Definition of Scenarios, Internal and External Services
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Copyright 2009 Cengage Learning. All Rights Reserved. May Not Be Copied, Scanned, Or Duplicated, in Whole Or in Part
Index Note: Page numbers referencing fi gures are italicized and followed by an “f ”. Page numbers referencing tables are italicized and followed by a “t”. A Ajax, 353 bankruptcy, 4, 9f About.com, 350 Alexa.com, 42, 78 banner advertising, 7f, 316, 368 AboutUs.org, 186, 190–192 Alta Vista, 7 Barack Obama’s online store, 328f Access application, 349 Amazon.com, 7f, 14f, 48, 247, BaseballNooz.com, 98–100 account managers, 37–38 248f–249f, 319–320, 322 BBC News, 3 ActionScript, 353–356 anonymity, 16 Bebo, 89t Adobe Flash AOL, 8f, 14f, 77, 79f, 416 behavioral changes, 16 application, 340–341 Apple iTunes, 13f–14f benign disinhibition, 16 fi le format. See .fl v fi le format Apple site, 11f, 284f Best Dates Now blog, 123–125 player, 150, 153, 156 applets, Java, 352, 356 billboard advertising, 369 Adobe GoLive, 343 applications, see names of specifi c bitmaps, 290, 292, 340, 357 Adobe Photoshop, 339–340 applications BJ’s site, 318 Advanced Research Projects ARPA (Advanced Research Black Friday, 48 Agency (ARPA), 2 Projects Agency), 2 blog communities, 8f advertising artistic fonts, 237 blog editors, 120, 142 dating sites, 106 ASCO Power University, 168–170 blog search engines, 126 defi ned, 397 .asf fi le format, 154t–155t Blogger, 344–347 e-commerce, 316 AskPatty.com, 206–209 blogging, 7f, 77–78, 86, 122–129, Facebook, 94–96 AuctionWeb, 7f 133–141, 190, 415 family and lifestyle sites, 109 audience, capturing and retaining, blogosphere, 122, 142 media, 373–376 61–62, 166, 263, 405–407, blogrolls, 121, 142 message, 371–372 410–422, 432 Blue Nile site, -

Liferay Portal 6 Enterprise Intranets
Liferay Portal 6 Enterprise Intranets Build and maintain impressive corporate intranets with Liferay Jonas X. Yuan BIRMINGHAM - MUMBAI Liferay Portal 6 Enterprise Intranets Copyright © 2010 Packt Publishing All rights reserved. No part of this book may be reproduced, stored in a retrieval system, or transmitted in any form or by any means, without the prior written permission of the publisher, except in the case of brief quotations embedded in critical articles or reviews. Every effort has been made in the preparation of this book to ensure the accuracy of the information presented. However, the information contained in this book is sold without warranty, either express or implied. Neither the author, nor Packt Publishing, and its dealers and distributors will be held liable for any damages caused or alleged to be caused directly or indirectly by this book. Packt Publishing has endeavored to provide trademark information about all of the companies and products mentioned in this book by the appropriate use of capitals. However, Packt Publishing cannot guarantee the accuracy of this information. First published: April 2010 Production Reference: 1230410 Published by Packt Publishing Ltd. 32 Lincoln Road Olton Birmingham, B27 6PA, UK. ISBN 978-1-849510-38-7 www.packtpub.com Cover Image by Karl Swedberg ([email protected]) Credits Author Editorial Team Leader Jonas X. Yuan Aanchal Kumar Reviewer Project Team Leader Amine Bousta Lata Basantani Acquisition Editor Project Coordinator Dilip Venkatesh Shubhanjan Chatterjee Development Editor Proofreaders Mehul Shetty Aaron Nash Lesley Harrison Technical Editors Aditya Belpathak Graphics Alfred John Geetanjali Sawant Charumathi Sankaran Nilesh Mohite Copy Editors Production Coordinators Leonard D'Silva Avinish Kumar Sanchari Mukherjee Aparna Bhagat Nilesh Mohite Indexers Hemangini Bari Cover Work Rekha Nair Aparna Bhagat About the Author Dr. -

The Example of Swedish Independent Music Fandom by Nancy K
First Monday Online groups are taking new forms as participants spread themselves amongst multiple Internet and offline platforms. The multinational online community of Swedish independent music fans exemplifies this trend. This participant–observation analysis of this fandom shows how sites are interlinked at multiple levels, and identifies several implications for theorists, researchers, developers, industry and independent professionals, and participants. Contents Introduction Fandom Swedish popular music The Swedish indie music fan community Discussion Conclusion Introduction The rise of social network sites is often taken to exemplify a shift from the interest–based online communities of the Web’s “first” incarnation to a new “Web 2.0” in which individuals are the basic unit, rather than communities. In a recent First Monday article, for instance, boyd (2006) states, “egocentric networks replace groups.” I argue that online groups have not been “replaced.” Even as their members build personal profiles and egocentric networks on MySpace, Facebook, BlackPlanet, Orkut, Bebo, and countless other emerging social network sites, online groups continue to thrive on Web boards, in multiplayer online games, and even on the all–but–forgotten Usenet. However, online communities are also taking a new form somewhere between the site-based online group and the egocentric network, distributing themselves throughout a variety of sites in a quasi–coherent networked fashion. This new form of distributed community poses particular problems for its members, developers, and analysts. This paper, based on over two years of participant–observation, describes this new shape of online community through a close look at the multinational online community of fans of independent rock music from Sweden. -

Address Munging: the Practice of Disguising, Or Munging, an E-Mail Address to Prevent It Being Automatically Collected and Used
Address Munging: the practice of disguising, or munging, an e-mail address to prevent it being automatically collected and used as a target for people and organizations that send unsolicited bulk e-mail address. Adware: or advertising-supported software is any software package which automatically plays, displays, or downloads advertising material to a computer after the software is installed on it or while the application is being used. Some types of adware are also spyware and can be classified as privacy-invasive software. Adware is software designed to force pre-chosen ads to display on your system. Some adware is designed to be malicious and will pop up ads with such speed and frequency that they seem to be taking over everything, slowing down your system and tying up all of your system resources. When adware is coupled with spyware, it can be a frustrating ride, to say the least. Backdoor: in a computer system (or cryptosystem or algorithm) is a method of bypassing normal authentication, securing remote access to a computer, obtaining access to plaintext, and so on, while attempting to remain undetected. The backdoor may take the form of an installed program (e.g., Back Orifice), or could be a modification to an existing program or hardware device. A back door is a point of entry that circumvents normal security and can be used by a cracker to access a network or computer system. Usually back doors are created by system developers as shortcuts to speed access through security during the development stage and then are overlooked and never properly removed during final implementation. -

Adversarial Web Search by Carlos Castillo and Brian D
Foundations and TrendsR in Information Retrieval Vol. 4, No. 5 (2010) 377–486 c 2011 C. Castillo and B. D. Davison DOI: 10.1561/1500000021 Adversarial Web Search By Carlos Castillo and Brian D. Davison Contents 1 Introduction 379 1.1 Search Engine Spam 380 1.2 Activists, Marketers, Optimizers, and Spammers 381 1.3 The Battleground for Search Engine Rankings 383 1.4 Previous Surveys and Taxonomies 384 1.5 This Survey 385 2 Overview of Search Engine Spam Detection 387 2.1 Editorial Assessment of Spam 387 2.2 Feature Extraction 390 2.3 Learning Schemes 394 2.4 Evaluation 397 2.5 Conclusions 400 3 Dealing with Content Spam and Plagiarized Content 401 3.1 Background 402 3.2 Types of Content Spamming 405 3.3 Content Spam Detection Methods 405 3.4 Malicious Mirroring and Near-Duplicates 408 3.5 Cloaking and Redirection 409 3.6 E-mail Spam Detection 413 3.7 Conclusions 413 4 Curbing Nepotistic Linking 415 4.1 Link-Based Ranking 416 4.2 Link Bombs 418 4.3 Link Farms 419 4.4 Link Farm Detection 421 4.5 Beyond Detection 424 4.6 Combining Links and Text 426 4.7 Conclusions 429 5 Propagating Trust and Distrust 430 5.1 Trust as a Directed Graph 430 5.2 Positive and Negative Trust 432 5.3 Propagating Trust: TrustRank and Variants 433 5.4 Propagating Distrust: BadRank and Variants 434 5.5 Considering In-Links as well as Out-Links 436 5.6 Considering Authorship as well as Contents 436 5.7 Propagating Trust in Other Settings 437 5.8 Utilizing Trust 438 5.9 Conclusions 438 6 Detecting Spam in Usage Data 439 6.1 Usage Analysis for Ranking 440 6.2 Spamming Usage Signals 441 6.3 Usage Analysis to Detect Spam 444 6.4 Conclusions 446 7 Fighting Spam in User-Generated Content 447 7.1 User-Generated Content Platforms 448 7.2 Splogs 449 7.3 Publicly-Writable Pages 451 7.4 Social Networks and Social Media Sites 455 7.5 Conclusions 459 8 Discussion 460 8.1 The (Ongoing) Struggle Between Search Engines and Spammers 460 8.2 Outlook 463 8.3 Research Resources 464 8.4 Conclusions 467 Acknowledgments 468 References 469 Foundations and TrendsR in Information Retrieval Vol. -

Young Adult Library Services Association
THE OFFICIAL JOURNAL OF THE YOUNG ADULT LIBRARY SERVICES ASSOCIATION five ye ng ar ti s a o r f b y e a l l e s c young adult c e s l l e a b y r 5 f a t o in rs librarylibrary services services g five yea VOLUME 6 | NUMBER 2 WINTER 2008 ISSN 1541-4302 $12.50 INSIDE: INFORMATION TOOLS MUsiC WEB siTes TOP FIFTY GAMinG CORE COLLECTION TITLES INTERVIEW WITH KIMBERLY NEWTON FUSCO INFORMATION LITERACY AND MUCH MORE! TM ISSUE! TEEN TECH WEEK TM TM TEEN TECH WEEK MARCH 2-8, 2008 ©2007 American Library Association | Produced in partnership with YALSA | Design by Distillery Design Studio | www.alastore.ala.org march 2–8, 2008 for Teen Tech Week™ 2008! Join the celebration! Visit www.ala.org/teentechweek, and you can: ã Get great ideas for activities and events for any library, at any budget ã Download free tech guides and social networking resources to share with your teens ã Buy cool Teen Tech Week merchandise for your library ã Find inspiration or give your own ideas at the Teen Tech Week wiki, http://wikis.ala.org/yalsa/index.php/ Teen_Tech_Week! Teen Tech Week 2008 National Corporate Sponsor www.playdnd.com ttw_fullpage_cmyk.indd 1 1/3/2008 1:32:22 PM THE OFFICIAL JOURNAL OF THE YOUNG ADULT LIBRARY SERVICES ASSOCIATION young adult library services VOLUME 6 | NU MBER 2 WINTER 2008 ISSN 1541-4302 YALSA Perspective 33 Music Web Sites for Teen Tech Week 6 Margaret Edwards Award Turns 20 and Beyond By Betty Carter and Pam Spencer Holley By Kate Pritchard and Jaina Lewis 36 Top Fifty Gaming Core Collection Titles School Library Perspective Compiled by Kelly Czarnecki 14 Do We Still Dewey? By Christine Allen Literature Surveys and Research 39 Information Literacy As a Department Teen Perspective Store 15 Teens’ Top Ten Redux Applications for Public Teen Librarians Readers from New Jersey Talk about the By Dr. -

Efficient and Trustworthy Review/Opinion Spam Detection
International Journal on Recent and Innovation Trends in Computing and Communication ISSN: 2321-8169 Volume: 5 Issue: 4 86 – 94 _____________________________________________________________________________________________ Efficient and Trustworthy Review/Opinion Spam Detection Sanketi P. Raut Prof. Chitra Wasnik ME II (Computer), Computer Dept. Lokmanya Tilak College of Engineering, Lokmanya Tilak College of Engineering, New Mumbai, New Mumbai, Email:[email protected] Email:[email protected] Abstract - The most common mode for consumers to express their level of satisfaction with their purchases is through online ratings, which we can refer as Online Review System. Network analysis has recently gained a lot of attention because of the arrival and the increasing attractiveness of social sites, such as blogs, social networking applications, micro blogging, or customer review sites. The reviews are used by potential customers to find opinions of existing users before purchasing the products. Online review systems plays an important part in affecting consumers' actions and decision making, and therefore attracting many spammers to insert fake feedback or reviews in order to manipulate review content and ratings. Malicious users misuse the review website and post untrustworthy, low quality, or sometimes fake opinions, which are referred as Spam Reviews. In this study, we aim at providing an efficient method to identify spam reviews and to filter out the spam content with the dataset of gsmarena.com. Experiments on the dataset collected from gsmarena.com show that the proposed system achieves higher accuracy than the standard naïve bayes. Keywords - Review Spam detection, Opinion, Text mining, WordNet, naïve bayes classifier, logistic Regression. __________________________________________________*****_________________________________________________ making purchase. Opinions/Reviews are middle of almost all I. -

Social Media Compendium Oktober 2009
Social Media Compendium Oktober 2009 COMMUNITY PLATFORMS / SOCIAL NETWORKS NICHED COMMUNITIES BLOG PLATFORMS BLOG COMMUNITIES & TOOLS / FORUM BLOG SEARCH COMMENT / REPUTATION MICROMEDIA / MICROBLOGGING SOCIAL BOOKMARKING CROWDSOURCED CONTENT CUSTOMER SERVICE, REVIEWS TEXT & PRESENTATION PUBLISHING & SHARING IMAGE SHARING & HOSTING IMAGE SEARCH IMAGE EDITING MUSIC SHARING & STREAMING VIDEO PUBLISHING & SHARING INSTRUCTIONAL & EDUCATIONAL VIDEOS VIDEO SEARCH ENGINES VIDEO STREAMING FEEDS / NEWS AGGREGATOR SOCIAL AGGREGATOR / PROFILE MANAGER LOCATION!BASED EVENTS DIRECT COMMUNICATION "IM / SMS / VOICE# WIKIS COLLABORATIVE PLATFORMS PRODUCTIVITY TOOLS INFORMATION DATABASES / MONITORING MEDIA & COMMUNICATION BLOGS SEARCH ENGINES REAL!TIME SEARCH by Matthieu Hartig ■ [email protected] ■ @matthartig COMMUNITY PLATFORMS / SOCIAL NETWORKS facebook.com (2) Facebook is the world’s largest free-access social networking website. Users can join networks organized by city, workplace, school, and region to connect and interact with other people. People can also add friends and send them messages, and update their personal pro"les to notify friends. hi5.com (43) hi5 is an international social network with a local #avor. It enables members to stay connect- ed, share their lives, and learn what’s happening around them – through customizable pro"le pages, messaging, unlimited photo storage, hundreds of OpenSocial applications and more. friendster.com (117) Founded in 2002, Friendster is one of the web’s older social networking services. Adults, 16 and up can join and connect with friends, family, school, groups, activities and interests. $e site currently has over 50 million users. Over 90% of Friendster’s tra%c comes from Asia. tagged.com (109) Protecting the safety of their users is what makes Tagged di&erent from other social network- ing sites. -

Empowering School Teachers for Emerging Technologies: an Action Plan
RESEARCH PAPERS EMPOWERING SCHOOL TEACHERS FOR EMERGING TECHNOLOGIES: AN ACTION PLAN By PRADEEP KUMAR MISRA Associate Professor, Faculty of Education and Allied Sciences, M.J.P. Rohilkhand University, Bareilly (U.P.) ABSTRACT “Possessing openness to emerging technologies is critical for teachers in the technology-rich 21st Century as technology continues to accelerate at a rapid rate. Readiness for new technologies is a challenge associated with change. Teachers who resist change may impede and/or limit their students' learning and skills. Teachers, therefore, must prepare students by teaching knowledge and skills necessary for students to be successful in the technology-rich 21st Century” (Niles, 2007, p.27). In this context, school teachers need to understand how emerging technologies work, what they offer, and to use them for betterment of teaching learning process. Here a pertinent question arises that what approach should be adopted to empower school teachers for emerging technologies. To critically and systematically deal with these issues, author talks about emerging technologies in education, their impact on teaching-learning process and need for Tech-savvy teachers. This discussion is followed by a detailed action plan to empower school teachers for emerging technologies. The proposed action plan is based on the approach that three parties namely NCTE (National Council for Teacher Education), Teacher Education Departments/Institutions and school teachers themselves are key to fulfill this promise. Keywords: Emerging Technologies, School Teachers, Technologies for Teachers, Technologies for Teaching Learning. INTRODUCTION more – and will always know more – than their teachers Background about technology and how to manipulate it”(p.42). Prensky (2007, p.42) further offers word of advice, “Teachers can Technology has caused a revolution in the way we teach and should be able to understand and teach where and and learn but there can be no real revolution unless the how new technologies can add value in learning. -
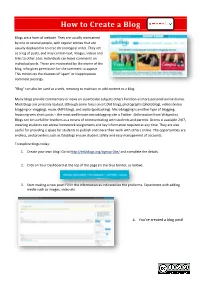
Introduction to Blogs
How to Create a Blog Blogs are a form of website. They are usually maintained by one or several people, with regular entries that are usually displayed in reverse chronological order. They act as a log of posts, and may contain text, images, videos and links to other sites. Individuals can leave comments on individual posts. These are moderated by the owner of the blog, who gives permission for the comment to appear. This minimizes the chances of ‘spam’ or inappropriate comment postings. "Blog" can also be used as a verb, meaning to maintain or add content to a blog. Many blogs provide commentary or news on a particular subject; others function as more personal online diaries. Most blogs are primarily textual, although some focus on art (Art blog), photographs (photoblog), videos (video blogging or vlogging), music (MP3 blog), and audio (podcasting). Microblogging is another type of blogging, featuring very short posts – the most well known microblogging site is Twitter. (Information from Wikipedia). Blogs can be useful for teachers as a means of communicating with students and parents. Access is available 24/7, meaning students can access homework assignments and key information required at any time. They are also useful for providing a space for students to publish and share their work with others online. The opportunities are endless, and providers such as Edublogs ensure student safety and easy management of accounts. To explore blogs today: 1. Create your own blog! Go to http://edublogs.org/signup-0be/ and complete the details. 2. Click on Your Dashboard at the top of the page (in the blue border, as below). -

The Users and Marketing Efficacy of MP3 Music Blogs
Florida State University Libraries Electronic Theses, Treatises and Dissertations The Graduate School 2006 Users and the Marketing Efficacy of MP3 Music Blogs Patrick W. O’Donnell Follow this and additional works at the FSU Digital Library. For more information, please contact [email protected] THE FLORIDA STATE UNIVERSITY COLLEGE OF COMMUNICATION USERS AND THE MARKETING EFFICACY OF MP3 MUSIC BLOGS By PATRICK W. O’DONNELL A Thesis submitted to the Department of Communication in partial fulfillment of the requirements for the degree of Master of Science Degree Awarded: Spring Semester, 2006 Copyright © 2006 Patrick W. O’Donnell All Rights Reserved The members of the Committee approve the thesis of Patrick W. O’Donnell on April 3, 2006. ___________________________ Steven McClung Professor Directing Thesis ___________________________ Jay Rayburn Committee Member ___________________________ Philip Grise Committee Member Approved: _________________________________ Stephen McDowell, Chair, Department of Communication _________________________________ John Mayo, Dean, College of Communication The Office of Graduate Studies has verified and approved the above name committee members. ii TABLE OF CONTENTS List of Tables……………………………………………………………………………IV Acknowledgements……………………………………………………………………..V Abstract…………………………………………………………………………………VI INTRODUCTION………………………………………………………………………1 1. LITERATURE REVIEW……………………………………………………………..2 Blogs……………………………………………………………………………..2 Online Music…………………………………………………………………….5 MP3 Blogs……………………………………………………………………….6 Scholarly -

The History of Digital Spam
The History of Digital Spam Emilio Ferrara University of Southern California Information Sciences Institute Marina Del Rey, CA [email protected] ACM Reference Format: This broad definition will allow me to track, in an inclusive Emilio Ferrara. 2019. The History of Digital Spam. In Communications of manner, the evolution of digital spam across its most popular appli- the ACM, August 2019, Vol. 62 No. 8, Pages 82-91. ACM, New York, NY, USA, cations, starting from spam emails to modern-days spam. For each 9 pages. https://doi.org/10.1145/3299768 highlighted application domain, I will dive deep to understand the nuances of different digital spam strategies, including their intents Spam!: that’s what Lorrie Faith Cranor and Brian LaMacchia ex- and catalysts and, from a technical standpoint, how they are carried claimed in the title of a popular call-to-action article that appeared out and how they can be detected. twenty years ago on Communications of the ACM [10]. And yet, Wikipedia provides an extensive list of domains of application: despite the tremendous efforts of the research community over the last two decades to mitigate this problem, the sense of urgency ``While the most widely recognized form of spam is email spam, the term is applied to similar abuses in other media: instant remains unchanged, as emerging technologies have brought new messaging spam, Usenet newsgroup spam, Web search engine spam, dangerous forms of digital spam under the spotlight. Furthermore, spam in blogs, wiki spam, online classified ads spam, mobile when spam is carried out with the intent to deceive or influence phone messaging spam, Internet forum spam, junk fax at scale, it can alter the very fabric of society and our behavior.