Towards the Semantic Web: Collaborative Tag Suggestions
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

The Example of Swedish Independent Music Fandom by Nancy K
First Monday Online groups are taking new forms as participants spread themselves amongst multiple Internet and offline platforms. The multinational online community of Swedish independent music fans exemplifies this trend. This participant–observation analysis of this fandom shows how sites are interlinked at multiple levels, and identifies several implications for theorists, researchers, developers, industry and independent professionals, and participants. Contents Introduction Fandom Swedish popular music The Swedish indie music fan community Discussion Conclusion Introduction The rise of social network sites is often taken to exemplify a shift from the interest–based online communities of the Web’s “first” incarnation to a new “Web 2.0” in which individuals are the basic unit, rather than communities. In a recent First Monday article, for instance, boyd (2006) states, “egocentric networks replace groups.” I argue that online groups have not been “replaced.” Even as their members build personal profiles and egocentric networks on MySpace, Facebook, BlackPlanet, Orkut, Bebo, and countless other emerging social network sites, online groups continue to thrive on Web boards, in multiplayer online games, and even on the all–but–forgotten Usenet. However, online communities are also taking a new form somewhere between the site-based online group and the egocentric network, distributing themselves throughout a variety of sites in a quasi–coherent networked fashion. This new form of distributed community poses particular problems for its members, developers, and analysts. This paper, based on over two years of participant–observation, describes this new shape of online community through a close look at the multinational online community of fans of independent rock music from Sweden. -

Young Adult Library Services Association
THE OFFICIAL JOURNAL OF THE YOUNG ADULT LIBRARY SERVICES ASSOCIATION five ye ng ar ti s a o r f b y e a l l e s c young adult c e s l l e a b y r 5 f a t o in rs librarylibrary services services g five yea VOLUME 6 | NUMBER 2 WINTER 2008 ISSN 1541-4302 $12.50 INSIDE: INFORMATION TOOLS MUsiC WEB siTes TOP FIFTY GAMinG CORE COLLECTION TITLES INTERVIEW WITH KIMBERLY NEWTON FUSCO INFORMATION LITERACY AND MUCH MORE! TM ISSUE! TEEN TECH WEEK TM TM TEEN TECH WEEK MARCH 2-8, 2008 ©2007 American Library Association | Produced in partnership with YALSA | Design by Distillery Design Studio | www.alastore.ala.org march 2–8, 2008 for Teen Tech Week™ 2008! Join the celebration! Visit www.ala.org/teentechweek, and you can: ã Get great ideas for activities and events for any library, at any budget ã Download free tech guides and social networking resources to share with your teens ã Buy cool Teen Tech Week merchandise for your library ã Find inspiration or give your own ideas at the Teen Tech Week wiki, http://wikis.ala.org/yalsa/index.php/ Teen_Tech_Week! Teen Tech Week 2008 National Corporate Sponsor www.playdnd.com ttw_fullpage_cmyk.indd 1 1/3/2008 1:32:22 PM THE OFFICIAL JOURNAL OF THE YOUNG ADULT LIBRARY SERVICES ASSOCIATION young adult library services VOLUME 6 | NU MBER 2 WINTER 2008 ISSN 1541-4302 YALSA Perspective 33 Music Web Sites for Teen Tech Week 6 Margaret Edwards Award Turns 20 and Beyond By Betty Carter and Pam Spencer Holley By Kate Pritchard and Jaina Lewis 36 Top Fifty Gaming Core Collection Titles School Library Perspective Compiled by Kelly Czarnecki 14 Do We Still Dewey? By Christine Allen Literature Surveys and Research 39 Information Literacy As a Department Teen Perspective Store 15 Teens’ Top Ten Redux Applications for Public Teen Librarians Readers from New Jersey Talk about the By Dr. -

Social Media Compendium Oktober 2009
Social Media Compendium Oktober 2009 COMMUNITY PLATFORMS / SOCIAL NETWORKS NICHED COMMUNITIES BLOG PLATFORMS BLOG COMMUNITIES & TOOLS / FORUM BLOG SEARCH COMMENT / REPUTATION MICROMEDIA / MICROBLOGGING SOCIAL BOOKMARKING CROWDSOURCED CONTENT CUSTOMER SERVICE, REVIEWS TEXT & PRESENTATION PUBLISHING & SHARING IMAGE SHARING & HOSTING IMAGE SEARCH IMAGE EDITING MUSIC SHARING & STREAMING VIDEO PUBLISHING & SHARING INSTRUCTIONAL & EDUCATIONAL VIDEOS VIDEO SEARCH ENGINES VIDEO STREAMING FEEDS / NEWS AGGREGATOR SOCIAL AGGREGATOR / PROFILE MANAGER LOCATION!BASED EVENTS DIRECT COMMUNICATION "IM / SMS / VOICE# WIKIS COLLABORATIVE PLATFORMS PRODUCTIVITY TOOLS INFORMATION DATABASES / MONITORING MEDIA & COMMUNICATION BLOGS SEARCH ENGINES REAL!TIME SEARCH by Matthieu Hartig ■ [email protected] ■ @matthartig COMMUNITY PLATFORMS / SOCIAL NETWORKS facebook.com (2) Facebook is the world’s largest free-access social networking website. Users can join networks organized by city, workplace, school, and region to connect and interact with other people. People can also add friends and send them messages, and update their personal pro"les to notify friends. hi5.com (43) hi5 is an international social network with a local #avor. It enables members to stay connect- ed, share their lives, and learn what’s happening around them – through customizable pro"le pages, messaging, unlimited photo storage, hundreds of OpenSocial applications and more. friendster.com (117) Founded in 2002, Friendster is one of the web’s older social networking services. Adults, 16 and up can join and connect with friends, family, school, groups, activities and interests. $e site currently has over 50 million users. Over 90% of Friendster’s tra%c comes from Asia. tagged.com (109) Protecting the safety of their users is what makes Tagged di&erent from other social network- ing sites. -

Empowering School Teachers for Emerging Technologies: an Action Plan
RESEARCH PAPERS EMPOWERING SCHOOL TEACHERS FOR EMERGING TECHNOLOGIES: AN ACTION PLAN By PRADEEP KUMAR MISRA Associate Professor, Faculty of Education and Allied Sciences, M.J.P. Rohilkhand University, Bareilly (U.P.) ABSTRACT “Possessing openness to emerging technologies is critical for teachers in the technology-rich 21st Century as technology continues to accelerate at a rapid rate. Readiness for new technologies is a challenge associated with change. Teachers who resist change may impede and/or limit their students' learning and skills. Teachers, therefore, must prepare students by teaching knowledge and skills necessary for students to be successful in the technology-rich 21st Century” (Niles, 2007, p.27). In this context, school teachers need to understand how emerging technologies work, what they offer, and to use them for betterment of teaching learning process. Here a pertinent question arises that what approach should be adopted to empower school teachers for emerging technologies. To critically and systematically deal with these issues, author talks about emerging technologies in education, their impact on teaching-learning process and need for Tech-savvy teachers. This discussion is followed by a detailed action plan to empower school teachers for emerging technologies. The proposed action plan is based on the approach that three parties namely NCTE (National Council for Teacher Education), Teacher Education Departments/Institutions and school teachers themselves are key to fulfill this promise. Keywords: Emerging Technologies, School Teachers, Technologies for Teachers, Technologies for Teaching Learning. INTRODUCTION more – and will always know more – than their teachers Background about technology and how to manipulate it”(p.42). Prensky (2007, p.42) further offers word of advice, “Teachers can Technology has caused a revolution in the way we teach and should be able to understand and teach where and and learn but there can be no real revolution unless the how new technologies can add value in learning. -
Introduction to Blogs
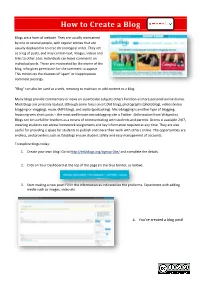
How to Create a Blog Blogs are a form of website. They are usually maintained by one or several people, with regular entries that are usually displayed in reverse chronological order. They act as a log of posts, and may contain text, images, videos and links to other sites. Individuals can leave comments on individual posts. These are moderated by the owner of the blog, who gives permission for the comment to appear. This minimizes the chances of ‘spam’ or inappropriate comment postings. "Blog" can also be used as a verb, meaning to maintain or add content to a blog. Many blogs provide commentary or news on a particular subject; others function as more personal online diaries. Most blogs are primarily textual, although some focus on art (Art blog), photographs (photoblog), videos (video blogging or vlogging), music (MP3 blog), and audio (podcasting). Microblogging is another type of blogging, featuring very short posts – the most well known microblogging site is Twitter. (Information from Wikipedia). Blogs can be useful for teachers as a means of communicating with students and parents. Access is available 24/7, meaning students can access homework assignments and key information required at any time. They are also useful for providing a space for students to publish and share their work with others online. The opportunities are endless, and providers such as Edublogs ensure student safety and easy management of accounts. To explore blogs today: 1. Create your own blog! Go to http://edublogs.org/signup-0be/ and complete the details. 2. Click on Your Dashboard at the top of the page (in the blue border, as below). -

The Users and Marketing Efficacy of MP3 Music Blogs
Florida State University Libraries Electronic Theses, Treatises and Dissertations The Graduate School 2006 Users and the Marketing Efficacy of MP3 Music Blogs Patrick W. O’Donnell Follow this and additional works at the FSU Digital Library. For more information, please contact [email protected] THE FLORIDA STATE UNIVERSITY COLLEGE OF COMMUNICATION USERS AND THE MARKETING EFFICACY OF MP3 MUSIC BLOGS By PATRICK W. O’DONNELL A Thesis submitted to the Department of Communication in partial fulfillment of the requirements for the degree of Master of Science Degree Awarded: Spring Semester, 2006 Copyright © 2006 Patrick W. O’Donnell All Rights Reserved The members of the Committee approve the thesis of Patrick W. O’Donnell on April 3, 2006. ___________________________ Steven McClung Professor Directing Thesis ___________________________ Jay Rayburn Committee Member ___________________________ Philip Grise Committee Member Approved: _________________________________ Stephen McDowell, Chair, Department of Communication _________________________________ John Mayo, Dean, College of Communication The Office of Graduate Studies has verified and approved the above name committee members. ii TABLE OF CONTENTS List of Tables……………………………………………………………………………IV Acknowledgements……………………………………………………………………..V Abstract…………………………………………………………………………………VI INTRODUCTION………………………………………………………………………1 1. LITERATURE REVIEW……………………………………………………………..2 Blogs……………………………………………………………………………..2 Online Music…………………………………………………………………….5 MP3 Blogs……………………………………………………………………….6 Scholarly -

Teaching Online Toolbox
P a g e | 60 Teaching Online Toolbox Technology is obviously an important consideration in teaching online. The key question is – which of the myriad of available technologies would most meaningfully impact learning in my online class? There is not a one-size-fits-all response to this question. Equally important, the technology is of little use if it is not coupled with an associated practice that makes it compelling to use a particular tool in your online class. Technology is a loose term we are using here to indicate a web application for your class. In the past few years, the web has evolved from a destination to a place for social interaction. The combination of unlimited access to information coupled with the unprecedented ability to publish to the web creates new opportunities for teaching and learning in online classes. Some key questions in this section: What does research suggest about integrating technology into your teaching? How do new social media tools open up opportunities for connecting and collaborating with online students? How can content be provided in new and engaging ways? What practices online support learning-centeredness? What role can mobile devices such as smart phones play in online learning? How might students collect their work as part of a college ePortfolio? Theory Behind Integrating Technology with Learning - TPACK TPACK - Technological Pedagogical Content Knowledge Online Teaching and Learning Resource Guide P a g e | 61 {Image courtesy Matt Koehler & Punya Mishra} While the same could be said of face-to-face instruction, the application and integration of content knowledge, pedagogical knowledge, and technological knowledge is at the heart of an online class. -

Survivalguide-6H.Pdf
INTRODUCTION BY JEFF PRICE, FOUNDER, TUNECORE With your music sitting on the shelves on the online stores available for purchase 24/7, the trick is to be discovered. In the “old days,” music fans discovered music through commercial radio, print magazines and TV. Record labels pitched albums and bands in hopes of getting them featured. These days you no longer need the record label in order to be heard and seen where people go to discover music. Commercial radio is being replaced by web-based radio stations like LastFM, where anyone can have their songs available to hear based on friend and “if you like this you will like that” recommen- dations. Print magazines have been replaced by online music and MP3 blogs. Anyone can email the blog owner (the editor) with their music. MTV has been replaced by YouTube, and anyone can upload a video to YouTube. Online, when one person sees or hears your song, they have the ability to share it everywhere, instantly. New music discovery tools like search engines have also cropped up. Google scours the net, picking up everything from music files to blog reviews. Even digital stores like iTunes allow people to share music they like by playlists. Everyone has access to get their music distributed into the music stores as well as have it at the places music fans go to discover, share and buy music. 1 So how do you get discovered? Even under the “old” model, many artists who got played on the radio, MTV and were featured in Rolling Stone magazine never became popular. -

Blogs in Education Kevin Curran and David Marshall School of Computing and Intelligent Systems, Faculty of Engineering, University of Ulster
3515 Kevin Curran et al./ Elixir Adv. Engg. Info. 36 (2011) 3515-3518 Available online at www.elixirjournal.org Advanced Engineering Informatics Elixir Adv. Engg. Info. 36 (2011) 3515 -3518 Blogs in education Kevin Curran and David Marshall School of Computing and Intelligent Systems, Faculty of Engineering, University of Ulster. ARTICLE INFO ABSTRACT Article history: Educational blogs are used to allow educators to interact with students from any location. Received: 18 May 2011; Teachers sharing ideas through blogs is a promising way to communicate teaching ideas and Received in revised form: allows multicultural teaching methods to be disseminated. The blogs that tell the educator 8 July 2011; how to use technology within the classroom are informative as many teachers would have no Accepted: 18 July 2011; idea about such teaching methods. Research based blogs allow users to see different educational topics discussed in more depth. This paper provides an overview of the impact Keywords blogs are having in an educational context. Educational blogs, © 2011 Elixir All rights reserved. Classroom, Teachers. Introduction Xanga, started in 1996, had only 100 diaries by 1997, and over A blog is a website that is maintained by an individual or 50,000,000 in December 2005. It was the launch of Open group with regular updates of information; this information Diaries in 1998 that helped blogging become more popular, as could include diary entries, descriptions of events or in this case this was the first blog community where readers could add educational material. In most blogs readers can supply comments to other writers' blog entries. -

DIAMONDS & MUSIC I
$6.99 (U.S.), $3.39 (CAN.), £5.50 (U.K.), 8.95 (EUROPE), Y2,500 (JAPAN) aw N W Z : -DIGIT 908 Illllllllllll llllllllllllllll lllllllllllllllllll I B1240804 APROE A04 E0101 MONTY GREENLY 3740 ELM AVE N A LONG BEACH CA 90807 -3402 THE INTERNAT ON4L AUTHORITY ON ML SIC, VIDEO AND DIGITAL ENTERTAINMENT AUGUST 21, 20C4 LUXU Q\Y" E É DIAMONDS & MUSIC i SPE(IAL REPORT INSIDE i www.americanradiohistory.com HOW ABOUT YOU BLINDING THE PAPARAZZI FOR A CHANGE A DIAMOND IS FOREVER ¡ THE FOREVERMPRK IS USED UNDER LICENSE. WWW.P DIA MIONDIS FOREVER.COM www.americanradiohistory.com $6.99 (U.S.), $8.99 (CAN.), £5.50 (U.K.), 8.95 (EUROPE), Y2,500 (JAPAN) aw a `) zW Iong Specia eport Begins On Page 19 www.billboard.com THE INTERNATIONAL AUTHORITY ON MUSIC, VIDEO AND DIGITAL ENTERTAINMENT 110TH YEARra AUGUST 21, 2004 HOT SPOTS Battling To Save Archives At Risk BY BILL HOLLAND When it comes to recorded music archives, there ain't nothing like the real thing. As technology evolves, it is essential, archivists say, that re- issues on new audio platforms be based on original masters. Unfortunately, in an unexpected by- product of digital - era recording, many original masters are in danger of dete- riorating or becoming obsolete. 13 A Bright Remedy That's because the material was This is a first in a Meredith Brooks' 2002 single recorded on early digital equipment two -part series on the challenges `Shine' re- emerges as the that is no longer manufactured. In U.S. record new song `The Dr. -

Dorin HERLO, Phd “Aurel Vlaicu” University of Arad
15 Journal Plus Education, ISSN: 1842-077X, E-ISSN (online) 2068 – 1151 Vol. VIII (2012), No. 1, pp. 15-19 E-LEARNING TOOLS FOR TEACHING AND LEARNING, - II part – Dorin HERLO, PhD “Aurel Vlaicu” University of Arad Abstract: In this second part of the paper is description of some Asynchronous tools of Virtual Learning Environment Tools used in education, knowing that in the previous part was presented some Synchronous tools. Since the tools provided by VLEs are very diverse, teachers must get to know them well in order to be able to use them efficiently in the process of teaching, learning and evaluation. When a teacher chooses to use e-learning tools, s/he should have in mind both the type of the course in which they can be applied and the students’ needs and abilities. Keywords – Virtual Learning Environment Tools (VLEs), Asynchronous The term “VLE tools” includes all kinds of virtual/internet-tools that can serve for educational purposes.Virtual Learning Environment tools (VLEs) are claimed and used by the students, guided by teachers, to facilitate the solving of various learning situations. As we said in the first part of this paper, theVLEs instruments can beclassified in: A. Synchronous tools – in a real time, instantaneous B. Asynchronous tools - transmission of data without the use of an external clock signal, where data can be transmitted intermittently rather than in a steady stream. Now it’s time to present some of Asynchronous tools! 1.Blog A blog (a blend of the term web log) is a type of website or part of a website. -

Does NME Even Know What a Music Blog Is?
Does NME even know what a music blog is?: The Rhetoric and Social Meaning of MP3 Blogs by Larissa Wodtke A thesis presented to the University of Waterloo in fulfilment of the thesis requirement for the degree of Master of Arts in English - Rhetoric and Communication Design Waterloo, Ontario, Canada, 2008 © Larissa Wodtke 2008 Author‘s Declaration I hereby declare that I am the sole author of this thesis. This is a true copy of the thesis, including any required final revisions, as accepted by my examiners. I understand that my thesis may be made electronically available to the public. ii Abstract MP3 blogs and their aggregators, which have risen to prominence over the past four years, are presenting an alternative way of promoting and discovering new music. I will argue that MP3 files greatly affect MP3 blogs in terms of shaping them as: a genre separate from general weblogs and music blogs without MP3s, especially due to the impact of MP3 blog aggregators such as The Hype Machine and Elbows; a particular form of rhetoric illuminated by Kenneth Burke's dramatistic ratios of agency-purpose, purpose-act and scene-act; and as a potentially subversive subculture, which like other subcultures, exists in a symbiotic relationship with the traditional media it defines itself against. Using excerpts from multiple MP3 blogs and their forums, interviews with MP3 bloggers and Anthony Volodkin (creator of The Hype Machine), references to MP3 blogs in traditional press, and Burke's theory of dramatism and Hodge and Kress's theories of social semiotics, I will demonstrate that the MP3 file is not only changing the way music is consumed and circulated, but also the way music is promoted and discussed.