Parse Tree Fragmentation of Ungrammatical Sentences
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-
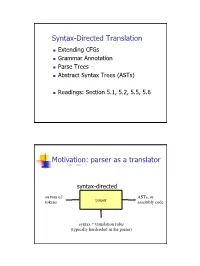
Syntax-Directed Translation, Parse Trees, Abstract Syntax Trees
Syntax-Directed Translation Extending CFGs Grammar Annotation Parse Trees Abstract Syntax Trees (ASTs) Readings: Section 5.1, 5.2, 5.5, 5.6 Motivation: parser as a translator syntax-directed translation stream of ASTs, or tokens parser assembly code syntax + translation rules (typically hardcoded in the parser) 1 Mechanism of syntax-directed translation syntax-directed translation is done by extending the CFG a translation rule is defined for each production given X Æ d A B c the translation of X is defined in terms of translation of nonterminals A, B values of attributes of terminals d, c constants To translate an input string: 1. Build the parse tree. 2. Working bottom-up • Use the translation rules to compute the translation of each nonterminal in the tree Result: the translation of the string is the translation of the parse tree's root nonterminal Why bottom up? a nonterminal's value may depend on the value of the symbols on the right-hand side, so translate a non-terminal node only after children translations are available 2 Example 1: arith expr to its value Syntax-directed translation: the CFG translation rules E Æ E + T E1.trans = E2.trans + T.trans E Æ T E.trans = T.trans T Æ T * F T1.trans = T2.trans * F.trans T Æ F T.trans = F.trans F Æ int F.trans = int.value F Æ ( E ) F.trans = E.trans Example 1 (cont) E (18) Input: 2 * (4 + 5) T (18) T (2) * F (9) F (2) ( E (9) ) int (2) E (4) * T (5) Annotated Parse Tree T (4) F (5) F (4) int (5) int (4) 3 Example 2: Compute type of expr E -> E + E if ((E2.trans == INT) and (E3.trans == INT) then E1.trans = INT else E1.trans = ERROR E -> E and E if ((E2.trans == BOOL) and (E3.trans == BOOL) then E1.trans = BOOL else E1.trans = ERROR E -> E == E if ((E2.trans == E3.trans) and (E2.trans != ERROR)) then E1.trans = BOOL else E1.trans = ERROR E -> true E.trans = BOOL E -> false E.trans = BOOL E -> int E.trans = INT E -> ( E ) E1.trans = E2.trans Example 2 (cont) Input: (2 + 2) == 4 1. -

Derivatives of Parsing Expression Grammars
Derivatives of Parsing Expression Grammars Aaron Moss Cheriton School of Computer Science University of Waterloo Waterloo, Ontario, Canada [email protected] This paper introduces a new derivative parsing algorithm for recognition of parsing expression gram- mars. Derivative parsing is shown to have a polynomial worst-case time bound, an improvement on the exponential bound of the recursive descent algorithm. This work also introduces asymptotic analysis based on inputs with a constant bound on both grammar nesting depth and number of back- tracking choices; derivative and recursive descent parsing are shown to run in linear time and constant space on this useful class of inputs, with both the theoretical bounds and the reasonability of the in- put class validated empirically. This common-case constant memory usage of derivative parsing is an improvement on the linear space required by the packrat algorithm. 1 Introduction Parsing expression grammars (PEGs) are a parsing formalism introduced by Ford [6]. Any LR(k) lan- guage can be represented as a PEG [7], but there are some non-context-free languages that may also be represented as PEGs (e.g. anbncn [7]). Unlike context-free grammars (CFGs), PEGs are unambiguous, admitting no more than one parse tree for any grammar and input. PEGs are a formalization of recursive descent parsers allowing limited backtracking and infinite lookahead; a string in the language of a PEG can be recognized in exponential time and linear space using a recursive descent algorithm, or linear time and space using the memoized packrat algorithm [6]. PEGs are formally defined and these algo- rithms outlined in Section 3. -

Parsing 1. Grammars and Parsing 2. Top-Down and Bottom-Up Parsing 3
Syntax Parsing syntax: from the Greek syntaxis, meaning “setting out together or arrangement.” 1. Grammars and parsing Refers to the way words are arranged together. 2. Top-down and bottom-up parsing Why worry about syntax? 3. Chart parsers • The boy ate the frog. 4. Bottom-up chart parsing • The frog was eaten by the boy. 5. The Earley Algorithm • The frog that the boy ate died. • The boy whom the frog was eaten by died. Slide CS474–1 Slide CS474–2 Grammars and Parsing Need a grammar: a formal specification of the structures allowable in Syntactic Analysis the language. Key ideas: Need a parser: algorithm for assigning syntactic structure to an input • constituency: groups of words may behave as a single unit or phrase sentence. • grammatical relations: refer to the subject, object, indirect Sentence Parse Tree object, etc. Beavis ate the cat. S • subcategorization and dependencies: refer to certain kinds of relations between words and phrases, e.g. want can be followed by an NP VP infinitive, but find and work cannot. NAME V NP All can be modeled by various kinds of grammars that are based on ART N context-free grammars. Beavis ate the cat Slide CS474–3 Slide CS474–4 CFG example CFG’s are also called phrase-structure grammars. CFG’s Equivalent to Backus-Naur Form (BNF). A context free grammar consists of: 1. S → NP VP 5. NAME → Beavis 1. a set of non-terminal symbols N 2. VP → V NP 6. V → ate 2. a set of terminal symbols Σ (disjoint from N) 3. -

Abstract Syntax Trees & Top-Down Parsing
Abstract Syntax Trees & Top-Down Parsing Review of Parsing • Given a language L(G), a parser consumes a sequence of tokens s and produces a parse tree • Issues: – How do we recognize that s ∈ L(G) ? – A parse tree of s describes how s ∈ L(G) – Ambiguity: more than one parse tree (possible interpretation) for some string s – Error: no parse tree for some string s – How do we construct the parse tree? Compiler Design 1 (2011) 2 Abstract Syntax Trees • So far, a parser traces the derivation of a sequence of tokens • The rest of the compiler needs a structural representation of the program • Abstract syntax trees – Like parse trees but ignore some details – Abbreviated as AST Compiler Design 1 (2011) 3 Abstract Syntax Trees (Cont.) • Consider the grammar E → int | ( E ) | E + E • And the string 5 + (2 + 3) • After lexical analysis (a list of tokens) int5 ‘+’ ‘(‘ int2 ‘+’ int3 ‘)’ • During parsing we build a parse tree … Compiler Design 1 (2011) 4 Example of Parse Tree E • Traces the operation of the parser E + E • Captures the nesting structure • But too much info int5 ( E ) – Parentheses – Single-successor nodes + E E int 2 int3 Compiler Design 1 (2011) 5 Example of Abstract Syntax Tree PLUS PLUS 5 2 3 • Also captures the nesting structure • But abstracts from the concrete syntax a more compact and easier to use • An important data structure in a compiler Compiler Design 1 (2011) 6 Semantic Actions • This is what we’ll use to construct ASTs • Each grammar symbol may have attributes – An attribute is a property of a programming language construct -

Compiler Construction
UNIVERSITY OF CAMBRIDGE Compiler Construction An 18-lecture course Alan Mycroft Computer Laboratory, Cambridge University http://www.cl.cam.ac.uk/users/am/ Lent Term 2007 Compiler Construction 1 Lent Term 2007 Course Plan UNIVERSITY OF CAMBRIDGE Part A : intro/background Part B : a simple compiler for a simple language Part C : implementing harder things Compiler Construction 2 Lent Term 2007 A compiler UNIVERSITY OF CAMBRIDGE A compiler is a program which translates the source form of a program into a semantically equivalent target form. • Traditionally this was machine code or relocatable binary form, but nowadays the target form may be a virtual machine (e.g. JVM) or indeed another language such as C. • Can appear a very hard program to write. • How can one even start? • It’s just like juggling too many balls (picking instructions while determining whether this ‘+’ is part of ‘++’ or whether its right operand is just a variable or an expression ...). Compiler Construction 3 Lent Term 2007 How to even start? UNIVERSITY OF CAMBRIDGE “When finding it hard to juggle 4 balls at once, juggle them each in turn instead ...” character -token -parse -intermediate -target stream stream tree code code syn trans cg lex A multi-pass compiler does one ‘simple’ thing at once and passes its output to the next stage. These are pretty standard stages, and indeed language and (e.g. JVM) system design has co-evolved around them. Compiler Construction 4 Lent Term 2007 Compilers can be big and hard to understand UNIVERSITY OF CAMBRIDGE Compilers can be very large. In 2004 the Gnu Compiler Collection (GCC) was noted to “[consist] of about 2.1 million lines of code and has been in development for over 15 years”. -

Advanced Parsing Techniques
Advanced Parsing Techniques Announcements ● Written Set 1 graded. ● Hard copies available for pickup right now. ● Electronic submissions: feedback returned later today. Where We Are Where We Are Parsing so Far ● We've explored five deterministic parsing algorithms: ● LL(1) ● LR(0) ● SLR(1) ● LALR(1) ● LR(1) ● These algorithms all have their limitations. ● Can we parse arbitrary context-free grammars? Why Parse Arbitrary Grammars? ● They're easier to write. ● Can leave operator precedence and associativity out of the grammar. ● No worries about shift/reduce or FIRST/FOLLOW conflicts. ● If ambiguous, can filter out invalid trees at the end. ● Generate candidate parse trees, then eliminate them when not needed. ● Practical concern for some languages. ● We need to have C and C++ compilers! Questions for Today ● How do you go about parsing ambiguous grammars efficiently? ● How do you produce all possible parse trees? ● What else can we do with a general parser? The Earley Parser Motivation: The Limits of LR ● LR parsers use shift and reduce actions to reduce the input to the start symbol. ● LR parsers cannot deterministically handle shift/reduce or reduce/reduce conflicts. ● However, they can nondeterministically handle these conflicts by guessing which option to choose. ● What if we try all options and see if any of them work? The Earley Parser ● Maintain a collection of Earley items, which are LR(0) items annotated with a start position. ● The item A → α·ω @n means we are working on recognizing A → αω, have seen α, and the start position of the item was the nth token. ● Using techniques similar to LR parsing, try to scan across the input creating these items. -

Lecture 3: Recursive Descent Limitations, Precedence Climbing
Lecture 3: Recursive descent limitations, precedence climbing David Hovemeyer September 9, 2020 601.428/628 Compilers and Interpreters Today I Limitations of recursive descent I Precedence climbing I Abstract syntax trees I Supporting parenthesized expressions Before we begin... Assume a context-free struct Node *Parser::parse_A() { grammar has the struct Node *next_tok = lexer_peek(m_lexer); following productions on if (!next_tok) { the nonterminal A: error("Unexpected end of input"); } A → b C A → d E struct Node *a = node_build0(NODE_A); int tag = node_get_tag(next_tok); (A, C, E are if (tag == TOK_b) { nonterminals; b, d are node_add_kid(a, expect(TOK_b)); node_add_kid(a, parse_C()); terminals) } else if (tag == TOK_d) { What is the problem node_add_kid(a, expect(TOK_d)); node_add_kid(a, parse_E()); with the parse function } shown on the right? return a; } Limitations of recursive descent Recall: a better infix expression grammar Grammar (start symbol is A): A → i = A T → T*F A → E T → T/F E → E + T T → F E → E-T F → i E → T F → n Precedence levels: Nonterminal Precedence Meaning Operators Associativity A lowest Assignment = right E Expression + - left T Term * / left F highest Factor No Parsing infix expressions Can we write a recursive descent parser for infix expressions using this grammar? Parsing infix expressions Can we write a recursive descent parser for infix expressions using this grammar? No Left recursion Left-associative operators want to have left-recursive productions, but recursive descent parsers can’t handle left recursion -
Top-Down Parsing & Bottom-Up Parsing I
Top-Down Parsing and Introduction to Bottom-Up Parsing Lecture 7 Instructor: Fredrik Kjolstad Slide design by Prof. Alex Aiken, with modifications 1 Predictive Parsers • Like recursive-descent but parser can “predict” which production to use – By looking at the next few tokens – No backtracking • Predictive parsers accept LL(k) grammars – L means “left-to-right” scan of input – L means “leftmost derivation” – k means “predict based on k tokens of lookahead” – In practice, LL(1) is used 2 LL(1) vs. Recursive Descent • In recursive-descent, – At each step, many choices of production to use – Backtracking used to undo bad choices • In LL(1), – At each step, only one choice of production – That is • When a non-terminal A is leftmost in a derivation • And the next input symbol is t • There is a unique production A ® a to use – Or no production to use (an error state) • LL(1) is a recursive descent variant without backtracking 3 Predictive Parsing and Left Factoring • Recall the grammar E ® T + E | T T ® int | int * T | ( E ) • Hard to predict because – For T two productions start with int – For E it is not clear how to predict • We need to left-factor the grammar 4 Left-Factoring Example • Recall the grammar E ® T + E | T T ® int | int * T | ( E ) • Factor out common prefixes of productions E ® T X X ® + E | e T ® int Y | ( E ) Y ® * T | e 5 LL(1) Parsing Table Example • Left-factored grammar E ® T X X ® + E | e T ® ( E ) | int Y Y ® * T | e • The LL(1) parsing table: next input token int * + ( ) $ E T X T X X + E e e T int Y ( E ) Y * T e e e rhs of production to use 6 leftmost non-terminal E ® T X X ® + E | e T ® ( E ) | int Y Y ® * T | e LL(1) Parsing Table Example • Consider the [E, int] entry – “When current non-terminal is E and next input is int, use production E ® T X” – This can generate an int in the first position int * + ( ) $ E T X T X X + E e e T int Y ( E ) Y * T e e e 7 E ® T X X ® + E | e T ® ( E ) | int Y Y ® * T | e LL(1) Parsing Tables. -

Parse Trees (=Derivation Tree) by Constructing a Derivation
CFG: Parsing •Generative aspect of CFG: By now it should be clear how, from a CFG G, you can derive strings wÎL(G). CFG: Parsing •Analytical aspect: Given a CFG G and strings w, how do you decide if wÎL(G) and –if so– how do you determine the derivation tree or the sequence of production rules Recognition of strings in a that produce w? This is called the problem of parsing. language 1 2 CFG: Parsing CFG: Parsing • Parser A program that determines if a string w Î L(G) Parse trees (=Derivation Tree) by constructing a derivation. Equivalently, A parse tree is a graphical representation it searches the graph of G. of a derivation sequence of a sentential form. – Top-down parsers • Constructs the derivation tree from root to leaves. • Leftmost derivation. Tree nodes represent symbols of the – Bottom-up parsers grammar (nonterminals or terminals) and • Constructs the derivation tree from leaves to tree edges represent derivation steps. root. • Rightmost derivation in reverse. 3 4 CFG: Parsing CFG: Parsing Parse Tree: Example Parse Tree: Example 1 E ® E + E | E * E | ( E ) | - E | id Given the following grammar: Lets examine this derivation: E Þ -E Þ -(E) Þ -(E + E) Þ -(id + id) E ® E + E | E * E | ( E ) | - E | id E E E E E Is the string -(id + id) a sentence in this grammar? - E - E - E - E Yes because there is the following derivation: ( E ) ( E ) ( E ) E Þ -E Þ -(E) Þ -(E + E) Þ -(id + id) E + E E + E This is a top-down derivation because we start building the id id parse tree at the top parse tree 5 6 1 CFG: Parsing CFG: Parsing S ® SS | a | b Parse Tree: Example 2 Rightmost Parse Tree: Example 2 abÎ L( S) derivation S Þ SS Þ Sb Þ ab S S S S S S S S Derivation S S S S Derivation S S S S Trees S S Trees a a b S S b a b S S S Leftmost S derivation S Þ SS Þ aS Þ ab Rightmost Derivation a b S S in Reverse 7 8 CFG: Parsing CFG: Parsing Practical Parsers Example 3 Consider the CFG grammar G • Language/Grammar designed to enable deterministic (directed S ® A and backtrack-free) searches. -

Technical Correspondence Techniques for Automatic Memoization with Applications to Context-Free Parsing
Technical Correspondence Techniques for Automatic Memoization with Applications to Context-Free Parsing Peter Norvig* University of California It is shown that a process similar to Earley's algorithm can be generated by a simple top-down backtracking parser, when augmented by automatic memoization. The memoized parser has the same complexity as Earley's algorithm, but parses constituents in a different order. Techniques for deriving memo functions are described, with a complete implementation in Common Lisp, and an outline of a macro-based approach for other languages. 1. Memoization The term memoization was coined by Donald Michie (1968) to refer to the process by which a function is made to automatically remember the results of previous compu- tations. The idea has become more popular in recent years with the rise of functional languages; Field and Harrison (1988) devote a whole chapter to it. The basic idea is just to keep a table of previously computed input/result pairs. In Common Lisp one could write: 1 (defun memo (fn) "Return a memo-function of fn." (let ((table (make-hash-table))) #'(lambda (x) (multiple-value-bind (val found) (gethash x table) (if found val (setf (gethash x table) (funcall fn x))))))). (For those familiar with Lisp but not Common Lisp, gethash returns two values, the stored entry in the table, and a boolean flag indicating if there is in fact an entry. The special form multiple-value-bind binds these two values to the symbols val and found. The special form serf is used here to update the table entry for x.) In this simple implementation fn is required to take one argument and return one value, and arguments that are eql produce the same value. -

Chart Parsing and Probabilistic Parsing
Chapter 8 Chart Parsing and Probabilistic Parsing 8.1 Introduction Chapter 7 started with an introduction to constituent structure in English, showing how words in a sentence group together in predictable ways. We showed how to describe this structure using syntactic tree diagrams, and observed that it is sometimes desirable to assign more than one such tree to a given string. In this case, we said that the string was structurally ambiguous; and example was old men and women. Treebanks are language resources in which the syntactic structure of a corpus of sentences has been annotated, usually by hand. However, we would also like to be able to produce trees algorithmically. A context-free phrase structure grammar (CFG) is a formal model for describing whether a given string can be assigned a particular constituent structure. Given a set of syntactic categories, the CFG uses a set of productions to say how a phrase of some category A can be analyzed into a sequence of smaller parts ±1 ... ±n. But a grammar is a static description of a set of strings; it does not tell us what sequence of steps we need to take to build a constituent structure for a string. For this, we need to use a parsing algorithm. We presented two such algorithms: Top-Down Recursive Descent (7.5.1) and Bottom-Up Shift-Reduce (7.5.2). As we pointed out, both parsing approaches suffer from important shortcomings. The Recursive Descent parser cannot handle left-recursive productions (e.g., productions such as NP → NP PP), and blindly expands categories top-down without checking whether they are compatible with the input string. -

Cs 473: Compiler Design
Lecture 3 CS 473: COMPILER DESIGN 1 creating an abstract representation of program syntax PARSING 2 Today: Parsing Source Code (Character stream) if (b == 0) { a = 1; } Lexical Analysis Token stream: if ( b == 0 ) { a = 0 ; } Parsing Abstract Syntax Tree: If Analysis & Eq Assn None Transformation b 0 a 1 Backend Assembly Code l1: cmpq %eax, $0 jeq l2 jmp l3 l2: … 3 Parsing: Finding Syntactic Structure { if (b == 0) a = b; while (a != 1) { print_int(a); a = a – 1; } Block } Source input If While Bop … … Bop Block Expr … b == 0 a != 1 Call Abstract Syntax tree … 4 Syntactic Analysis (Parsing): Overview • Input: stream of tokens (generated by lexer) • Output: abstract syntax tree • Strategy: – Parse the token stream to build a tree showing how the pieces relate – Forget the “concrete” syntax, remember the “abstract” syntax • Why abstract? Consider these three different concrete inputs: a + b (a + ((b))) Bop ((a) + (b)) Same abstract syntax tree a + b • Will catch lots of malformed programs! Wrong number of operators, missing semicolons, unmatched parens; most “syntax errors” appear here – But no type errors, initialization, etc.: we still don’t know what anything means! 5 Specifying Language Syntax • First question: how to describe language syntax precisely and conveniently? • Last time: we described tokens using regular expressions – Easy to implement, efficient DFA representation – Why not use regular expressions on tokens to specify programming language syntax? • Limits of regular expressions: – DFAs have only finite # of states – So DFAs can’t “count” – For example, consider the language of all strings that contain balanced parentheses – easier than most programming languages, but not regular.