Sc2/Wg2 N3686-Us
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

A Practical Sanskrit Introductory
A Practical Sanskrit Intro ductory This print le is available from ftpftpnacaczawiknersktintropsjan Preface This course of fteen lessons is intended to lift the Englishsp eaking studentwho knows nothing of Sanskrit to the level where he can intelligently apply Monier DhatuPat ha Williams dictionary and the to the study of the scriptures The rst ve lessons cover the pronunciation of the basic Sanskrit alphab et Devanagar together with its written form in b oth and transliterated Roman ash cards are included as an aid The notes on pronunciation are largely descriptive based on mouth p osition and eort with similar English Received Pronunciation sounds oered where p ossible The next four lessons describ e vowel emb ellishments to the consonants the principles of conjunct consonants Devanagar and additions to and variations in the alphab et Lessons ten and sandhi eleven present in grid form and explain their principles in sound The next three lessons p enetrate MonierWilliams dictionary through its four levels of alphab etical order and suggest strategies for nding dicult words The artha DhatuPat ha last lesson shows the extraction of the from the and the application of this and the dictionary to the study of the scriptures In addition to the primary course the rst eleven lessons include a B section whichintro duces the student to the principles of sentence structure in this fully inected language Six declension paradigms and class conjugation in the present tense are used with a minimal vo cabulary of nineteen words In the B part of -

Tai Lü / ᦺᦑᦟᦹᧉ Tai Lùe Romanization: KNAB 2012
Institute of the Estonian Language KNAB: Place Names Database 2012-10-11 Tai Lü / ᦺᦑᦟᦹᧉ Tai Lùe romanization: KNAB 2012 I. Consonant characters 1 ᦀ ’a 13 ᦌ sa 25 ᦘ pha 37 ᦤ da A 2 ᦁ a 14 ᦍ ya 26 ᦙ ma 38 ᦥ ba A 3 ᦂ k’a 15 ᦎ t’a 27 ᦚ f’a 39 ᦦ kw’a 4 ᦃ kh’a 16 ᦏ th’a 28 ᦛ v’a 40 ᦧ khw’a 5 ᦄ ng’a 17 ᦐ n’a 29 ᦜ l’a 41 ᦨ kwa 6 ᦅ ka 18 ᦑ ta 30 ᦝ fa 42 ᦩ khwa A 7 ᦆ kha 19 ᦒ tha 31 ᦞ va 43 ᦪ sw’a A A 8 ᦇ nga 20 ᦓ na 32 ᦟ la 44 ᦫ swa 9 ᦈ ts’a 21 ᦔ p’a 33 ᦠ h’a 45 ᧞ lae A 10 ᦉ s’a 22 ᦕ ph’a 34 ᦡ d’a 46 ᧟ laew A 11 ᦊ y’a 23 ᦖ m’a 35 ᦢ b’a 12 ᦋ tsa 24 ᦗ pa 36 ᦣ ha A Syllable-final forms of these characters: ᧅ -k, ᧂ -ng, ᧃ -n, ᧄ -m, ᧁ -u, ᧆ -d, ᧇ -b. See also Note D to Table II. II. Vowel characters (ᦀ stands for any consonant character) C 1 ᦀ a 6 ᦀᦴ u 11 ᦀᦹ ue 16 ᦀᦽ oi A 2 ᦰ ( ) 7 ᦵᦀ e 12 ᦵᦀᦲ oe 17 ᦀᦾ awy 3 ᦀᦱ aa 8 ᦶᦀ ae 13 ᦺᦀ ai 18 ᦀᦿ uei 4 ᦀᦲ i 9 ᦷᦀ o 14 ᦀᦻ aai 19 ᦀᧀ oei B D 5 ᦀᦳ ŭ,u 10 ᦀᦸ aw 15 ᦀᦼ ui A Indicates vowel shortness in the following cases: ᦀᦲᦰ ĭ [i], ᦵᦀᦰ ĕ [e], ᦶᦀᦰ ăe [ ∎ ], ᦷᦀᦰ ŏ [o], ᦀᦸᦰ ăw [ ], ᦀᦹᦰ ŭe [ ɯ ], ᦵᦀᦲᦰ ŏe [ ]. -

Devan¯Agar¯I for TEX Version 2.17.1
Devanagar¯ ¯ı for TEX Version 2.17.1 Anshuman Pandey 6 March 2019 Contents 1 Introduction 2 2 Project Information 3 3 Producing Devan¯agar¯ıText with TEX 3 3.1 Macros and Font Definition Files . 3 3.2 Text Delimiters . 4 3.3 Example Input Files . 4 4 Input Encoding 4 4.1 Supplemental Notes . 4 5 The Preprocessor 5 5.1 Preprocessor Directives . 7 5.2 Protecting Text from Conversion . 9 5.3 Embedding Roman Text within Devan¯agar¯ıText . 9 5.4 Breaking Pre-Defined Conjuncts . 9 5.5 Supported LATEX Commands . 9 5.6 Using Custom LATEX Commands . 10 6 Devan¯agar¯ıFonts 10 6.1 Bombay-Style Fonts . 11 6.2 Calcutta-Style Fonts . 11 6.3 Nepali-Style Fonts . 11 6.4 Devan¯agar¯ıPen Fonts . 11 6.5 Default Devan¯agar¯ıFont (LATEX Only) . 12 6.6 PostScript Type 1 . 12 7 Special Topics 12 7.1 Delimiter Scope . 12 7.2 Line Spacing . 13 7.3 Hyphenation . 13 7.4 Captions and Date Formats (LATEX only) . 13 7.5 Customizing the date and captions (LATEX only) . 14 7.6 Using dvnAgrF in Sections and References (LATEX only) . 15 7.7 Devan¯agar¯ıand Arabic Numerals . 15 7.8 Devan¯agar¯ıPage Numbers and Other Counters (LATEX only) . 15 1 7.9 Category Codes . 16 8 Using Devan¯agar¯ıin X E LATEXand luaLATEX 16 8.1 Using Hindi with Polyglossia . 17 9 Using Hindi with babel 18 9.1 Installation . 18 9.2 Usage . 18 9.3 Language attributes . 19 9.3.1 Attribute modernhindi . -

An Introduction to Indic Scripts
An Introduction to Indic Scripts Richard Ishida W3C [email protected] HTML version: http://www.w3.org/2002/Talks/09-ri-indic/indic-paper.html PDF version: http://www.w3.org/2002/Talks/09-ri-indic/indic-paper.pdf Introduction This paper provides an introduction to the major Indic scripts used on the Indian mainland. Those addressed in this paper include specifically Bengali, Devanagari, Gujarati, Gurmukhi, Kannada, Malayalam, Oriya, Tamil, and Telugu. I have used XHTML encoded in UTF-8 for the base version of this paper. Most of the XHTML file can be viewed if you are running Windows XP with all associated Indic font and rendering support, and the Arial Unicode MS font. For examples that require complex rendering in scripts not yet supported by this configuration, such as Bengali, Oriya, and Malayalam, I have used non- Unicode fonts supplied with Gamma's Unitype. To view all fonts as intended without the above you can view the PDF file whose URL is given above. Although the Indic scripts are often described as similar, there is a large amount of variation at the detailed implementation level. To provide a detailed account of how each Indic script implements particular features on a letter by letter basis would require too much time and space for the task at hand. Nevertheless, despite the detail variations, the basic mechanisms are to a large extent the same, and at the general level there is a great deal of similarity between these scripts. It is certainly possible to structure a discussion of the relevant features along the same lines for each of the scripts in the set. -

A STUDY of WRITING Oi.Uchicago.Edu Oi.Uchicago.Edu /MAAM^MA
oi.uchicago.edu A STUDY OF WRITING oi.uchicago.edu oi.uchicago.edu /MAAM^MA. A STUDY OF "*?• ,fii WRITING REVISED EDITION I. J. GELB Phoenix Books THE UNIVERSITY OF CHICAGO PRESS oi.uchicago.edu This book is also available in a clothbound edition from THE UNIVERSITY OF CHICAGO PRESS TO THE MOKSTADS THE UNIVERSITY OF CHICAGO PRESS, CHICAGO & LONDON The University of Toronto Press, Toronto 5, Canada Copyright 1952 in the International Copyright Union. All rights reserved. Published 1952. Second Edition 1963. First Phoenix Impression 1963. Printed in the United States of America oi.uchicago.edu PREFACE HE book contains twelve chapters, but it can be broken up structurally into five parts. First, the place of writing among the various systems of human inter communication is discussed. This is followed by four Tchapters devoted to the descriptive and comparative treatment of the various types of writing in the world. The sixth chapter deals with the evolution of writing from the earliest stages of picture writing to a full alphabet. The next four chapters deal with general problems, such as the future of writing and the relationship of writing to speech, art, and religion. Of the two final chapters, one contains the first attempt to establish a full terminology of writing, the other an extensive bibliography. The aim of this study is to lay a foundation for a new science of writing which might be called grammatology. While the general histories of writing treat individual writings mainly from a descriptive-historical point of view, the new science attempts to establish general principles governing the use and evolution of writing on a comparative-typological basis. -

565 Part 36—Loan Guaranty
Department of Veterans Affairs Pt. 36 (3) Permits, license, and other use Vermont Avenue NW., Washington, DC agreements or grants of real property 20420. for use by non-VA groups; and, (Authority: 42 U.S.C. 4321–4370a) (4) Application for grants-in-aid for acquisition, construction, expansion or improvement of state veterans’ health PART 36—LOAN GUARANTY care facilities or cemeteries. (c) Public notices or other means Subpart A—Guaranty of Loans to Veterans used to inform or solicit applicants for to Purchase Manufactured Homes and permits, leases, or related actions will Lots, Including Site Preparation describe the environmental documents, Sec. studies or information foreseeably re- 36.4201 Applicability of the § 36.4200 series. quired for later action by VA elements 36.4202 Definitions. and will advise of the assistance avail- able to applicants by VA element. GENERAL PROVISIONS (d) When VA owned land is leased or 36.4203 Eligibility of the veteran for the otherwise provided to non-VA groups, manufactured home loan benefit under 38 VA element affected will initiate the U.S.C. 3712. NEPA process pursuant to these regu- 36.4204 Loan purposes, maximum loan lations. amounts and terms. (e) When VA grant funds are re- 36.4205 Computation of guaranty. 36.4206 Underwriting standards, occupancy, quested by a State agency, VA element and non-discrimination requirements. affected will initiate the NEPA process 36.4207 Manufactured home standards. and ensure compliance with VA envi- 36.4208 Manufactured home location stand- ronmental program. The environ- ards. mental documents prepared by the 36.4209 Reporting requirements. grant applicant shall assure full com- 36.4210 Joint loans. -
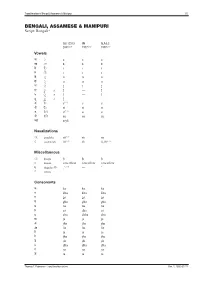
Transliteration of <Script Name>
Transliteration of Bengali, Assamese & Manipuri 1/5 BENGALI, ASSAMESE & MANIPURI Script: Bengali* ISO 15919 UN ALA-LC 2001(1.0) 1977(2.0) 1997(3.0) Vowels অ ◌ a a a আ ◌া ā ā ā ই ি◌ i i i ঈ ◌ী ī ī ī উ ◌ু u u u ঊ ◌ূ ū ū ū ঋ ◌ৃ r̥ ṛ r̥ ৠ ◌ৄ r̥̄ — r̥̄ ঌ ◌ৢ l̥ — l̥ ৡ ◌ৣ A l̥ ̄ — — এ ে◌ e(1.1) e e ঐ ৈ◌ ai ai ai ও ে◌া o(1.1) o o ঔ ে◌ৗ au au au অ�া a:yā — — Nasalizations ◌ং anunāsika ṁ(1.2) ṁ ṃ ◌ঁ candrabindu m̐ (1.2) m̐ n̐, m̐ (3.1) Miscellaneous ◌ঃ bisarga ḥ ḥ ḥ ◌্ hasanta vowelless vowelless vowelless (1.3) ঽ abagraha Ⓑ :’ — ’ ৺ isshara — — — Consonants ক ka ka ka খ kha kha kha গ ga ga ga ঘ gha gha gha ঙ ṅa ṅa ṅa চ ca cha ca ছ cha chha cha জ ja ja ja ঝ jha jha jha ঞ ña ña ña ট ṭa ṭa ṭa ঠ ṭha ṭha ṭha ড ḍa ḍa ḍa ঢ ḍha ḍha ḍha ণ ṇa ṇa ṇa ত ta ta ta Thomas T. Pedersen – transliteration.eki.ee Rev. 2, 2005-07-21 Transliteration of Bengali, Assamese & Manipuri 2/5 ISO 15919 UN ALA-LC 2001(1.0) 1977(2.0) 1997(3.0) থ tha tha tha দ da da da ধ dha dha dha ন na na na প pa pa pa ফ pha pha pha ব ba ba ba(3.2) ভ bha bha bha ম ma ma ma য ya ja̱ ya র ⒷⓂ ra ra ra ৰ Ⓐ ra ra ra ল la la la ৱ ⒶⓂ va va wa শ śa sha śa ষ ṣa ṣha sha স sa sa sa হ ha ha ha ড় ṛa ṙa ṛa ঢ় ṛha ṙha ṛha য় ẏa ya ẏa জ় za — — ব় wa — — ক় Ⓑ qa — — খ় Ⓑ k̲h̲a — — গ় Ⓑ ġa — — ফ় Ⓑ fa — — Adscript consonants ◌� ya-phala -ya(1.4) -ya ẏa ৎ khanda-ta -t -t ṯa ◌� repha r- r- r- ◌� baphala -b -b -b ◌� raphala -r -r -r Vowel ligatures (conjuncts)C � gu � ru � rū � Ⓐ ru � rū � śu � hr̥ � hu � tru � trū � ntu � lgu Thomas T. -
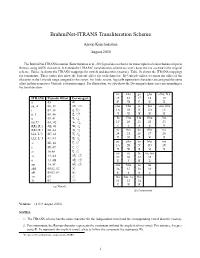
Brahminet-ITRANS Transliteration Scheme
BrahmiNet-ITRANS Transliteration Scheme Anoop Kunchukuttan August 2020 The BrahmiNet-ITRANS notation (Kunchukuttan et al., 2015) provides a scheme for transcription of major Indian scripts in Roman, using ASCII characters. It extends the ITRANS1 transliteration scheme to cover characters not covered in the original scheme. Tables 1a shows the ITRANS mappings for vowels and diacritics (matras). Table 1b shows the ITRANS mappings for consonants. These tables also show the Unicode offset for each character. By Unicode offset, we mean the offset of the character in the Unicode range assigned to the script. For Indic scripts, logically equivalent characters are assigned the same offset in their respective Unicode codepoint ranges. For illustration, we also show the Devanagari characters corresponding to the transliteration. ka kha ga gha ∼Na, N^a ITRANS Unicode Offset Devanagari 15 16 17 18 19 a 05 अ क ख ग घ ङ aa, A 06, 3E आ, ◌ा cha Cha ja jha ∼na, JNa i 07, 3F इ, ि◌ 1A 1B 1C 1D 1E ii, I 08, 40 ई, ◌ी च छ ज झ ञ u 09, 41 उ, ◌ु Ta Tha Da Dha Na uu, U 0A, 42 ऊ, ◌ू 1F 20 21 22 23 RRi, R^i 0B, 43 ऋ, ◌ृ ट ठ ड ढ ण RRI, R^I 60, 44 ॠ, ◌ॄ ta tha da dha na LLi, L^i 0C, 62 ऌ, ◌ॢ 24 25 26 27 28 LLI, L^I 61, 63 ॡ, ◌ॣ त थ द ध न pa pha ba bha ma .e 0E, 46 ऎ, ◌ॆ 2A 2B 2C 2D 2E e 0F, 47 ए, ◌े प फ ब भ म ai 10,48 ऐ, ◌ै ya ra la va, wa .o 12, 4A ऒ, ◌ॊ 2F 30 32 35 o 13, 4B ओ, ◌ो य र ल व au 14, 4C औ, ◌ौ sha Sha sa ha aM 05 02, 02 अं 36 37 38 39 aH 05 03, 03 अः श ष स ह .m 02 ◌ं Ra lda, La zha .h 03 ◌ः 31 33 34 (a) Vowels ऱ ळ ऴ (b) Consonants Version: v1.0 (9 August 2020) NOTES: 1. -

Prof. P. Bhaskar Reddy Sri Venkateswara University, Tirupati
Component-I (A) – Personal details: Prof. P. Bhaskar Reddy Sri Venkateswara University, Tirupati. Prof. P. Bhaskar Reddy Sri Venkateswara University, Tirupati. & Dr. K. Muniratnam Director i/c, Epigraphy, ASI, Mysore Dr. Sayantani Pal Dept. of AIHC, University of Calcutta. Prof. P. Bhaskar Reddy Sri Venkateswara University, Tirupati. Component-I (B) – Description of module: Subject Name Indian Culture Paper Name Indian Epigraphy Module Name/Title Kharosthi Script Module Id IC / IEP / 15 Pre requisites Kharosthi Script – Characteristics – Origin – Objectives Different Theories – Distribution and its End Keywords E-text (Quadrant-I) : 1. Introduction Kharosthi was one of the major scripts of the Indian subcontinent in the early period. In the list of 64 scripts occurring in the Lalitavistara (3rd century CE), a text in Buddhist Hybrid Sanskrit, Kharosthi comes second after Brahmi. Thus both of them were considered to be two major scripts of the Indian subcontinent. Both Kharosthi and Brahmi are first encountered in the edicts of Asoka in the 3rd century BCE. 2. Discovery of the script and its Decipherment The script was first discovered on one side of a large number of coins bearing Greek legends on the other side from the north western part of the Indian subcontinent in the first quarter of the 19th century. Later in 1830 to 1834 two full inscriptions of the time of Kanishka bearing the same script were found at Manikiyala in Pakistan. After this discovery James Prinsep named the script as ‘Bactrian Pehelevi’ since it occurred on a number of so called ‘Bactrian’ coins. To James Prinsep the characters first looked similar to Pahlavi (Semitic) characters. -

Simplified Abugidas
Simplified Abugidas Chenchen Ding, Masao Utiyama, and Eiichiro Sumita Advanced Translation Technology Laboratory, Advanced Speech Translation Research and Development Promotion Center, National Institute of Information and Communications Technology 3-5 Hikaridai, Seika-cho, Soraku-gun, Kyoto, 619-0289, Japan fchenchen.ding, mutiyama, [email protected] phonogram segmental abjad Abstract writing alphabet system An abugida is a writing system where the logogram syllabic abugida consonant letters represent syllables with Figure 1: Hierarchy of writing systems. a default vowel and other vowels are de- noted by diacritics. We investigate the fea- ណូ ន ណណន នួន ននន …ជិតណណន… sibility of recovering the original text writ- /noon/ /naen/ /nuən/ /nein/ vowel machine ten in an abugida after omitting subordi- diacritic omission learning ណន នន methods nate diacritics and merging consonant let- consonant character ters with similar phonetic values. This is merging N N … J T N N … crucial for developing more efficient in- (a) ABUGIDA SIMPLIFICATION (b) RECOVERY put methods by reducing the complexity in abugidas. Four abugidas in the south- Figure 2: Overview of the approach in this study. ern Brahmic family, i.e., Thai, Burmese, ters equally. In contrast, abjads (e.g., the Arabic Khmer, and Lao, were studied using a and Hebrew scripts) do not write most vowels ex- newswire 20; 000-sentence dataset. We plicitly. The third type, abugidas, also called al- compared the recovery performance of a phasyllabary, includes features from both segmen- support vector machine and an LSTM- tal and syllabic systems. In abugidas, consonant based recurrent neural network, finding letters represent syllables with a default vowel, that the abugida graphemes could be re- and other vowels are denoted by diacritics. -

The Formal Kharoṣṭhī Script from the Northern Tarim Basin in Northwest
Acta Orientalia Hung. 73 (2020) 3, 335–373 DOI: 10.1556/062.2020.00015 Th e Formal Kharoṣṭhī script from the Northern Tarim Basin in Northwest China may write an Iranian language1 FEDERICO DRAGONI, NIELS SCHOUBBEN and MICHAËL PEYROT* L eiden University Centre for Linguistics, Universiteit Leiden, Postbus 9515, 2300 RA Leiden, Th e Netherlands E-mail: [email protected]; [email protected]; *Corr esponding Author: [email protected] Received: February 13, 2020 •Accepted: May 25, 2020 © 2020 The Authors ABSTRACT Building on collaborative work with Stefan Baums, Ching Chao-jung, Hannes Fellner and Georges-Jean Pinault during a workshop at Leiden University in September 2019, tentative readings are presented from a manuscript folio (T II T 48) from the Northern Tarim Basin in Northwest China written in the thus far undeciphered Formal Kharoṣṭhī script. Unlike earlier scholarly proposals, the language of this folio can- not be Tocharian, nor can it be Sanskrit or Middle Indic (Gāndhārī). Instead, it is proposed that the folio is written in an Iranian language of the Khotanese-Tumšuqese type. Several readings are proposed, but a full transcription, let alone a full translation, is not possible at this point, and the results must consequently remain provisional. KEYWORDS Kharoṣṭhī, Formal Kharoṣṭhī, Khotanese, Tumšuqese, Iranian, Tarim Basin 1 We are grateful to Stefan Baums, Chams Bernard, Ching Chao-jung, Doug Hitch, Georges-Jean Pinault and Nicholas Sims-Williams for very helpful discussions and comments on an earlier draft. We also thank the two peer-reviewers of the manuscript. One of them, Richard Salomon, did not wish to remain anonymous, and espe- cially his observation on the possible relevance of Khotan Kharoṣṭhī has proved very useful. -

Draft Screening Assessment
Screening Asse ssment for the Challenge Phenol, (1,1-dimethylethyl)-4-methoxy- (Butylated hydroxyanisole) Chemical Abstracts Service Registry Number 25013-16-5 Environment Canada Health Canada July 2010 Screening Assessment CAS RN 25013-16-5 Synopsis The Ministers of the Environment and of Health have conducted a screening assessment of phenol, (1,1-dimethylethyl)-4-methoxy- (also known as butylated hydroxyanisole or BHA), Chemical Abstracts Service Registry Number 25013-16-5. The substance BHA was identified in the categorization of the Domestic Substances List as a high priority for action under the Challenge, as it was determined to present intermediate potential for exposure of individuals in Canada and was considered to present a high hazard to human health, based upon classification by other agencies on the basis of carcinogenicity. The substance did not meet the ecological categorization criteria for persistence, bioaccumulation or inherent toxicity to aquatic organisms. Therefore, this assessment focuses principally upon information relevant to the evaluation of risks to human health. According to information reported in response to a notice published under section 71 of the Canadian Environmental Protection Act, 1999 (CEPA 1999), no BHA was manufactured in Canada in 2006 at quantities equal to or greater than the reporting threshold of 100 kg. However, between 100 and 1000 kg of BHA was imported into Canada, while between 1000 and 10 000 kg of BHA was used in Canada alone, in a product, in a mixture or in a manufactured item. BHA is permitted for use in Canada as an antioxidant in food. In fats and fat-containing foods, BHA delays the deterioration of flavours and odours and substantially increases the shelf life.