A Benchmark of Hemoglobin Blocking During Library Preparation for Mrna
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Diagnosis of Sickle Cell Disease and HBB Haplotyping in the Era of Personalized Medicine: Role of Next Generation Sequencing
Journal of Personalized Medicine Article Diagnosis of Sickle Cell Disease and HBB Haplotyping in the Era of Personalized Medicine: Role of Next Generation Sequencing Adekunle Adekile 1,*, Nagihan Akbulut-Jeradi 2, Rasha Al Khaldi 2, Maria Jinky Fernandez 2 and Jalaja Sukumaran 1 1 Department of Pediatrics, Faculty of Medicine, Kuwait University, P.O. Box 24923, Safat 13110, Kuwait; jalajasukumaran@hotmail 2 Advanced Technology Company, Hawali 32060, Kuwait; [email protected] (N.A.-J.); [email protected] (R.A.); [email protected] (M.J.F.) * Correspondence: [email protected]; Tel.: +965-253-194-86 Abstract: Hemoglobin genotype and HBB haplotype are established genetic factors that modify the clinical phenotype in sickle cell disease (SCD). Current methods of establishing these two factors are cumbersome and/or prone to errors. The throughput capability of next generation sequencing (NGS) makes it ideal for simultaneous interrogation of the many genes of interest in SCD. This study was designed to confirm the diagnosis in patients with HbSS and Sβ-thalassemia, identify any ß-thal mutations and simultaneously determine the ßS HBB haplotype. Illumina Ampliseq custom DNA panel was used to genotype the DNA samples. Haplotyping was based on the alleles on five haplotype-specific SNPs. The patients studied included 159 HbSS patients and 68 Sβ-thal patients, previously diagnosed using high performance liquid chromatography (HPLC). There was Citation: Adekile, A.; considerable discordance between HPLC and NGS results, giving a false +ve rate of 20.5% with a S Akbulut-Jeradi, N.; Al Khaldi, R.; sensitivity of 79% for the identification of Sβthal. -

Identifying and Mapping Cell-Type-Specific Chromatin PNAS PLUS Programming of Gene Expression
Identifying and mapping cell-type-specific chromatin PNAS PLUS programming of gene expression Troels T. Marstranda and John D. Storeya,b,1 aLewis-Sigler Institute for Integrative Genomics, and bDepartment of Molecular Biology, Princeton University, Princeton, NJ 08544 Edited by Wing Hung Wong, Stanford University, Stanford, CA, and approved January 2, 2014 (received for review July 2, 2013) A problem of substantial interest is to systematically map variation Relating DHS to gene-expression levels across multiple cell in chromatin structure to gene-expression regulation across con- types is challenging because the DHS represents a continuous ditions, environments, or differentiated cell types. We developed variable along the genome not bound to any specific region, and and applied a quantitative framework for determining the exis- the relationship between DHS and gene expression is largely tence, strength, and type of relationship between high-resolution uncharacterized. To exploit variation across cell types and test chromatin structure in terms of DNaseI hypersensitivity and genome- for cell-type-specific relationships between DHS and gene expres- wide gene-expression levels in 20 diverse human cell types. We sion, the measurement units must be placed on a common scale, show that ∼25% of genes show cell-type-specific expression ex- the continuous DHS measure associated to each gene in a well- plained by alterations in chromatin structure. We find that distal defined manner, and all measurements considered simultaneously. regions of chromatin structure (e.g., ±200 kb) capture more genes Moreover, the chromatin and gene-expression relationship may with this relationship than local regions (e.g., ±2.5 kb), yet the local only manifest in a single cell type, making standard measures of regions show a more pronounced effect. -

Supporting Information
Supporting Information Biagioli et al. 10.1073/pnas.0813216106 SI Text and the procedure was repeated twice. Single cells were then RNA Isolation, Reverse Transcription, qPCR, Cloning, and Sequencing. resuspended in panning buffer and incubated on lectin-coated RNA was extracted from cell lines and blood by using TRIzol panning plates for 15 min at room temperature. Nonadherent reagent (Invitrogen) and following vendor instructions. cells were transferred to the next panning plate (four pannings, RNA was extracted from LCM- or FACS-purified cells with an 15 min each). Then, nonadherent cells were collected, centri- Absolutely RNA Nanoprep Kit (Stratagene). Single-strand fuged, and resuspended in serum-free neuronal medium or PBS. cDNA was obtained from purified RNA by using the iSCRIPT A similar procedure was also followed for the dissociation of cDNA Synhesis Kit (Bio-Rad) according to the manufacturer’s cortical and hippocampal astrocytes and oligodendrocytes. instructions. Quantitative RT-PCR was performed by using A cell strainer with 70-m nylon mesh was used to obtain a SYBER-Green PCR Master Mix and an iQ5 Real-Time PCR single-cell suspension (BD Falcon) before sorting. 7-AAD Detection System (Bio-Rad). (Beckman–Coulter) was added to the cell suspension to exclude Quantitative RT-PCR was performed with an iCycler IQ dead cells. A high-speed cell sorter (MoFlo) was used to sort (Bio-Rad); -actin was used as an endogenous control to nor- subpopulation of cells expressing GFP. Sorting parameters used malize the expression level of target genes. Primers were chosen for the three different populations are visualized in Fig. -

Adult, Embryonic and Fetal Hemoglobin Are Expressed in Human Glioblastoma Cells
514 INTERNATIONAL JOURNAL OF ONCOLOGY 44: 514-520, 2014 Adult, embryonic and fetal hemoglobin are expressed in human glioblastoma cells MARWAN EMARA1,2, A. ROBERT TURNER1 and JOAN ALLALUNIS-TURNER1 1Department of Oncology, University of Alberta and Alberta Health Services, Cross Cancer Institute, Edmonton, AB T6G 1Z2, Canada; 2Center for Aging and Associated Diseases, Zewail City of Science and Technology, Cairo, Egypt Received September 7, 2013; Accepted October 7, 2013 DOI: 10.3892/ijo.2013.2186 Abstract. Hemoglobin is a hemoprotein, produced mainly in Introduction erythrocytes circulating in the blood. However, non-erythroid hemoglobins have been previously reported in other cell Globins are hemo-containing proteins, have the ability to types including human and rodent neurons of embryonic bind gaseous ligands [oxygen (O2), nitric oxide (NO) and and adult brain, but not astrocytes and oligodendrocytes. carbon monoxide (CO)] reversibly. They have been described Human glioblastoma multiforme (GBM) is the most aggres- in prokaryotes, fungi, plants and animals with an enormous sive tumor among gliomas. However, despite extensive basic diversity of structure and function (1). To date, hemoglobin, and clinical research studies on GBM cells, little is known myoglobin, neuroglobin (Ngb) and cytoglobin (Cygb) repre- about glial defence mechanisms that allow these cells to sent the vertebrate globin family with distinct function and survive and resist various types of treatment. We have tissue distributions (2). During ontogeny, developing erythro- shown previously that the newest members of vertebrate blasts sequentially express embryonic {[Gower 1 (ζ2ε2), globin family, neuroglobin (Ngb) and cytoglobin (Cygb), are Gower 2 (α2ε2), and Portland 1 (ζ2γ2)] to fetal [Hb F(α2γ2)] expressed in human GBM cells. -
Technical Note, Appendix: an Analysis of Blood Processing Methods to Prepare Samples for Genechip® Expression Profiling (Pdf, 1
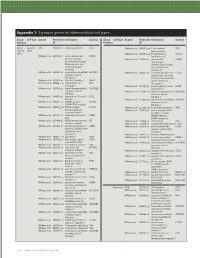
Appendix 1: Signature genes for different blood cell types. Blood Cell Type Source Probe Set Description Symbol Blood Cell Type Source Probe Set Description Symbol Fraction ID Fraction ID Mono- Lympho- GSK 203547_at CD4 antigen (p55) CD4 Whitney et al. 209813_x_at T cell receptor TRG nuclear cytes gamma locus cells Whitney et al. 209995_s_at T-cell leukemia/ TCL1A Whitney et al. 203104_at colony stimulating CSF1R lymphoma 1A factor 1 receptor, Whitney et al. 210164_at granzyme B GZMB formerly McDonough (granzyme 2, feline sarcoma viral cytotoxic T-lymphocyte- (v-fms) oncogene associated serine homolog esterase 1) Whitney et al. 203290_at major histocompatibility HLA-DQA1 Whitney et al. 210321_at similar to granzyme B CTLA1 complex, class II, (granzyme 2, cytotoxic DQ alpha 1 T-lymphocyte-associated Whitney et al. 203413_at NEL-like 2 (chicken) NELL2 serine esterase 1) Whitney et al. 203828_s_at natural killer cell NK4 (H. sapiens) transcript 4 Whitney et al. 212827_at immunoglobulin heavy IGHM Whitney et al. 203932_at major histocompatibility HLA-DMB constant mu complex, class II, Whitney et al. 212998_x_at major histocompatibility HLA-DQB1 DM beta complex, class II, Whitney et al. 204655_at chemokine (C-C motif) CCL5 DQ beta 1 ligand 5 Whitney et al. 212999_x_at major histocompatibility HLA-DQB Whitney et al. 204661_at CDW52 antigen CDW52 complex, class II, (CAMPATH-1 antigen) DQ beta 1 Whitney et al. 205049_s_at CD79A antigen CD79A Whitney et al. 213193_x_at T cell receptor beta locus TRB (immunoglobulin- Whitney et al. 213425_at Homo sapiens cDNA associated alpha) FLJ11441 fis, clone Whitney et al. 205291_at interleukin 2 receptor, IL2RB HEMBA1001323, beta mRNA sequence Whitney et al. -

Recombinant Human Hemoglobin Subunit Theta-1/HBQ1 (N-6His)
9853 Pacific Heights Blvd. Suite D. San Diego, CA 92121, USA Tel: 858-263-4982 Email: [email protected] 32-8592: Recombinant Human Hemoglobin Subunit theta-1/HBQ1 (N-6His) Gene : HBQ1 Gene ID : 3049 Uniprot ID : P09105 Description Source: E.coli. MW :17.7kD. Recombinant Human Hemoglobin subunit theta-1 is produced by our E.coli expression system and the target gene encoding Met1-Arg142 is expressed with a 6His tag at the N-terminus. Hemoglobin subunit theta-1 is a protein that in humans is encoded by the HBQ1 gene. Theta-globin mRNA is originally found in human fetal erythroid tissue but not in adult erythroid or other nonerythroid tissue. Theta-1 is a member of the human alpha-globin gene cluster that includes five functional genes and two pseudogenes. Research supports a transcriptionally active role for the gene and a functional role for the peptide in specific cells, possibly those of early erythroid tissue. Hemoglobin has a quaternary structure characteristically composed of many multi- subunit globular proteins. Most of the amino acids in hemoglobin form alpha helices, connected by short non-helical segments. Hydrogen bonds stabilize the helical sections inside this protein, causing attractions within the molecule, folding each polypeptide chain into a specific shape. Hemoglobin's quaternary structure comes from its four subunits in roughly a tetrahedral arrangement. Product Info Amount : 10 µg / 50 µg Content : Lyophilized from a 0.2 µm filtered solution of 20mM PB, 150mM NaCl, pH 7.0. Lyophilized protein should be stored at -20°C, though stable at room temperature for 3 weeks. -

Molecular Epidemiology and Hematologic Characterization of Δβ
Jiang et al. BMC Medical Genetics (2020) 21:43 https://doi.org/10.1186/s12881-020-0981-x RESEARCH ARTICLE Open Access Molecular epidemiology and hematologic characterization of δβ-thalassemia and hereditary persistence of fetal hemoglobin in 125,661 families of greater Guangzhou area, the metropolis of southern China Fan Jiang1,2, Liandong Zuo2, Dongzhi Li2, Jian Li2, Xuewei Tang2, Guilan Chen2, Jianying Zhou2, Hang Lu2 and Can Liao1,2* Abstract Background: Individuals with δβ-thalassemia/HPFH and β-thalassemia usually present with intermedia or thalassemia major. No large-scale survey on HPFH/δβ-thalassemia in southern China has been reported to date. The purpose of this study was to examine the molecular epidemiology and hematologic characteristics of these disorders in Guangzhou, the largest city in Southern China, to offer advice for thalassemia screening programs and genetic counseling. Methods: A total of 125,661 couples participated in pregestational thalassemia screening. 654 subjects with fetal hemoglobin (HbF) level ≥ 5% were selected for further investigation. Gap-PCR combined with Multiplex ligation dependent probe amplification (MLPA) was used to screen for β-globin gene cluster deletions. Gene sequencing for the promoter region of HBG1 /HBG2 gene was performed for all those subjects. Results: A total of 654 individuals had hemoglobin (HbF) levels≥5, and 0.12% of the couples were found to be heterozygous for HPFH/δβ-thalassemia, including Chinese Gγ (Aγδβ)0-thal, Southeast Asia HPFH (SEA-HPFH), Taiwanese deletion and Hb Lepore–Boston–Washington. The highest prevalence was observed in the Huadu district and the lowest in the Nansha district. Three cases were identified as carrying β-globin gene cluster deletions, which had not been previously reported. -

Identification of Novel HPFH-Like Mutations by CRISPR Base Editing That Elevates the Expression of Fetal Hemoglobin
bioRxiv preprint doi: https://doi.org/10.1101/2020.06.30.178715; this version posted July 1, 2020. The copyright holder for this preprint (which was not certified by peer review) is the author/funder. All rights reserved. No reuse allowed without permission. Identification of novel HPFH-like mutations by CRISPR base editing that elevates the expression of fetal hemoglobin Nithin Sam Ravi1,3, Beeke Wienert4,8,9, Stacia K. Wyman4, Jonathan Vu4, Aswin Anand Pai2, Poonkuzhali Balasubramanian2, Yukio Nakamura7, Ryo Kurita10, Srujan Marepally1, Saravanabhavan Thangavel1, Shaji R. Velayudhan1,2, Alok Srivastava1,2, Mark A. DeWitt 4,5, Jacob E. Corn4,6, Kumarasamypet M. Mohankumar1* 1. Centre for Stem Cell Research (a unit of inStem, Bengaluru), Christian Medical College Campus, Bagayam, Vellore-632002, Tamil Nadu, India. 2. Department of Haematology, Christian Medical College Hospital, IDA Scudder Rd, Vellore-632002, Tamil Nadu, India. 3. Sree Chitra Tirunal Institute for Medical Sciences and Technology, Thiruvananthapuram - 695 011, Kerala, India. 4. Innovative Genomics Institute, University of California Berkeley, Berkeley, California- 94704, USA. 5. Department of Microbiology, Immunology, and Molecular Genetics, University of California - Los Angeles, Los Angeles, California - 90095, USA. 6. Institute of Molecular Health Sciences, Department of Biology, ETH Zurich, Otto-Stern- Weg, Zurich - 8092, Switzerland. 7. Cell Engineering Division, RIKEN BioResource Center, Tsukuba, Ibaraki 305-0074, Japan. 8. Institute of Data Science and Biotechnology, Gladstone Institutes, San Francisco, California -94158, USA 9. School of Biotechnology and Biomolecular Sciences, University of New South Wales - 2052, Sydney, Australia. 10. Research and Development Department Central Blood Institute Blood Service Headquarters Japanese Red Cross Society, 2-1-67 Tatsumi, Tokyo, 135-8521, Japan *Corresponding Author: Dr. -

Hemoglobin Sickle D Punjab—A Case Report
154 Case Report Hemoglobin sickle D Punjab—a case report M. B. Mukherjee, R. R. Surve, R. R. Gangakhedkar, D. Mohanty, R. B. Colah Institute of Immunohaematology, Parel, Mumbai, India. Case History Compound heterozygosity for βS/βD results in a severe hemolytic anemia and a clinical syndrome similar to that of sickle cell disease. Here, we report a case of HbSD Punjab disease. A 10 year old female child residing at Nagpur, A 10 year old female child from Nagpur was referred Maharashtra presented with severe hemolytic anemia, to us with severe hemolytic anemia, occasional episodes hepatosplenomegaly and occasional pains in bones and of pains (predominantly bones and abdomen) associ- abdomen. Initially, she was thought to be a case of sickle cell anemia, however, with the help of HPLC and molecu- ated with fever. She had also received three units of lar analysis it was confirmed as HbSD Punjab disease. blood. Physical examination revealed short stature Key words: HbSD Punjab, Sickle cell disease, Haplotype, (weight 12.5 kg and height 105 cm), pallor, hepatome- α-geonotype galy (2 cm) and splenomegaly (3 cm) below the right and left costal margins respectively. Cardiovascular, res- piratory and nervous systems were normal. HbD Punjab also known as HbD Los Angeles is a β- chain variant and is characterized by a Glu→Gln sub- Investigations stitution at codon 121 with a GAA→CAA change at the DNA level and the electrophotetic mobility at alkaline Her Hb was 5.9 g/dl and the reticulocyte count was pH is similar to HbS (β6, Glu→Val).[1] HbD has been 3.3%. -

Simultaneous Detection of Target Cnvs and Snvs of Thalassemia by Multiplex PCR and Next‑Generation Sequencing
MOLECULAR MEDICINE REPORTS 19: 2837-2848, 2019 Simultaneous detection of target CNVs and SNVs of thalassemia by multiplex PCR and next‑generation sequencing DONG-MEI FAN1*, XU YANG2*, LI-MIN HUANG1, GUO-JUN OUYANG3, XUE-XI YANG1 and MING LI1 1Institute of Antibody Engineering, School of Laboratory Medicine and Biotechnology, Southern Medical University, Guangzhou, Guangdong 510515; 2Clinical Innovation and Research Center, Shenzhen Hospital of Southern Medical University, Shenzhen, Guangdong 518110; 3Guangzhou Darui Biotechnology Co., Ltd., Guangzhou, Guangdong 510663, P.R. China Received May 16, 2018; Accepted December 3, 2018 DOI: 10.3892/mmr.2019.9896 Abstract. Thalassemia is caused by complex mechanisms, Introduction including copy number variants (CNVs) and single nucleotide variants (SNVs). The CNV types of α-thalassemia are typi- Thalassemia is caused by copy number variants (CNVs) and cally detected by gap-polymerase chain reaction (PCR). The single nucleotide variants (SNVs) in the α-globin (HBA) or SNV types are detected by Sanger sequencing. In the present β-globin (HBB) genes that result in the absence or lack of α- or study, a novel method was developed that simultaneously β-globin chains, and ultimately hemolytic anemia. It is esti- detects CNVs and SNVs by multiplex PCR and next-genera- mated that ~7% of the world population carries the gene for the tion sequencing (NGS). To detect CNVs, 33 normal samples disease (1), and the birth rate of children with hemoglobin (Hb) were used as a cluster of control values to build a baseline, disorders is ≥2.4% per year (2). Thalassemia occurs most in the and the A, B, C, and D ratios were developed to evaluate-SEA, Mediterranean region, East South Asia, and the subcontinents -α4.2, -α3.7, and compound or homozygous CNVs, respectively. -

The Alexipharmic Mechanisms of Five Licorice Ingredients Involved in CYP450 and Nrf2 Pathways in Paraquat-Induced Mice Acute Lung Injury
Hindawi Oxidative Medicine and Cellular Longevity Volume 2019, Article ID 7283104, 20 pages https://doi.org/10.1155/2019/7283104 Research Article The Alexipharmic Mechanisms of Five Licorice Ingredients Involved in CYP450 and Nrf2 Pathways in Paraquat-Induced Mice Acute Lung Injury Zi-Jing Liu,1,2 Jing Zhong,1 Mei Zhang,1 Ze-Hui Chen,1 Ji-Ye Wang,1 Han-Ying Chen,1,2 Xiao-Qin Wang,1,2 and Bo Zhang 1,2 1Key Laboratory of Xinjiang Endemic Phytomedicine Resources, Ministry of Education, School of Pharmacy, Shihezi University, Shihezi 832002, China 2Pharmacology Department, School of Pharmacy, Shihezi University, Shihezi 832002, China Correspondence should be addressed to Bo Zhang; [email protected] Received 21 May 2018; Revised 30 September 2018; Accepted 3 December 2018; Published 28 April 2019 Academic Editor: Pablo Muriel Copyright © 2019 Zi-Jing Liu et al. This is an open access article distributed under the Creative Commons Attribution License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited. Oxidative stress is an important mechanism in acute lung injury (ALI) induced by paraquat (PQ), one of the most widely used herbicides in developing countries. In clinical prophylaxis and treatment, licorice is a widely used herbal medicine in China due to its strong alexipharmic characteristics. However, the corresponding biochemical mechanism of antioxidation and detoxification enzymes induced by licorice’s ingredients is still not fully demonstrated. In this study, the detoxification effect of licorice was evaluated in vivo and in vitro. The detoxification and antioxidation effect of its active ingredients involved in the treatment was screened systematically according to Absorption, Distribution, Metabolism, and Excretion (ADME): predictions and evidence-based literature mining methods in silico approach. -

Normal, C=Critical
Patient Report |FINAL Client: Example Client ABC123 Patient: Patient, Example 123 Test Drive Salt Lake City, UT 84108 DOB 7/22/1970 UNITED STATES Gender: Female Patient Identifiers: 01234567890ABCD, 012345 Physician: Doctor, Example Visit Number (FIN): 01234567890ABCD Collection Date: 00/00/0000 00:00 Hemoglobin Evaluation Reflexive Cascade ARUP test code 2005792 Hemoglobin A 97.1 % (Ref Interval: 95.0-97.9) Hemoglobin A2 2.6 % (Ref Interval: 2.0-3.5) Hemoglobin F 0.3 % (Ref Interval: 0.0-2.1) REFERENCE INTERVAL: Hemoglobin F Access complete set of age- and/or gender-specific reference intervals for this test in the ARUP Laboratory Test Directory (aruplab.com). Hemoglobin S 0.0 % (Ref Interval: 0.0-0.0) Hemoglobin C 0.0 % (Ref Interval: 0.0-0.0) Hemoglobin E 0.0 % (Ref Interval: 0.0-0.0) Hemoglobin - Other 0.0 % (Ref Interval: 0.0-0.0) Sickle Cell Solubility Not Performed Hemoglobin, Capillary Electrophoresis Performed Hemoglobin Evaluation See Note Beta Globin Full Gene Sequencing Not Applicable H=High, L=Low, *=Abnormal, C=Critical Patient: Patient, Example ARUP Accession: 21-048-400496 Patient Identifiers: 01234567890ABCD, 012345 Visit Number (FIN): 01234567890ABCD Page 1 of 4 | Printed: 3/11/2021 11:41:09 AM 4848 Patient Report |FINAL Beta Globin (HBB) Del/Dup Result Not Applicable Alpha Thalassemia HBA1 and HBA2 Seq Not Applicable Gamma Globin (HBG1 and HBG2) Sequencing Not Applicable Hemoglobin Cascade Interpretation See Note H=High, L=Low, *=Abnormal, C=Critical Patient: Patient, Example ARUP Accession: 21-048-400496 Patient Identifiers: 01234567890ABCD, 012345 Visit Number (FIN): 01234567890ABCD Page 2 of 4 | Printed: 3/11/2021 11:41:09 AM 4848 Patient Report |FINAL RESULT Normal hemoglobin evaluation.