Dictionary of Contemporary English (LDOCE) and retesting on these plus a further 55 definitions. Finally, we discuss limitations of the current system and possible extensions to deal with lexical (syntactic and semantic)frequency of occurrence. -

CS 375, Compilers: Class Notes Gordon S. Novak Jr. Department Of
CS 375, Compilers: Class Notes Gordon S. Novak Jr. Department of Computer Sciences University of Texas at Austin [email protected] http://www.cs.utexas.edu/users/novak Copyright c Gordon S. Novak Jr.1 1A few slides reproduce figures from Aho, Lam, Sethi, and Ullman, Compilers: Principles, Techniques, and Tools, Addison-Wesley; these have footnote credits. 1 I wish to preach not the doctrine of ignoble ease, but the doctrine of the strenuous life. { Theodore Roosevelt Innovation requires Austin, Texas. We need faster chips and great compilers. Both those things are from Austin. { Guy Kawasaki 2 Course Topics • Introduction • Lexical Analysis: characters ! words lexer { Regular grammars { Hand-written lexical analyzer { Number conversion { Regular expressions { LEX • Syntax Analysis: words ! sentences parser { Context-free grammars { Operator precedence { Recursive descent parsing { Shift-reduce parsing, YACC { Intermediate code { Symbol tables • Code Generation { Code generation from trees { Register assignment { Array references { Subroutine calls • Optimization { Constant folding, partial evaluation, Data flow analysis • Object-oriented programming 3 Pascal Test Program program graph1(output); { Jensen & Wirth 4.9 } const d = 0.0625; {1/16, 16 lines for [x,x+1]} s = 32; {32 character widths for [y,y+1]} h = 34; {character position of x-axis} c = 6.28318; {2*pi} lim = 32; var x,y : real; i,n : integer; begin for i := 0 to lim do begin x := d*i; y := exp(-x)*sin(c*x); n := round(s*y) + h; repeat write(' '); n := n-1 until n=0; writeln('*') end end. * * * * * * * * * * * * * * * * * * * * * * * * * * 4 Introduction • What a compiler does; why we need compilers • Parts of a compiler and what they do • Data flow between the parts 5 Machine Language A computer is basically a very fast pocket calculator attached to a large memory. -

LATE Ain't Earley: a Faster Parallel Earley Parser
LATE Ain’T Earley: A Faster Parallel Earley Parser Peter Ahrens John Feser Joseph Hui [email protected] [email protected] [email protected] July 18, 2018 Abstract We present the LATE algorithm, an asynchronous variant of the Earley algorithm for pars- ing context-free grammars. The Earley algorithm is naturally task-based, but is difficult to parallelize because of dependencies between the tasks. We present the LATE algorithm, which uses additional data structures to maintain information about the state of the parse so that work items may be processed in any order. This property allows the LATE algorithm to be sped up using task parallelism. We show that the LATE algorithm can achieve a 120x speedup over the Earley algorithm on a natural language task. 1 Introduction Improvements in the efficiency of parsers for context-free grammars (CFGs) have the potential to speed up applications in software development, computational linguistics, and human-computer interaction. The Earley parser has an asymptotic complexity that scales with the complexity of the CFG, a unique, desirable trait among parsers for arbitrary CFGs. However, while the more commonly used Cocke-Younger-Kasami (CYK) [2, 5, 12] parser has been successfully parallelized [1, 7], the Earley algorithm has seen relatively few attempts at parallelization. Our research objectives were to understand when there exists parallelism in the Earley algorithm, and to explore methods for exploiting this parallelism. We first tried to naively parallelize the Earley algorithm by processing the Earley items in each Earley set in parallel. We found that this approach does not produce any speedup, because the dependencies between Earley items force much of the work to be performed sequentially. -

NLTK Parsing Demos
NLTK Parsing Demos Adrian Brasoveanu∗ March 3, 2014 Contents 1 Recursive descent parsing (top-down, depth-first)1 2 Shift-reduce (bottom-up)4 3 Left-corner parser: top-down with bottom-up filtering5 4 General Background: Memoization6 5 Chart parsing 11 6 Bottom-Up Chart Parsing 15 7 Top-down Chart Parsing 21 8 The Earley Algorithm 25 9 Back to Left-Corner chart parsing 30 1 Recursive descent parsing (top-down, depth-first) [py1] >>> import nltk, re, pprint >>> from __future__ import division [py2] >>> grammar1= nltk.parse_cfg(""" ... S -> NP VP ... VP -> V NP | V NP PP ... PP -> P NP ... V ->"saw"|"ate"|"walked" ∗Based on the NLTK book (Bird et al. 2009) and created with the PythonTeX package (Poore 2013). 1 ... NP ->"John"|"Mary"|"Bob" | Det N | Det N PP ... Det ->"a"|"an"|"the"|"my" ... N ->"man"|"dog"|"cat"|"telescope"|"park" ... P ->"in"|"on"|"by"|"with" ... """) [py3] >>> rd_parser= nltk.RecursiveDescentParser(grammar1) >>> sent=’Mary saw a dog’.split() >>> sent [’Mary’, ’saw’, ’a’, ’dog’] >>> trees= rd_parser.nbest_parse(sent) >>> for tree in trees: ... print tree,"\n\n" ... (S (NP Mary) (VP (V saw) (NP (Det a) (N dog)))) [py4] >>> rd_parser= nltk.RecursiveDescentParser(grammar1, trace=2) >>> rd_parser.nbest_parse(sent) Parsing ’Mary saw a dog’ [*S] E [ * NP VP ] E [ * ’John’ VP ] E [ * ’Mary’ VP ] M [ ’Mary’ * VP ] E [ ’Mary’ * V NP ] E [ ’Mary’ * ’saw’ NP ] M [ ’Mary’ ’saw’ * NP ] E [ ’Mary’ ’saw’ * ’John’ ] E [ ’Mary’ ’saw’ * ’Mary’ ] E [ ’Mary’ ’saw’ * ’Bob’ ] E [ ’Mary’ ’saw’ * Det N ] E [ ’Mary’ ’saw’ * ’a’ N ] M [ ’Mary’ ’saw’ -

Parsing 1. Grammars and Parsing 2. Top-Down and Bottom-Up Parsing 3
Syntax Parsing syntax: from the Greek syntaxis, meaning “setting out together or arrangement.” 1. Grammars and parsing Refers to the way words are arranged together. 2. Top-down and bottom-up parsing Why worry about syntax? 3. Chart parsers • The boy ate the frog. 4. Bottom-up chart parsing • The frog was eaten by the boy. 5. The Earley Algorithm • The frog that the boy ate died. • The boy whom the frog was eaten by died. Slide CS474–1 Slide CS474–2 Grammars and Parsing Need a grammar: a formal specification of the structures allowable in Syntactic Analysis the language. Key ideas: Need a parser: algorithm for assigning syntactic structure to an input • constituency: groups of words may behave as a single unit or phrase sentence. • grammatical relations: refer to the subject, object, indirect Sentence Parse Tree object, etc. Beavis ate the cat. S • subcategorization and dependencies: refer to certain kinds of relations between words and phrases, e.g. want can be followed by an NP VP infinitive, but find and work cannot. NAME V NP All can be modeled by various kinds of grammars that are based on ART N context-free grammars. Beavis ate the cat Slide CS474–3 Slide CS474–4 CFG example CFG’s are also called phrase-structure grammars. CFG’s Equivalent to Backus-Naur Form (BNF). A context free grammar consists of: 1. S → NP VP 5. NAME → Beavis 1. a set of non-terminal symbols N 2. VP → V NP 6. V → ate 2. a set of terminal symbols Σ (disjoint from N) 3. -

Chart Parsing and Constraint Programming
Chart Parsing and Constraint Programming Frank Morawietz Seminar f¨ur Sprachwissenschaft Universit¨at T¨ubingen Wilhelmstr. 113 72074 T¨ubingen, Germany [email protected] Abstract yet another language. The approach allows for a rapid In this paper, parsing-as-deduction and constraint pro- and very flexible but at the same time uniform method gramming are brought together to outline a procedure for of implementation of all kinds of parsing algorithms (for the specification of constraint-based chart parsers. Fol- constraint-based theories). The goal is not necessarily to lowing the proposal in Shieber et al. (1995), we show build the fastest parser, but rather to build – for an ar- how to directly realize the inference rules for deductive bitrary algorithm – a parser fast and perspicuously. For parsers as Constraint Handling Rules (Fr¨uhwirth, 1998) example, the advantage of our approach compared to the by viewing the items of a chart parser as constraints and one proposed in Shieber et al. (1995) is that we do not the constraint base as a chart. This allows the direct use have to design a special deduction engine and we do not of constraint resolution to parse sentences. have to handle chart and agenda explicitly. Furthermore, the process can be used in any constraint-based formal- 1 Introduction ism which allows for constraint propagation and there- fore can be easily integrated into existing applications. The parsing-as-deduction approach proposed in Pereira The paper proceeds by reviewing the parsing-as- and Warren (1983) and extended in Shieber et al. (1995) deduction approach and a particular way of imple- and the parsing schemata defined in Sikkel (1997) are menting constraint systems, Constraint Handling Rules well established parsing paradigms in computational lin- (CHR) as presented in Fr¨uhwirth (1998). -

Abstract Syntax Trees & Top-Down Parsing
Abstract Syntax Trees & Top-Down Parsing Review of Parsing • Given a language L(G), a parser consumes a sequence of tokens s and produces a parse tree • Issues: – How do we recognize that s ∈ L(G) ? – A parse tree of s describes how s ∈ L(G) – Ambiguity: more than one parse tree (possible interpretation) for some string s – Error: no parse tree for some string s – How do we construct the parse tree? Compiler Design 1 (2011) 2 Abstract Syntax Trees • So far, a parser traces the derivation of a sequence of tokens • The rest of the compiler needs a structural representation of the program • Abstract syntax trees – Like parse trees but ignore some details – Abbreviated as AST Compiler Design 1 (2011) 3 Abstract Syntax Trees (Cont.) • Consider the grammar E → int | ( E ) | E + E • And the string 5 + (2 + 3) • After lexical analysis (a list of tokens) int5 ‘+’ ‘(‘ int2 ‘+’ int3 ‘)’ • During parsing we build a parse tree … Compiler Design 1 (2011) 4 Example of Parse Tree E • Traces the operation of the parser E + E • Captures the nesting structure • But too much info int5 ( E ) – Parentheses – Single-successor nodes + E E int 2 int3 Compiler Design 1 (2011) 5 Example of Abstract Syntax Tree PLUS PLUS 5 2 3 • Also captures the nesting structure • But abstracts from the concrete syntax a more compact and easier to use • An important data structure in a compiler Compiler Design 1 (2011) 6 Semantic Actions • This is what we’ll use to construct ASTs • Each grammar symbol may have attributes – An attribute is a property of a programming language construct -

Compiler Construction
UNIVERSITY OF CAMBRIDGE Compiler Construction An 18-lecture course Alan Mycroft Computer Laboratory, Cambridge University http://www.cl.cam.ac.uk/users/am/ Lent Term 2007 Compiler Construction 1 Lent Term 2007 Course Plan UNIVERSITY OF CAMBRIDGE Part A : intro/background Part B : a simple compiler for a simple language Part C : implementing harder things Compiler Construction 2 Lent Term 2007 A compiler UNIVERSITY OF CAMBRIDGE A compiler is a program which translates the source form of a program into a semantically equivalent target form. • Traditionally this was machine code or relocatable binary form, but nowadays the target form may be a virtual machine (e.g. JVM) or indeed another language such as C. • Can appear a very hard program to write. • How can one even start? • It’s just like juggling too many balls (picking instructions while determining whether this ‘+’ is part of ‘++’ or whether its right operand is just a variable or an expression ...). Compiler Construction 3 Lent Term 2007 How to even start? UNIVERSITY OF CAMBRIDGE “When finding it hard to juggle 4 balls at once, juggle them each in turn instead ...” character -token -parse -intermediate -target stream stream tree code code syn trans cg lex A multi-pass compiler does one ‘simple’ thing at once and passes its output to the next stage. These are pretty standard stages, and indeed language and (e.g. JVM) system design has co-evolved around them. Compiler Construction 4 Lent Term 2007 Compilers can be big and hard to understand UNIVERSITY OF CAMBRIDGE Compilers can be very large. In 2004 the Gnu Compiler Collection (GCC) was noted to “[consist] of about 2.1 million lines of code and has been in development for over 15 years”.