Efficient Recursive Parsing
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Derivatives of Parsing Expression Grammars
Derivatives of Parsing Expression Grammars Aaron Moss Cheriton School of Computer Science University of Waterloo Waterloo, Ontario, Canada [email protected] This paper introduces a new derivative parsing algorithm for recognition of parsing expression gram- mars. Derivative parsing is shown to have a polynomial worst-case time bound, an improvement on the exponential bound of the recursive descent algorithm. This work also introduces asymptotic analysis based on inputs with a constant bound on both grammar nesting depth and number of back- tracking choices; derivative and recursive descent parsing are shown to run in linear time and constant space on this useful class of inputs, with both the theoretical bounds and the reasonability of the in- put class validated empirically. This common-case constant memory usage of derivative parsing is an improvement on the linear space required by the packrat algorithm. 1 Introduction Parsing expression grammars (PEGs) are a parsing formalism introduced by Ford [6]. Any LR(k) lan- guage can be represented as a PEG [7], but there are some non-context-free languages that may also be represented as PEGs (e.g. anbncn [7]). Unlike context-free grammars (CFGs), PEGs are unambiguous, admitting no more than one parse tree for any grammar and input. PEGs are a formalization of recursive descent parsers allowing limited backtracking and infinite lookahead; a string in the language of a PEG can be recognized in exponential time and linear space using a recursive descent algorithm, or linear time and space using the memoized packrat algorithm [6]. PEGs are formally defined and these algo- rithms outlined in Section 3. -

A Typed, Algebraic Approach to Parsing
A Typed, Algebraic Approach to Parsing Neelakantan R. Krishnaswami Jeremy Yallop University of Cambridge University of Cambridge United Kingdom United Kingdom [email protected] [email protected] Abstract the subject have remained remarkably stable: context-free In this paper, we recall the definition of the context-free ex- languages are specified in BackusśNaur form, and parsers pressions (or µ-regular expressions), an algebraic presenta- for these specifications are implemented using algorithms tion of the context-free languages. Then, we define a core derived from automata theory. This integration of theory and type system for the context-free expressions which gives a practice has yielded many benefits: we have linear-time algo- compositional criterion for identifying those context-free ex- rithms for parsing unambiguous grammars efficiently [Knuth pressions which can be parsed unambiguously by predictive 1965; Lewis and Stearns 1968] and with excellent error re- algorithms in the style of recursive descent or LL(1). porting for bad input strings [Jeffery 2003]. Next, we show how these typed grammar expressions can However, in languages with good support for higher-order be used to derive a parser combinator library which both functions (such as ML, Haskell, and Scala) it is very popular guarantees linear-time parsing with no backtracking and to use parser combinators [Hutton 1992] instead. These li- single-token lookahead, and which respects the natural de- braries typically build backtracking recursive descent parsers notational semantics of context-free expressions. Finally, we by composing higher-order functions. This allows building show how to exploit the type information to write a staged up parsers with the ordinary abstraction features of the version of this library, which produces dramatic increases programming language (variables, data structures and func- in performance, even outperforming code generated by the tions), which is sufficiently beneficial that these libraries are standard parser generator tool ocamlyacc. -

A Declarative Extension of Parsing Expression Grammars for Recognizing Most Programming Languages
Journal of Information Processing Vol.24 No.2 256–264 (Mar. 2016) [DOI: 10.2197/ipsjjip.24.256] Regular Paper A Declarative Extension of Parsing Expression Grammars for Recognizing Most Programming Languages Tetsuro Matsumura1,†1 Kimio Kuramitsu1,a) Received: May 18, 2015, Accepted: November 5, 2015 Abstract: Parsing Expression Grammars are a popular foundation for describing syntax. Unfortunately, several syn- tax of programming languages are still hard to recognize with pure PEGs. Notorious cases appears: typedef-defined names in C/C++, indentation-based code layout in Python, and HERE document in many scripting languages. To recognize such PEG-hard syntax, we have addressed a declarative extension to PEGs. The “declarative” extension means no programmed semantic actions, which are traditionally used to realize the extended parsing behavior. Nez is our extended PEG language, including symbol tables and conditional parsing. This paper demonstrates that the use of Nez Extensions can realize many practical programming languages, such as C, C#, Ruby, and Python, which involve PEG-hard syntax. Keywords: parsing expression grammars, semantic actions, context-sensitive syntax, and case studies on program- ming languages invalidate the declarative property of PEGs, thus resulting in re- 1. Introduction duced reusability of grammars. As a result, many developers need Parsing Expression Grammars [5], or PEGs, are a popu- to redevelop grammars for their software engineering tools. lar foundation for describing programming language syntax [6], In this paper, we propose a declarative extension of PEGs for [15]. Indeed, the formalism of PEGs has many desirable prop- recognizing context-sensitive syntax. The “declarative” exten- erties, including deterministic behaviors, unlimited look-aheads, sion means no arbitrary semantic actions that are written in a gen- and integrated lexical analysis known as scanner-less parsing. -

Adaptive LL(*) Parsing: the Power of Dynamic Analysis
Adaptive LL(*) Parsing: The Power of Dynamic Analysis Terence Parr Sam Harwell Kathleen Fisher University of San Francisco University of Texas at Austin Tufts University [email protected] [email protected] kfi[email protected] Abstract PEGs are unambiguous by definition but have a quirk where Despite the advances made by modern parsing strategies such rule A ! a j ab (meaning “A matches either a or ab”) can never as PEG, LL(*), GLR, and GLL, parsing is not a solved prob- match ab since PEGs choose the first alternative that matches lem. Existing approaches suffer from a number of weaknesses, a prefix of the remaining input. Nested backtracking makes de- including difficulties supporting side-effecting embedded ac- bugging PEGs difficult. tions, slow and/or unpredictable performance, and counter- Second, side-effecting programmer-supplied actions (muta- intuitive matching strategies. This paper introduces the ALL(*) tors) like print statements should be avoided in any strategy that parsing strategy that combines the simplicity, efficiency, and continuously speculates (PEG) or supports multiple interpreta- predictability of conventional top-down LL(k) parsers with the tions of the input (GLL and GLR) because such actions may power of a GLR-like mechanism to make parsing decisions. never really take place [17]. (Though DParser [24] supports The critical innovation is to move grammar analysis to parse- “final” actions when the programmer is certain a reduction is time, which lets ALL(*) handle any non-left-recursive context- part of an unambiguous final parse.) Without side effects, ac- free grammar. ALL(*) is O(n4) in theory but consistently per- tions must buffer data for all interpretations in immutable data forms linearly on grammars used in practice, outperforming structures or provide undo actions. -

Conflict Resolution in a Recursive Descent Compiler Generator
LL(1) Conflict Resolution in a Recursive Descent Compiler Generator Albrecht Wöß, Markus Löberbauer, Hanspeter Mössenböck Johannes Kepler University Linz, Institute of Practical Computer Science, Altenbergerstr. 69, 4040 Linz, Austria {woess,loeberbauer,moessenboeck}@ssw.uni-linz.ac.at Abstract. Recursive descent parsing is restricted to languages whose grammars are LL(1), i.e., which can be parsed top-down with a single lookahead symbol. Unfortunately, many languages such as Java, C++, or C# are not LL(1). There- fore recursive descent parsing cannot be used or the parser has to make its deci- sions based on semantic information or a multi-symbol lookahead. In this paper we suggest a systematic technique for resolving LL(1) conflicts in recursive descent parsing and show how to integrate it into a compiler gen- erator (Coco/R). The idea is to evaluate user-defined boolean expressions, in order to allow the parser to make its parsing decisions where a one symbol loo- kahead does not suffice. Using our extended compiler generator we implemented a compiler front end for C# that can be used as a framework for implementing a variety of tools. 1 Introduction Recursive descent parsing [16] is a popular top-down parsing technique that is sim- ple, efficient, and convenient for integrating semantic processing. However, it re- quires the grammar of the parsed language to be LL(1), which means that the parser must always be able to select between alternatives with a single symbol lookahead. Unfortunately, many languages such as Java, C++ or C# are not LL(1) so that one either has to resort to bottom-up LALR(1) parsing [5, 1], which is more powerful but less convenient for semantic processing, or the parser has to resolve the LL(1) con- flicts using semantic information or a multi-symbol lookahead. -

A Parsing Machine for Pegs
A Parsing Machine for PEGs ∗ Sérgio Medeiros Roberto Ierusalimschy [email protected] [email protected] Department of Computer Science PUC-Rio, Rio de Janeiro, Brazil ABSTRACT parsing approaches. The PEG formalism gives a convenient Parsing Expression Grammar (PEG) is a recognition-based syntax for describing top-down parsers for unambiguous lan- foundation for describing syntax that renewed interest in guages. The parsers it describes can parse strings in linear top-down parsing approaches. Generally, the implementa- time, despite backtracking, by using a memoizing algorithm tion of PEGs is based on a recursive-descent parser, or uses called Packrat [1]. Although Packrat has guaranteed worst- a memoization algorithm. case linear time complexity, it also has linear space com- We present a new approach for implementing PEGs, based plexity, with a rather large constant. This makes Packrat on a virtual parsing machine, which is more suitable for impractical for parsing large amounts of data. pattern matching. Each PEG has a corresponding program LPEG [7, 11] is a pattern-matching tool for Lua, a dy- that is executed by the parsing machine, and new programs namically typed scripting language [6, 8]. LPEG uses PEGs are dynamically created and composed. The virtual machine to describe patterns instead of the more popular Perl-like is embedded in a scripting language and used by a pattern- "regular expressions" (regexes). Regexes are a more ad-hoc matching tool. way of describing patterns; writing a complex regex is more We give an operational semantics of PEGs used for pat- a trial and error than a systematic process, and their per- tern matching, then describe our parsing machine and its formance is very unpredictable. -

Advanced Parsing Techniques
Advanced Parsing Techniques Announcements ● Written Set 1 graded. ● Hard copies available for pickup right now. ● Electronic submissions: feedback returned later today. Where We Are Where We Are Parsing so Far ● We've explored five deterministic parsing algorithms: ● LL(1) ● LR(0) ● SLR(1) ● LALR(1) ● LR(1) ● These algorithms all have their limitations. ● Can we parse arbitrary context-free grammars? Why Parse Arbitrary Grammars? ● They're easier to write. ● Can leave operator precedence and associativity out of the grammar. ● No worries about shift/reduce or FIRST/FOLLOW conflicts. ● If ambiguous, can filter out invalid trees at the end. ● Generate candidate parse trees, then eliminate them when not needed. ● Practical concern for some languages. ● We need to have C and C++ compilers! Questions for Today ● How do you go about parsing ambiguous grammars efficiently? ● How do you produce all possible parse trees? ● What else can we do with a general parser? The Earley Parser Motivation: The Limits of LR ● LR parsers use shift and reduce actions to reduce the input to the start symbol. ● LR parsers cannot deterministically handle shift/reduce or reduce/reduce conflicts. ● However, they can nondeterministically handle these conflicts by guessing which option to choose. ● What if we try all options and see if any of them work? The Earley Parser ● Maintain a collection of Earley items, which are LR(0) items annotated with a start position. ● The item A → α·ω @n means we are working on recognizing A → αω, have seen α, and the start position of the item was the nth token. ● Using techniques similar to LR parsing, try to scan across the input creating these items. -

Verifiable Parse Table Composition for Deterministic Parsing*
Verifiable Parse Table Composition for Deterministic Parsing? August Schwerdfeger and Eric Van Wyk Department of Computer Science and Engineering University of Minnesota, Minneapolis, MN {schwerdf,evw}@cs.umn.edu Abstract. One obstacle to the implementation of modular extensions to programming languages lies in the problem of parsing extended lan- guages. Specifically, the parse tables at the heart of traditional LALR(1) parsers are so monolithic and tightly constructed that, in the general case, it is impossible to extend them without regenerating them from the source grammar. Current extensible frameworks employ a variety of solutions, ranging from a full regeneration to using pluggable binary mod- ules for each different extension. But recompilation is time-consuming, while the pluggable modules in many cases cannot support the addition of more than one extension, or use backtracking or non-deterministic parsing techniques. We present here a middle-ground approach that allows an extension, if it meets certain restrictions, to be compiled into a parse table fragment. The host language parse table and fragments from multiple extensions can then always be efficiently composed to produce a conflict-free parse table for the extended language. This allows for the distribution of de- terministic parsers for extensible languages in a pre-compiled format, eliminating the need for the “source code” grammar to be distributed. In practice, we have found these restrictions to be reasonable and admit many useful language extensions. 1 Introduction In parsing programming languages, the usual practice is to generate a single parser for the language to be parsed. A well known and often-used approach is LR parsing [1] which relies on a process, sometimes referred to as grammar compilation, to generate a monolithic parse table representing the grammar being parsed. -
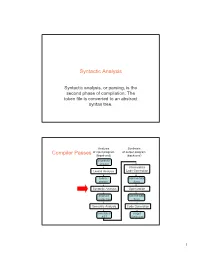
Syntactic Analysis, Or Parsing, Is the Second Phase of Compilation: the Token File Is Converted to an Abstract Syntax Tree
Syntactic Analysis Syntactic analysis, or parsing, is the second phase of compilation: The token file is converted to an abstract syntax tree. Analysis Synthesis Compiler Passes of input program of output program (front -end) (back -end) character stream Intermediate Lexical Analysis Code Generation token intermediate stream form Syntactic Analysis Optimization abstract intermediate syntax tree form Semantic Analysis Code Generation annotated target AST language 1 Syntactic Analysis / Parsing • Goal: Convert token stream to abstract syntax tree • Abstract syntax tree (AST): – Captures the structural features of the program – Primary data structure for remainder of analysis • Three Part Plan – Study how context-free grammars specify syntax – Study algorithms for parsing / building ASTs – Study the miniJava Implementation Context-free Grammars • Compromise between – REs, which can’t nest or specify recursive structure – General grammars, too powerful, undecidable • Context-free grammars are a sweet spot – Powerful enough to describe nesting, recursion – Easy to parse; but also allow restrictions for speed • Not perfect – Cannot capture semantics, as in, “variable must be declared,” requiring later semantic pass – Can be ambiguous • EBNF, Extended Backus Naur Form, is popular notation 2 CFG Terminology • Terminals -- alphabet of language defined by CFG • Nonterminals -- symbols defined in terms of terminals and nonterminals • Productions -- rules for how a nonterminal (lhs) is defined in terms of a (possibly empty) sequence of terminals -

Lecture 3: Recursive Descent Limitations, Precedence Climbing
Lecture 3: Recursive descent limitations, precedence climbing David Hovemeyer September 9, 2020 601.428/628 Compilers and Interpreters Today I Limitations of recursive descent I Precedence climbing I Abstract syntax trees I Supporting parenthesized expressions Before we begin... Assume a context-free struct Node *Parser::parse_A() { grammar has the struct Node *next_tok = lexer_peek(m_lexer); following productions on if (!next_tok) { the nonterminal A: error("Unexpected end of input"); } A → b C A → d E struct Node *a = node_build0(NODE_A); int tag = node_get_tag(next_tok); (A, C, E are if (tag == TOK_b) { nonterminals; b, d are node_add_kid(a, expect(TOK_b)); node_add_kid(a, parse_C()); terminals) } else if (tag == TOK_d) { What is the problem node_add_kid(a, expect(TOK_d)); node_add_kid(a, parse_E()); with the parse function } shown on the right? return a; } Limitations of recursive descent Recall: a better infix expression grammar Grammar (start symbol is A): A → i = A T → T*F A → E T → T/F E → E + T T → F E → E-T F → i E → T F → n Precedence levels: Nonterminal Precedence Meaning Operators Associativity A lowest Assignment = right E Expression + - left T Term * / left F highest Factor No Parsing infix expressions Can we write a recursive descent parser for infix expressions using this grammar? Parsing infix expressions Can we write a recursive descent parser for infix expressions using this grammar? No Left recursion Left-associative operators want to have left-recursive productions, but recursive descent parsers can’t handle left recursion -

Basics of Compiler Design
Basics of Compiler Design Anniversary edition Torben Ægidius Mogensen DEPARTMENT OF COMPUTER SCIENCE UNIVERSITY OF COPENHAGEN Published through lulu.com. c Torben Ægidius Mogensen 2000 – 2010 [email protected] Department of Computer Science University of Copenhagen Universitetsparken 1 DK-2100 Copenhagen DENMARK Book homepage: http://www.diku.dk/∼torbenm/Basics First published 2000 This edition: August 20, 2010 ISBN 978-87-993154-0-6 Contents 1 Introduction 1 1.1 What is a compiler? . 1 1.2 The phases of a compiler . 2 1.3 Interpreters . 3 1.4 Why learn about compilers? . 4 1.5 The structure of this book . 5 1.6 To the lecturer . 6 1.7 Acknowledgements . 7 1.8 Permission to use . 7 2 Lexical Analysis 9 2.1 Introduction . 9 2.2 Regular expressions . 10 2.2.1 Shorthands . 13 2.2.2 Examples . 14 2.3 Nondeterministic finite automata . 15 2.4 Converting a regular expression to an NFA . 18 2.4.1 Optimisations . 20 2.5 Deterministic finite automata . 22 2.6 Converting an NFA to a DFA . 23 2.6.1 Solving set equations . 23 2.6.2 The subset construction . 26 2.7 Size versus speed . 29 2.8 Minimisation of DFAs . 30 2.8.1 Example . 32 2.8.2 Dead states . 34 2.9 Lexers and lexer generators . 35 2.9.1 Lexer generators . 41 2.10 Properties of regular languages . 42 2.10.1 Relative expressive power . 42 2.10.2 Limits to expressive power . 44 i ii CONTENTS 2.10.3 Closure properties . 45 2.11 Further reading . -

Deterministic Parsing of Languages with Dynamic Operators
Deterministic Parsing of Languages with Dynamic Op erators Kjell Post Allen Van Gelder James Kerr Baskin Computer Science Center University of California Santa Cruz, CA 95064 email: [email protected] UCSC-CRL-93-15 July 27, 1993 Abstract Allowing the programmer to de ne op erators in a language makes for more readable co de but also complicates the job of parsing; standard parsing techniques cannot accommo date dynamic grammars. We presentan LR parsing metho dology, called deferreddecision parsing , that handles dynamic op erator declarations, that is, op erators that are declared at run time, are applicable only within a program or context, and are not in the underlying language or grammar. It uses a parser generator that takes pro duction rules as input, and generates a table-driven LR parser, much like yacc. Shift/reduce con icts that involve dynamic op erators are resolved at parse time rather than at table construction time. For an op erator-rich language, this technique reduces the size of the grammar needed and parse table pro duced. The added cost to the parser is minimal. Ambiguous op erator constructs can either b e detected by the parser as input is b eing read or avoided altogether by enforcing reasonable restrictions on op erator declarations. Wehave b een able to describ e the syntax of Prolog, a language known for its lib eral use of op erators, and Standard ML, which supp orts lo cal declarations of op erators. De nite clause grammars DCGs, a novel parsing feature of Prolog, can b e translated into ecient co de by our parser generator.