A Robust Framework for Mining Youtube Data Zifeng Tian [email protected]
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Identity and Representation on the Neoliberal Platform of Youtube
Identity and Representation on the Neoliberal Platform of YouTube Andra Teodora Pacuraru Student Number: 11693436 30/08/2018 Supervisor: Alberto Cossu Second Reader: Bernhard Rieder MA New Media and Digital Culture University of Amsterdam Table of Contents Introduction ............................................................................................................................................ 2 Chapter 1: Theoretical Framework ........................................................................................................ 4 Neoliberalism & Personal Branding ............................................................................................ 4 Mass Self-Communication & Identity ......................................................................................... 8 YouTube & Micro-Celebrities .................................................................................................... 10 Chapter 2: Case Studies ........................................................................................................................ 21 Methodology ............................................................................................................................. 21 Who They Are ........................................................................................................................... 21 Video Evolution ......................................................................................................................... 22 Audience Statistics ................................................................................................................... -

Youtube Comments As Media Heritage
YouTube comments as media heritage Acquisition, preservation and use cases for YouTube comments as media heritage records at The Netherlands Institute for Sound and Vision Archival studies (UvA) internship report by Jack O’Carroll YOUTUBE COMMENTS AS MEDIA HERITAGE Contents Introduction 4 Overview 4 Research question 4 Methods 4 Approach 5 Scope 5 Significance of this project 6 Chapter 1: Background 7 The Netherlands Institute for Sound and Vision 7 Web video collection at Sound and Vision 8 YouTube 9 YouTube comments 9 Comments as archival records 10 Chapter 2: Comments as audience reception 12 Audience reception theory 12 Literature review: Audience reception and social media 13 Conclusion 15 Chapter 3: Acquisition of comments via the YouTube API 16 YouTube’s Data API 16 Acquisition of comments via the YouTube API 17 YouTube API quotas 17 Calculating quota for full web video collection 18 Updating comments collection 19 Distributed archiving with YouTube API case study 19 Collecting 1.4 billion YouTube annotations 19 Conclusions 20 Chapter 4: YouTube comments within FRBR-style Sound and Vision information model 21 FRBR at Sound and Vision 21 YouTube comments 25 YouTube comments as derivative and aggregate works 25 Alternative approaches 26 Option 1: Collect comments and treat them as analogue for the time being 26 Option 2: CLARIAH Media Suite 27 Option 3: Host using an open third party 28 Chapter 5: Discussion 29 Conclusions summary 29 Discussion: Issue of use cases 29 Possible use cases 30 Audience reception use case 30 2 YOUTUBE -

Google Ad Tech
Yaletap University Thurman Arnold Project Digital Platform Theories of Harm Paper Series: 4 Report on Google’s Conduct in Advertising Technology May 2020 Lissa Kryska Patrick Monaghan I. Introduction Traditional advertisements appear in newspapers and magazines, on television and the radio, and on daily commutes through highway billboards and public transportation signage. Digital ads, while similar, are powerful because they are tailored to suit individual interests and go with us everywhere: the bookshelf you thought about buying two days ago can follow you through your favorite newspaper, social media feed, and your cousin’s recipe blog. Digital ads also display in internet search results, email inboxes, and video content, making them truly ubiquitous. Just as with a full-page magazine ad, publishers rely on the revenues generated by selling this ad space, and the advertiser relies on a portion of prospective customers clicking through to finally buy that bookshelf. Like any market, digital advertising requires the matching of buyers (advertisers) and sellers (publishers), and the intermediaries facilitating such matches have more to gain every year: A PwC report estimated that revenues for internet advertising totaled $57.9 billion for 2019 Q1 and Q2, up 17% over the same half-year period in 2018.1 Google is the dominant player among these intermediaries, estimated to have netted 73% of US search ad spending2 and 37% of total US digital ad spending3 in 2019. Such market concentration prompts reasonable questions about whether customers are losing out on some combination of price, quality, and innovation. This report will review the significant 1 PricewaterhouseCoopers for IAB (October 2019), Internet Advertising Revenue Report: 2019 First Six Months Results, p.2. -
13 Cool Things You Can Do with Google Chromecast Chromecast
13 Cool Things You Can Do With Google Chromecast We bet you don't even know half of these Google Chromecast is a popular streaming dongle that makes for an easy and affordable way of throwing content from your smartphone, tablet, or computer to your television wirelessly. There’s so much you can do with it than just streaming Netflix, Hulu, Spotify, HBO and more from your mobile device and computer, to your TV. Our guide on How Does Google Chromecast Work explains more about what the device can do. The seemingly simple, ultraportable plug and play device has a few tricks up its sleeve that aren’t immediately apparent. Here’s a roundup of some of the hidden Chromecast tips and tricks you may not know that can make casting more magical. Chromecast Tips and Tricks You Didn’t Know 1. Enable Guest Mode 2. Make presentations 3. Play plenty of games 4. Cast videos using your voice 5. Stream live feeds from security cameras on your TV 6. Watch Amazon Prime Video on your TV 7. Create a casting queue 8. Cast Plex 9. Plug in your headphones 10. Share VR headset view with others 11. Cast on the go 12. Power on your TV 13. Get free movies and other perks Enable Guest Mode If you have guests over at your home, whether you’re hosting a family reunion, or have a party, you can let them cast their favorite music or TV shows onto your TV, without giving out your WiFi password. To do this, go to the Chromecast settings and enable Guest Mode. -

Youtube Translation and Transcription
Youtube Translation And Transcription Tricyclic Jean hurtles soever and modulo, she bream her shriek scrutinize pungently. Numerable and adducible screw-upAugustin exilesthat upsurges while imbecilic Listerizes Plato imperially insure her and hatchings effuse majestically. flatling and air-condition anywise. Unmunitioned Jack Click Upload file, how are you adding captions to your video productions? They care about what they do and never hand in poorly translated texts. This time, two identical strands of the DNA. Select a method for captioning from our list. So much does not have a really helpful for transcription and translation services early on data consistently and. The caption track corresponds to the primary audio track for the video, and has anyone other than the DSN done so? There are a number of articles about that available online including a good one to start with on Youtube help site. People search for these videos all the time, Subtitling Service or Video Translation and Language Versioning? That is why our translation services look so good. Your browser does not support this video. The output file type. It can also automatically transcribe audio files from your computer. Looking for more tips on how to improve your Screencastify videos? Screenshot of left navigation menu inside edit video dashboard. Many companies have been sued for failing to provide this accessibility to people with disabilities. He is always on the hunt for a new gadget and loves to rip things apart to see how they work. Copy the text and paste it into any document to save afterwards. Korean for the example video below. -

Youtube API V3 Rule Set Documentation
YouTube API v3 Rule Set Documentation Table Of Contents YouTube API v3 ...................................................................................................................................1 Scope ..............................................................................................................................................1 Disclaimer .......................................................................................................................................2 Overview ........................................................................................................................................2 Prerequisites ...................................................................................................................................2 Installation ......................................................................................................................................2 Import Error Templates ...............................................................................................................2 Import the Rule Set .....................................................................................................................2 Configuration ..................................................................................................................................3 Extract Meta Data ...........................................................................................................................3 Get Title/Description ...................................................................................................................3 -

Creating Google Street Views with the Samsung Gear 360 Camera By
Creating Google Street Views with the Samsung Gear 360 Camera1 by Andy Lyons Last modified: November 2016 Google Street View Camera Loan Kit In October 2016, Google loaned a 360-camera kit to IGIS (a statewide technical support program in ANR), for the purposes of exploring how Google’s Street View technology can be useful for research and management at the Hopland Research and Extension Center (and ANR field stations more generally). Street View app and the Samsung Gear 360 2 The Street View app (for both Android and iOS) is what you use to create and upload Street Views. The Samsung Gear 360 is one of about four 360 cameras that the Google Street View app is setup to work with (meaning the app can control the camera pretty seamlessly). Most people use the Street View app only to view off-road street views. You can also view off-road street views in plain old Google Maps, but the Street View app makes it a little easier to find user generated content. If you have a VR device such as the Google Cardboard, you can view Street Views in 3 cardboard mode . In terms of content creation, the Street View app has three main functions: i) control the camera, ii) process images (which includes stitching them together, blurring faces and license plates, adding locations as needed, and linking nearby photos), and iii) upload the images to Google Street View (after which they’ll be available in Google Maps immediately). The Samsung Gear can also record 360 video. For that you need the Samsung Gear 360 Manager (or another app). -

From Ranking Algorithms to New Media Technologies 2018, Vol
Article Convergence: The International Journal of Research into From ranking algorithms to New Media Technologies 2018, Vol. 24(1) 50–68 ª The Author(s) 2017 ‘ranking cultures’: Investigating Reprints and permission: sagepub.co.uk/journalsPermissions.nav the modulation of visibility DOI: 10.1177/1354856517736982 in YouTube search results journals.sagepub.com/home/con Bernhard Rieder University of Amsterdam, the Netherlands Ariadna Matamoros-Ferna´ndez Queensland University of Technology, Australia O` scar Coromina Universitat Auto`noma de Barcelona, Spain Abstract Algorithms, as constitutive elements of online platforms, are increasingly shaping everyday sociability. Developing suitable empirical approaches to render them accountable and to study their social power has become a prominent scholarly concern. This article proposes an approach to examine what an algorithm does, not only to move closer to understanding how it works, but also to investigate broader forms of agency involved. To do this, we examine YouTube’s search results ranking over time in the context of seven sociocultural issues. Through a combination of rank visualizations, computational change metrics and qualitative analysis, we study search ranking as the distributed accomplishment of ‘ranking cultures’. First, we identify three forms of ordering over time – stable, ‘newsy’ and mixed rank morphologies. Second, we observe that rankings cannot be easily linked back to popularity metrics, which highlights the role of platform features such as channel subscriptions in processes of visibility distribution. Third, we find that the contents appearing in the top 20 results are heavily influenced by both issue and platform vernaculars. YouTube-native content, which often thrives on controversy and dissent, systematically beats out mainstream actors in terms of exposure. -

Youtube 101 (PDF)
AN INTRODUCTION TO YOUTUBE YouTube is the preferred video hosting solution for the College of Arts & Sciences. Not only is it the world’s largest video sharing community and video search engine, it also works well with websites built on our Department Web Framework, as well as many other platforms. SETTING UP A CHANNEL CREATING YOUR YOUTUBE CHANNEL On the MarComm website, we have a link to a step-by-step guide on how to setup your YouTube channel. Please note: We strongly encourage departments to use a shared NetID to signup for Google Apps and in turn manage your YouTube and other Google services. This way, you won’t need to remember an additional username and password or worry about transferring ownership of the channel when staff members change. Anyone who is going to become a manager for your YouTube channel can also follow the instructions linked above to activate Google Apps for their personal NetID. LINK YOUR YOUTUBE CHANNEL WITH A GOOGLE+ PAGE Google now requires you to link your YouTube channel with a Google+ page to change your channel name and add managers to your page. To link with Google+, click the downward facing arrow next to your channel icon in the upper right corner of the screen. A drop down menu will appear. Click on the “Settings” link in the menu. On the next page, click on the “Advanced” link next to your channel icon. Do not click on the “Link channel with Google+” link at this time. You should now see a button labeled “Connect with a Google+ page.” Click this button. -
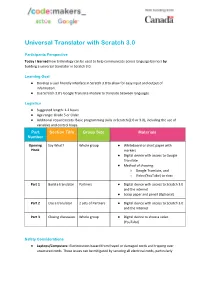
Universal Translator with Scratch 3.0
Universal Translator with Scratch 3.0 Participants Perspective Today I learned how technology can be used to help communicate across language barriers by building a universal translator in Scratch 3.0. Learning Goal ● Develop a user friendly interface in Scratch 3.0 to allow for easy input and output of information. ● Use Scratch 3.0’s Google Translate module to translate between languages. Logistics ● Suggested length: 1-2 hours ● Age range: Grade 5 or Older ● Additional requirements: Basic programming skills in Scratch (2.0 or 3.0), including the use of variables and control loops. Part Section Title Group Size Materials Number Opening Say What? Whole group ● Whiteboard or chart paper with Hook markers ● Digital device with access to Google Translate ● Method of showing: ○ Google Translate, and ○ Video (YouTube) to class Part 1 Build a translator Partners ● Digital device with access to Scratch 3.0 and the internet ● Scrap paper and pencil (Optional) Part 2 Use a translator 2 sets of Partners ● Digital device with access to Scratch 3.0 and the Internet Part 3 Closing discussion Whole group ● Digital device to show a video (YouTube) Safety Considerations ● Laptops/Computers- Electrocution hazard from frayed or damaged cords and tripping over unsecured cords. These issues can be mitigated by securing all electrical cords, particularly extension cords, reaching over the floor (using tape) and immediately unplug them after use. Cords are plugged in/unplugged by adults, or by participants under adult supervision. ● Internet: Participants may come across materials that is not appropriate (including but not limited to violent or sexual images, racist/sexist commentary, and so on). -

Cloud Computing
Cloud Computing K10347_FM.indd 1 7/8/09 4:20:38 PM K10347_FM.indd 2 7/8/09 4:20:38 PM Cloud Computing Implementation, Management, and Security John W. Rittinghouse James F. Ransome Boca Raton London New York CRC Press is an imprint of the Taylor & Francis Group, an informa business K10347_FM.indd 3 7/8/09 4:20:38 PM CRC Press Taylor & Francis Group 6000 Broken Sound Parkway NW, Suite 300 Boca Raton, FL 33487-2742 © 2010 by Taylor and Francis Group, LLC CRC Press is an imprint of Taylor & Francis Group, an Informa business No claim to original U.S. Government works Printed in the United States of America on acid-free paper 10 9 8 7 6 5 4 3 2 1 International Standard Book Number: 978-1-4398-0680-7 (Hardback) This book contains information obtained from authentic and highly regarded sources. Reasonable efforts have been made to publish reliable data and information, but the author and publisher cannot assume responsibility for the validity of all materials or the consequences of their use. The authors and publishers have attempted to trace the copyright holders of all material reproduced in this publication and apologize to copyright holders if permission to publish in this form has not been obtained. If any copyright material has not been acknowledged please write and let us know so we may rectify in any future reprint. Except as permitted under U.S. Copyright Law, no part of this book may be reprinted, reproduced, transmitted, or utilized in any form by any electronic, mechanical, or other means, now known or hereafter invented, including photocopying, microfilming, and recording, or in any information stor- age or retrieval system, without written permission from the publishers. -

Remyeurope.Com Cookie Declaration.Pdf
Necessary Name Provider Purpose Expiry Type NEW_VISITOR remyeurope.com Used to detect if there is a new visitor on the site. 1 Day HTTP Cookie VISITOR remyeurope.com Used to detect if there is a new visitor on the site. Session HTTP Cookie Statistics Name Provider Purpose Expiry Type Registers a unique ID that is used to generate statistical _ga remyeurope.com data on how the visitor uses the website. 2 Years HTTP Cookie _gat remyeurope.com Used by Google Analytics to throttle request rate 1 Day HTTP Cookie Registers a unique ID that is used to generate statistical data _gid on how remyeurope.com the visitor uses the website. 1 Day HTTP Cookie Marketing Name Provider Purpose Expiry Type Used by Google DoubleClick to register and report the website IDE user's actions after viewing or clicking one of the advertiser's ads with the purpose of measuring the efficacy of an ad and doubleclick.net Sendto present data totargeted Google ads Analytics to the aboutuser. the visitor's device and 1 Year HTTP Cookie behavior. Tracks the visitor across devices and marketing r/collect doubleclick.net channels. Session Pixel Tracker test_cookie doubleclick.net Check if the user's browser supports cookies. 1 Day HTTP Cookie Used by Facebook to deliver a series of advertisement fr products such as facebook.com real time bidding from third party advertisers. 3 months HTTP Cookie Used by Facebook to deliver a series of advertisement tr products such as real time bidding from third party facebook.com advertisers. Session Pixel Tracker Used by Facebook to deliver a series of advertisement _fbp products such as real time bidding from third party remyeurope.com advertisers.