A Performance & Power Comparison of Modern High-Speed DRAM
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

MEGHARAJ-THESIS-2017.Pdf (1.176Mb)
INTGRATING PROCESSING IN-MEMORY (PIM) TECHNOLOGY INTO GENERAL PURPOSE GRAPHICS PROCESSING UNITS (GPGPU) FOR ENERGY EFFICIENT COMPUTING A Thesis Presented to the Faculty of the Department of Electrical Engineering University of Houston In Partial Fulfillment of the Requirements for the Degree Master of Science in Electrical Engineering by Paraag Ashok Kumar Megharaj August 2017 INTGRATING PROCESSING IN-MEMORY (PIM) TECHNOLOGY INTO GENERAL PURPOSE GRAPHICS PROCESSING UNITS (GPGPU) FOR ENERGY EFFICIENT COMPUTING ________________________________________________ Paraag Ashok Kumar Megharaj Approved: ______________________________ Chair of the Committee Dr. Xin Fu, Assistant Professor, Electrical and Computer Engineering Committee Members: ____________________________ Dr. Jinghong Chen, Associate Professor, Electrical and Computer Engineering _____________________________ Dr. Xuqing Wu, Assistant Professor, Information and Logistics Technology ____________________________ ______________________________ Dr. Suresh K. Khator, Associate Dean, Dr. Badri Roysam, Professor and Cullen College of Engineering Chair of Dept. in Electrical and Computer Engineering Acknowledgements I would like to thank my advisor, Dr. Xin Fu, for providing me an opportunity to study under her guidance and encouragement through my graduate study at University of Houston. I would like to thank Dr. Jinghong Chen and Dr. Xuqing Wu for serving on my thesis committee. Besides, I want to thank my friend, Chenhao Xie, for helping me out and discussing in detail all the problems -
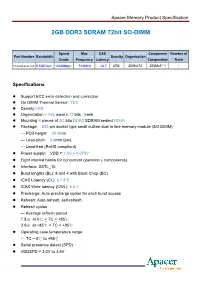
2GB DDR3 SDRAM 72Bit SO-DIMM
Apacer Memory Product Specification 2GB DDR3 SDRAM 72bit SO-DIMM Speed Max CAS Component Number of Part Number Bandwidth Density Organization Grade Frequency Latency Composition Rank 0C 78.A2GCB.AF10C 8.5GB/sec 1066Mbps 533MHz CL7 2GB 256Mx72 256Mx8 * 9 1 Specifications z Support ECC error detection and correction z On DIMM Thermal Sensor: YES z Density:2GB z Organization – 256 word x 72 bits, 1rank z Mounting 9 pieces of 2G bits DDR3 SDRAM sealed FBGA z Package: 204-pin socket type small outline dual in line memory module (SO-DIMM) --- PCB height: 30.0mm --- Lead pitch: 0.6mm (pin) --- Lead-free (RoHS compliant) z Power supply: VDD = 1.5V + 0.075V z Eight internal banks for concurrent operation ( components) z Interface: SSTL_15 z Burst lengths (BL): 8 and 4 with Burst Chop (BC) z /CAS Latency (CL): 6,7,8,9 z /CAS Write latency (CWL): 5,6,7 z Precharge: Auto precharge option for each burst access z Refresh: Auto-refresh, self-refresh z Refresh cycles --- Average refresh period 7.8㎲ at 0℃ < TC < +85℃ 3.9㎲ at +85℃ < TC < +95℃ z Operating case temperature range --- TC = 0℃ to +95℃ z Serial presence detect (SPD) z VDDSPD = 3.0V to 3.6V Apacer Memory Product Specification Features z Double-data-rate architecture; two data transfers per clock cycle. z The high-speed data transfer is realized by the 8 bits prefetch pipelined architecture. z Bi-directional differential data strobe (DQS and /DQS) is transmitted/received with data for capturing data at the receiver. z DQS is edge-aligned with data for READs; center aligned with data for WRITEs. -

Memory & Devices
Memory & Devices Memory • Random Access Memory (vs. Serial Access Memory) • Different flavors at different levels – Physical Makeup (CMOS, DRAM) – Low Level Architectures (FPM,EDO,BEDO,SDRAM, DDR) • Cache uses SRAM: Static Random Access Memory – No refresh (6 transistors/bit vs. 1 transistor • Main Memory is DRAM: Dynamic Random Access Memory – Dynamic since needs to be refreshed periodically (1% time) – Addresses divided into 2 halves (Memory as a 2D matrix): • RAS or Row Access Strobe • CAS or Column Access Strobe Random-Access Memory (RAM) Key features – RAM is packaged as a chip. – Basic storage unit is a cell (one bit per cell). – Multiple RAM chips form a memory. Static RAM (SRAM) – Each cell stores bit with a six-transistor circuit. – Retains value indefinitely, as long as it is kept powered. – Relatively insensitive to disturbances such as electrical noise. – Faster and more expensive than DRAM. Dynamic RAM (DRAM) – Each cell stores bit with a capacitor and transistor. – Value must be refreshed every 10-100 ms. – Sensitive to disturbances. – Slower and cheaper than SRAM. Semiconductor Memory Types Static RAM • Bits stored in transistor “latches” à no capacitors! – no charge leak, no refresh needed • Pro: no refresh circuits, faster • Con: more complex construction, larger per bit more expensive transistors “switch” faster than capacitors charge ! • Cache Static RAM Structure 1 “NOT ” 1 0 six transistors per bit 1 0 (“flip flop”) 0 1 0/1 = example 0 Static RAM Operation • Transistor arrangement (flip flop) has 2 stable logic states • Write 1. signal bit line: High à 1 Low à 0 2. address line active à “switch” flip flop to stable state matching bit line • Read no need 1. -

Performance Impact of Memory Channels on Sparse and Irregular Algorithms
Performance Impact of Memory Channels on Sparse and Irregular Algorithms Oded Green1,2, James Fox2, Jeffrey Young2, Jun Shirako2, and David Bader3 1NVIDIA Corporation — 2Georgia Institute of Technology — 3New Jersey Institute of Technology Abstract— Graph processing is typically considered to be a Graph algorithms are typically latency-bound if there is memory-bound rather than compute-bound problem. One com- not enough parallelism to saturate the memory subsystem. mon line of thought is that more available memory bandwidth However, the growth in parallelism for shared-memory corresponds to better graph processing performance. However, in this work we demonstrate that the key factor in the utilization systems brings into question whether graph algorithms are of the memory system for graph algorithms is not necessarily still primarily latency-bound. Getting peak or near-peak the raw bandwidth or even the latency of memory requests. bandwidth of current memory subsystems requires highly Instead, we show that performance is proportional to the parallel applications as well as good spatial and temporal number of memory channels available to handle small data memory reuse. The lack of spatial locality in sparse and transfers with limited spatial locality. Using several widely used graph frameworks, including irregular algorithms means that prefetched cache lines have Gunrock (on the GPU) and GAPBS & Ligra (for CPUs), poor data reuse and that the effective bandwidth is fairly low. we evaluate key graph analytics kernels using two unique The introduction of high-bandwidth memories like HBM and memory hierarchies, DDR-based and HBM/MCDRAM. Our HMC have not yet closed this inefficiency gap for latency- results show that the differences in the peak bandwidths sensitive accesses [19]. -

Different Types of RAM RAM RAM Stands for Random Access Memory. It Is Place Where Computer Stores Its Operating System. Applicat
Different types of RAM RAM RAM stands for Random Access Memory. It is place where computer stores its Operating System. Application Program and current data. when you refer to computer memory they mostly it mean RAM. The two main forms of modern RAM are Static RAM (SRAM) and Dynamic RAM (DRAM). DRAM memories (Dynamic Random Access Module), which are inexpensive . They are used essentially for the computer's main memory SRAM memories(Static Random Access Module), which are fast and costly. SRAM memories are used in particular for the processer's cache memory. Early memories existed in the form of chips called DIP (Dual Inline Package). Nowaday's memories generally exist in the form of modules, which are cards that can be plugged into connectors for this purpose. They are generally three types of RAM module they are 1. DIP 2. SIMM 3. DIMM 4. SDRAM 1. DIP(Dual In Line Package) Older computer systems used DIP memory directely, either soldering it to the motherboard or placing it in sockets that had been soldered to the motherboard. Most memory chips are packaged into small plastic or ceramic packages called dual inline packages or DIPs . A DIP is a rectangular package with rows of pins running along its two longer edges. These are the small black boxes you see on SIMMs, DIMMs or other larger packaging styles. However , this arrangment caused many problems. Chips inserted into sockets suffered reliability problems as the chips would (over time) tend to work their way out of the sockets. 2. SIMM A SIMM, or single in-line memory module, is a type of memory module containing random access memory used in computers from the early 1980s to the late 1990s . -

Product Guide SAMSUNG ELECTRONICS RESERVES the RIGHT to CHANGE PRODUCTS, INFORMATION and SPECIFICATIONS WITHOUT NOTICE
May. 2018 DDR4 SDRAM Memory Product Guide SAMSUNG ELECTRONICS RESERVES THE RIGHT TO CHANGE PRODUCTS, INFORMATION AND SPECIFICATIONS WITHOUT NOTICE. Products and specifications discussed herein are for reference purposes only. All information discussed herein is provided on an "AS IS" basis, without warranties of any kind. This document and all information discussed herein remain the sole and exclusive property of Samsung Electronics. No license of any patent, copyright, mask work, trademark or any other intellectual property right is granted by one party to the other party under this document, by implication, estoppel or other- wise. Samsung products are not intended for use in life support, critical care, medical, safety equipment, or similar applications where product failure could result in loss of life or personal or physical harm, or any military or defense application, or any governmental procurement to which special terms or provisions may apply. For updates or additional information about Samsung products, contact your nearest Samsung office. All brand names, trademarks and registered trademarks belong to their respective owners. © 2018 Samsung Electronics Co., Ltd. All rights reserved. - 1 - May. 2018 Product Guide DDR4 SDRAM Memory 1. DDR4 SDRAM MEMORY ORDERING INFORMATION 1 2 3 4 5 6 7 8 9 10 11 K 4 A X X X X X X X - X X X X SAMSUNG Memory Speed DRAM Temp & Power DRAM Type Package Type Density Revision Bit Organization Interface (VDD, VDDQ) # of Internal Banks 1. SAMSUNG Memory : K 8. Revision M: 1st Gen. A: 2nd Gen. 2. DRAM : 4 B: 3rd Gen. C: 4th Gen. D: 5th Gen. -

DDR and DDR2 SDRAM Controller Compiler User Guide
DDR and DDR2 SDRAM Controller Compiler User Guide 101 Innovation Drive Software Version: 9.0 San Jose, CA 95134 Document Date: March 2009 www.altera.com Copyright © 2009 Altera Corporation. All rights reserved. Altera, The Programmable Solutions Company, the stylized Altera logo, specific device designations, and all other words and logos that are identified as trademarks and/or service marks are, unless noted otherwise, the trademarks and service marks of Altera Corporation in the U.S. and other countries. All other product or service names are the property of their respective holders. Altera products are protected under numerous U.S. and foreign patents and pending ap- plications, maskwork rights, and copyrights. Altera warrants performance of its semiconductor products to current specifications in accordance with Altera's standard warranty, but reserves the right to make changes to any products and services at any time without notice. Altera assumes no responsibility or liability arising out of the application or use of any information, product, or service described herein except as expressly agreed to in writing by Altera Corporation. Altera customers are advised to obtain the latest version of device specifications before relying on any published information and before placing orders for products or services. UG-DDRSDRAM-10.0 Contents Chapter 1. About This Compiler Release Information . 1–1 Device Family Support . 1–1 Features . 1–2 General Description . 1–2 Performance and Resource Utilization . 1–4 Installation and Licensing . 1–5 OpenCore Plus Evaluation . 1–6 Chapter 2. Getting Started Design Flow . 2–1 SOPC Builder Design Flow . 2–1 DDR & DDR2 SDRAM Controller Walkthrough . -

AXP Internal 2-Apr-20 1
2-Apr-20 AXP Internal 1 2-Apr-20 AXP Internal 2 2-Apr-20 AXP Internal 3 2-Apr-20 AXP Internal 4 2-Apr-20 AXP Internal 5 2-Apr-20 AXP Internal 6 Class 6 Subject: Computer Science Title of the Book: IT Planet Petabyte Chapter 2: Computer Memory GENERAL INSTRUCTIONS: • Exercises to be written in the book. • Assignment questions to be done in ruled sheets. • You Tube link is for the explanation of Primary and Secondary Memory. YouTube Link: ➢ https://youtu.be/aOgvgHiazQA INTRODUCTION: ➢ Computer can store a large amount of data safely in their memory for future use. ➢ A computer’s memory is measured either in Bits or Bytes. ➢ The memory of a computer is divided into two categories: Primary Memory, Secondary Memory. ➢ There are two types of Primary Memory: ROM and RAM. ➢ Cache Memory is used to store program and instructions that are frequently used. EXPLANATION: Computer Memory: Memory plays a very important role in a computer. It is the basic unit where data and instructions are stored temporarily. Memory usually consists of one or more chips on the mother board, or you can say it consists of electronic components that store instructions waiting to be executed by the processor, data needed by those instructions, and the results of processing the data. Memory Units: Computer memory is measured in bits and bytes. A bit is the smallest unit of information that a computer can process and store. A group of 4 bits is known as nibble, and a group of 8 bits is called byte. -

Peering Over the Memory Wall: Design Space and Performance
Peering Over the Memory Wall: Design Space and Performance Analysis of the Hybrid Memory Cube UniversityDesign of Maryland Space andSystems Performance & Computer Architecture Analysis Group of Technical the Hybrid Report UMD-SCA-2012-10-01 Memory Cube Paul Rosenfeld*, Elliott Cooper-Balis*, Todd Farrell*, Dave Resnick°, and Bruce Jacob† *Micron, Inc. °Sandia National Labs †University of Maryland Abstract the hybrid memory cube which has the potential to address The Hybrid Memory Cube is an emerging main memory all three of these problems at the same time. The HMC tech- technology that leverages advances in 3D fabrication tech- nology leverages advances in fabrication technology to create niques to create a CMOS logic layer with DRAM dies stacked a 3D stack that contains a CMOS logic layer with several on top. The logic layer contains several DRAM memory con- DRAM dies stacked on top. The logic layer contains several trollers that receive requests from high speed serial links from memory controllers, a high speed serial link interface, and an the host processor. Each memory controller is connected to interconnect switch that connects the high speed links to the several memory banks in several DRAM dies with a vertical memory controllers. By stacking memory elements on top of through-silicon via (TSV). Since the TSVs form a dense in- controllers, the HMC can deliver data from memory banks to terconnect with short path lengths, the data bus between the controllers with much higher bandwidth and lower energy per controller and banks can be operated at higher throughput and bit than a traditional memory system. -

You Need to Know About Ddr4
Overcoming DDR Challenges in High-Performance Designs Mazyar Razzaz, Applications Engineering Jeff Steinheider, Product Marketing September 2018 | AMF-NET-T3267 Company Public – NXP, the NXP logo, and NXP secure connections for a smarter world are trademarks of NXP B.V. All other product or service names are the property of their respective owners. © 2018 NXP B.V. Agenda • Basic DDR SDRAM Structure • DDR3 vs. DDR4 SDRAM Differences • DDR Bring up Issues • Configurations and Validation via QCVS Tool COMPANY PUBLIC 1 BASIC DDR SDRAM STRUCTURE COMPANY PUBLIC 2 Single Transistor Memory Cell Access Transistor Column (bit) line Row (word) line G S D “1” => Vcc “0” => Gnd “precharged” to Vcc/2 Cbit Ccol Storage Parasitic Line Capacitor Vcc/2 Capacitance COMPANY PUBLIC 3 Memory Arrays B0 B1 B2 B3 B4 B5 B6 B7 ROW ADDRESS DECODER ADDRESS ROW W0 W1 W2 SENSE AMPS & WRITE DRIVERS COLUMN ADDRESS DECODER COMPANY PUBLIC 4 Internal Memory Banks • Multiple arrays organized into banks • Multiple banks per memory device − DDR3 – 8 banks, and 3 bank address (BA) bits − DDR4 – 16 banks with 4 banks in each of 4 sub bank groups − Can have one active row in each bank at any given time • Concurrency − Can be opening or closing a row in one bank while accessing another bank Bank 0 Bank 1 Bank 2 Bank 3 Row 0 Row 1 Row 2 Row 3 Row … Row Buffers COMPANY PUBLIC 5 Memory Access • A requested row is ACTIVATED and made accessible through the bank’s row buffers • READ and/or WRITE are issued to the active row in the row buffers • The row is PRECHARGED and is no longer -

Improving DRAM Performance by Parallelizing Refreshes
Improving DRAM Performance by Parallelizing Refreshes with Accesses Kevin Kai-Wei Chang Donghyuk Lee Zeshan Chishti† [email protected] [email protected] [email protected] Alaa R. Alameldeen† Chris Wilkerson† Yoongu Kim Onur Mutlu [email protected] [email protected] [email protected] [email protected] Carnegie Mellon University †Intel Labs Abstract Each DRAM cell must be refreshed periodically every re- fresh interval as specified by the DRAM standards [11, 14]. Modern DRAM cells are periodically refreshed to prevent The exact refresh interval time depends on the DRAM type data loss due to leakage. Commodity DDR (double data rate) (e.g., DDR or LPDDR) and the operating temperature. While DRAM refreshes cells at the rank level. This degrades perfor- DRAM is being refreshed, it becomes unavailable to serve mance significantly because it prevents an entire DRAM rank memory requests. As a result, refresh latency significantly de- from serving memory requests while being refreshed. DRAM de- grades system performance [24, 31, 33, 41] by delaying in- signed for mobile platforms, LPDDR (low power DDR) DRAM, flight memory requests. This problem will become more preva- supports an enhanced mode, called per-bank refresh, that re- lent as DRAM density increases, leading to more DRAM rows freshes cells at the bank level. This enables a bank to be ac- to be refreshed within the same refresh interval. DRAM chip cessed while another in the same rank is being refreshed, alle- density is expected to increase from 8Gb to 32Gb by 2020 as viating part of the negative performance impact of refreshes. -

Dual-DIMM DDR2 and DDR3 SDRAM Board Design Guidelines, External
5. Dual-DIMM DDR2 and DDR3 SDRAM Board Design Guidelines June 2012 EMI_DG_005-4.1 EMI_DG_005-4.1 This chapter describes guidelines for implementing dual unbuffered DIMM (UDIMM) DDR2 and DDR3 SDRAM interfaces. This chapter discusses the impact on signal integrity of the data signal with the following conditions in a dual-DIMM configuration: ■ Populating just one slot versus populating both slots ■ Populating slot 1 versus slot 2 when only one DIMM is used ■ On-die termination (ODT) setting of 75 Ω versus an ODT setting of 150 Ω f For detailed information about a single-DIMM DDR2 SDRAM interface, refer to the DDR2 and DDR3 SDRAM Board Design Guidelines chapter. DDR2 SDRAM This section describes guidelines for implementing a dual slot unbuffered DDR2 SDRAM interface, operating at up to 400-MHz and 800-Mbps data rates. Figure 5–1 shows a typical DQS, DQ, and DM signal topology for a dual-DIMM interface configuration using the ODT feature of the DDR2 SDRAM components. Figure 5–1. Dual-DIMM DDR2 SDRAM Interface Configuration (1) VTT Ω RT = 54 DDR2 SDRAM DIMMs (Receiver) Board Trace FPGA Slot 1 Slot 2 (Driver) Board Trace Board Trace Note to Figure 5–1: (1) The parallel termination resistor RT = 54 Ω to VTT at the FPGA end of the line is optional for devices that support dynamic on-chip termination (OCT). © 2012 Altera Corporation. All rights reserved. ALTERA, ARRIA, CYCLONE, HARDCOPY, MAX, MEGACORE, NIOS, QUARTUS and STRATIX words and logos are trademarks of Altera Corporation and registered in the U.S. Patent and Trademark Office and in other countries.