Prototypes and Hyperspee: Where Are They in the Grammar?
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

12 Morphology and Lexical Semantics
248 Beth Levin and Malka Rappaport Hovav 12 Morphology and Lexical Semantics BETH LEVIN AND MALKA RAPPAPORT HOVAV The relation between lexical semantics and morphology has not been the subject of much study. This may seem surprising, since a morpheme is often viewed as a minimal Saussurean sign relating form and meaning: it is a concept with a phonologically composed name. On this view, morphology has both a semantic side and a structural side, the latter sometimes called “morphological realization” (Aronoff 1994, Zwicky 1986b). Since morphology is the study of the structure and derivation of complex signs, attention could be focused on the semantic side (the composition of complex concepts) and the structural side (the composition of the complex names for the concepts) and the relation between them. In fact, recent work in morphology has been concerned almost exclusively with the composition of complex names for concepts – that is, with the struc- tural side of morphology. This dissociation of “form” from “meaning” was foreshadowed by Aronoff’s (1976) demonstration that morphemes are not necessarily associated with a constant meaning – or any meaning at all – and that their nature is basically structural. Although in early generative treat- ments of word formation, semantic operations accompanied formal morpho- logical operations (as in Aronoff’s Word Formation Rules), many subsequent generative theories of morphology, following Lieber (1980), explicitly dissoci- ate the lexical semantic operations of composition from the formal structural -

Studies in the Linguistic Sciences
UNIVERSITY OF ILLINOIS Llb'RARY AT URBANA-CHAMPAIGN MODERN LANGUAGE NOTICE: Return or renew all Library Materialsl The Minimum Fee (or each Lost Book is $50.00. The person charging this material is responsible for its return to the library from which it was withdrawn on or before the Latest Date stamped below. Theft, mutilation, and underlining of books are reasons for discipli- nary action and may result in dismissal from the University. To renew call Telephone Center, 333-8400 UNIVERSITY OF ILLINOIS LIBRARY AT URBANA-CHAMPAIGN ModeriJLanp & Lb Library ^rn 425 333-0076 L161—O-I096 Che Linguistic Sciences PAPERS IN GENERAL LINGUISTICS ANTHONY BRITTI Quantifier Repositioning SUSAN MEREDITH BURT Remarks on German Nominalization CHIN-CHUAN CHENG AND CHARLES KISSEBERTH Ikorovere Makua Tonology (Part 1) PETER COLE AND GABRIELLA HERMON Subject to Object Raising in an Est Framework: Evidence from Quechua RICHARD CURETON The Inclusion Constraint: Description and Explanation ALICE DAVISON Some Mysteries of Subordination CHARLES A. FERGUSON AND APIA DIL The Sociolinguistic Valiable (s) in Bengali: A Sound Change in Progress GABRIELLA HERMON Rule Ordering Versus Globality: Evidencefrom the Inversion Construction CHIN-W. KIM Neutralization in Korean Revisited DAVID ODDEN Principles of Stress Assignment: A Crosslinguistic View PAULA CHEN ROHRBACH The Acquisition of Chinese by Adult English Speakers: An Error Analysis MAURICE K.S. WONG Origin of the High Rising Changed Tone in Cantonese SORANEE WONGBIASAJ On the Passive in Thai Department of Linguistics University of Illinois^-^ STUDIES IN THE LINGUISTIC SCIENCES PUBLICATION OF THE DEPARTMENT OF LINGUISTICS UNIVERSITY OF ILLINOIS AT URBANA-CHAMPAIGN EDITORS: Charles W. Kisseberth, Braj B. -

Morphemes by Kirsten Mills Student, University of North Carolina at Pembroke, 1998
Morphemes by Kirsten Mills http://www.uncp.edu/home/canada/work/caneng/morpheme.htm Student, University of North Carolina at Pembroke, 1998 Introduction Morphemes are what make up words. Often, morphemes are thought of as words but that is not always true. Some single morphemes are words while other words have two or more morphemes within them. Morphemes are also thought of as syllables but this is incorrect. Many words have two or more syllables but only one morpheme. Banana, apple, papaya, and nanny are just a few examples. On the other hand, many words have two morphemes and only one syllable; examples include cats, runs, and barked. Definitions morpheme: a combination of sounds that have a meaning. A morpheme does not necessarily have to be a word. Example: the word cats has two morphemes. Cat is a morpheme, and s is a morpheme. Every morpheme is either a base or an affix. An affix can be either a prefix or a suffix. Cat is the base morpheme, and s is a suffix. affix: a morpheme that comes at the beginning (prefix) or the ending (suffix) of a base morpheme. Note: An affix usually is a morpheme that cannot stand alone. Examples: -ful, -ly, -ity, -ness. A few exceptions are able, like, and less. base: a morpheme that gives a word its meaning. The base morpheme cat gives the word cats its meaning: a particular type of animal. prefix: an affix that comes before a base morpheme. The in in the word inspect is a prefix. suffix: an affix that comes after a base morpheme. -

From Phoneme to Morpheme Author(S): Zellig S
Linguistic Society of America From Phoneme to Morpheme Author(s): Zellig S. Harris Source: Language, Vol. 31, No. 2 (Apr. - Jun., 1955), pp. 190-222 Published by: Linguistic Society of America Stable URL: http://www.jstor.org/stable/411036 Accessed: 09/02/2009 08:03 Your use of the JSTOR archive indicates your acceptance of JSTOR's Terms and Conditions of Use, available at http://www.jstor.org/page/info/about/policies/terms.jsp. JSTOR's Terms and Conditions of Use provides, in part, that unless you have obtained prior permission, you may not download an entire issue of a journal or multiple copies of articles, and you may use content in the JSTOR archive only for your personal, non-commercial use. Please contact the publisher regarding any further use of this work. Publisher contact information may be obtained at http://www.jstor.org/action/showPublisher?publisherCode=lsa. Each copy of any part of a JSTOR transmission must contain the same copyright notice that appears on the screen or printed page of such transmission. JSTOR is a not-for-profit organization founded in 1995 to build trusted digital archives for scholarship. We work with the scholarly community to preserve their work and the materials they rely upon, and to build a common research platform that promotes the discovery and use of these resources. For more information about JSTOR, please contact [email protected]. Linguistic Society of America is collaborating with JSTOR to digitize, preserve and extend access to Language. http://www.jstor.org FROM PHONEME TO MORPHEME ZELLIG S. HARRIS University of Pennsylvania 0.1. -
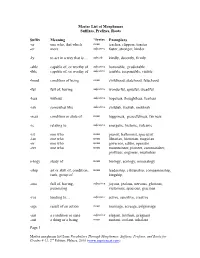
Morpheme Master List
Master List of Morphemes Suffixes, Prefixes, Roots Suffix Meaning *Syntax Exemplars -er one who, that which noun teacher, clippers, toaster -er more adjective faster, stronger, kinder -ly to act in a way that is… adverb kindly, decently, firmly -able capable of, or worthy of adjective honorable, predictable -ible capable of, or worthy of adjective terrible, responsible, visible -hood condition of being noun childhood, statehood, falsehood -ful full of, having adjective wonderful, spiteful, dreadful -less without adjective hopeless, thoughtless, fearless -ish somewhat like adjective childish, foolish, snobbish -ness condition or state of noun happiness, peacefulness, fairness -ic relating to adjective energetic, historic, volcanic -ist one who noun pianist, balloonist, specialist -ian one who noun librarian, historian, magician -or one who noun governor, editor, operator -eer one who noun mountaineer, pioneer, commandeer, profiteer, engineer, musketeer o-logy study of noun biology, ecology, mineralogy -ship art or skill of, condition, noun leadership, citizenship, companionship, rank, group of kingship -ous full of, having, adjective joyous, jealous, nervous, glorious, possessing victorious, spacious, gracious -ive tending to… adjective active, sensitive, creative -age result of an action noun marriage, acreage, pilgrimage -ant a condition or state adjective elegant, brilliant, pregnant -ant a thing or a being noun mutant, coolant, inhalant Page 1 Master morpheme list from Vocabulary Through Morphemes: Suffixes, Prefixes, and Roots for -

Stylistics Lecture 3 Morphemes & Semantics
Stylistics Lecture 3 Morphemes & Semantics MOAZZAM A L I MALIK ASSISTANT PROFESSOR UNIVERSITY OF GUJRAT Words & Morphemes Words are potentially complex units, composed of even more basic units, called morphemes. A morpheme is the smallest part of a word that has grammatical function or meaning. we will designate them in braces { }. For example, played, plays, playing can all be analyzed into the morphemes {play} + {-ed}, {-s}, and {-ing}, respectively. Basic Concepts in Morphology The English plural morpheme {-s} can be expressed by three different but clearly related phonemic forms /iz/, /z/, and /s/. These are the variant phonological realizations of plural morpheme and hence are known as allomorphs. Morph is a minimal meaningful form, regardless of whether it is a morpheme or allomorph. Basic Concepts in Morphology Affixes are classified according to whether they are attached before or after the form to which they are added. A root morpheme is the basic form to which other morphemes are attached In moveable, {-able} is attached to {move}, which we’ve determined is the word’s root. However, {im- } is attached to moveable, not to {move} (there is no word immove), but moveable is not a root. Expressions to which affixes are attached are called bases. While roots may be bases, bases are not always roots. Basic Concepts in Morphology Words that have meaning by themselves—boy, food, door—are called lexical morphemes. Those words that function to specify the relationship between one lexical morpheme and another—words like at, in, on, -ed, -s— are called grammatical morphemes. Those morphemes that can stand alone as words are called free morphemes (e.g., boy, food, in, on). -

Foundational Literacy Glossary of Terms
Foundational Literacy Glossary of Terms Accuracy The ability to recognize words correctly Advanced Phonics Strategies for decoding multisyllabic words that include morphology and information about the meaning, pronunciation, and parts of speech of words gained from knowledge of prefixes, roots, and suffixes Affixes Affixes are word parts that are "fixed to" either the beginnings of words (prefixes) or the endings of words (suffixes). The word disrespectful has two affixes, a prefix (dis-) and a suffix (-ful) Alphabetic Awareness Knowledge of letters of the alphabet coupled with the understanding that the alphabet represents the sounds of spoken language and the correspondence of spoken sounds to written language Alphabetic Code Sound-symbol relationships to recognize words Alphabetic Principle The concept that letters and letter combinations represent individual phonemes in written words Alphabetic Understanding Understanding that the left-to-right spellings of printed words represent their phonemes from first to last Automaticity The ability to translate letters-to-sounds-to-words fluently, effortlessly Base Word A unit of meaning that can stand alone as a whole word (e.g., friend, pig). Also called a free morpheme. Also called a free morpheme Blend A blend is a consonant sequence before or after a vowel within a syllable, such as cl, br, or st; it is the written language equivalent of consonant cluster Blending The task of combining sounds rapidly to accurately represent the word Chunking A decoding strategy for separating words into -

Summary of Cruse
English D Lexical Semantics Course Mitthögskolan HT 2002 Morgan Lundberg Notes on Meaning in Language by D. Alan Cruse Meaning in Language by D.A. Cruse Chapter 5 Introduction to lexical semantics The nature of word meaning [Recap: Phoneme: minimal meaning distinguishing element: /d/, /f/, /u:/. Morpheme: minimal meaning bearing element: dis-, zebra, -tion] The (prototypical) word – ‘a minimal permutable (‘utbytbart’) element’ · Can be moved about in a sentence (or rather, position altered): Am I mad?/I am mad. · Can’t be - broken up by other elements [exception: ‘infixes’ – unusual in Eng.] - have its parts reordered: needlessly – *lylessneed Internal structure: root morpheme [+ derivational and/or inflectional morphemes (affixes)]. Grammatical words are said to have no root morpheme: on, a, or, the Note on compounds : polar bear, bluebird, sea horse – look like two morphemes, but are (semantically) best considered one unit – one root morpheme. Ex: Polar bear – ?This bear is polar. Bluebird – ?a/*any bird which is blue Sea horse - *a horse (that lives/swims/grazes) in/by the sea Cf. ordinary nominal modification: red house – the house is red Prosody is indicative (except in very long words): ‘sea ,lion (compound) vs. ‘big ‘house (common noun phrase). What is a word in lexical semantics? · Word form – phonologically (and/or graphically) distinct “shape”: bank, mole · Lexeme – phonologically and semantically distinct, autonomous symbolic unit (i.e., it can stand alone because it contains a root morpheme): bank1, bank 2, mole1, swimming, etc. - Inflected forms based on the same root count as the same lexeme: swims, swimming, swam, swum. · In lexical semantics, a word is the same as a lexeme (=lexical unit). -

Introduction to Words and Morphemes
MODULE 1 Introduction to Words and Morphemes Dr. Leany Nani Harsa, M.Si. INTRODUCTION nowledge of a language enables you to combine words to form phrases, K and phrases to form sentences. You cannot buy a dictionary of any language with all its sentences, because no dictionary can list all the possible sentences. Knowing a language means being able to produce new sentences never spoken before and to understand sentences never heard before. Knowledge of a language, then, makes it possible to understand and produce new sentences. If you counted the number of sentences in this book that you have seen or heard before, the number would be small. Next time you write an essay or a letter, see how many of your sentences are new. Few sentences are stored in your brain, to be pulled out to fit some situation or matched with some sentence that you hear. Novel sentences never spoken or heard before cannot be stored in your memory. In this unit you are going to: 1. Add your knowledge about linguistics which begins with introduction consisting Morphosyntax that is a combination between Morphology and Syntax. The exercises will show your comprehending the Morphosyntax. 2. Differentiate between content words and function words. 3. Differentiate between bound and free morpheme and finally you are able to do exercises on Identifying Morphemes. 1.2 English Morpho - Syntax Unit 1 Morphosyntax DEFINITIONS Language is a tool used by people for communication and a formal symbolic system. The art of conceptualizing and describing a language involves analyzing its formal systematic properties and interpreting the language as a communicative character. -

Lexical and Semantic Field As Reflection of Interpenetration and Interaction of Different Types of Common Polynational Language
Advances in Social Science, Education and Humanities Research (ASSEHR), volume 97 Proceedings of the 7th International Scientific and Practical Conference Current Issues of Linguistics and Didactics: The Interdisciplinary Approach in Humanities (CILDIAH 2017) Lexical and semantic field as reflection of interpenetration and interaction of different types of common polynational language Yu.S. Dzyubenko Department of Germanic and Romance Philology Volgograd State University Volgograd, Russia [email protected] Abstract—The article is devoted to the study of the lexical and are combined according to the topic. L.G. Vedenina explains semantic field as a microsystem of multiple lexical units united by the term ‘field’ as a generalization that structures linguistic common meaning of the word ‘education’ and reflecting the and cultural competence in a specific area of the society. In given conceptual field in the language. Aggregation of the LSF, lexical units are united by a common content and reflect linguistic units by their semantic content is the base of field the conceptual and functional similarity of the indicated lexical and semantic modeling. The concept of the field makes it phenomena. The lexical and semantic field is singled out by possible to describe the microstructural interactions of the one common seme (it includes the words of one part of linguistic units. The units of the same language field reflect the speech); the lexical and semantic group is singled out by objective, conceptual or functional similarities of the phenomena several common semes. [8]. When LSF is singled out ‘two being described; therefore, the field model represents a words are considered to be semantically related to each other dialectical connection between linguistic phenomena and the extralinguistic world. -

Morphology Ppt.Pdf
6/14/20 Morphology: An Exploration of Bases & Affixes to Build Spelling, Vocabulary, & Comprehension William Van Cleave Mid-Ohio ESC • June 18 & 19, 2020 facebook: W.V.C.ED • website: wvced.com [email protected] 1 Framing Our Discussion 2 1 6/14/20 What the Research Says Morphological awareness is a strong predictor of… • reading ability. • vocabulary knowledge. • comprehension. (Anglin et al, 1993; Carlisle, 2000; Berninger, Abbot, Nagy, & Carslisle, 2010; Carlisle &. Feldman, 1995; Kirby et al., 2012; Nagy & Anderson, 1984; Nagy et al., 2006 as cited in McKeown et al, 2017). 3 What the Research Says Knowledge of morphology is useful for academic vocabulary development, both for comprehension and writing. This means it affects Tier Two vocabulary development. One in three words you see for the first time is linked morphologically to something you already know, but that doesn’t mean you’ll know the word itself (Anglin et al (1993) as cited in McKeown et al (2017), 130). You need morphological awareness—or the ability relate an unfamiliar word to other, known words that share morphemes with it (70). 4 2 6/14/20 What the Research Says We should develop morphological knowledge… ! to build word sense. ! to build literacy skills, including vocabulary and reading comprehension. ! to build knowledge in content. ! to build polysemy, or an understanding of multiple meanings, through the study of word families (60). 5 What the Research Says A meta-analysis conducted by Bowers et al (2010) of 22 morphology studies found that morphology instruction benefits learners, especially less proficient readers. Students have difficulty with transfer. -

10. Semic Analysis Summary
Louis Hébert, Tools for Text and Image Analysis: An Introduction to Applied Semiotics 10. SEMIC ANALYSIS SUMMARY Semic analysis was developed within the field of semantics (the study of meaning in linguistic units). This chapter presents Rastier's interpretive semantics, and semic analysis as formulated therein. Semic analysis is performed on a semiotic act – a text, for example – by identifying the semes, that is, the elements of meaning (parts of the signified), defining clusters of semes (isotopies and molecules) and determining the relations between the clusters (relations of presupposition, comparison, etc., between the isotopies). The repetition of a seme creates an isotopy. For example, in "There was a fine ship, carved from solid gold / With azure reaching masts, on seas unknown" (Émile Nelligan, "The Golden Ship"), the words "ship", "masts" and "seas" all contain the seme /navigation/ (as well as others). The repetition of this seme creates the isotopy /navigation/. A semic molecule is a cluster of at least two semes appearing together more than once in a single semantic unit (a single word, for instance). For instance, in the poem just quoted, there is a semic molecule formed by the semes /precious/ + /dispersion/. It appears in the "streaming hair" ("cheveux épars") of the beautiful Goddess of Love (Venus) who was "spread-eagled" ("s'étalait") at the ship's prow, and also in the sinking of the ship's treasure, which the sailors "disputed amongst themselves" ("entre eux ont disputés"). 1. THEORY Semic analysis is performed on a semiotic act – such as a text – by identifying the semes (the elements of meaning), finding clusters of semes (isotopies and molecules) and determining the relations between the clusters (relations of presupposition, comparison, etc., between the isotopies).