Parsing with Earley Virtual Machines
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Derivatives of Parsing Expression Grammars
Derivatives of Parsing Expression Grammars Aaron Moss Cheriton School of Computer Science University of Waterloo Waterloo, Ontario, Canada [email protected] This paper introduces a new derivative parsing algorithm for recognition of parsing expression gram- mars. Derivative parsing is shown to have a polynomial worst-case time bound, an improvement on the exponential bound of the recursive descent algorithm. This work also introduces asymptotic analysis based on inputs with a constant bound on both grammar nesting depth and number of back- tracking choices; derivative and recursive descent parsing are shown to run in linear time and constant space on this useful class of inputs, with both the theoretical bounds and the reasonability of the in- put class validated empirically. This common-case constant memory usage of derivative parsing is an improvement on the linear space required by the packrat algorithm. 1 Introduction Parsing expression grammars (PEGs) are a parsing formalism introduced by Ford [6]. Any LR(k) lan- guage can be represented as a PEG [7], but there are some non-context-free languages that may also be represented as PEGs (e.g. anbncn [7]). Unlike context-free grammars (CFGs), PEGs are unambiguous, admitting no more than one parse tree for any grammar and input. PEGs are a formalization of recursive descent parsers allowing limited backtracking and infinite lookahead; a string in the language of a PEG can be recognized in exponential time and linear space using a recursive descent algorithm, or linear time and space using the memoized packrat algorithm [6]. PEGs are formally defined and these algo- rithms outlined in Section 3. -

LATE Ain't Earley: a Faster Parallel Earley Parser
LATE Ain’T Earley: A Faster Parallel Earley Parser Peter Ahrens John Feser Joseph Hui [email protected] [email protected] [email protected] July 18, 2018 Abstract We present the LATE algorithm, an asynchronous variant of the Earley algorithm for pars- ing context-free grammars. The Earley algorithm is naturally task-based, but is difficult to parallelize because of dependencies between the tasks. We present the LATE algorithm, which uses additional data structures to maintain information about the state of the parse so that work items may be processed in any order. This property allows the LATE algorithm to be sped up using task parallelism. We show that the LATE algorithm can achieve a 120x speedup over the Earley algorithm on a natural language task. 1 Introduction Improvements in the efficiency of parsers for context-free grammars (CFGs) have the potential to speed up applications in software development, computational linguistics, and human-computer interaction. The Earley parser has an asymptotic complexity that scales with the complexity of the CFG, a unique, desirable trait among parsers for arbitrary CFGs. However, while the more commonly used Cocke-Younger-Kasami (CYK) [2, 5, 12] parser has been successfully parallelized [1, 7], the Earley algorithm has seen relatively few attempts at parallelization. Our research objectives were to understand when there exists parallelism in the Earley algorithm, and to explore methods for exploiting this parallelism. We first tried to naively parallelize the Earley algorithm by processing the Earley items in each Earley set in parallel. We found that this approach does not produce any speedup, because the dependencies between Earley items force much of the work to be performed sequentially. -

Lecture 10: CYK and Earley Parsers Alvin Cheung Building Parse Trees Maaz Ahmad CYK and Earley Algorithms Talia Ringer More Disambiguation
Hack Your Language! CSE401 Winter 2016 Introduction to Compiler Construction Ras Bodik Lecture 10: CYK and Earley Parsers Alvin Cheung Building Parse Trees Maaz Ahmad CYK and Earley algorithms Talia Ringer More Disambiguation Ben Tebbs 1 Announcements • HW3 due Sunday • Project proposals due tonight – No late days • Review session this Sunday 6-7pm EEB 115 2 Outline • Last time we saw how to construct AST from parse tree • We will now discuss algorithms for generating parse trees from input strings 3 Today CYK parser builds the parse tree bottom up More Disambiguation Forcing the parser to select the desired parse tree Earley parser solves CYK’s inefficiency 4 CYK parser Parser Motivation • Given a grammar G and an input string s, we need an algorithm to: – Decide whether s is in L(G) – If so, generate a parse tree for s • We will see two algorithms for doing this today – Many others are available – Each with different tradeoffs in time and space 6 CYK Algorithm • Parsing algorithm for context-free grammars • Invented by John Cocke, Daniel Younger, and Tadao Kasami • Basic idea given string s with n tokens: 1. Find production rules that cover 1 token in s 2. Use 1. to find rules that cover 2 tokens in s 3. Use 2. to find rules that cover 3 tokens in s 4. … N. Use N-1. to find rules that cover n tokens in s. If succeeds then s is in L(G), else it is not 7 A graphical way to visualize CYK Initial graph: the input (terminals) Repeat: add non-terminal edges until no more can be added. -

Abstract Syntax Trees & Top-Down Parsing
Abstract Syntax Trees & Top-Down Parsing Review of Parsing • Given a language L(G), a parser consumes a sequence of tokens s and produces a parse tree • Issues: – How do we recognize that s ∈ L(G) ? – A parse tree of s describes how s ∈ L(G) – Ambiguity: more than one parse tree (possible interpretation) for some string s – Error: no parse tree for some string s – How do we construct the parse tree? Compiler Design 1 (2011) 2 Abstract Syntax Trees • So far, a parser traces the derivation of a sequence of tokens • The rest of the compiler needs a structural representation of the program • Abstract syntax trees – Like parse trees but ignore some details – Abbreviated as AST Compiler Design 1 (2011) 3 Abstract Syntax Trees (Cont.) • Consider the grammar E → int | ( E ) | E + E • And the string 5 + (2 + 3) • After lexical analysis (a list of tokens) int5 ‘+’ ‘(‘ int2 ‘+’ int3 ‘)’ • During parsing we build a parse tree … Compiler Design 1 (2011) 4 Example of Parse Tree E • Traces the operation of the parser E + E • Captures the nesting structure • But too much info int5 ( E ) – Parentheses – Single-successor nodes + E E int 2 int3 Compiler Design 1 (2011) 5 Example of Abstract Syntax Tree PLUS PLUS 5 2 3 • Also captures the nesting structure • But abstracts from the concrete syntax a more compact and easier to use • An important data structure in a compiler Compiler Design 1 (2011) 6 Semantic Actions • This is what we’ll use to construct ASTs • Each grammar symbol may have attributes – An attribute is a property of a programming language construct -

Simple, Efficient, Sound-And-Complete Combinator Parsing for All Context
Simple, efficient, sound-and-complete combinator parsing for all context-free grammars, using an oracle OCaml 2014 workshop, talk proposal Tom Ridge University of Leicester, UK [email protected] This proposal describes a parsing library that is based on current grammar, the start symbol and the input to the back-end Earley work due to be published as [3]. The talk will focus on the OCaml parser, which parses the input and returns a parsing oracle. The library and its usage. oracle is then used to guide the action phase of the parser. 1. Combinator parsers 4. Real-world performance 3 Parsers for context-free grammars can be implemented directly and In addition to O(n ) theoretical performance, we also optimize our naturally in a functional style known as “combinator parsing”, us- back-end Earley parser. Extensive performance measurements on ing recursion following the structure of the grammar rules. Tradi- small grammars (described in [3]) indicate that the performance is tionally parser combinators have struggled to handle all features of arguably better than the Happy parser generator [1]. context-free grammars, such as left recursion. 5. Online distribution 2. Sound and complete combinator parsers This work has led to the P3 parsing library for OCaml, freely Previous work [2] introduced novel parser combinators that could available online1. The distribution includes extensive examples. be used to parse all context-free grammars. A parser generator built Some of the examples are: using these combinators was proved both sound and complete in the • HOL4 theorem prover. Parsing and disambiguation of arithmetic expressions using This previous approach has all the traditional benefits of combi- precedence annotations. -

Improving Upon Earley's Parsing Algorithm in Prolog
Improving Upon Earley’s Parsing Algorithm In Prolog Matt Voss Artificial Intelligence Center University of Georgia Athens, GA 30602 May 7, 2004 Abstract This paper presents a modification of the Earley (1970) parsing algorithm in Prolog. The Earley algorithm presented here is based on an implementation in Covington (1994a). The modifications are meant to improve on that algorithm in several key ways. The parser features a predictor that works like a left-corner parser with links, thus decreasing the number of chart entries. It implements subsump- tion checking, and organizes chart entries to take advantage of first argument indexing for quick retrieval. 1 Overview The Earley parsing algorithm is well known for its great efficiency in produc- ing all possible parses of a sentence in relatively little time, without back- tracking, and while handling left recursive rules correctly. It is also known for being considerably slower than most other parsing algorithms1. This pa- per outlines an attempt to overcome many of the pitfalls associated with implementations of Earley parsers. It uses the Earley parser in Covington (1994a) as a starting point. In particular the Earley top-down predictor is exchanged for a predictor that works like a left-corner predictor with links, 1See Covington (1994a) for one comparison of run times for a variety of algorithms. 1 following Leiss (1990). Chart entries store the positions of constituents in the input string, rather than lists containing the constituents themselves, and the arguments of chart entries are arranged to take advantage of first argument indexing. This means a small trade-off between easy-to-read code and efficiency of processing. -

AST Indexing: a Near-Constant Time Solution to the Get-Descendants-By-Type Problem Samuel Livingston Kelly Dickinson College
Dickinson College Dickinson Scholar Student Honors Theses By Year Student Honors Theses 5-18-2014 AST Indexing: A Near-Constant Time Solution to the Get-Descendants-by-Type Problem Samuel Livingston Kelly Dickinson College Follow this and additional works at: http://scholar.dickinson.edu/student_honors Part of the Software Engineering Commons Recommended Citation Kelly, Samuel Livingston, "AST Indexing: A Near-Constant Time Solution to the Get-Descendants-by-Type Problem" (2014). Dickinson College Honors Theses. Paper 147. This Honors Thesis is brought to you for free and open access by Dickinson Scholar. It has been accepted for inclusion by an authorized administrator. For more information, please contact [email protected]. AST Indexing: A Near-Constant Time Solution to the Get-Descendants-by-Type Problem by Sam Kelly Submitted in partial fulfillment of Honors Requirements for the Computer Science Major Dickinson College, 2014 Associate Professor Tim Wahls, Supervisor Associate Professor John MacCormick, Reader Part-Time Instructor Rebecca Wells, Reader April 22, 2014 The Department of Mathematics and Computer Science at Dickinson College hereby accepts this senior honors thesis by Sam Kelly, and awards departmental honors in Computer Science. Tim Wahls (Advisor) Date John MacCormick (Committee Member) Date Rebecca Wells (Committee Member) Date Richard Forrester (Department Chair) Date Department of Mathematics and Computer Science Dickinson College April 2014 ii Abstract AST Indexing: A Near-Constant Time Solution to the Get- Descendants-by-Type Problem by Sam Kelly In this paper we present two novel abstract syntax tree (AST) indexing algorithms that solve the get-descendants-by-type problem in near constant time. -

Advanced Parsing Techniques
Advanced Parsing Techniques Announcements ● Written Set 1 graded. ● Hard copies available for pickup right now. ● Electronic submissions: feedback returned later today. Where We Are Where We Are Parsing so Far ● We've explored five deterministic parsing algorithms: ● LL(1) ● LR(0) ● SLR(1) ● LALR(1) ● LR(1) ● These algorithms all have their limitations. ● Can we parse arbitrary context-free grammars? Why Parse Arbitrary Grammars? ● They're easier to write. ● Can leave operator precedence and associativity out of the grammar. ● No worries about shift/reduce or FIRST/FOLLOW conflicts. ● If ambiguous, can filter out invalid trees at the end. ● Generate candidate parse trees, then eliminate them when not needed. ● Practical concern for some languages. ● We need to have C and C++ compilers! Questions for Today ● How do you go about parsing ambiguous grammars efficiently? ● How do you produce all possible parse trees? ● What else can we do with a general parser? The Earley Parser Motivation: The Limits of LR ● LR parsers use shift and reduce actions to reduce the input to the start symbol. ● LR parsers cannot deterministically handle shift/reduce or reduce/reduce conflicts. ● However, they can nondeterministically handle these conflicts by guessing which option to choose. ● What if we try all options and see if any of them work? The Earley Parser ● Maintain a collection of Earley items, which are LR(0) items annotated with a start position. ● The item A → α·ω @n means we are working on recognizing A → αω, have seen α, and the start position of the item was the nth token. ● Using techniques similar to LR parsing, try to scan across the input creating these items. -
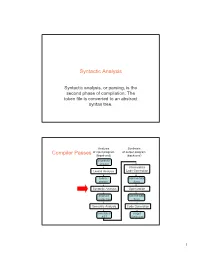
Syntactic Analysis, Or Parsing, Is the Second Phase of Compilation: the Token File Is Converted to an Abstract Syntax Tree
Syntactic Analysis Syntactic analysis, or parsing, is the second phase of compilation: The token file is converted to an abstract syntax tree. Analysis Synthesis Compiler Passes of input program of output program (front -end) (back -end) character stream Intermediate Lexical Analysis Code Generation token intermediate stream form Syntactic Analysis Optimization abstract intermediate syntax tree form Semantic Analysis Code Generation annotated target AST language 1 Syntactic Analysis / Parsing • Goal: Convert token stream to abstract syntax tree • Abstract syntax tree (AST): – Captures the structural features of the program – Primary data structure for remainder of analysis • Three Part Plan – Study how context-free grammars specify syntax – Study algorithms for parsing / building ASTs – Study the miniJava Implementation Context-free Grammars • Compromise between – REs, which can’t nest or specify recursive structure – General grammars, too powerful, undecidable • Context-free grammars are a sweet spot – Powerful enough to describe nesting, recursion – Easy to parse; but also allow restrictions for speed • Not perfect – Cannot capture semantics, as in, “variable must be declared,” requiring later semantic pass – Can be ambiguous • EBNF, Extended Backus Naur Form, is popular notation 2 CFG Terminology • Terminals -- alphabet of language defined by CFG • Nonterminals -- symbols defined in terms of terminals and nonterminals • Productions -- rules for how a nonterminal (lhs) is defined in terms of a (possibly empty) sequence of terminals -

Lecture 3: Recursive Descent Limitations, Precedence Climbing
Lecture 3: Recursive descent limitations, precedence climbing David Hovemeyer September 9, 2020 601.428/628 Compilers and Interpreters Today I Limitations of recursive descent I Precedence climbing I Abstract syntax trees I Supporting parenthesized expressions Before we begin... Assume a context-free struct Node *Parser::parse_A() { grammar has the struct Node *next_tok = lexer_peek(m_lexer); following productions on if (!next_tok) { the nonterminal A: error("Unexpected end of input"); } A → b C A → d E struct Node *a = node_build0(NODE_A); int tag = node_get_tag(next_tok); (A, C, E are if (tag == TOK_b) { nonterminals; b, d are node_add_kid(a, expect(TOK_b)); node_add_kid(a, parse_C()); terminals) } else if (tag == TOK_d) { What is the problem node_add_kid(a, expect(TOK_d)); node_add_kid(a, parse_E()); with the parse function } shown on the right? return a; } Limitations of recursive descent Recall: a better infix expression grammar Grammar (start symbol is A): A → i = A T → T*F A → E T → T/F E → E + T T → F E → E-T F → i E → T F → n Precedence levels: Nonterminal Precedence Meaning Operators Associativity A lowest Assignment = right E Expression + - left T Term * / left F highest Factor No Parsing infix expressions Can we write a recursive descent parser for infix expressions using this grammar? Parsing infix expressions Can we write a recursive descent parser for infix expressions using this grammar? No Left recursion Left-associative operators want to have left-recursive productions, but recursive descent parsers can’t handle left recursion -

0368-3133 Lecture 4: Syntax Analysis: Earley Parsing Bottom-Up
Compilation 0368-3133 Lecture 4: Syntax Analysis: Earley Parsing Bottom-Up Parsing Noam Rinetzky 1 The Real Anatomy oF a Compiler txt Process Lexical Syntax Sem. characters Lexical tokens Syntax AST Source text Analysis Analysis Analysis input text Annotated AST Intermediate Intermediate Code code IR code IR generation generation optimization Symbolic Instructions exe Target code SI Machine code MI Write optimization generation executable Executable output code 2 Broad kinds of parsers • Parsers For arbitrary grammars – Earley’s method, CYK method – Usually, not used in practice (though might change) • Top-Down parsers – Construct parse tree in a top-down matter – Find the leFtmost derivation • Bottom-Up parsers – Construct parse tree in a bottom-up manner – Find the rightmost derivation in a reverse order 3 Intuition: Top-down parsing • Begin with start symbol • Guess the productions • Check iF parse tree yields user's program 4 Intuition: Top-down parsing Unambiguous grammar E ® E + T E ® T T ® T * F T ® F E F ® id F ® num E F ® ( E ) T T T F F F 1 * 2 + 3 5 Intuition: Top-down parsing Unambiguous grammar Left-most E ® E + T derivation E ® T T ® T * F T ® F E F ® id F ® num F ® ( E ) 1 * 2 + 3 6 Intuition: Top-down parsing Unambiguous grammar E ® E + T E ® T T ® T * F T ® F E F ® id F ® num E F ® ( E ) T 1 * 2 + 3 7 Intuition: Top-down parsing Unambiguous grammar E ® E + T E ® T T ® T * F T ® F E F ® id F ® num E F ® ( E ) T T 1 * 2 + 3 8 Intuition: Top-Down parsing Unambiguous grammar E ® E + T E ® T T ® T * F T ® F E F ® id F ® num -

Understanding Source Code Evolution Using Abstract Syntax Tree Matching
Understanding Source Code Evolution Using Abstract Syntax Tree Matching Iulian Neamtiu Jeffrey S. Foster Michael Hicks [email protected] [email protected] [email protected] Department of Computer Science University of Maryland at College Park ABSTRACT so understanding how the type structure of real programs Mining software repositories at the source code level can pro- changes over time can be invaluable for weighing the merits vide a greater understanding of how software evolves. We of DSU implementation choices. Second, we are interested in present a tool for quickly comparing the source code of dif- a kind of “release digest” for explaining changes in a software ferent versions of a C program. The approach is based on release: what functions or variables have changed, where the partial abstract syntax tree matching, and can track sim- hot spots are, whether or not the changes affect certain com- ple changes to global variables, types and functions. These ponents, etc. Typical release notes can be too high level for changes can characterize aspects of software evolution use- developers, and output from diff can be too low level. ful for answering higher level questions. In particular, we To answer these and other software evolution questions, consider how they could be used to inform the design of a we have developed a tool that can quickly tabulate and sum- dynamic software updating system. We report results based marize simple changes to successive versions of C programs on measurements of various versions of popular open source by partially matching their abstract syntax trees. The tool programs, including BIND, OpenSSH, Apache, Vsftpd and identifies the changes, additions, and deletions of global vari- the Linux kernel.