Evaluating Software's Impact on System and System and System Of
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Environmental Systems Analysis Tools for Decision-Making
Environmental systems analysis tools for decision-making LCA and Swedish waste management as an example Åsa Moberg Licentiate thesis Royal Institute of Technology Department of Urban Planning and Environment Environmental Strategies Research Stockholm 2006 Titel: Environmental systems analysis tools for decision‐making LCA and Swedish waste management as an example Author: Åsa Moberg Cover page photo: Marianne Lockner TRITA‐SOM 06‐002 ISSN 1653‐6126 ISRN KTH/SOM/‐‐06/002‐‐SE ISBN 91‐7178‐304‐0 Printed in Sweden by US AB, Stockholm, 2006 2 Abstract Decisions are made based on information of different kinds. Several tools have been developed to facilitate the inclusion of environmental aspects in decision‐making on different levels. Which tool to use in a specific decision‐making situation depends on the decision context. This thesis discusses the choice between different environmental systems analysis (ESA) tools and suggests that key factors influencing the choice of ESA tool are object of study, impacts considered and information type regarding site‐specificity and according to the DPSIR‐framework. Waste management in Sweden is used as an example to illustrate decision‐making situations, but discussions concerning choice of tools are also thought to be of general concern. It is suggested that there is a need for a number of ESA tools in waste management decision‐making. Procedural tools like Environmental Impact Assessment (EIA) and Strategic Environmental Assessment (SEA) should be used e.g. by companies applying for development of waste management facilities and by public authorities preparing plans and programmes. Within these procedural tools analytical tools providing relevant information could be used, e.g. -

A Quantitative Reliability, Maintainability and Supportability Approach for NASA's Second Generation Reusable Launch Vehicle
A Quantitative Reliability, Maintainability and Supportability Approach for NASA's Second Generation Reusable Launch Vehicle Fayssai M. Safie, Ph. D. Marshall Space Flight Center Huntsville, Alabama Tel: 256-544-5278 E-mail: Fayssal.Safie @ msfc.nasa.gov Charles Daniel, Ph.D. Marshall Space Flight Center Huntsville, Alabama Tel: 256-544-5278 E-mail: Charles.Daniel @msfc.nasa.gov Prince Kalia Raytheon ITSS Marshall Space Flight Center Huntsville, Alabama Tel: 256-544-6871 E-mail: Prince.Kalia @ msfc.nasa.gov ABSTRACT The United States National Aeronautics and Space Administration (NASA) is in the midst of a 10-year Second Generation Reusable Launch Vehicle (RLV) program to improve its space transportation capabilities for both cargo and crewed missions. The objectives of the program are to: significantly increase safety and reliability, reduce the cost of accessing low-earth orbit, attempt to leverage commercial launch capabilities, and provide a growth path for manned space exploration. The safety, reliability and life cycle cost of the next generation vehicles are major concerns, and NASA aims to achieve orders of magnitude improvement in these areas. To get these significant improvements, requires a rigorous process that addresses Reliability, Maintainability and Supportability (RMS) and safety through all the phases of the life cycle of the program. This paper discusses the RMS process being implemented for the Second Generation RLV program. 1.0 INTRODUCTION The 2nd Generation RLV program has in place quantitative Level-I RMS, and cost requirements [Ref 1] as shown in Table 1, a paradigm shift from the Space Shuttle program. This paradigm shift is generating a change in how space flight system design is approached. -

CISM160 Systems Analysis and Design Course Syllabus
ATLANTIC CAPE COMMUNITY COLLEGE ISAS DEPARTMENT COURSE SYLLABUS COURSE TITLE: CISM160 Systems Analysis and Design Instructor: Dr. Otto Hernandez Office: A-142 Phone: 609-343-4978 eMail: [email protected] REQUIRED TEXTBOOK AND MATERIALS: Essentials of Systems Analysis and Design. Author: Valacich; Edition: 6th; ISBN: 9780133546231 COURSE DESCRIPTION: Investigation of information systems with respect to their existence and identification and development of needed informational improvements within an organization. Recommended methods and procedures considering computer involvement are reviewed, designed and implemented using the case-study approach PRE-REQUISITE: one of the following: CISM135, CISM154 or CISM174 ADA STATEMENT: As per the Americans with Disabilities Act (ADA), reasonable accommodations can be provided to students who present current documentation (within five years) of a disability to Atlantic Cape Community College’s Center for Accessibility, located on the first floor of “J” Building in the Counseling and Support Services department (Mays Landing campus). Reasonable accommodations cannot be provided for a course until the student registers with the Center for Accessibility. For more information, please contact the Center for Accessibility via email at [email protected] call 609-343- 5680. LEARNING GOALS & OBJECTIVES: A) Understanding the Systems Development Environment 1. Define information systems analysis and design. 2. Define and discuss the modern approach to systems analysis and design. 3. Illustrate how systems development extends to different types of information systems and not just transaction processing systems. 4. Introduce the traditional information systems development life cycle, which serves as the basis for the organization of the material in this book. 5. Show that the life cycle is a flexible basis for systems analysis and design and that it can support many different tools and techniques, such as prototyping and JAD. -

Systems Analysis – a New Paradigm and Decision Support Tools for the Water Framework Directive
Hydrol. Earth Syst. Sci., 12, 739–749, 2008 www.hydrol-earth-syst-sci.net/12/739/2008/ Hydrology and © Author(s) 2008. This work is distributed under Earth System the Creative Commons Attribution 3.0 License. Sciences Systems Analysis – a new paradigm and decision support tools for the water framework directive M. Bruen Centre for Water Resources Research, University College Dublin, Newstead, Belfield, Dublin 4, Ireland Received: 23 May 2007 – Published in Hydrol. Earth Syst. Sci. Discuss.: 12 June 2007 Revised: 3 March 2008 – Accepted: 7 April 2008 – Published: 15 May 2008 Abstract. In the early days of Systems Analysis the focus education and outreach influencing behaviour), economic in- was on providing tools for optimisation, modelling and sim- struments and legislation. Regardless of any scientific and ulation for use by experts. Now there is a recognition of the economic justification, it is unlikely that all proposed mea- need to develop and disseminate tools to assist in making de- sures or policies will be acceptable to all stakeholders so cisions, negotiating compromises and communicating pref- that considerable controversy and some planning and legal erences that can easily be used by stakeholders without the challenges can be expected. Consultation, negotiation, com- need for specialist training. The Water Framework Direc- promise and refinement of measures can be expected. Thus tive (WFD) requires public participation and thus provides it is imperative that all decisions on policy and measures a strong incentive for progress in this direction. This pa- be taken not only (i) on the basis of the best available sci- per places the new paradigm in the context of the classical entific and economic information but also (ii) be taken us- one and discusses some of the new approaches which can be ing an unbiased, independent and logical methodology and used in the implementation of the WFD. -

Chapter 9 – Designing the Database
Systems Analysis and Design in a Changing World, seventh edition 9-1 Chapter 9 – Designing the Database Table of Contents Chapter Overview Learning Objectives Notes on Opening Case and EOC Cases Instructor's Notes (for each section) ◦ Key Terms ◦ Lecture notes ◦ Quick quizzes Classroom Activities Troubleshooting Tips Discussion Questions Chapter Overview Database management systems provide designers, programmers, and end users with sophisticated capabilities to store, retrieve, and manage data. Sharing and managing the vast amounts of data needed by a modern organization would not be possible without a database management system. In Chapter 4, students learned to construct conceptual data models and to develop entity-relationship diagrams (ERDs) for traditional analysis and domain model class diagrams for object-oriented (OO) analysis. To implement an information system, developers must transform a conceptual data model into a more detailed database model and implement that model in a database management system. In the first sections of this chapter students learn about relational database management systems, and how to convert a data model into a relational database schema. The database sections conclude with a discussion of database architectural issues such as single server databases versus distributed databases which are deployed across multiple servers and multiple sites. Many system interfaces are electronic transmissions or paper outputs to external agents. Therefore, system developers need to design and implement integrity controls and security controls to protect the system and its data. This chapter discusses techniques to provide the integrity controls to reduce errors, fraud, and misuse of system components. The last section of the chapter discusses security controls and explains the basic concepts of data protection, digital certificates, and secure transactions. -
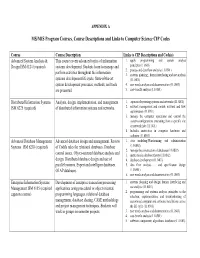
MS/MIS Program Courses, Course Descriptions and Links to Computer Science CIP Codes
APPENDIX A MS/MIS Program Courses, Course Descriptions and Links to Computer Science CIP Codes Course Course Description Links to CIP Descriptions and Code(s) Advanced System Analysis & This course covers advanced topics of information 1. apply programming and system analyst Design ISM 6124 (required) systems development. Students learn to manage and principles(11.0501) 2. process and data flow analysis.(11.0501) perform activities throughout the information 3. systems planning ; human interfacing and use analysis systems development life cycle. State‐of‐the‐art (11.0401) system development processes, methods, and tools 4. user needs analysis and documentation (11.0501) are presented 5. cost-benefit analysis (11.0501) Distributed Information Systems Analysis, design, implementation, and management 1. aspects of operating systems and networks (11.0201) ISM 6225 (required) of distributed information systems and networks. 2. network management and control; network and flow optimization (11.0901) 3. manage the computer operations and control the system configurations emanating from a specific site or network hub (11.1001) 4. Includes instruction in computer hardware and software (11.0501) Advanced Database Management Advanced database design and management. Review 1. data modeling/Warehousing and administration Systems ISM 6218 (required) of Codd's rules for relational databases. Database (11.0802) 2. manage the construction of databases (11.0802) control issues. Object‐oriented database analysis and 3. instruction in database theory (11.0802) design. Distributed database design and use of 4. database development (11.0401) parallel systems. Expert and intelligent databases. 5. data flow analysis … and specification design OLAP databases. (11.0501) 6. user needs analysis and documentation (11.0501) Enterprise Information Systems Development of enterprise transaction processing 1. -

A Systems Analysis and Design Model to Initiate Scheduling of Construction Activities in Renovation of a Major Building
Session 3642 A Systems Analysis and Design Model to Initiate Scheduling of Construction Activities in Renovation of a Major Building Dr. Bahador Ghahramani, P.E., CPE Engineering Management Department University of Missouri-Rolla, Rolla, MO 65409-0370 (USA) Tel: (573) 341-6057 Fax: (573) 341-6567 E-mail: [email protected] Abstract A Systems Analysis and Design (SA&D) model is presented in this paper that is important for engineering management (EMGT) educators to help their students to solve complex project management and scheduling problems. The SA&D model discussed here was developed to provide a scheduling process for a large construction project in a major city in the United States. The paper will attempt to answer such critical issues as sequencing, timeline analysis, seasonal factors, and lead/lag time of the project. A scheduling model that makes use of SA&D is described. The model was required to incorporate sequencing, timeline analysis, seasonal factors, and lead/log time for the project. Also, this paper discusses the relevance of the SA&D in the EMGT education, and how students will benefit from this model. 1. Introduction The primary goal of this paper is to educate engineering management (EMGT) educators in the basic understanding of the field of Systems Analysis and Design (SA&D), its application and how it can be used to solve practical technical problems. The paper also helps our educators better understand how their students can use SA&D to solve scheduling problems of a major theatre construction project. The project’s initial goal was to renovate a major building in a major United States city. -

Basic Structural Modeling Project Project
BASIC STRUCTURAL MODELING PROJECT Joseph J. Simpson 11-04-2013 PROJECT DESCRIPTION DOCUMENT Version 0.61 Table of Contents Introduction Purpose Project Context Basic Structural Modeling Publications Basic Structural Modeling Elements Project Artifacts Basic Structural Modeling Executable Code Basic Structural Model Project Schedule Basic Structural Model Project Organization Appendix A – SAGE Support for BSM Functions Appendix B – NOTES Introduction The Basic Structural Modeling (BSM) Project (BSMP) is focused on clearly defining the elements of BSM, and creating a well-documented set of computer executable code that demonstrates each element of the code base. Each BSM element will have a text description, an outline of typical application, executable code functions, and standard test packages. BSM is one component of Structural Modeling developed by John N. Warfield and reported in a number of publications, including Societal Systems: Planning, Policy and Complexity, 1976. Structural Modeling has two components: BSM and Interpretive Structural Modeling (ISM). Within this project, ISM will only be considered when the BSM elements are used to support ISM activities. Purpose The primary purpose of the BSMP is the creation of an open-source set of computer code that is available to support the implementation of ISM methods. A distinct boundary between BSM and ISM is developed to support awareness of these two different structural modeling activities. Well-defined packages of verified code – produced by this project – can be used in a number of system structural analysis activities, including ISM activities. The distinct boundary between BSM and ISM methods and procedures is established based on the content of the book Societal Systems: Planning, Policy and Complexity. -

Chapter 10 – Approaches to System Development
Systems Analysis and Design in a Changing World, seventh edition 10-1 Chapter 10 – Approaches to System Development Table of Contents Chapter Overview Learning Objectives Notes on Opening Case and EOC Cases Instructor's Notes (for each section) ◦ Key Terms ◦ Lecture notes ◦ Quick quizzes Classroom Activities Troubleshooting Tips Discussion Questions Chapter Overview The chapter first presents and explains the differences in the life cycle approach—the predictive and the adaptive approaches. These two approaches are really a continuum and any give project may have elements of both approaches. The predictive approach to the SDLC is used for projects that are well understood and low risk. The adaptive approach to the SDLC is used for projects that are not well understood and are higher risk. Adaptive SDLCs are more iterative and allow the project team to adapt the project to changing circumstances. The chapter includes a discussion of the Agile philosophy and Agile modeling principles. Students should understand that Agile philosophy recognizes that most users do not understand the complexities of business processes and supporting software and therefore most projects must be flexible and agile. Agile modeling has basic principles to encourage developers to use modeling as a means to the end product (working software), and not an end in and of itself. Finally the chapter concludes with a discussion of three methodologies that embrace the Agile philosophy – Unified Process (UP), Extreme Programming (XP), and Scrum. Learning Objectives After reading this chapter, the student should be able to: • Compare the underlying assumptions and uses of a predictive and an adaptive system development life cycle (SDLC) • Explain what makes up a system development methodology—the SDLC as well as models, ©2016. -

Chapter 1 - from Beginning to End: an Overview of Systems Analysis and Design
Systems Analysis and Design in a Changing World, seventh edition 1-1 Chapter 1 - From Beginning to End: An Overview of Systems Analysis and Design IM Table of Contents Chapter Overview Learning Objectives Instructor's Notes (for each section) ◦ Key Terms ◦ Lecture notes ◦ Quick quizzes Classroom Activities Troubleshooting Tips Discussion Questions Chapter Overview This edition, the seventh, continues with the approach we began in the last edition to provide a much more example based learning opportunity. As such the entire first chapter is an example of a complete development project from beginning to end. Obviously, in a single chapter example, not every step is elaborated. However, by going through the entire process, students will be able to obtain a broad overview and a clear perspective of the entire development process. The chapter first introduces several basic concepts that are needed to understand systems development. The first few sections define Systems Analysis, Systems Design, the Systems Development Life Cycle (SDLC), iterative development, Agile development and the six core processes of systems development. The remainder of the chapter illustrates the first iteration of a typical development project for the Ridgeline Mountain Outfitters (RMO) Tradeshow system. It divides the project into seven steps, including pre-project activities and then six other development steps. For simplicity purposes, each step is assigned a day, so the project has Day 1 activities, Day 2 activities, etc. Throughout this set of daily activities, all six core processes are explained and illustrated. Sample models and diagrams are presented to give the students an introduction to some of the major techniques and models that will be taught later in the text. -

Systems Analysis and Design Project Management
Systems Analysis and Design Project Management Alan Dennis, Barbara Haley Wixom, and Roberta Roth Chapter 3 John Wiley & Sons, Inc. Slides by Candace S. Garrod Red Rocks Community College PowerPoint Presentation for Dennis, W ixom, & Roth Systems Analysis and Design, 3rd Edition PowerPoint Presentation for Dennis, W ixom, & Roth Systems Analysis and Design, 3rd Edition 3 - 1 Copyright 2006 © John W iley & Sons, Inc. All rights reserved. 3 - 2 Copyright 2006 © John W iley & Sons, Inc. All rights reserved. Four Key Steps in Managing Key Definitions Projects Project management is the process of Identifying project size planning and controlling the development of a system within a Creating and managing the specified timeframe at a minimum cost workplan with the right functionality. Staffing the project A project manager has the primary responsibility for managing the hundreds Coordinating project activities of tasks and roles that need to be carefully coordinated. PowerPoint Presentation for Dennis, W ixom, & Roth Systems Analysis and Design, 3rd Edition PowerPoint Presentation for Dennis, W ixom, & Roth Systems Analysis and Design, 3rd Edition 3 - 3 Copyright 2006 © John W iley & Sons, Inc. All rights reserved. 3 - 4 Copyright 2006 © John W iley & Sons, Inc. All rights reserved. Project Manager’s Balancing Act Project Management involves IDENTIFYING PROJECT SIZE making trade-offs… Project Size P r o j e c t e C m o i s T t t c je ro Modifying one element P requires adjusting the others PowerPoint Presentation for Dennis, W ixom, & Roth Systems Analysis and Design, 3rd Edition PowerPoint Presentation for Dennis, W ixom, & Roth Systems Analysis and Design, 3rd Edition 3 - 5 Copyright 2006 © John W iley & Sons, Inc. -

Enterprise Architecture for Information System Analysis
Enterprise Architecture for Information System Analysis Modeling and assessing data accuracy, availability, performance and application usage PER NÄRMAN Doctoral Thesis Stockholm, Sweden 2012 TRITA-EE 2012:035 Industrial Information and Control Systems ISSN 1653-5146 KTH, Royal Institute of Technology ISRN KTH/ICS/R--12/01--SE Stockholm, Sweden Submitted in partial fulfillment of the requirements for the degree of Doctor of Philosophy © Per Närman, September 2012, Copyrighted articles are reprinted with kind permission from El- sevier and Taylor & Francis. Universitetsservice US AB Abstract Decisions concerning IT systems are often made without adequate decision-support. This has led to unnecessary IT costs and failures to realize business benefits. The present thesis presents a framework for analysis of four information systems properties relevant to IT decision-making. The work is founded on enterprise architecture, a model-based IT and business management discipline. Based on the existing ArchiMate framework, a new enterprise architecture framework has been developed and implemented in a software tool. The framework supports modeling and analysis of data accuracy, service performance, service availability and application usage. To analyze data accuracy, data flows are modeled, the service availability analysis uses fault tree analysis, the performance analysis employs queuing networks and the application usage analysis combines the Technology Acceptance Model and Task-Technology Fit model. The accuracy of the framework’s estimates was empirically tested. Data accuracy and service performance were evaluated in studies at the same power utility. Service availability was tested in multiple studies at banks and power utilities. Data was collected through interviews with system development or maintenance staff.