Codegenassem.Java) Lexical Analysis (Scanning)
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Derivatives of Parsing Expression Grammars
Derivatives of Parsing Expression Grammars Aaron Moss Cheriton School of Computer Science University of Waterloo Waterloo, Ontario, Canada [email protected] This paper introduces a new derivative parsing algorithm for recognition of parsing expression gram- mars. Derivative parsing is shown to have a polynomial worst-case time bound, an improvement on the exponential bound of the recursive descent algorithm. This work also introduces asymptotic analysis based on inputs with a constant bound on both grammar nesting depth and number of back- tracking choices; derivative and recursive descent parsing are shown to run in linear time and constant space on this useful class of inputs, with both the theoretical bounds and the reasonability of the in- put class validated empirically. This common-case constant memory usage of derivative parsing is an improvement on the linear space required by the packrat algorithm. 1 Introduction Parsing expression grammars (PEGs) are a parsing formalism introduced by Ford [6]. Any LR(k) lan- guage can be represented as a PEG [7], but there are some non-context-free languages that may also be represented as PEGs (e.g. anbncn [7]). Unlike context-free grammars (CFGs), PEGs are unambiguous, admitting no more than one parse tree for any grammar and input. PEGs are a formalization of recursive descent parsers allowing limited backtracking and infinite lookahead; a string in the language of a PEG can be recognized in exponential time and linear space using a recursive descent algorithm, or linear time and space using the memoized packrat algorithm [6]. PEGs are formally defined and these algo- rithms outlined in Section 3. -

Ece351 Lab Manual
DEREK RAYSIDE & ECE351 STAFF ECE351 LAB MANUAL UNIVERSITYOFWATERLOO 2 derek rayside & ece351 staff Copyright © 2014 Derek Rayside & ECE351 Staff Compiled March 6, 2014 acknowledgements: • Prof Paul Ward suggested that we look into something with vhdl to have synergy with ece327. • Prof Mark Aagaard, as the ece327 instructor, consulted throughout the development of this material. • Prof Patrick Lam generously shared his material from the last offering of ece251. • Zhengfang (Alex) Duanmu & Lingyun (Luke) Li [1b Elec] wrote solutions to most labs in txl. • Jiantong (David) Gao & Rui (Ray) Kong [3b Comp] wrote solutions to the vhdl labs in antlr. • Aman Muthrej and Atulan Zaman [3a Comp] wrote solutions to the vhdl labs in Parboiled. • TA’s Jon Eyolfson, Vajih Montaghami, Alireza Mortezaei, Wenzhu Man, and Mohammed Hassan. • TA Wallace Wu developed the vhdl labs. • High school students Brian Engio and Tianyu Guo drew a number of diagrams for this manual, wrote Javadoc comments for the code, and provided helpful comments on the manual. Licensed under Creative Commons Attribution-ShareAlike (CC BY-SA) version 2.5 or greater. http://creativecommons.org/licenses/by-sa/2.5/ca/ http://creativecommons.org/licenses/by-sa/3.0/ Contents 0 Overview 9 Compiler Concepts: call stack, heap 0.1 How the Labs Fit Together . 9 Programming Concepts: version control, push, pull, merge, SSH keys, IDE, 0.2 Learning Progressions . 11 debugger, objects, pointers 0.3 How this project compares to CS241, the text book, etc. 13 0.4 Student work load . 14 0.5 How this course compares to MIT 6.035 .......... 15 0.6 Where do I learn more? . -

Implementation of Processing in Racket 1 Introduction
P2R Implementation of Processing in Racket Hugo Correia [email protected] Instituto Superior T´ecnico University of Lisbon Abstract. Programming languages are being introduced in several ar- eas of expertise, including design and architecture. Processing is an ex- ample of one of these languages that was created to teach architects and designers how to program. In spite of offering a wide set of features, Pro- cessing does not support the use of traditional computer-aided design applications, which are heavily used in the architecture industry. Rosetta is a generative design tool based on the Racket language that attempts to solve this problem. Rosetta provides a novel approach to de- sign creation, offering a set of programming languages that generate de- signs in different computer-aided design applications. However, Rosetta does not support Processing. Therefore, the goal is to add Processing to Rosetta's language set, offering architects that know Processing, an alternative solution that supports computer-aided design applications. In order to achieve this goal, a source-to-source compiler that translates Processing into Racket will be developed. This will also give the Racket community the ability to use Processing in the Racket environment, and, at the same time, will allow the Processing community to take advantage of Racket's libraries and development environment. In this report, an analysis of different language implementation mecha- nisms will be presented, focusing on the different steps of the compilation phase, as well as higher-level solutions, including Language Workbenches. In order to gain insight of source-to-source compiler creation, relevant existing source-to-source compilers are presented. -

Adaptive LL(*) Parsing: the Power of Dynamic Analysis
Adaptive LL(*) Parsing: The Power of Dynamic Analysis Terence Parr Sam Harwell Kathleen Fisher University of San Francisco University of Texas at Austin Tufts University [email protected] [email protected] kfi[email protected] Abstract PEGs are unambiguous by definition but have a quirk where Despite the advances made by modern parsing strategies such rule A ! a j ab (meaning “A matches either a or ab”) can never as PEG, LL(*), GLR, and GLL, parsing is not a solved prob- match ab since PEGs choose the first alternative that matches lem. Existing approaches suffer from a number of weaknesses, a prefix of the remaining input. Nested backtracking makes de- including difficulties supporting side-effecting embedded ac- bugging PEGs difficult. tions, slow and/or unpredictable performance, and counter- Second, side-effecting programmer-supplied actions (muta- intuitive matching strategies. This paper introduces the ALL(*) tors) like print statements should be avoided in any strategy that parsing strategy that combines the simplicity, efficiency, and continuously speculates (PEG) or supports multiple interpreta- predictability of conventional top-down LL(k) parsers with the tions of the input (GLL and GLR) because such actions may power of a GLR-like mechanism to make parsing decisions. never really take place [17]. (Though DParser [24] supports The critical innovation is to move grammar analysis to parse- “final” actions when the programmer is certain a reduction is time, which lets ALL(*) handle any non-left-recursive context- part of an unambiguous final parse.) Without side effects, ac- free grammar. ALL(*) is O(n4) in theory but consistently per- tions must buffer data for all interpretations in immutable data forms linearly on grammars used in practice, outperforming structures or provide undo actions. -

Abstract Syntax Trees & Top-Down Parsing
Abstract Syntax Trees & Top-Down Parsing Review of Parsing • Given a language L(G), a parser consumes a sequence of tokens s and produces a parse tree • Issues: – How do we recognize that s ∈ L(G) ? – A parse tree of s describes how s ∈ L(G) – Ambiguity: more than one parse tree (possible interpretation) for some string s – Error: no parse tree for some string s – How do we construct the parse tree? Compiler Design 1 (2011) 2 Abstract Syntax Trees • So far, a parser traces the derivation of a sequence of tokens • The rest of the compiler needs a structural representation of the program • Abstract syntax trees – Like parse trees but ignore some details – Abbreviated as AST Compiler Design 1 (2011) 3 Abstract Syntax Trees (Cont.) • Consider the grammar E → int | ( E ) | E + E • And the string 5 + (2 + 3) • After lexical analysis (a list of tokens) int5 ‘+’ ‘(‘ int2 ‘+’ int3 ‘)’ • During parsing we build a parse tree … Compiler Design 1 (2011) 4 Example of Parse Tree E • Traces the operation of the parser E + E • Captures the nesting structure • But too much info int5 ( E ) – Parentheses – Single-successor nodes + E E int 2 int3 Compiler Design 1 (2011) 5 Example of Abstract Syntax Tree PLUS PLUS 5 2 3 • Also captures the nesting structure • But abstracts from the concrete syntax a more compact and easier to use • An important data structure in a compiler Compiler Design 1 (2011) 6 Semantic Actions • This is what we’ll use to construct ASTs • Each grammar symbol may have attributes – An attribute is a property of a programming language construct -

Conflict Resolution in a Recursive Descent Compiler Generator
LL(1) Conflict Resolution in a Recursive Descent Compiler Generator Albrecht Wöß, Markus Löberbauer, Hanspeter Mössenböck Johannes Kepler University Linz, Institute of Practical Computer Science, Altenbergerstr. 69, 4040 Linz, Austria {woess,loeberbauer,moessenboeck}@ssw.uni-linz.ac.at Abstract. Recursive descent parsing is restricted to languages whose grammars are LL(1), i.e., which can be parsed top-down with a single lookahead symbol. Unfortunately, many languages such as Java, C++, or C# are not LL(1). There- fore recursive descent parsing cannot be used or the parser has to make its deci- sions based on semantic information or a multi-symbol lookahead. In this paper we suggest a systematic technique for resolving LL(1) conflicts in recursive descent parsing and show how to integrate it into a compiler gen- erator (Coco/R). The idea is to evaluate user-defined boolean expressions, in order to allow the parser to make its parsing decisions where a one symbol loo- kahead does not suffice. Using our extended compiler generator we implemented a compiler front end for C# that can be used as a framework for implementing a variety of tools. 1 Introduction Recursive descent parsing [16] is a popular top-down parsing technique that is sim- ple, efficient, and convenient for integrating semantic processing. However, it re- quires the grammar of the parsed language to be LL(1), which means that the parser must always be able to select between alternatives with a single symbol lookahead. Unfortunately, many languages such as Java, C++ or C# are not LL(1) so that one either has to resort to bottom-up LALR(1) parsing [5, 1], which is more powerful but less convenient for semantic processing, or the parser has to resolve the LL(1) con- flicts using semantic information or a multi-symbol lookahead. -

Keyword Based Search Engine for Web Applications Using Lucene and Javacc Priyesh Wani, Nikita Shah, Kapil Thombare, Chaitalee Zade
Priyesh Wani et al IJCSET |April 2012| Vol 2, Issue 4,1143-1146 Keyword based Search Engine for Web Applications Using Lucene and JavaCC Priyesh Wani, Nikita Shah, Kapil Thombare, Chaitalee Zade Information Technology, Computer Science University of Pune [email protected] [email protected] [email protected] [email protected] Abstract—Past Few years IT industry has taken leap towards functionality to an application or website. Lucene is able to developing Web based Applications. The need aroused due to achieve fast search responses because, instead of searching increasing globalization. Web applications has revolutionized the text directly, it searches an index instead. Which is the way business processes. It provides scalability and equivalent to retrieving pages in a book related to a extensibility in managing different processes in respective keyword by searching the index at the back of a book, as domains. With evolving standard of these web applications some functionalities has become part of that standard, Search opposed to searching the words in each page of the book. Engine being one of them. Organization dealing with large JavacCC: Java Compiler Compiler (JavaCC) is the most number of clients has to face an overhead of maintaining huge popular parser generator for use with Java applications. A databases. Retrieval of data in that case becomes difficult from parser generator is a tool that reads a grammar specification developer’s point of view. In this paper we have presented an and converts it to a Java program that can recognize efficient way of implementing keyword based search engine matches to the grammar. -

AST Indexing: a Near-Constant Time Solution to the Get-Descendants-By-Type Problem Samuel Livingston Kelly Dickinson College
Dickinson College Dickinson Scholar Student Honors Theses By Year Student Honors Theses 5-18-2014 AST Indexing: A Near-Constant Time Solution to the Get-Descendants-by-Type Problem Samuel Livingston Kelly Dickinson College Follow this and additional works at: http://scholar.dickinson.edu/student_honors Part of the Software Engineering Commons Recommended Citation Kelly, Samuel Livingston, "AST Indexing: A Near-Constant Time Solution to the Get-Descendants-by-Type Problem" (2014). Dickinson College Honors Theses. Paper 147. This Honors Thesis is brought to you for free and open access by Dickinson Scholar. It has been accepted for inclusion by an authorized administrator. For more information, please contact [email protected]. AST Indexing: A Near-Constant Time Solution to the Get-Descendants-by-Type Problem by Sam Kelly Submitted in partial fulfillment of Honors Requirements for the Computer Science Major Dickinson College, 2014 Associate Professor Tim Wahls, Supervisor Associate Professor John MacCormick, Reader Part-Time Instructor Rebecca Wells, Reader April 22, 2014 The Department of Mathematics and Computer Science at Dickinson College hereby accepts this senior honors thesis by Sam Kelly, and awards departmental honors in Computer Science. Tim Wahls (Advisor) Date John MacCormick (Committee Member) Date Rebecca Wells (Committee Member) Date Richard Forrester (Department Chair) Date Department of Mathematics and Computer Science Dickinson College April 2014 ii Abstract AST Indexing: A Near-Constant Time Solution to the Get- Descendants-by-Type Problem by Sam Kelly In this paper we present two novel abstract syntax tree (AST) indexing algorithms that solve the get-descendants-by-type problem in near constant time. -
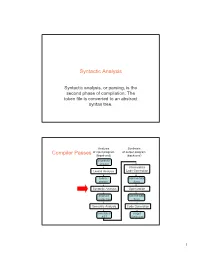
Syntactic Analysis, Or Parsing, Is the Second Phase of Compilation: the Token File Is Converted to an Abstract Syntax Tree
Syntactic Analysis Syntactic analysis, or parsing, is the second phase of compilation: The token file is converted to an abstract syntax tree. Analysis Synthesis Compiler Passes of input program of output program (front -end) (back -end) character stream Intermediate Lexical Analysis Code Generation token intermediate stream form Syntactic Analysis Optimization abstract intermediate syntax tree form Semantic Analysis Code Generation annotated target AST language 1 Syntactic Analysis / Parsing • Goal: Convert token stream to abstract syntax tree • Abstract syntax tree (AST): – Captures the structural features of the program – Primary data structure for remainder of analysis • Three Part Plan – Study how context-free grammars specify syntax – Study algorithms for parsing / building ASTs – Study the miniJava Implementation Context-free Grammars • Compromise between – REs, which can’t nest or specify recursive structure – General grammars, too powerful, undecidable • Context-free grammars are a sweet spot – Powerful enough to describe nesting, recursion – Easy to parse; but also allow restrictions for speed • Not perfect – Cannot capture semantics, as in, “variable must be declared,” requiring later semantic pass – Can be ambiguous • EBNF, Extended Backus Naur Form, is popular notation 2 CFG Terminology • Terminals -- alphabet of language defined by CFG • Nonterminals -- symbols defined in terms of terminals and nonterminals • Productions -- rules for how a nonterminal (lhs) is defined in terms of a (possibly empty) sequence of terminals -

Lecture 3: Recursive Descent Limitations, Precedence Climbing
Lecture 3: Recursive descent limitations, precedence climbing David Hovemeyer September 9, 2020 601.428/628 Compilers and Interpreters Today I Limitations of recursive descent I Precedence climbing I Abstract syntax trees I Supporting parenthesized expressions Before we begin... Assume a context-free struct Node *Parser::parse_A() { grammar has the struct Node *next_tok = lexer_peek(m_lexer); following productions on if (!next_tok) { the nonterminal A: error("Unexpected end of input"); } A → b C A → d E struct Node *a = node_build0(NODE_A); int tag = node_get_tag(next_tok); (A, C, E are if (tag == TOK_b) { nonterminals; b, d are node_add_kid(a, expect(TOK_b)); node_add_kid(a, parse_C()); terminals) } else if (tag == TOK_d) { What is the problem node_add_kid(a, expect(TOK_d)); node_add_kid(a, parse_E()); with the parse function } shown on the right? return a; } Limitations of recursive descent Recall: a better infix expression grammar Grammar (start symbol is A): A → i = A T → T*F A → E T → T/F E → E + T T → F E → E-T F → i E → T F → n Precedence levels: Nonterminal Precedence Meaning Operators Associativity A lowest Assignment = right E Expression + - left T Term * / left F highest Factor No Parsing infix expressions Can we write a recursive descent parser for infix expressions using this grammar? Parsing infix expressions Can we write a recursive descent parser for infix expressions using this grammar? No Left recursion Left-associative operators want to have left-recursive productions, but recursive descent parsers can’t handle left recursion -

Literature Review
Rhodes University Computer Science Department Honours year project Literature Review Author: Etienne Stalmans Supervisor: Dr. Karen Bradshaw June 2010 1 Introduction Software visualisation (SV) is the process of producing a visual metaphor to represent the operation of a program or algorithm [13]. The use of SV in teaching is not a new concept and numerous studies have been performed to evaluate its effectiveness. The aim of SV in teaching is to increase learners understanding of concepts through simplification. In order for a SV system to be successful, the visual metaphor needs to effectively and efficiently relay the mapped data [4, 8]. Dougles et al., [8] found that \active use of visualizations by students improves their learning process". Compiler generators produce human-readable parsers from user specified grammars. A grammar is used to formalise the syntax and semantics of a language. In order to understand how a language is parsed, it is important to understand the grammar first. Grammars are classified according to hierarchical type. The grammar type determines which parsing method will be used to evaluate it.One such parsing method is recursive descent parsing. Recursive descent parsers are used to parse Type 2 grammars [25], also known as context free grammars. Coco/R is a recursive descent parser generator which is used to teach compiler theory [25]. VCOCO provides limited visualisation of Coco/R operation. This is done by highlighting the current execution point [23]; providing a debugging approach to expert users [2]. Thus VCOCO is not suitable to be used as an education tool [2], as it assumes prior knowledge of compilers and does not contain explanation facilities which beginners require. -

Understanding Source Code Evolution Using Abstract Syntax Tree Matching
Understanding Source Code Evolution Using Abstract Syntax Tree Matching Iulian Neamtiu Jeffrey S. Foster Michael Hicks [email protected] [email protected] [email protected] Department of Computer Science University of Maryland at College Park ABSTRACT so understanding how the type structure of real programs Mining software repositories at the source code level can pro- changes over time can be invaluable for weighing the merits vide a greater understanding of how software evolves. We of DSU implementation choices. Second, we are interested in present a tool for quickly comparing the source code of dif- a kind of “release digest” for explaining changes in a software ferent versions of a C program. The approach is based on release: what functions or variables have changed, where the partial abstract syntax tree matching, and can track sim- hot spots are, whether or not the changes affect certain com- ple changes to global variables, types and functions. These ponents, etc. Typical release notes can be too high level for changes can characterize aspects of software evolution use- developers, and output from diff can be too low level. ful for answering higher level questions. In particular, we To answer these and other software evolution questions, consider how they could be used to inform the design of a we have developed a tool that can quickly tabulate and sum- dynamic software updating system. We report results based marize simple changes to successive versions of C programs on measurements of various versions of popular open source by partially matching their abstract syntax trees. The tool programs, including BIND, OpenSSH, Apache, Vsftpd and identifies the changes, additions, and deletions of global vari- the Linux kernel.