Advanced Parsing Techniques
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-
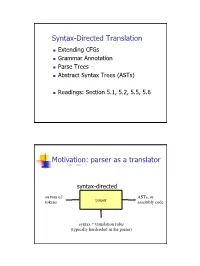
Syntax-Directed Translation, Parse Trees, Abstract Syntax Trees
Syntax-Directed Translation Extending CFGs Grammar Annotation Parse Trees Abstract Syntax Trees (ASTs) Readings: Section 5.1, 5.2, 5.5, 5.6 Motivation: parser as a translator syntax-directed translation stream of ASTs, or tokens parser assembly code syntax + translation rules (typically hardcoded in the parser) 1 Mechanism of syntax-directed translation syntax-directed translation is done by extending the CFG a translation rule is defined for each production given X Æ d A B c the translation of X is defined in terms of translation of nonterminals A, B values of attributes of terminals d, c constants To translate an input string: 1. Build the parse tree. 2. Working bottom-up • Use the translation rules to compute the translation of each nonterminal in the tree Result: the translation of the string is the translation of the parse tree's root nonterminal Why bottom up? a nonterminal's value may depend on the value of the symbols on the right-hand side, so translate a non-terminal node only after children translations are available 2 Example 1: arith expr to its value Syntax-directed translation: the CFG translation rules E Æ E + T E1.trans = E2.trans + T.trans E Æ T E.trans = T.trans T Æ T * F T1.trans = T2.trans * F.trans T Æ F T.trans = F.trans F Æ int F.trans = int.value F Æ ( E ) F.trans = E.trans Example 1 (cont) E (18) Input: 2 * (4 + 5) T (18) T (2) * F (9) F (2) ( E (9) ) int (2) E (4) * T (5) Annotated Parse Tree T (4) F (5) F (4) int (5) int (4) 3 Example 2: Compute type of expr E -> E + E if ((E2.trans == INT) and (E3.trans == INT) then E1.trans = INT else E1.trans = ERROR E -> E and E if ((E2.trans == BOOL) and (E3.trans == BOOL) then E1.trans = BOOL else E1.trans = ERROR E -> E == E if ((E2.trans == E3.trans) and (E2.trans != ERROR)) then E1.trans = BOOL else E1.trans = ERROR E -> true E.trans = BOOL E -> false E.trans = BOOL E -> int E.trans = INT E -> ( E ) E1.trans = E2.trans Example 2 (cont) Input: (2 + 2) == 4 1. -

Derivatives of Parsing Expression Grammars
Derivatives of Parsing Expression Grammars Aaron Moss Cheriton School of Computer Science University of Waterloo Waterloo, Ontario, Canada [email protected] This paper introduces a new derivative parsing algorithm for recognition of parsing expression gram- mars. Derivative parsing is shown to have a polynomial worst-case time bound, an improvement on the exponential bound of the recursive descent algorithm. This work also introduces asymptotic analysis based on inputs with a constant bound on both grammar nesting depth and number of back- tracking choices; derivative and recursive descent parsing are shown to run in linear time and constant space on this useful class of inputs, with both the theoretical bounds and the reasonability of the in- put class validated empirically. This common-case constant memory usage of derivative parsing is an improvement on the linear space required by the packrat algorithm. 1 Introduction Parsing expression grammars (PEGs) are a parsing formalism introduced by Ford [6]. Any LR(k) lan- guage can be represented as a PEG [7], but there are some non-context-free languages that may also be represented as PEGs (e.g. anbncn [7]). Unlike context-free grammars (CFGs), PEGs are unambiguous, admitting no more than one parse tree for any grammar and input. PEGs are a formalization of recursive descent parsers allowing limited backtracking and infinite lookahead; a string in the language of a PEG can be recognized in exponential time and linear space using a recursive descent algorithm, or linear time and space using the memoized packrat algorithm [6]. PEGs are formally defined and these algo- rithms outlined in Section 3. -

LATE Ain't Earley: a Faster Parallel Earley Parser
LATE Ain’T Earley: A Faster Parallel Earley Parser Peter Ahrens John Feser Joseph Hui [email protected] [email protected] [email protected] July 18, 2018 Abstract We present the LATE algorithm, an asynchronous variant of the Earley algorithm for pars- ing context-free grammars. The Earley algorithm is naturally task-based, but is difficult to parallelize because of dependencies between the tasks. We present the LATE algorithm, which uses additional data structures to maintain information about the state of the parse so that work items may be processed in any order. This property allows the LATE algorithm to be sped up using task parallelism. We show that the LATE algorithm can achieve a 120x speedup over the Earley algorithm on a natural language task. 1 Introduction Improvements in the efficiency of parsers for context-free grammars (CFGs) have the potential to speed up applications in software development, computational linguistics, and human-computer interaction. The Earley parser has an asymptotic complexity that scales with the complexity of the CFG, a unique, desirable trait among parsers for arbitrary CFGs. However, while the more commonly used Cocke-Younger-Kasami (CYK) [2, 5, 12] parser has been successfully parallelized [1, 7], the Earley algorithm has seen relatively few attempts at parallelization. Our research objectives were to understand when there exists parallelism in the Earley algorithm, and to explore methods for exploiting this parallelism. We first tried to naively parallelize the Earley algorithm by processing the Earley items in each Earley set in parallel. We found that this approach does not produce any speedup, because the dependencies between Earley items force much of the work to be performed sequentially. -

A Declarative Extension of Parsing Expression Grammars for Recognizing Most Programming Languages
Journal of Information Processing Vol.24 No.2 256–264 (Mar. 2016) [DOI: 10.2197/ipsjjip.24.256] Regular Paper A Declarative Extension of Parsing Expression Grammars for Recognizing Most Programming Languages Tetsuro Matsumura1,†1 Kimio Kuramitsu1,a) Received: May 18, 2015, Accepted: November 5, 2015 Abstract: Parsing Expression Grammars are a popular foundation for describing syntax. Unfortunately, several syn- tax of programming languages are still hard to recognize with pure PEGs. Notorious cases appears: typedef-defined names in C/C++, indentation-based code layout in Python, and HERE document in many scripting languages. To recognize such PEG-hard syntax, we have addressed a declarative extension to PEGs. The “declarative” extension means no programmed semantic actions, which are traditionally used to realize the extended parsing behavior. Nez is our extended PEG language, including symbol tables and conditional parsing. This paper demonstrates that the use of Nez Extensions can realize many practical programming languages, such as C, C#, Ruby, and Python, which involve PEG-hard syntax. Keywords: parsing expression grammars, semantic actions, context-sensitive syntax, and case studies on program- ming languages invalidate the declarative property of PEGs, thus resulting in re- 1. Introduction duced reusability of grammars. As a result, many developers need Parsing Expression Grammars [5], or PEGs, are a popu- to redevelop grammars for their software engineering tools. lar foundation for describing programming language syntax [6], In this paper, we propose a declarative extension of PEGs for [15]. Indeed, the formalism of PEGs has many desirable prop- recognizing context-sensitive syntax. The “declarative” exten- erties, including deterministic behaviors, unlimited look-aheads, sion means no arbitrary semantic actions that are written in a gen- and integrated lexical analysis known as scanner-less parsing. -

Lecture 10: CYK and Earley Parsers Alvin Cheung Building Parse Trees Maaz Ahmad CYK and Earley Algorithms Talia Ringer More Disambiguation
Hack Your Language! CSE401 Winter 2016 Introduction to Compiler Construction Ras Bodik Lecture 10: CYK and Earley Parsers Alvin Cheung Building Parse Trees Maaz Ahmad CYK and Earley algorithms Talia Ringer More Disambiguation Ben Tebbs 1 Announcements • HW3 due Sunday • Project proposals due tonight – No late days • Review session this Sunday 6-7pm EEB 115 2 Outline • Last time we saw how to construct AST from parse tree • We will now discuss algorithms for generating parse trees from input strings 3 Today CYK parser builds the parse tree bottom up More Disambiguation Forcing the parser to select the desired parse tree Earley parser solves CYK’s inefficiency 4 CYK parser Parser Motivation • Given a grammar G and an input string s, we need an algorithm to: – Decide whether s is in L(G) – If so, generate a parse tree for s • We will see two algorithms for doing this today – Many others are available – Each with different tradeoffs in time and space 6 CYK Algorithm • Parsing algorithm for context-free grammars • Invented by John Cocke, Daniel Younger, and Tadao Kasami • Basic idea given string s with n tokens: 1. Find production rules that cover 1 token in s 2. Use 1. to find rules that cover 2 tokens in s 3. Use 2. to find rules that cover 3 tokens in s 4. … N. Use N-1. to find rules that cover n tokens in s. If succeeds then s is in L(G), else it is not 7 A graphical way to visualize CYK Initial graph: the input (terminals) Repeat: add non-terminal edges until no more can be added. -

Parsing 1. Grammars and Parsing 2. Top-Down and Bottom-Up Parsing 3
Syntax Parsing syntax: from the Greek syntaxis, meaning “setting out together or arrangement.” 1. Grammars and parsing Refers to the way words are arranged together. 2. Top-down and bottom-up parsing Why worry about syntax? 3. Chart parsers • The boy ate the frog. 4. Bottom-up chart parsing • The frog was eaten by the boy. 5. The Earley Algorithm • The frog that the boy ate died. • The boy whom the frog was eaten by died. Slide CS474–1 Slide CS474–2 Grammars and Parsing Need a grammar: a formal specification of the structures allowable in Syntactic Analysis the language. Key ideas: Need a parser: algorithm for assigning syntactic structure to an input • constituency: groups of words may behave as a single unit or phrase sentence. • grammatical relations: refer to the subject, object, indirect Sentence Parse Tree object, etc. Beavis ate the cat. S • subcategorization and dependencies: refer to certain kinds of relations between words and phrases, e.g. want can be followed by an NP VP infinitive, but find and work cannot. NAME V NP All can be modeled by various kinds of grammars that are based on ART N context-free grammars. Beavis ate the cat Slide CS474–3 Slide CS474–4 CFG example CFG’s are also called phrase-structure grammars. CFG’s Equivalent to Backus-Naur Form (BNF). A context free grammar consists of: 1. S → NP VP 5. NAME → Beavis 1. a set of non-terminal symbols N 2. VP → V NP 6. V → ate 2. a set of terminal symbols Σ (disjoint from N) 3. -

Abstract Syntax Trees & Top-Down Parsing
Abstract Syntax Trees & Top-Down Parsing Review of Parsing • Given a language L(G), a parser consumes a sequence of tokens s and produces a parse tree • Issues: – How do we recognize that s ∈ L(G) ? – A parse tree of s describes how s ∈ L(G) – Ambiguity: more than one parse tree (possible interpretation) for some string s – Error: no parse tree for some string s – How do we construct the parse tree? Compiler Design 1 (2011) 2 Abstract Syntax Trees • So far, a parser traces the derivation of a sequence of tokens • The rest of the compiler needs a structural representation of the program • Abstract syntax trees – Like parse trees but ignore some details – Abbreviated as AST Compiler Design 1 (2011) 3 Abstract Syntax Trees (Cont.) • Consider the grammar E → int | ( E ) | E + E • And the string 5 + (2 + 3) • After lexical analysis (a list of tokens) int5 ‘+’ ‘(‘ int2 ‘+’ int3 ‘)’ • During parsing we build a parse tree … Compiler Design 1 (2011) 4 Example of Parse Tree E • Traces the operation of the parser E + E • Captures the nesting structure • But too much info int5 ( E ) – Parentheses – Single-successor nodes + E E int 2 int3 Compiler Design 1 (2011) 5 Example of Abstract Syntax Tree PLUS PLUS 5 2 3 • Also captures the nesting structure • But abstracts from the concrete syntax a more compact and easier to use • An important data structure in a compiler Compiler Design 1 (2011) 6 Semantic Actions • This is what we’ll use to construct ASTs • Each grammar symbol may have attributes – An attribute is a property of a programming language construct -

Simple, Efficient, Sound-And-Complete Combinator Parsing for All Context
Simple, efficient, sound-and-complete combinator parsing for all context-free grammars, using an oracle OCaml 2014 workshop, talk proposal Tom Ridge University of Leicester, UK [email protected] This proposal describes a parsing library that is based on current grammar, the start symbol and the input to the back-end Earley work due to be published as [3]. The talk will focus on the OCaml parser, which parses the input and returns a parsing oracle. The library and its usage. oracle is then used to guide the action phase of the parser. 1. Combinator parsers 4. Real-world performance 3 Parsers for context-free grammars can be implemented directly and In addition to O(n ) theoretical performance, we also optimize our naturally in a functional style known as “combinator parsing”, us- back-end Earley parser. Extensive performance measurements on ing recursion following the structure of the grammar rules. Tradi- small grammars (described in [3]) indicate that the performance is tionally parser combinators have struggled to handle all features of arguably better than the Happy parser generator [1]. context-free grammars, such as left recursion. 5. Online distribution 2. Sound and complete combinator parsers This work has led to the P3 parsing library for OCaml, freely Previous work [2] introduced novel parser combinators that could available online1. The distribution includes extensive examples. be used to parse all context-free grammars. A parser generator built Some of the examples are: using these combinators was proved both sound and complete in the • HOL4 theorem prover. Parsing and disambiguation of arithmetic expressions using This previous approach has all the traditional benefits of combi- precedence annotations. -

Efficient Recursive Parsing
Purdue University Purdue e-Pubs Department of Computer Science Technical Reports Department of Computer Science 1976 Efficient Recursive Parsing Christoph M. Hoffmann Purdue University, [email protected] Report Number: 77-215 Hoffmann, Christoph M., "Efficient Recursive Parsing" (1976). Department of Computer Science Technical Reports. Paper 155. https://docs.lib.purdue.edu/cstech/155 This document has been made available through Purdue e-Pubs, a service of the Purdue University Libraries. Please contact [email protected] for additional information. EFFICIENT RECURSIVE PARSING Christoph M. Hoffmann Computer Science Department Purdue University West Lafayette, Indiana 47907 CSD-TR 215 December 1976 Efficient Recursive Parsing Christoph M. Hoffmann Computer Science Department Purdue University- Abstract Algorithms are developed which construct from a given LL(l) grammar a recursive descent parser with as much, recursion resolved by iteration as is possible without introducing auxiliary memory. Unlike other proposed methods in the literature designed to arrive at parsers of this kind, the algorithms do not require extensions of the notational formalism nor alter the grammar in any way. The algorithms constructing the parsers operate in 0(k«s) steps, where s is the size of the grammar, i.e. the sum of the lengths of all productions, and k is a grammar - dependent constant. A speedup of the algorithm is possible which improves the bound to 0(s) for all LL(l) grammars, and constructs smaller parsers with some auxiliary memory in form of parameters -

Improving Upon Earley's Parsing Algorithm in Prolog
Improving Upon Earley’s Parsing Algorithm In Prolog Matt Voss Artificial Intelligence Center University of Georgia Athens, GA 30602 May 7, 2004 Abstract This paper presents a modification of the Earley (1970) parsing algorithm in Prolog. The Earley algorithm presented here is based on an implementation in Covington (1994a). The modifications are meant to improve on that algorithm in several key ways. The parser features a predictor that works like a left-corner parser with links, thus decreasing the number of chart entries. It implements subsump- tion checking, and organizes chart entries to take advantage of first argument indexing for quick retrieval. 1 Overview The Earley parsing algorithm is well known for its great efficiency in produc- ing all possible parses of a sentence in relatively little time, without back- tracking, and while handling left recursive rules correctly. It is also known for being considerably slower than most other parsing algorithms1. This pa- per outlines an attempt to overcome many of the pitfalls associated with implementations of Earley parsers. It uses the Earley parser in Covington (1994a) as a starting point. In particular the Earley top-down predictor is exchanged for a predictor that works like a left-corner predictor with links, 1See Covington (1994a) for one comparison of run times for a variety of algorithms. 1 following Leiss (1990). Chart entries store the positions of constituents in the input string, rather than lists containing the constituents themselves, and the arguments of chart entries are arranged to take advantage of first argument indexing. This means a small trade-off between easy-to-read code and efficiency of processing. -

Compiler Construction
UNIVERSITY OF CAMBRIDGE Compiler Construction An 18-lecture course Alan Mycroft Computer Laboratory, Cambridge University http://www.cl.cam.ac.uk/users/am/ Lent Term 2007 Compiler Construction 1 Lent Term 2007 Course Plan UNIVERSITY OF CAMBRIDGE Part A : intro/background Part B : a simple compiler for a simple language Part C : implementing harder things Compiler Construction 2 Lent Term 2007 A compiler UNIVERSITY OF CAMBRIDGE A compiler is a program which translates the source form of a program into a semantically equivalent target form. • Traditionally this was machine code or relocatable binary form, but nowadays the target form may be a virtual machine (e.g. JVM) or indeed another language such as C. • Can appear a very hard program to write. • How can one even start? • It’s just like juggling too many balls (picking instructions while determining whether this ‘+’ is part of ‘++’ or whether its right operand is just a variable or an expression ...). Compiler Construction 3 Lent Term 2007 How to even start? UNIVERSITY OF CAMBRIDGE “When finding it hard to juggle 4 balls at once, juggle them each in turn instead ...” character -token -parse -intermediate -target stream stream tree code code syn trans cg lex A multi-pass compiler does one ‘simple’ thing at once and passes its output to the next stage. These are pretty standard stages, and indeed language and (e.g. JVM) system design has co-evolved around them. Compiler Construction 4 Lent Term 2007 Compilers can be big and hard to understand UNIVERSITY OF CAMBRIDGE Compilers can be very large. In 2004 the Gnu Compiler Collection (GCC) was noted to “[consist] of about 2.1 million lines of code and has been in development for over 15 years”. -

Verifiable Parse Table Composition for Deterministic Parsing*
Verifiable Parse Table Composition for Deterministic Parsing? August Schwerdfeger and Eric Van Wyk Department of Computer Science and Engineering University of Minnesota, Minneapolis, MN {schwerdf,evw}@cs.umn.edu Abstract. One obstacle to the implementation of modular extensions to programming languages lies in the problem of parsing extended lan- guages. Specifically, the parse tables at the heart of traditional LALR(1) parsers are so monolithic and tightly constructed that, in the general case, it is impossible to extend them without regenerating them from the source grammar. Current extensible frameworks employ a variety of solutions, ranging from a full regeneration to using pluggable binary mod- ules for each different extension. But recompilation is time-consuming, while the pluggable modules in many cases cannot support the addition of more than one extension, or use backtracking or non-deterministic parsing techniques. We present here a middle-ground approach that allows an extension, if it meets certain restrictions, to be compiled into a parse table fragment. The host language parse table and fragments from multiple extensions can then always be efficiently composed to produce a conflict-free parse table for the extended language. This allows for the distribution of de- terministic parsers for extensible languages in a pre-compiled format, eliminating the need for the “source code” grammar to be distributed. In practice, we have found these restrictions to be reasonable and admit many useful language extensions. 1 Introduction In parsing programming languages, the usual practice is to generate a single parser for the language to be parsed. A well known and often-used approach is LR parsing [1] which relies on a process, sometimes referred to as grammar compilation, to generate a monolithic parse table representing the grammar being parsed.